Azure Machine Learning
An Azure machine learning service for building and deploying models.
2,544 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJ%3C/text%3E%3C/svg%3E)
I'm having trouble getting ML assisted data labeling to begin prelabeling.
I have an object detection Data Labeling project in Azure ML Studio workspace. ML Assisted is enabled from the project creation. I manually labeled the number required to start Training run (in my case, 45). Completed Training run without issue. Yet, the Inference run never started up. The info button when I hover over the "Prelabeled" Task Queue informs me the Inference run must be done before prelabeling can begin. How do I start the Inference run? Is there a manual step needed to start the Inference run? I thought it would happen automatically after the Training run completed (ensuring compute resource is available of course). I labeled more manually to trigger and complete a 2nd Training run, but Inference still did not start. I must be missing something, but not sure what to do.
The on-demand button in the Settings is for the Training run only, so it is not clear if the Inference run can be triggered on-demand.
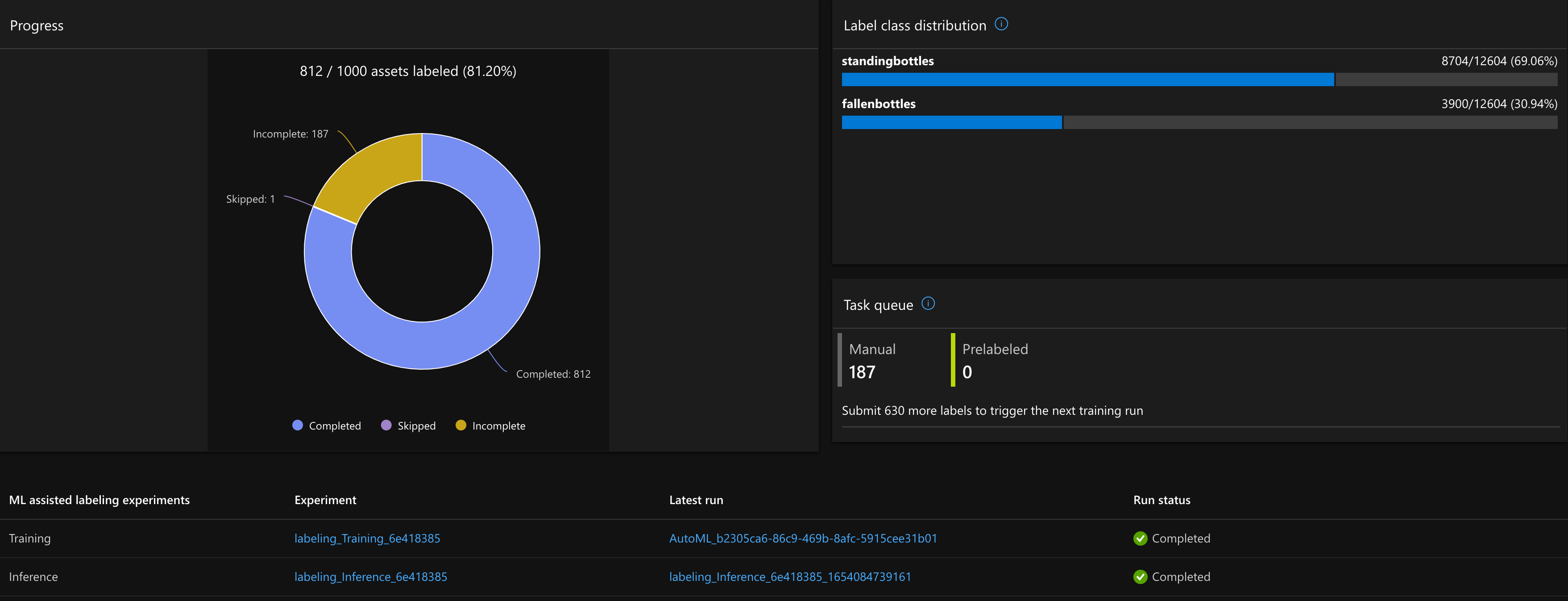
Here's my project experiments summary on the dashboard view:
ML assisted data labeling experiments Experiment Latest run Run Status
Training cool_experiment AutoML_<hashid> Completed
Inference Experiment not started -- --

I am having the same problem. Training for the ML assisted data labeling completed but the inference run does not start. How can I start the inference run?
@Ramr-msft Some months ago, the ML assisted data labeling inference run started automatically, I never had to export labeled data or use AutoML. That was all automated. Did that change now?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERM%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ES%3C/text%3E%3C/svg%3E)
Inference run is used to generate ML-Assisted pre-labeled task for labelers. There are two prerequisites for that to happen:
Hi @Shu ,
Thanks for your reply. The first prerequisite is met, there is a model (training completed successfully). The second prerequisite is met, too (there is a need). But somehow, all images were moved to the Manual task queue instead of the Prelabeled task queue. I do not understand, why.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERH%3C/text%3E%3C/svg%3E)
Is there a way to manually trigger an inference run, for ml-assisted labeling?