Azure Container Registry
An Azure service that provides a registry of Docker and Open Container Initiative images.
383 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAN%3C/text%3E%3C/svg%3E)
Hi,
First I tried from the UI in Azure portal. I went through however after that I started seeing this error message:

But when I check the container registry everything looks normal.
Does this mean the AKS is upgraded or not?
I also see this in the CL


@Arash Niknafs Any update on the issue?
Please "Accept as Answer" if below helped so it can help others in community looking for help on similar topics.
Thanks
@Arash Niknafs Thank you for your query!!!
Your AKS is not upgraded yet since if it was updates the result would be something as below same is mentioned here
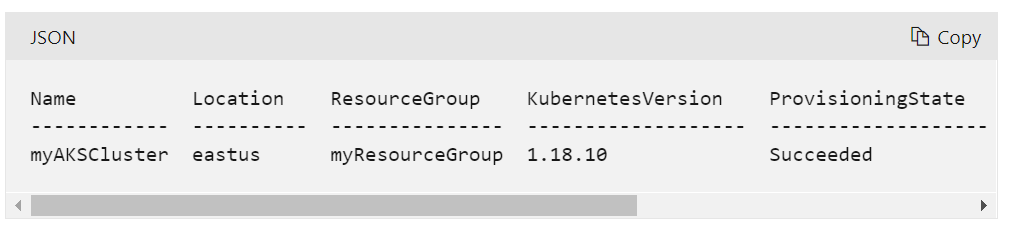
Until the cluster is out of failed state, upgrade and scale operations won't succeed.
As mentioned here below steps might help:
Common root issues and resolutions include:
Once the underlying cause for upgrade failure is resolved, your cluster should be in a succeeded state. Once a succeeded state is verified, retry the original operation.
Also you can ensure that any PodDisruptionBudgets (PDBs) is allowed for at least 1 pod replica to be moved at a time otherwise the drain/evict operation will fail. If the drain operation fails, the upgrade operation will fail by design to ensure that the applications are not disrupted. Please correct what caused the operation to stop (incorrect PDBs, lack of quota, and so on) and re-try the operation
Also, you can check activity logs of the AKS cluster. There will be a failed upgrade. The error message might help us to determine the correct reason as well if above is not the case.
Hope it helps!!!
Please "Accept as Answer" if it helped so it can help others in community looking for help on similar topics.