Transact-SQL
A Microsoft extension to the ANSI SQL language that includes procedural programming, local variables, and various support functions.
4,551 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EE%3C/text%3E%3C/svg%3E)
Hi,
I have a requirement to get latest record based on a group and updated datetime.
Attached screenshot of the requirement:
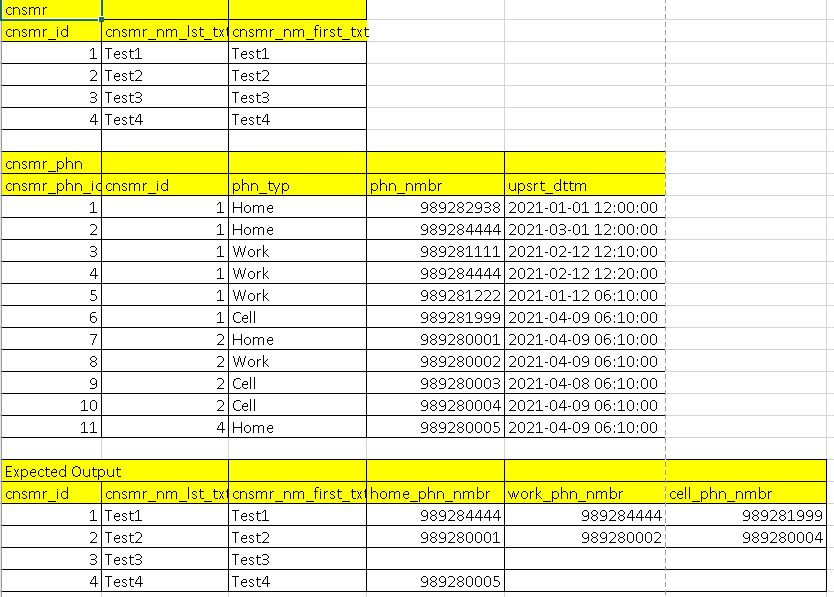
Query of the requirement:
--CNSMR
DECLARE @CNSMR TABLE(
cnsmr_id INT,
cnsmr_nm_lst_txt VARCHAR(100),
cnsmr_nm_first_txt VARCHAR(100)
)
INSERT INTO @CNSMR
SELECT '1','Test1','Test1' UNION ALL
SELECT '2','Test2','Test2' UNION ALL
SELECT '3','Test3','Test3' UNION ALL
SELECT '4','Test4','Test4'
--SELECT *FROM @CNSMR
--CNSMR_PHN
DECLARE @CNSMR_PHN TABLE(
cnsmr_phn_id INT,
cnsmr_id INT,
phn_typ VARCHAR(10),
phn_nmbr VARCHAR(20),
upsrt_dttm DATETIME
)
INSERT INTO @CNSMR_PHN
SELECT '1','1','Home','989282938','2021-01-01 12:00:00' UNION ALL
SELECT '2','1','Home','989284444','2021-03-01 12:00:00' UNION ALL
SELECT '3','1','Work','989281111','2021-02-12 12:10:00' UNION ALL
SELECT '4','1','Work','989284444','2021-02-12 12:20:00' UNION ALL
SELECT '5','1','Work','989281222','2021-01-12 06:10:00' UNION ALL
SELECT '6','1','Cell','989281999','2021-04-09 06:10:00' UNION ALL
SELECT '7','2','Home','989280001','2021-04-09 06:10:00' UNION ALL
SELECT '8','2','Work','989280002','2021-04-09 06:10:00' UNION ALL
SELECT '9','2','Cell','989280003','2021-04-08 06:10:00' UNION ALL
SELECT '10','2','Cell','989280004','2021-04-09 06:10:00' UNION ALL
SELECT '11','4','Home','989280005','2021-04-09 06:10:00'
--SELECT *FROM @CNSMR_PHN
--EXPECTED OUPTUT
SELECT '1' cnsmr_id,'Test1' cnsmr_nm_lst_txt,'Test1' cnsmr_nm_first_txt,'989284444' home_phn_nmbr,'989284444' work_phn_nmbr,'989281999' cell_phn_nmbr UNION ALL
SELECT '2','Test2','Test2','989280001','989280002','989280004' UNION ALL
SELECT '3','Test3','Test3','','','' UNION ALL
SELECT '4','Test4','Test4','989280005','',''
Requirement is there are cnsmr and cnsmr_phn table and I need to get latest phone number for each type for each cnsmr_id based on upsrt_dttm, if there is no phone number for a consumer/type then populate blank but every cnsmr_id should be in the output.
This has to be written without cte as complex query is not supported by tool that I am using
I have written like this:
SELECT c.cnsmr_id,
c.cnsmr_nm_lst_txt,
c.cnsmr_nm_first_txt,
ISNULL(cpH.home_phn_nmbr,'') home_phn_nmbr,
ISNULL(cpW.work_phn_nmbr,'') work_phn_nmbr,
ISNULL(cpC.cell_phn_nmbr,'') cell_phn_nmbr
FROM @cnsmr c
LEFT JOIN (
SELECT cp.cnsmr_id,cp.phn_nmbr home_phn_nmbr,ROW_NUMBER() OVER(PARTITION BY cp.cnsmr_id,cp.phn_typ ORDER BY upsrt_dttm DESC) ranking1
FROM @cnsmr_phn cp
WHERE cp.phn_typ = 'HOME'
) cpH ON c.cnsmr_id = cpH.cnsmr_id
AND cpH.ranking1 = 1
LEFT JOIN (
SELECT cp.cnsmr_id,cp.phn_nmbr work_phn_nmbr,ROW_NUMBER() OVER(PARTITION BY cp.cnsmr_id,cp.phn_typ ORDER BY upsrt_dttm DESC) ranking1
FROM @cnsmr_phn cp
WHERE cp.phn_typ = 'WORK'
) cpW ON c.cnsmr_id = cpW.cnsmr_id
AND cpW.ranking1 = 1
LEFT JOIN (
SELECT cp.cnsmr_id,cp.phn_nmbr cell_phn_nmbr,ROW_NUMBER() OVER(PARTITION BY cp.cnsmr_id,cp.phn_typ ORDER BY upsrt_dttm DESC) ranking1
FROM @cnsmr_phn cp
WHERE cp.phn_typ = 'CELL'
) cpC ON c.cnsmr_id = cpC.cnsmr_id
AND cpC.ranking1 = 1
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EEM%3C/text%3E%3C/svg%3E)
Do you have anyupdate?
Please also remember to accept the answers if they helped. Your action would be helpful to other users who encounter the same issue and read this thread.

This seems to work:
select
c.cnsmr_id,
c.cnsmr_nm_lst_txt,
c.cnsmr_nm_first_txt,
isnull(hp.phn_nmbr, '') as home_phn_nmbr,
isnull(wp.phn_nmbr, '') as work_phn_nmbr,
isnull(cp.phn_nmbr, '') as cell_phn_nmbr
from @CNSMR c
outer apply (select top(1) * from @CNSMR_PHN where phn_typ = 'Home' and cnsmr_id = c.cnsmr_id order by upsrt_dttm desc) hp
outer apply (select top(1) * from @CNSMR_PHN where phn_typ = 'Work' and cnsmr_id = c.cnsmr_id order by upsrt_dttm desc) wp
outer apply (select top(1) * from @CNSMR_PHN where phn_typ = 'Cell' and cnsmr_id = c.cnsmr_id order by upsrt_dttm desc) cp
order by c.cnsmr_id
Using PIVOT:
;
with N as
(
select *, row_number() over (partition by cnsmr_id, phn_typ order by upsrt_dttm desc) rn
from @CNSMR_PHN
)
select c.cnsmr_id, c.cnsmr_nm_lst_txt, c.cnsmr_nm_first_txt,
isnull([Home], '') as home_phn_nmbr,
isnull([Work], '') as work_phn_nmbr,
isnull([Cell], '') as cell_phn_nmbr
from ( select cnsmr_id, phn_typ, phn_nmbr from N where rn = 1) t
pivot ( max(phn_nmbr) for phn_typ in ([Home], [Work], [Cell]) ) p
right outer join @CNSMR c on c.cnsmr_id = p.cnsmr_id
order by c.cnsmr_id
Hi @Eshwar ,
To simplify the code, the most convenient way seems to be to use cte, but unfortunately you want a method other than cte.
In addition, your code seems to have no performance issues. So there is no need to optimize.
If you have any question, please feel free to let me know.
Regards
Echo
If the answer is helpful, please click "Accept Answer" and upvote it.
Note: Please follow the steps in our documentation to enable e-mail notifications if you want to receive the related email notification for this thread.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJC%3C/text%3E%3C/svg%3E)
> have a requirement to get latest record [sic: rows are not records] based on a group and updated datetime. <<
What you have posted is some of the worst SQL or attempted SQL I've seen a long time. I'm going to rewrite it and then try to explain just a few of your mistakes. You've obviously never had any exposure or training to RDBMS or SQL.
>Attached screenshot of the requirement: <<
We don't post pictures in SQL forums. We post actual code that people can compile. Does your boss make you work from pictures? You don't seem to understand that a table by definition, must contain a key. This is usually covered in the first week when RDBMS class. An identifier cannot be an integer by definition. Identifiers are on a nominal scale (do you understand scales and measurements?). What I found interesting was you are using table names that are five or six letters long. 50 years ago, when I was a Fortran programmer, the compiler would only let us use six-letter names! And you even keep things in uppercase letters, just like we had to on punch cards! I'm going to rewrite the mess you posted, discuss some, sorry I can't cover all of the problems, and make a recommendation that you quit writing pointer chains using integers.
CREATE TABLE Customers
(customer_id CHAR(16) NOT NULL PRIMARY KEY,
customer_nm_lst VARCHAR(20) NOT NULL,
customer_nm_first VARCHAR(20) NOT NULL);
Notice I have added a primary key. A key is not an option! It is the definition of what makes a table! But you're still writing code for punchcards. I picked a 16 character string for my customer identifier. Identifiers have to be characters because they are never numerics. This is the length of most credit card numbers so it would seem to be a good choice. I also picked the length of the name columns based on international postal standards; where did you get 100 when you declare these columns? Surely you would not just make them up without at least a little research! Putting that silly "_txt" postfix is a design flaw so bad it's called a tibble. It refers to putting metadata in the data element names.
Your insertion statement is a syntax that Microsoft got from Sybase about 40 years ago. It will not port, it is not standard. For several years, Microsoft has supported the ANSI/ISO standard syntax for table construction in an insertion statement. Why don't you start using it? Also, in your original posting before I corrected it, you are inserting integers as strings! You just want to increase the overhead? Here's the skeleton of the current syntax
INSERT INTO Customers
VALUES (...), (...), (...);
The second table needs to reference the first table. This ability to reference things instead of using pointer chains is what the R in RDBMS stands for
CREATE TABLE Customer_Phones
(customer_id CHAR(16) NOT NULL
REFERENCES Customers(customer_id),
phone_type CHAR(4) NOT NULL
CHECK (phone_type IN ('work','cell','home')),
activation_timestamp DATETIME2(0) DEFAULT CURRENT_TIMESTAMP NOT NULL,
phone_nbr CHAR(20) NOT NULL, --- enforce international standards
PRIMARY KEY (customer_id, phone_type, activation_timestamp));
Please notice the references clause. This is not the same as the pointer chains that you been building with INTEGERs. The SQL engine will enforce the relationship between the referenced and referencing tables. Again, this is a fundamental concept in RDBMS and is optional subclauses to maintain the referential integrity of the schema.
Please notice the CHECK() clause on the phone type. This is one of the most powerful things in SQL.
The activation timestamp is using the DATETIME2(0) data type, which corresponds to the ANSI/ISO standard timestamp data type. This is a bit of local dialect from Microsoft. The default clause guarantees that it's always filled with the current timestamp. Good SQL programmers make the database engine provide all the defaults, constraints and CHECK()s that it can in the DDL, one way, one time, and always consistent.
You need to look up the international standards for telephone numbers and use them in a CHECK() constraint.
The declaration of the primary key guarantees that you don't have duplicates. But now we have a problem because of the timestamp. I can declare an activation time for a phone in the future; do you want to count that as the most recent even though it can't be used? I'm going to assume so. Another feature of SQL that is different from the Fortran that you were writing, is a feature called a VIEW
CREATE VIEW Current_Phones
AS
SELECT customer_id, phone_type, activation_timestamp, phone_nbr,
MAX(activation_timestamp) OVER (PARTITION BY customer_id, phone_type) AS current_activation_timestamp
FROM Customers
WHERE current_activation_timestamp = activation_timestamp;
> Requirement is there are customer and customer_phone table and I need to get latest phone number for each type for each customer_id based on activation_ timestamp, if there is no phone number for a consumer/type then populate blank but every customer_id should be in the output. <<
SELECT C.customer_id, C.phone_type, C.phone_nbr,
FROM Customers AS C
LEFT OUTER JOIN
Current_Phones AS P
ON C.customer_id = P.customer_id
AND C.phone_type = P.phone_type;
I did this very quickly, and have not really tested it.