Azure Blob Storage
An Azure service that stores unstructured data in the cloud as blobs.
2,416 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKS%3C/text%3E%3C/svg%3E)
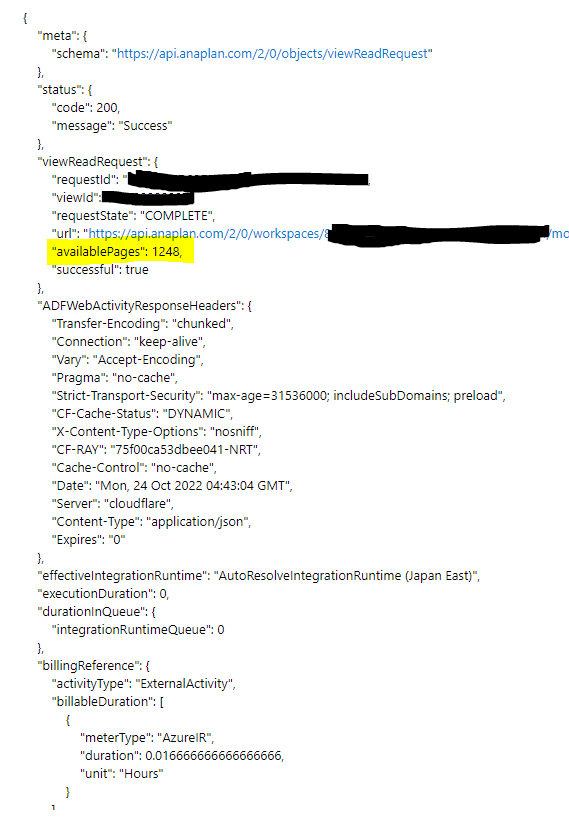
Data is downloaded via HTTP API calls.
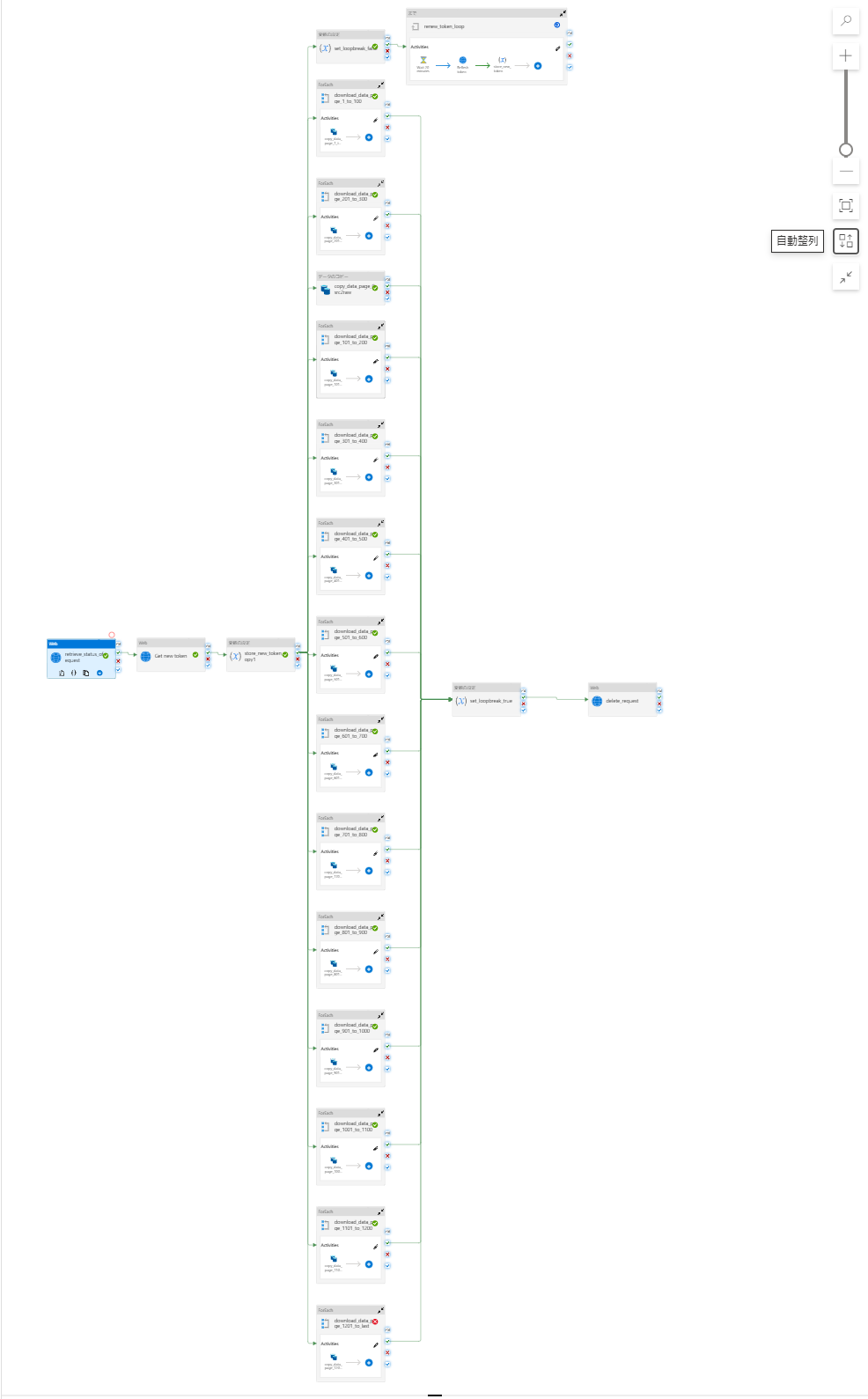
I want to initiate the request with "Initiate Request", get the number of pages available for download with 'retrieve_status_of_request', divide the pages into 50 pages each, and perform the copy activity for each 50 pages simultaneously with Foreach.
The image shows the number of nodes divided manually.
Does anyone know of a function or pipeline structure that would smartly accomplish this?
Any help would be appreciated.
Thank you.



' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Kakehi Shunya (筧 隼弥) ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet. In case if you have any resolution please do share that same with the community as it can be helpful to others . Otherwise, will respond back with the more details and we will try to help .
Thanks
Martin
Hello @Kakehi Shunya (筧 隼弥) ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet. In case if you have any resolution please do share that same with the community as it can be helpful to others .
If you have any question relating to the current thread, please do let us know and we will try out best to help you.
In case if you have any other question on a different issue, we request you to open a new thread .
Thanks
Martin
Hello @Kakehi Shunya (筧 隼弥) and welcome to Microsoft Q&A.
While your existing structure would do things in parallel, there are more compact and flexible ways to accomplish this.
I have in mind, a ForEach loop, containing a copy activity. Since we know how many pages total, and how many pages per page-batch, we can calculate how many page-batches on the fly.
The ForEach loop requires an array/list of things to iterate over. In this case we want it to be the start/end for each group of pages (page-batch). I am assuming you know how to setup the Copy Activity REST pagination to do a range. If we want pages 51-100 to be a single page-batch and handled by a single copy, the pagination rule for that would be start=51, end =100, increment = 1.
You have already done a calculation on how many page-batches (24.8) depending upon how your API works, we will need to either round up, or handle the remainde .8 seperately from the rest.
We can use the range function to make a sequence of numbers representing our page-batches. This is what we will iterate over.
@range(0,24)
-> [0,1,2,3,4,5,6...22,23,24]
Inside the ForEach loop, we use the expression @item() to get the value of the current iteration. We can then use it to calculate the page start and end.
Start: @add( 1 , mul( item() , 50) )
End: @mul( 50 , add(1 , item() ) )
item | start | end
0 | 1 | 50
1 | 51 | 100
2 | 101 | 150
3 | 151 | 200
In this way we determine the pagination btis.
You will also want to parameterize the sink dataset to make use of item() so each page-batch has a different file name. If you do not, you risk each page-batch overwriting each other.
Now, since you mentioned you want all this parallel, you will want to make sure the ForEach "Sequential" is turned off. Also, crank up the "Batch count" to 20-something. Batch count determines how many workers are making the ForEach parallel.
Try not to use Set Variable activity inside ForEach. All the parallel instances will fight over a single variable "slot".
Hold up, in your picture are those multiple forEach loops? Somehow I thought they were just copy activities. Now I am second guessing my understanding...
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how