Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,362 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EGC%3C/text%3E%3C/svg%3E)
Hi All,
Would a SQL Pool created as part of a Synapse Workspace perform any differently to an exiting SQL Pool from a different region? Documentation states that the SQL Pool uses Azure Storage but does not specifically state if that's server specific storage, or say the Data Lake that the workspace exists on.
Would a SQL Pool created as part of a workspace perform any better at ingestion data from the workspace data lake; than an existing SQL pool in the same region? Would that performance degrade if that existing SQL Pool was in a neighbouring region?

Welcome to the Microsoft Q&A platform.
There are two types on SQL Pools in Azure Synapse Analytics.
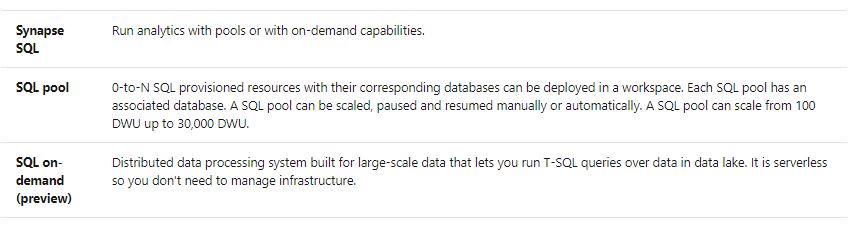
Q: What is a good use case for Synapse SQL pool?
SQL pool is the heart of your data warehouse needs. It's the leading data warehouse solution in price/performance. SQL pool is the industry-leading cloud data warehouse solution because you can:
Q: What is a good use case for SQL on-demand in Synapse?
SQL on-demand is a query service over the data in your data lake. It enables you to democratize access to all your data by providing a familiar T-SQL syntax to query data in place, without a need to copy or load data into a specialized store.
Use case examples include the following:
Reference: Azure Synapse SQL architecture
Hope this helps. Do let us know if you any further queries.
----------------------------------------------------------------------------------------
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.
@Grant Campbell Just checking in to see if the above answer helped. If this answers your query, do click “Accept Answer" and Up-Vote for the same. And, if you have any further query do let us know.
@Grant Campbell Following up to see if the above suggestion was helpful. And, if you have any further query do let us know.
Thank you for your answer but my question is more to do with the storage structure of a SQL Pool Gen2; if there's any difference between a Synapse workspace Synapse SQL Pool or an independent Synapse SQL Pool as to where data is stored. Documentation states that a Synapse SQL Pool & Synape Spark Pools share the same data lake when working together and I was wondering if that meant that a workspace SQL Pool 'lived' ontop of the workspace data lake. If so, this would provide a large performance uplift in ELT processes. While your answer is appreciated; I need a little more detail to satisfy my question.