Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
1,916 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKK%3C/text%3E%3C/svg%3E)
Hi
We are currently creating CI /CD pipeline for ADF in Azure Devops and below are the steps that we are following,
We have succeeded in these two, however currently we are integrating ADF with Azure Data bricks. We have created the linked service for the Databricks and couldn't find the required parameters in ARM template for Data bricks to override in release pipelines. But we ultimately found some options from documentation about two approaches about parameterization.
Can you please help me to understand which is the best approach as in to avoid any manual intervention and automate ADF - databricks linked services in CI CD.
Also please be noted - we are not going to use existing interactive cluster in Data bricks but create new cluster every time on releases. Give us a pointer if there are any documentation to it.
Many Thanks,
Karthik
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
@Karthik Karunanithy did my responses help? If it solved your issue, please mar as accepted answer, otherwise tell me how I may better assist.
Oh, I see. I was confused before, because the New Cluster option, makes a new cluster every pipeline activity run. Or so I thought, I didn't explicitly look into that.
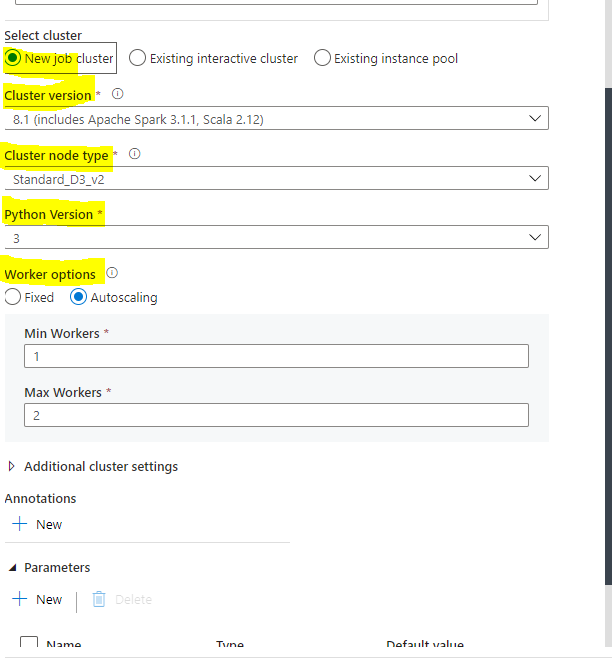
I have been able to parameterize most of the highlighted. The Python version seems to be an oddball.
{
"name": "AzureDatabricks1",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"parameters": {
"version": {
"type": "string"
},
"nodeType": {
"type": "string"
},
"driverType": {
"type": "string"
}
},
"annotations": [],
"type": "AzureDatabricks",
"typeProperties": {
"domain": "https://XXXX.azuredatabricks.net",
"newClusterNodeType": "@linkedService().nodeType",
"newClusterNumOfWorker": "1",
"newClusterSparkEnvVars": {
"PYSPARK_PYTHON": "/databricks/python3/bin/python3"
},
"newClusterVersion": "@linkedService().version",
"newClusterInitScripts": [],
"newClusterDriverNodeType": "@linkedService().driverType",
"encryptedCredential": XXXX
}
}
}
Note the Python version is under "newClusterSparkEnvVars" when choosing 3 (above). When choosing 2 (below) it is not present. Also below note the number of workers when I set the autoscaling min 2 max 4. This means the dynamic content for scaling should be a string literal of form min:max
{
"name": "AzureDatabricks1",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"parameters": {
"version": {
"type": "string"
},
"nodeType": {
"type": "string"
},
"driverType": {
"type": "string"
},
},
"annotations": [],
"type": "AzureDatabricks",
"typeProperties": {
"domain": "https://XXXX.azuredatabricks.net",
"newClusterNodeType": "@linkedService().nodeType",
"newClusterNumOfWorker": "2:4",
"newClusterVersion": "@linkedService().version",
"newClusterInitScripts": [],
"newClusterDriverNodeType": "@linkedService().driverType",
"encryptedCredential": XXXX
}
}
}
Hello @Karthik Karunanithy and welcome to Microsoft Q&A.
Please tell me if I understand correctly, as follows:
When you do a deployment, you update both Databricks and Data Factory. Every deployment, you create a new cluster in Databricks. You want help making it so the Data Factory's Linked Service to Databricks points to the new cluster.
There is a third option I would like to inform you of: Parameterizing the linked service itself. This lets you give the clusterId at runtime. This can also be combined with global parameters if you like.
Depending upon what you do for a default parameter, you may need to adjust the activity. If the default value is left blank, you will need to pass a real value through the pipeline.
{
"name": "AzureDatabricks1",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"parameters": {
"clusterId": {
"type": "string",
"defaultValue": "BlankOrDefaultClusterIDOrGlobalParam"
}
},
"annotations": [],
"type": "AzureDatabricks",
"typeProperties": {
"domain": XXXX,
"existingClusterId": "@linkedService().clusterId",
"encryptedCredential": XXXX
}
}
}
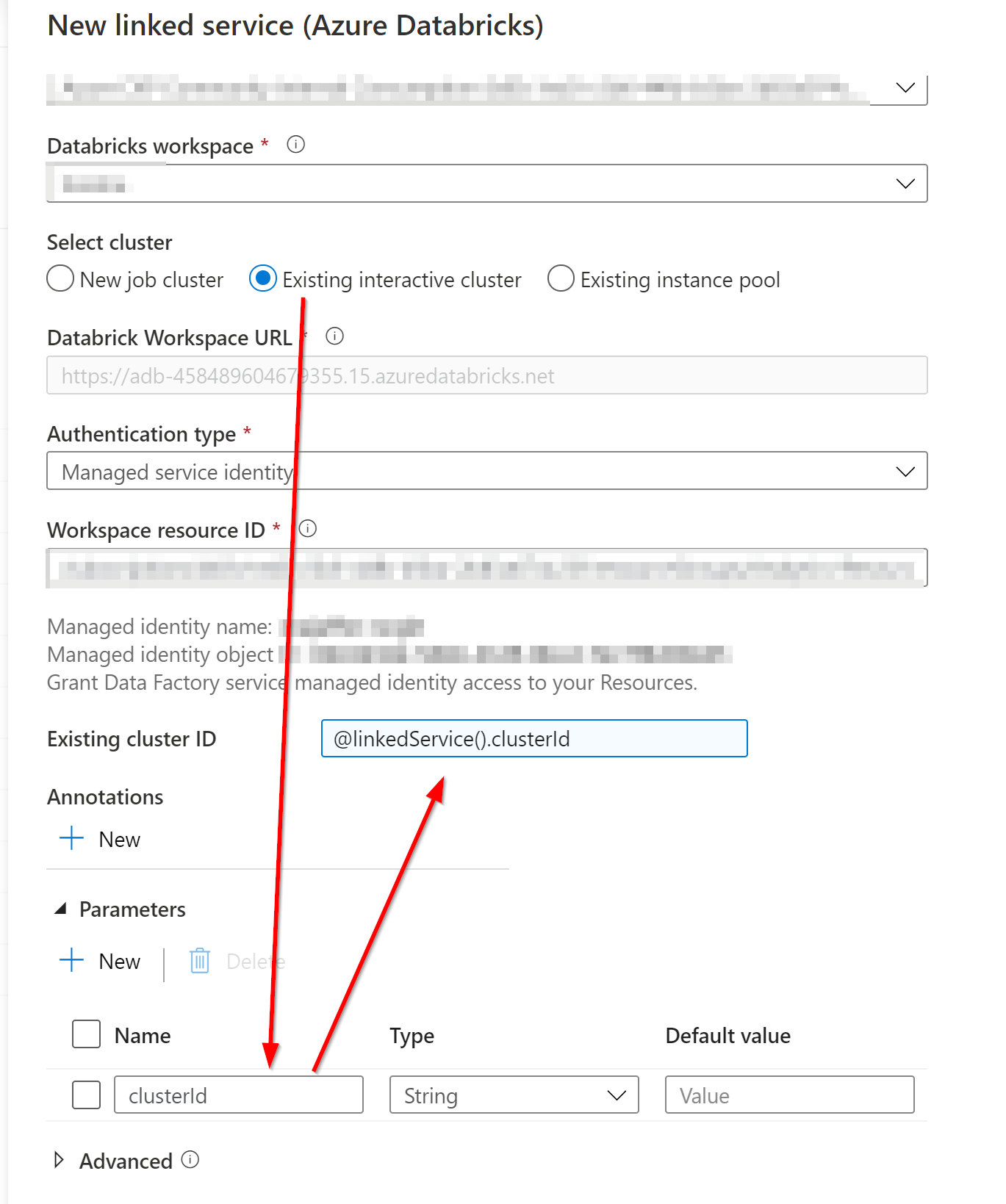
Hi @MartinJaffer-MSFT ,
Thanks for responding back to the query. Actually I have tried that option with existing interactive cluster, the actual requirement is to create new cluster every time when we promote the databricks changes to higher environments.
eg: Changes from DEV env -> Release to UAT -> Create a new cluster and deploy the changes.
We were looking at options to parameterize the below highlighted when we use New Job Cluster option.
Also, can you please confirm on this, if we go into the approach of using arm-template-definition.json in our repo - do we need to keep updating this file when we create a new linked service every time in the ADF?