Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,362 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERC%3C/text%3E%3C/svg%3E)
Hi, I´ve recently created my synapse workspace and when I tryied to run more then 1 notebook in parallel, I got an error that I don´t have enough vcores to run the notebooks. I´ve created a service request to increase my quota of vcores to 50, but I´ve noticed that when I tried to run 4 applications at the same time, I was able run 3 and 1 got queued. To run 4, or more applications at the same time, should I have requested more vcores? I thought that each application needed 12 vcores, so for 4 applications I´ll needed 48 vcores, then 50 vcores of quota should be enough
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBM%3C/text%3E%3C/svg%3E)
Hello @Ricardo Cauduro ,
Welcome to the MS Q&A platform.
Sorry, it looks like your understanding is wrong. The default number of V-cores on the sparkpools depends on the Spark pool node size and the number of Nodes.
For example: If we choose a node size small(4 vcore/32 GB) and the number of nodes 6, then the total number of Vcores will be 4*6 = 24 Vcores.
Regarding your statement: "I thought that each application needed 12 vcores, so for 4 applications I´ll needed 48 vcores, then 50 vcores of quota should be enough"
To run a single notebook (application), the minimum number of Vcores depends on the code. Some notebooks may use 12 Vcores, and some may use 20 Vcores. These are depending on the workload.
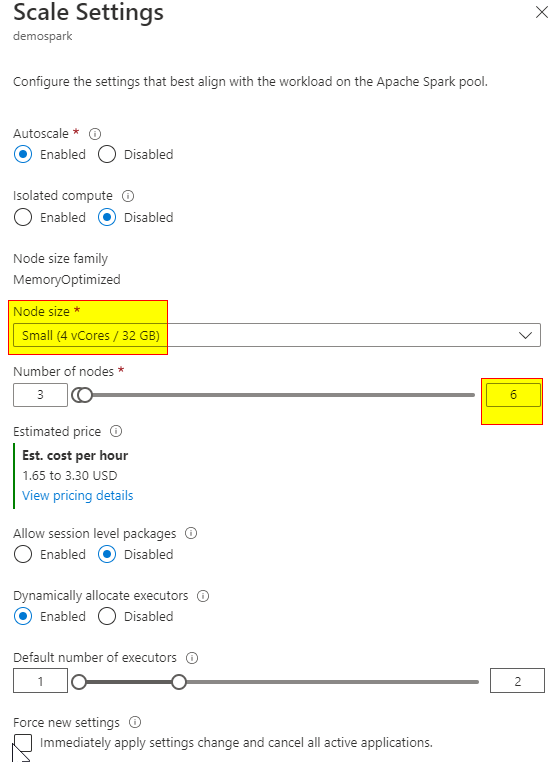
When I had the small pool (4 vcore) and 5 nodes, one of my notebook took all 20 Vcores. and when I try to run a new notebook, I saw the below error as the vcores were exhausted by my 1st notebook session. I need to close the current session to run the 2nd notebook.
AVAILABLE_COMPUTE_CAPACITY_EXCEEDED: Livy session has failed. Session state: Error. Error code:
AVAILABLE_COMPUTE_CAPACITY_EXCEEDED. Your job requested 20 vcores. However,
the pool only has 0 vcores available out of quota of 20 vcores. Try ending
the running job(s) in the pool, reducing the numbers of vcores requested,
increasing the pool maximum size or using another pool. Source: User.
Here is one more example provided in the documentation(with respect to the nodes):
Reference document: https://learn.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-concepts
I hope this helps. Please let me know if you have any further questions.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hello @Ricardo Cauduro ,
I am just checking in to see if you have any further questions here.
Hello @Ricardo Cauduro ,
I am just checking in to see if you have any further questions here.

Hi @BhargavaGunnam-MSFT . I would like to thank you for you time and great explanation. So to run more jobs at the same time I need to check how many v-cores each notebook is using than request an raise on my vcore quota right?
Hello @Ricardo Cauduro ,
Your understanding is correct.
you can also configure the session for the notebook.
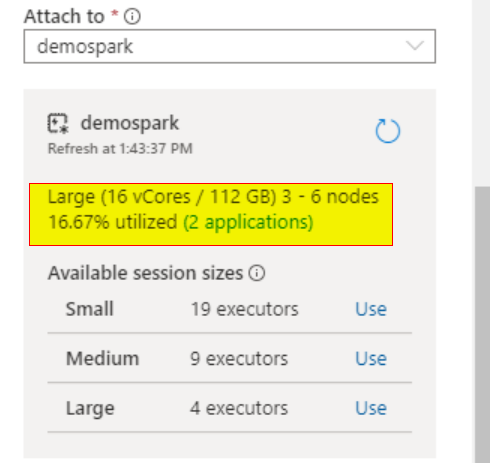
for ex: If your Spark pool is configured with Node size, large (16 Vcores/128GB), and number of nodes 3 to 6
So in total, we will get 16*6 = 96 Vcores available on the spark pool.
How to configure the session on the notebook level:
Click on the Gear ICON on the notebook
You will see the executor size, Driver size and Executors. These are the main components for any Notebook session.
When you select the spark pool with Node size- large, you will see available executor size -small, medium, and large
If I choose my session to small and executors to 3, my notebook session will use max- 12 Vcores + 1 driver (4 vcores) in my case
So total= 16 Vcores will be used in my notebook out of 96 V-cores.
I hope this gives you more clarity on the V-cores.
Please note: Driver Size is equal to Executor size.
If this answers your question, please consider accepting the answer by hitting the Accept answer button, as it helps the community.
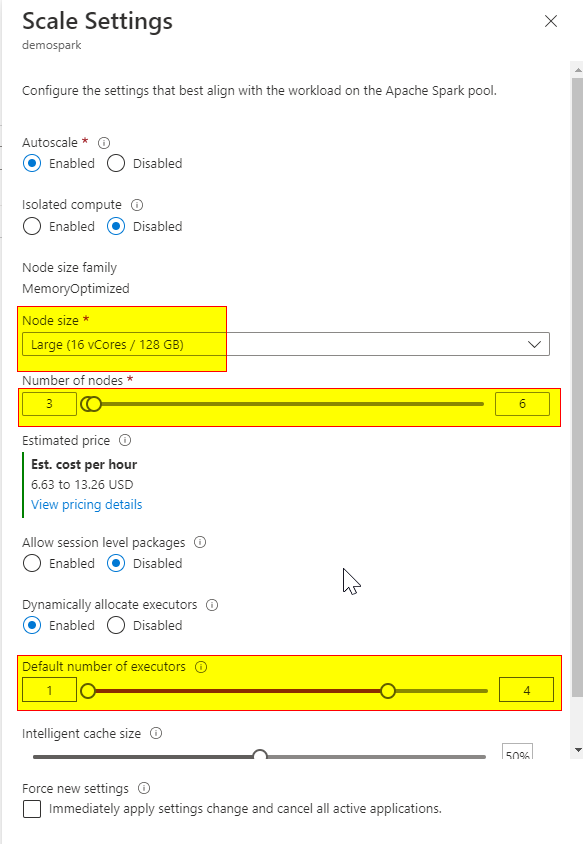
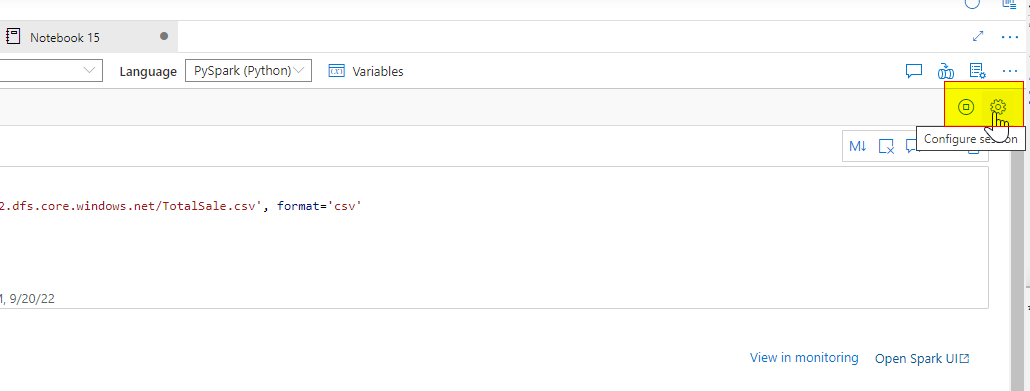
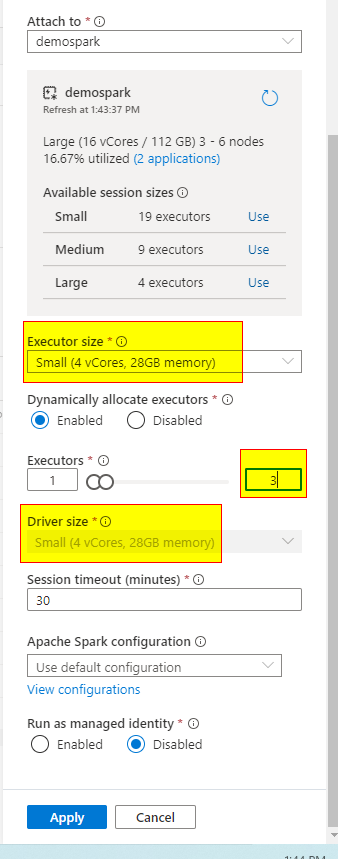
Hello @Ricardo Cauduro ,
Also, we can see how much percent of the resources and number of applications are used on the spark pool using the notebook "configure sessi.on"
Hello @Ricardo Cauduro ,
I am just checking in to see if you have any further questions here.
If this answers your question, please consider accepting the answer by hitting the Accept answer button, as it helps the community.
Hi @BhargavaGunnam-MSFT . I´ve upvoted but I can see the accept answer button... it should be right after your answer but it´s not there.
Hello @Ricardo Cauduro ,
I will bring this to my team's attention. Thank you so much for the feedback.