Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
9,473 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EIM%3C/text%3E%3C/svg%3E)
Hi Team,
My Blob storage is partitioned by yyyy-mm-dd-hh and every half an hour a new CSV file is getting dumped. I am trying to trigger the Data Factory pipeline whenever a new file available in my blob storage account.
Target- Every time when it triggers my ADF pipeline I want to load only the new files but currently with my setting it is loading all the available files whenever it triggers the pipeline. One option was to trigger with a tumbling window, but then with that, I have to run the pipeline in a certain time interval, instead, I want to trigger my pipeline automatically whenever I get a new file in the container.
Please guide me, how can I trigger my ADF pipeline to load only the new files every time.

' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKM%3C/text%3E%3C/svg%3E)
Hi @Imran Mondal ,
As per my testing:
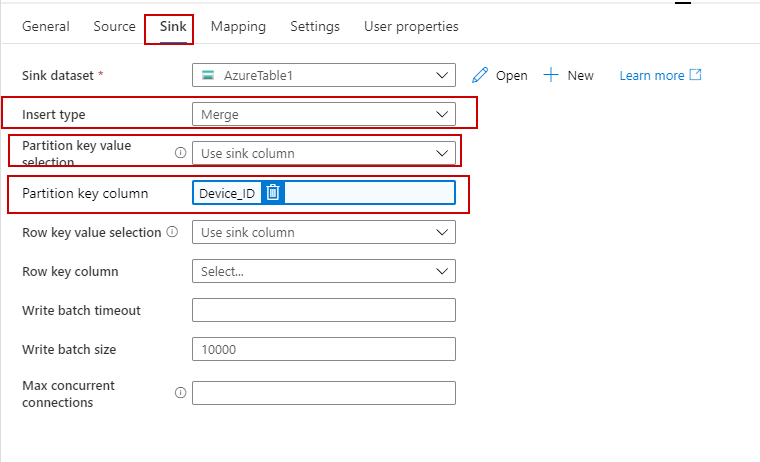
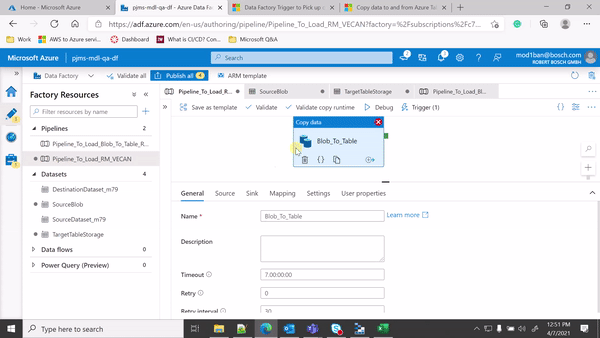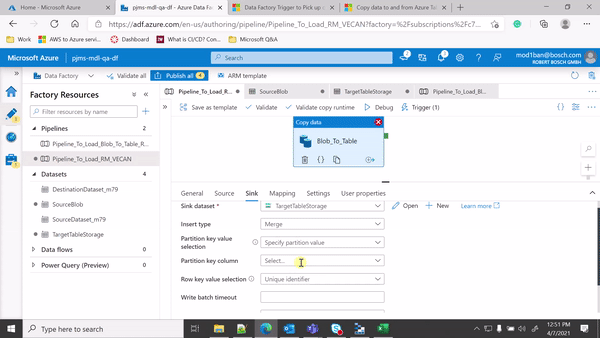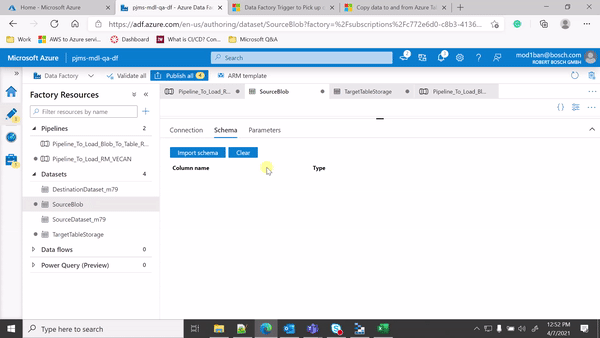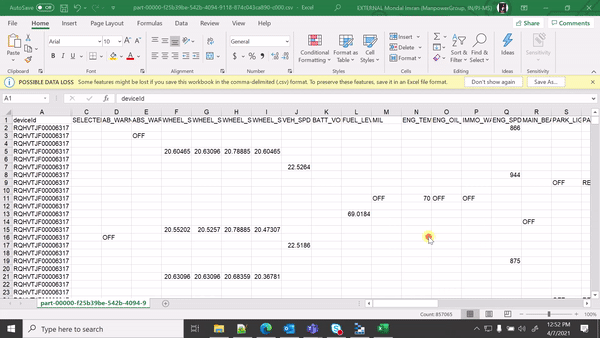
Output - In the table storage I want to load the files and if a new column is there it should load that column as well.
So, I had removed all the source schema and target schema, to load everything. The problem is in the source file I have a column named Device_ID, how can I use that
column as a partition key while loading to the Sink table.
If you source column changes then you can use the below setting in your copy activity. Which will insert new entities including new source columns/properties for the PartitionKey = Device_ID
For the second ask:
Second- All the column data type is string, how can change only one column data type, that is for data time column, keeping in mind the dynamic column in the source.
I don't think this can be done in the same copy activity. By default a property is created as type String, unless you specify a different type. To explicitly type a property, specify its data type by using the appropriate OData data type for an Insert Entity or Update Entity operation. For more information, see Inserting and Updating Entities.
Hope this answers your query.
Note: As the original query of this thread was answered it is always recommended to open new thread for new queries so that it will be easy for the community to find the helpful information :)
----------
Please don’t forget to Accept Answer and Up-Vote wherever the information provided helps you, this can be beneficial to other community members.
Hi @Imran Mondal ,
Just checking in to see if the above suggestion was helpful. If this answers your query, please do click “Accept Answer” and/or Up-Vote, as it might be beneficial to other community members reading this thread.
And, if you have any further query do let us know.
Thanks
Hi @Imran Mondal ,
We still have not heard back from you. Just wanted to check if the above suggestion was helpful? If it answers your query, please do click “Accept Answer” and/or Up-Vote, as it might be beneficial to other community members reading this thread.
And, if you have any further query do let us know.
Thank you

Have you checked Event based trigger already? With that you get options - As soon as file created/modified, pipeline will get triggered
https://learn.microsoft.com/en-us/azure/data-factory/how-to-create-event-trigger
----------
Please don't forget to Accept Answer and Up-vote if the response helped -- Vaibhav
Yes, I have tried event-based trigger only, If you see my attached screen recording it is an event-based trigger but it is picking all the files when a new blob is getting created and it is creating duplicates, every time the trigger runs it picks up the older files from earlier trigger as well. IHowever, I want it to pick up only the new files.

Hey @Imran ,
Please refer the below link:
https://stackoverflow.com/questions/66869516/azure-data-factory-storage-event-trigger-only-on-new-files/66869669#66869669
Event trigger would trigger an ADF whenever a new file is uploaded but you can use
parameter :

Or you can even use Getmetadata and identify the child items and then pick the file with the latest date to processs only the latest file which caused the ADF trigger
@Nandan Hegde I followed the above steps, But still, it is picking up all the files available in the folder every time it triggers based on blob created. Please suggest how to resolve this.
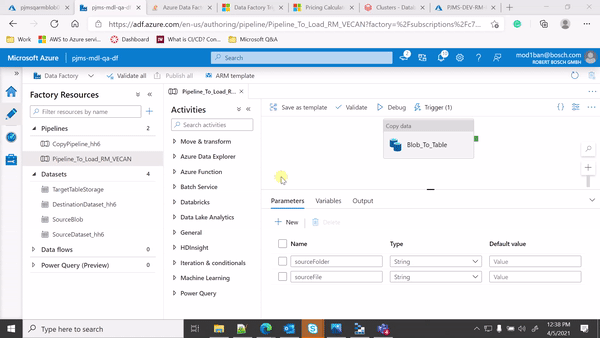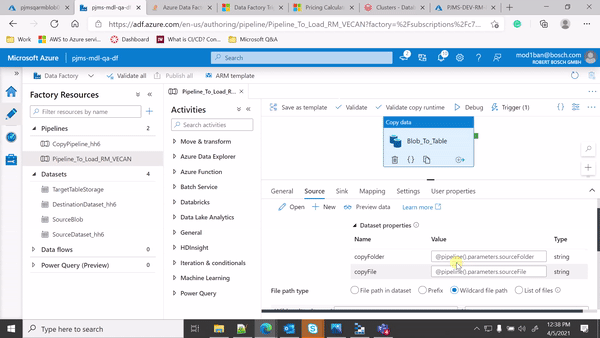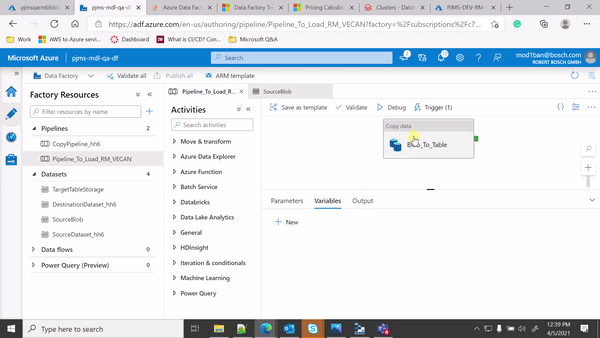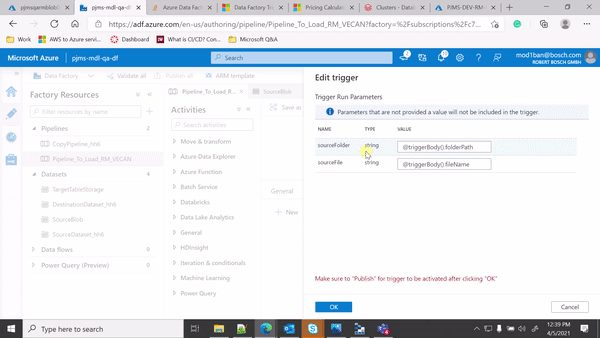
Hi @Imran Mondal ,
Thanks for sharing the GIF as it helps alot to identify the issue.
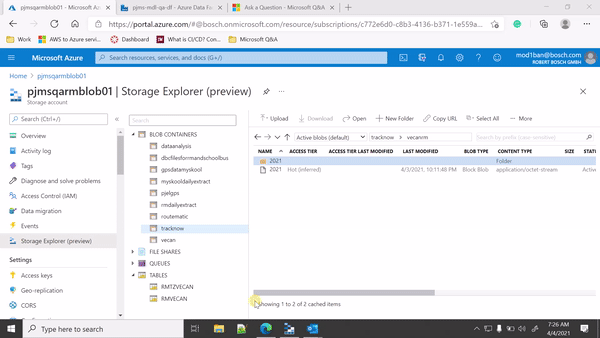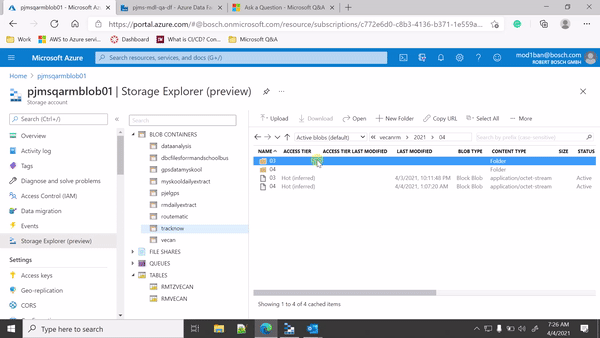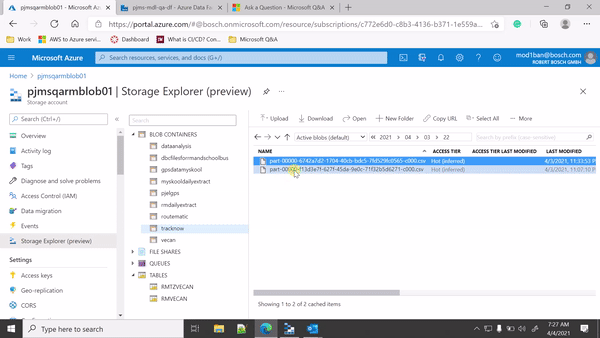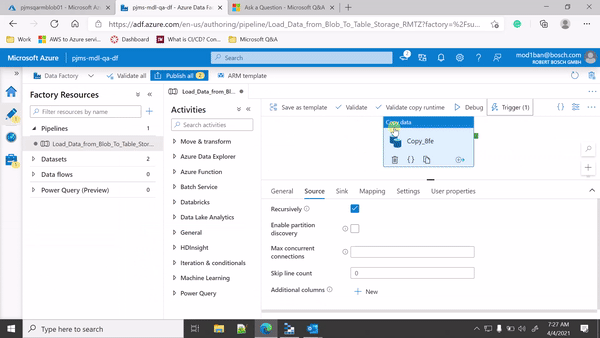
From the GIF, in your Copy activity source settings, you are using File path type = Wildcard file path because of which your pipeline is processing all files with *.csv.
Since you are mapping the folder path and source file details from event trigger parameters to pipeline parameters and then from pipeline parameters to your dataset parameters, could you please make sure that you use File path type = File path in dataset as shown below:
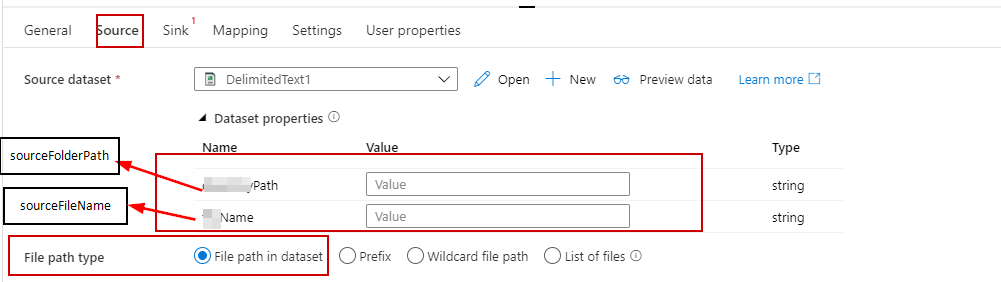
Also I have noticed that you have declared the dataset parameters and mapped the pipeline parameters to your dataset parameters in copy source settings but you haven't used the dataset parameters in your dataset connection settings -> File path. Please make sure to use the dataset parameters as dynamic expression in your dataset connection settings -> File Path as below:
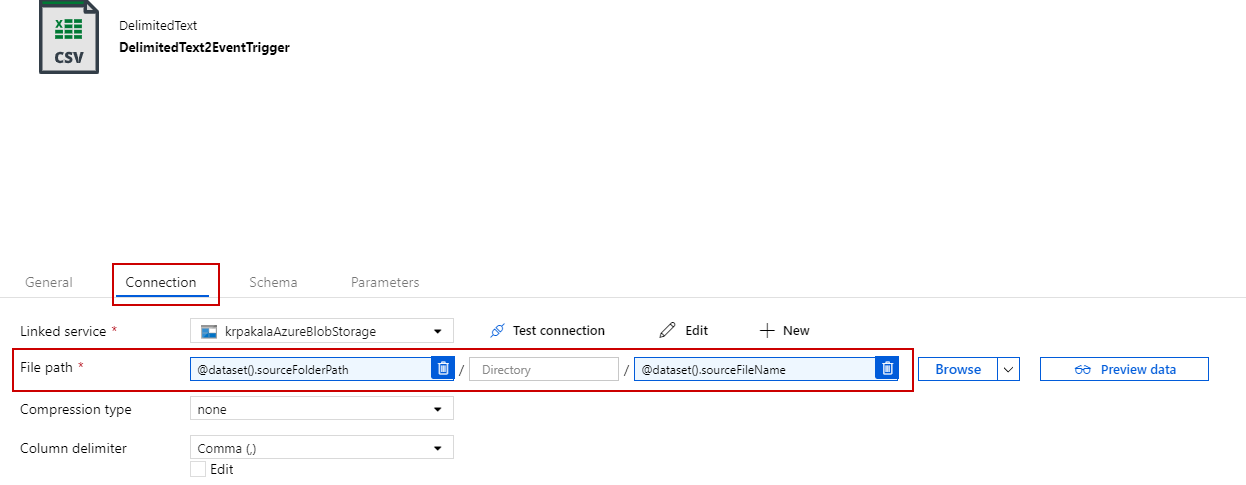
For more details, please refer to this GitHub issue: https://github.com/MicrosoftDocs/azure-docs/issues/42345
Note: In case if the dataset is being used by other pipelines, I would recommend to use a separate dataset for this pipeline.
Hope this helps to resolve your issue. Do let us know how it goes.
Thank you
----------
Please don’t forget to Accept Answer and Up-Vote wherever the information provided helps you, this can be beneficial to other community members.
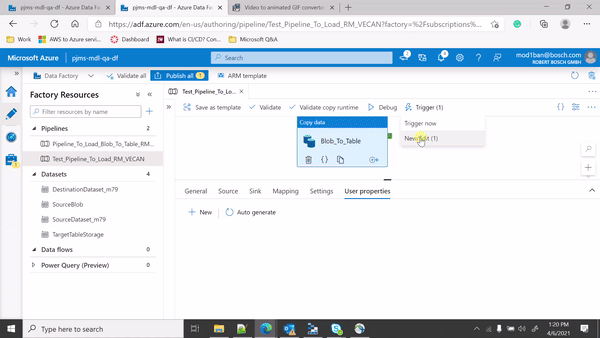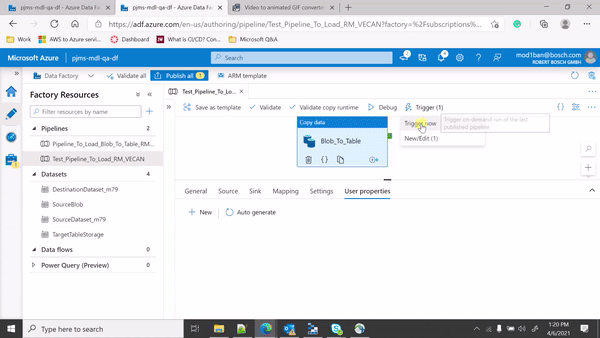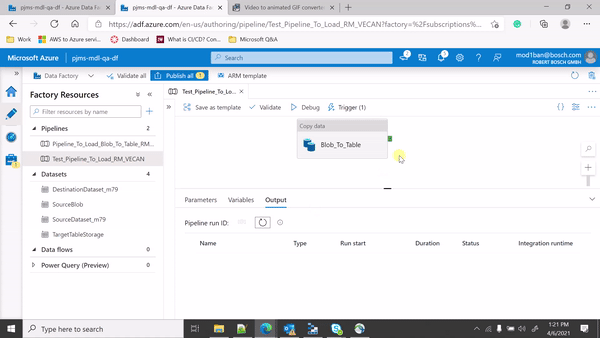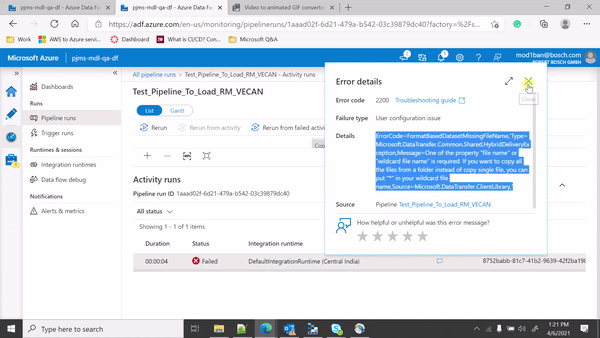
Hi @KranthiPakala-MSFT thank you for your reply. I have modified the pipeline and currently, it is throwing the below error.
Error
Notifications
Operation on target Blob_To_Table failed: ErrorCode=FormatBasedDatasetMissingFileName,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=One of the property "file name" or "wildcard file name" is required. If you want to copy all the files from a folder instead of copy single file, you can put "*" in your wildcard file name,Source=Microsoft.DataTransfer.ClientLibrary,'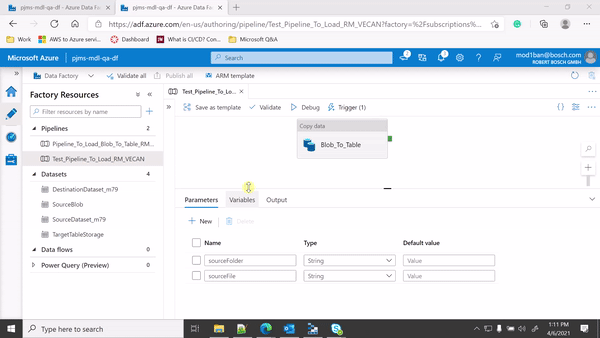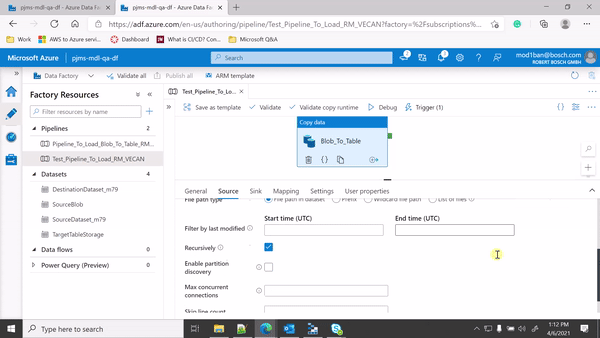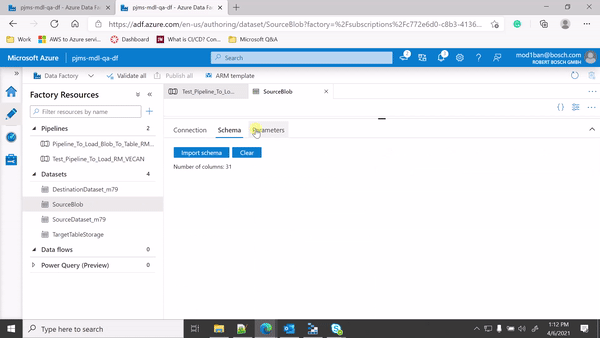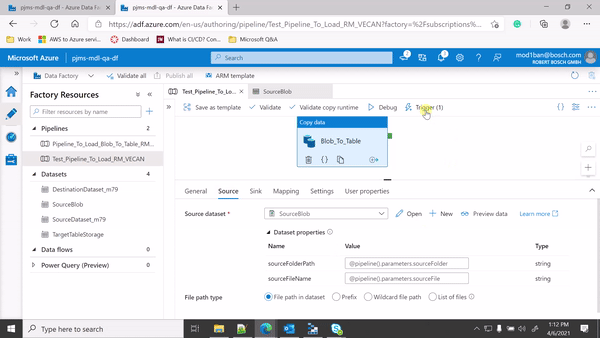
Hi Team,
Could anyone please help me resolve this ..
Hi @KranthiPakala-MSFT ,
Request you to please look into this once, Please.
Hi @Imran Mondal ,
Sorry for the delay. From the GIF you have provided your configuration looks good so far. But you are clicking on Trigger Now button for testing an Event Trigger.
In order to test your Event trigger and associated pipeline, please do upload a file to the blob location to which your event trigger is configured. As soon as your file/blob is uploaded your event trigger should fire and pass the folder path and file name as parameter values to the associated pipeline and you shouldn't see this error.
Could you please try uploading a file to your blob location rather than clicking Trigger now button and let us know how it goes.
We look forward to your confirmation.
Thanks
@Imran Mondal - If you would like to test your pipeline with Trigger now button then when you click on that button it will ask you to provide values for sourceFolder and sourceFile parameters and once your provide the input values for those parameters, your pipeline should run without issues but this will not confirm your event trigger testing. In order to confirm that your event trigger testing works fine please upload a file to the blob location to which your event trigger is looking for events.
Hope this clarifies. Do let us know how it goes.
Hi @KranthiPakala-MSFT thank you for your reply, It is working now.So now that job is running, one more problem we see is -
So, I had removed all the source schema and target schema, to load everything. The problem is in the source file I have a column named Device_ID, how can I use that column as a partition key while loading to the Sink table.
Second- All the column data type is string, how can change only one column data type, that is for data time column, keeping in mind the dynamic column in the source.
Please help me, If we can solve this, then we will not have to use any other tools to solve our use case. Please help me resolve this.
Hi @KranthiPakala-MSFT I know I am asking too much, But I am hoping you can surely help me with this.
I will wait for your reply.
Hi @KranthiPakala-MSFT please help me resolve this one last part..
Thank you in advance .
Hi @Imran Mondal ,
Sorry for the delay. This sounds a bit tricky but let me try it on my end to see if it is possible or not and will get back to you soon. As I am not an expert on Table storage I would like to give a try before I confirm anything. I would also request you to please try with insert type = merge and insert type = replace option in sink settings of your copy activity and see the behavior.
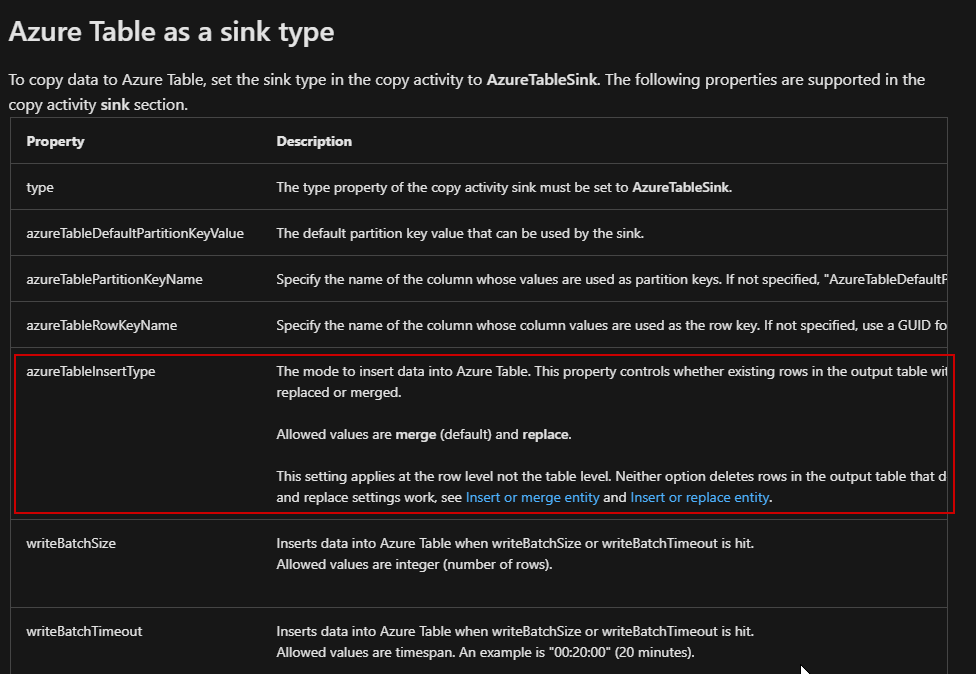
Reference doc: Azure Table as a sink type