Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
9,477 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERR%3C/text%3E%3C/svg%3E)
Hello folks,
I have a "long-running" pipeline, by my estimates, it should only take about 24 hours to complete. I started the pipeline after dinner on Friday and let it go until Monday morning, and by all means it should have completed, however it is currently on hour 60 of execution. The pipeline is a multi-level data migration pipeline that fires an internal pipelines for each postgres table and copies the data over to another postgres table. Currently set to run about 10 in parallel at a time. However I noticed that this morning, it is only running 1 at a time. I can confirm that it was running parallel when I started Friday. Are there any restrictions for DIUs or anything, that would cause this kind of behavior?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Robert Riley and welcome to Microsoft Q&A.
There are a few things to check as possible causes. I assume you have an execute pipeline activity inside a forEach loop.
There are at least two places the restriction could be taking place. The first two to check are pipeline currency and loop settings. Either one alone could cause the throttle, so both need to be correct.
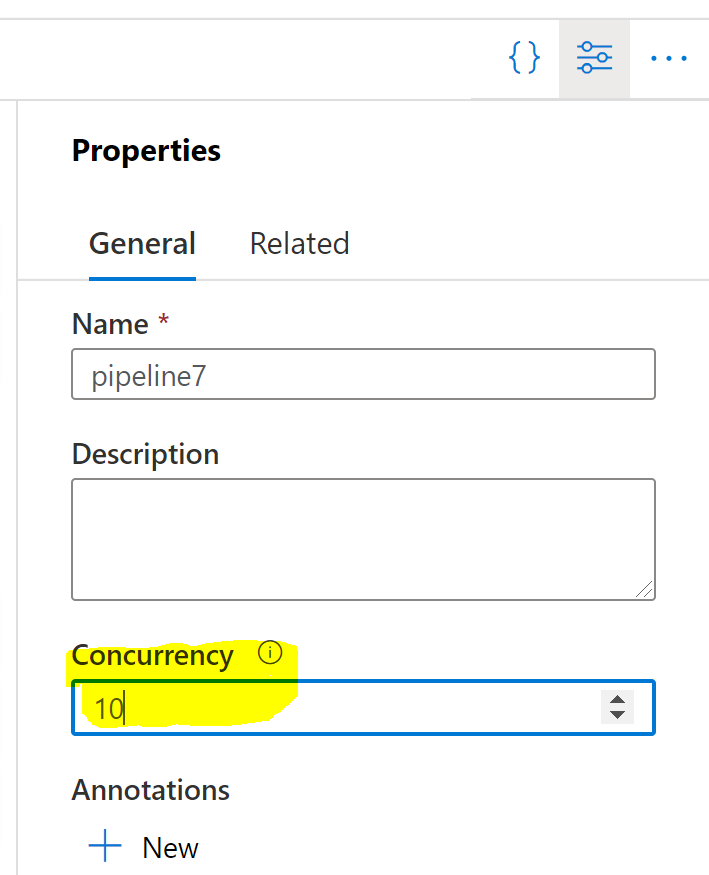
Each pipeline has a concurrency property; how many instances are allowed to run at any given time. This will also throttle triggers.
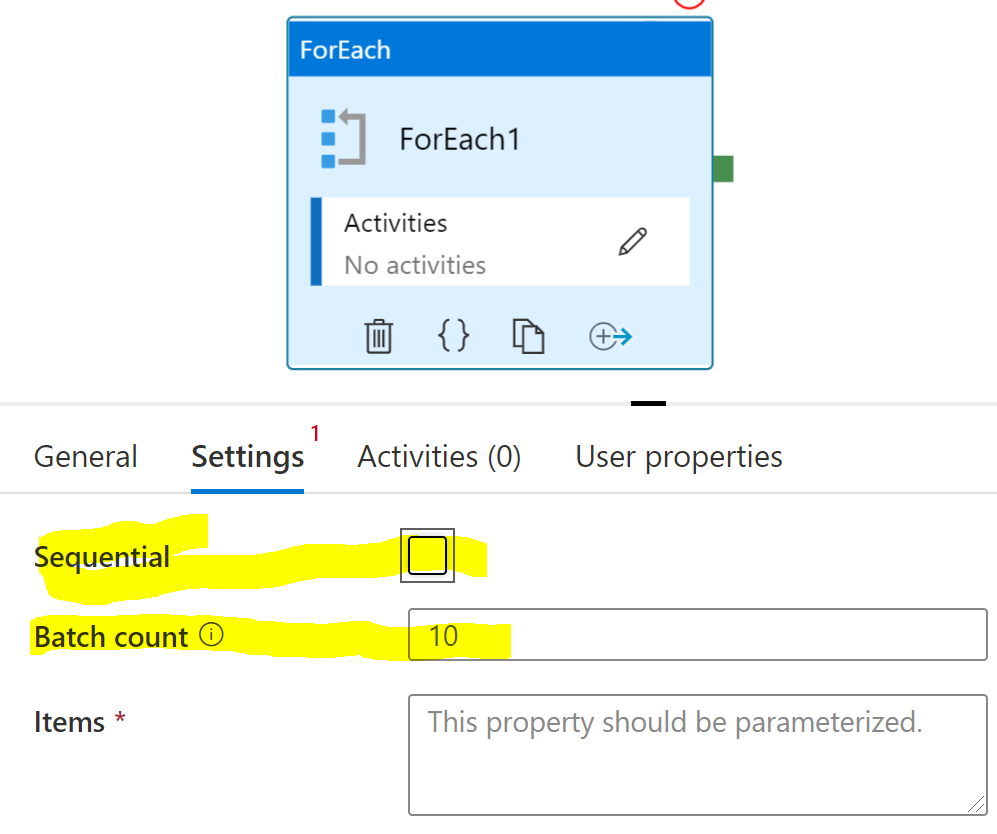
There are also the settings on the loop. When the Sequential option is selected, only one (1) instance is run at a time. There is also the Batch count feature, which determines the maximum number of loop instances run in parallel (assuming Sequential is off).
Thanks for the response @MartinJaffer-MSFT . I recognize your name from lurking here long enough, hopefully you can help.
Currently it does look like batch count is 10 and not sequential:

There is no value for maximum pipeline concurrency at the moment, but the documentation states that the default is "no maximum".

I did also notice something peculiar after posting this, I have an execute pipeline activity for logging start and finish of the activities in our target db. I took a look at the records and found that no pipeline was triggered between "2021-01-31 05:52:51" UTC and "2021-02-01 13:50:18" UTC, this is a greater span of time than the longest single pipeline run.

@Robert Riley Now that we have established the fault is not in the concurrency or loop settings, It is time to look at the resources allocated for the job.
The parallel copy is orthogonal to Data Integration Units or Self-hosted IR nodes. It is counted across all the DIUs or Self-hosted IR nodes.
(Source)
You will need at least one DIU for each unit of parallelism. Check what the DIU is set to. If it is less than 10, set to 10 or make it empty to let ADF decide for you.
If any of the data stores are on-premise or otherwise using a Self-Hosted Integration Runtime, you can look into the max jobs per node and the number of nodes.
There are two copy activities, both DIUs are set to auto, and both activities are azure managed postgres to azure managed postgres (this is a schema migration).
@Robert Riley I recently learned something that may highlight the cause. Some versions of Postgres are single-threaded. Parallelism requires multi-threading. Since some version are single-threaded, they will be unable to copy in parallel.