Azure SQL Database
An Azure relational database service.
5,120 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMD%3C/text%3E%3C/svg%3E)
When running the following:
%%spark
val df = spark.read.sqlanalytics("tailsql1.dbo.indu_history_staging")
df.write.mode("overwrite").saveAsTable("default.t1")
To read a table from dedicated SQL pool in Azure Synapse Analytics, I get the following error:
Error: org.apache.spark.SparkException: Job aborted.
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:198)
at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:159)
at org.apache.spark.sql.execution.datasources.DataSource.writeAndRead(DataSource.scala:502)
at org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand.saveDataIntoTable(createDataSourceTables.scala:217)
at org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand.run(createDataSourceTables.scala:176)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:104)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:102)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.doExecute(commands.scala:122)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:134)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:130)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:158)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:155)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:130)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:108)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:106)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:682)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:682)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:87)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:134)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:77)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:682)
at org.apache.spark.sql.DataFrameWriter.createTable(DataFrameWriter.scala:480)
at org.apache.spark.sql.DataFrameWriter.saveAsTable(DataFrameWriter.scala:459)
at org.apache.spark.sql.DataFrameWriter.saveAsTable(DataFrameWriter.scala:415)
... 52 elided
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 6.0 failed 4 times, most recent failure: Lost task 0.3 in stage 6.0 (TID 8, 07ef16759c6d4267b329d7a7e1995a0d005b8886402, executor 1): org.apache.spark.SparkException: Task failed while writing rows.
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:257)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:170)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:169)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:409)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:415)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.spark.sql.execution.datasources.SchemaColumnConvertNotSupportedException
at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.constructConvertNotSupportedException(VectorizedColumnReader.java:250)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.decodeDictionaryIds(VectorizedColumnReader.java:343)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.readBatch(VectorizedColumnReader.java:191)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedParquetRecordReader.nextBatch(VectorizedParquetRecordReader.java:261)
at com.microsoft.spark.sqlanalytics.read.SQLAnalyticsInputPartitionReader.next(SQLAnalyticsInputPartitionReader.scala:53)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.datasourcev2scan_nextBatch_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:244)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:242)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:248)
... 10 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1896)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1884)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1883)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1883)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:930)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:930)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:930)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2117)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2066)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2055)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:739)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2111)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:167)
... 76 more
Caused by: org.apache.spark.SparkException: Task failed while writing rows.
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:257)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:170)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:169)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:409)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:415)
... 3 more
Caused by: org.apache.spark.sql.execution.datasources.SchemaColumnConvertNotSupportedException
at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.constructConvertNotSupportedException(VectorizedColumnReader.java:250)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.decodeDictionaryIds(VectorizedColumnReader.java:343)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.readBatch(VectorizedColumnReader.java:191)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedParquetRecordReader.nextBatch(VectorizedParquetRecordReader.java:261)
at com.microsoft.spark.sqlanalytics.read.SQLAnalyticsInputPartitionReader.next(SQLAnalyticsInputPartitionReader.scala:53)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.datasourcev2scan_nextBatch_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:244)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:242)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:248)
... 10 more

Hello @Michael Drozdov ,
Welcome to the Microsoft Q&A platform.
Are you overwriting the data to the same partition with different schema? That will cause a problem.
I’m able to successfully load the data from Dedicated SQL pool.
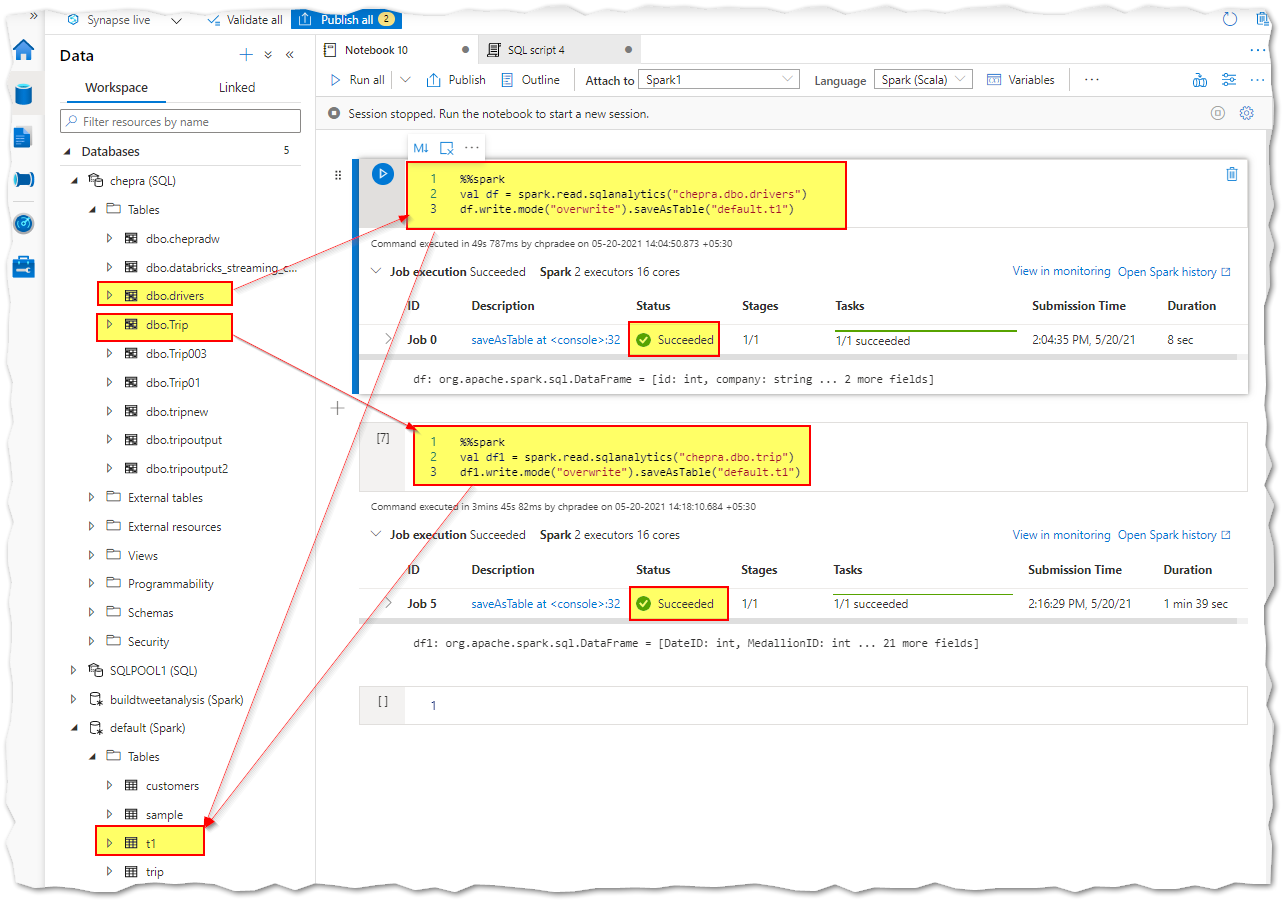
Hope this helps. Do let us know if you any further queries.
------------
Please don’t forget to Accept Answer and Up-Vote wherever the information provided helps you, this can be beneficial to other community members.
Hello @Michael Drozdov ,
Just checking in to see if the above answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.
Hello @Michael Drozdov ,
Following up to see if the above suggestion was helpful. And, if you have any further query do let us know.
Take care & stay safe!
---------------------------------------------------------------------------
Please "Accept the answer" if the information helped you. This will help us and others in the community as well.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMA%3C/text%3E%3C/svg%3E)
@PRADEEPCHEEKATLA-MSFT , to expand on the scenario, try having a date data type in SQL Pool and they try read that data into a notepad, see if you can read it. I have a customer who is facing an issue reading data from SQL Pool within a notebook, with the similar error message:
org.apache.spark.sql.execution.datasources.SchemaColumnConvertNotSupportedException
We likely have a limitation working with Date data type from SQL pool using the spark connector.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ETS%3C/text%3E%3C/svg%3E)
I had a similar issue with Date data type yesterday and thus ran into this post in search of a resolution. It worked fine when I changed them from Date to Datetime. I know this is not a long term solution but it worked. continuing my search for a better solution.
Hello @Tony S. Semaan ,
Since this thread is too old, I would recommend creating a new thread on the same forum with as much details about your issue as possible. That would make sure that your issue has better visibility in the community.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPC%3C/text%3E%3C/svg%3E)
I initially gave up on solving this and assumed something was going on behind the scenes.
So yes, I also am experiencing the same issue with Date columns in Spark - DateTime works fine.