Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
1,904 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAR%3C/text%3E%3C/svg%3E)
Hello There,
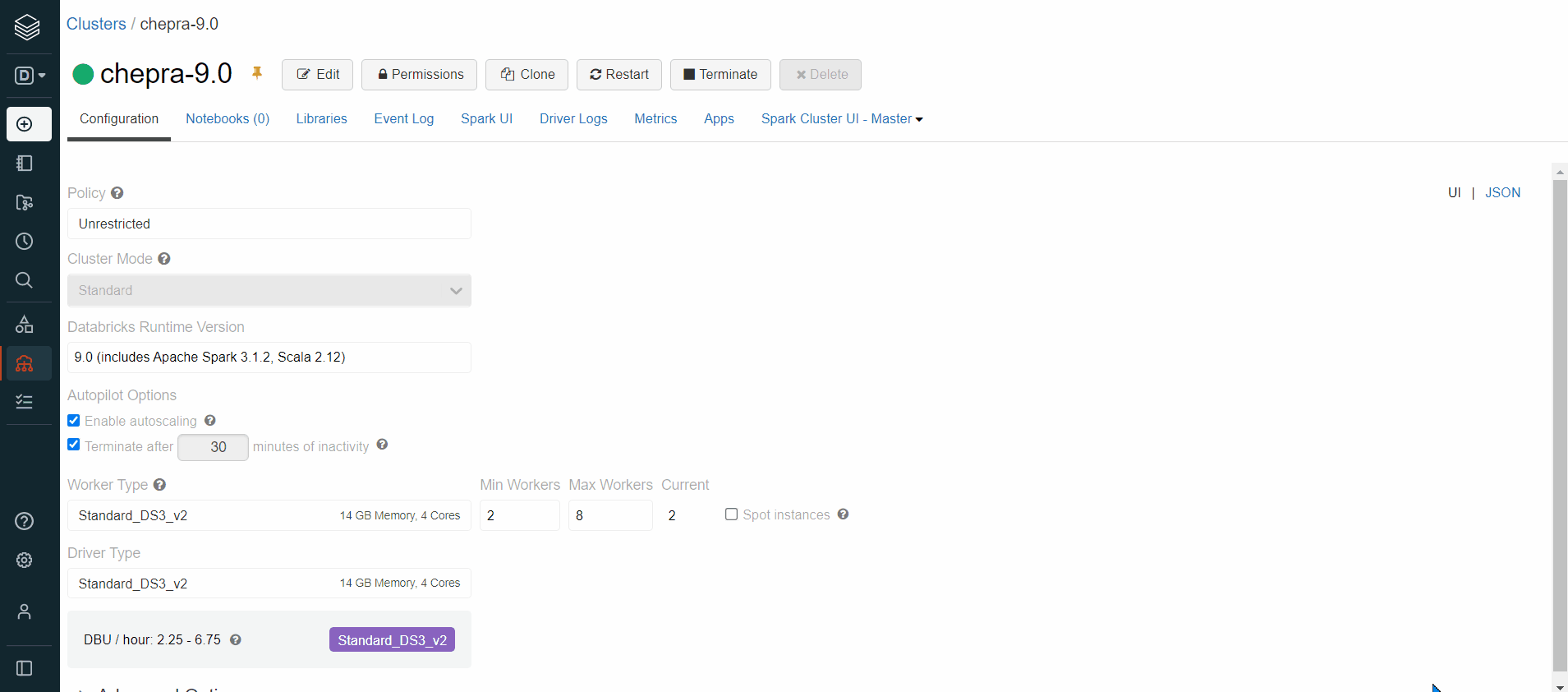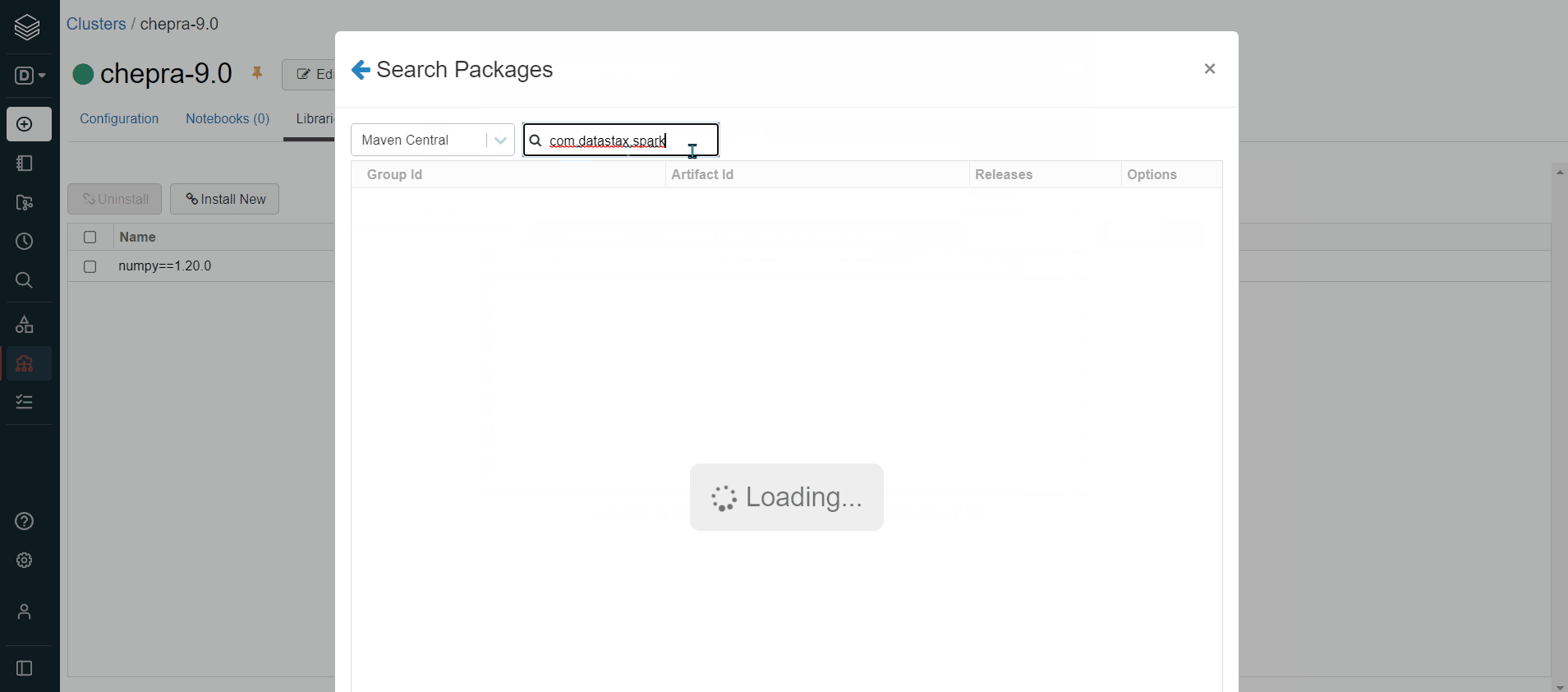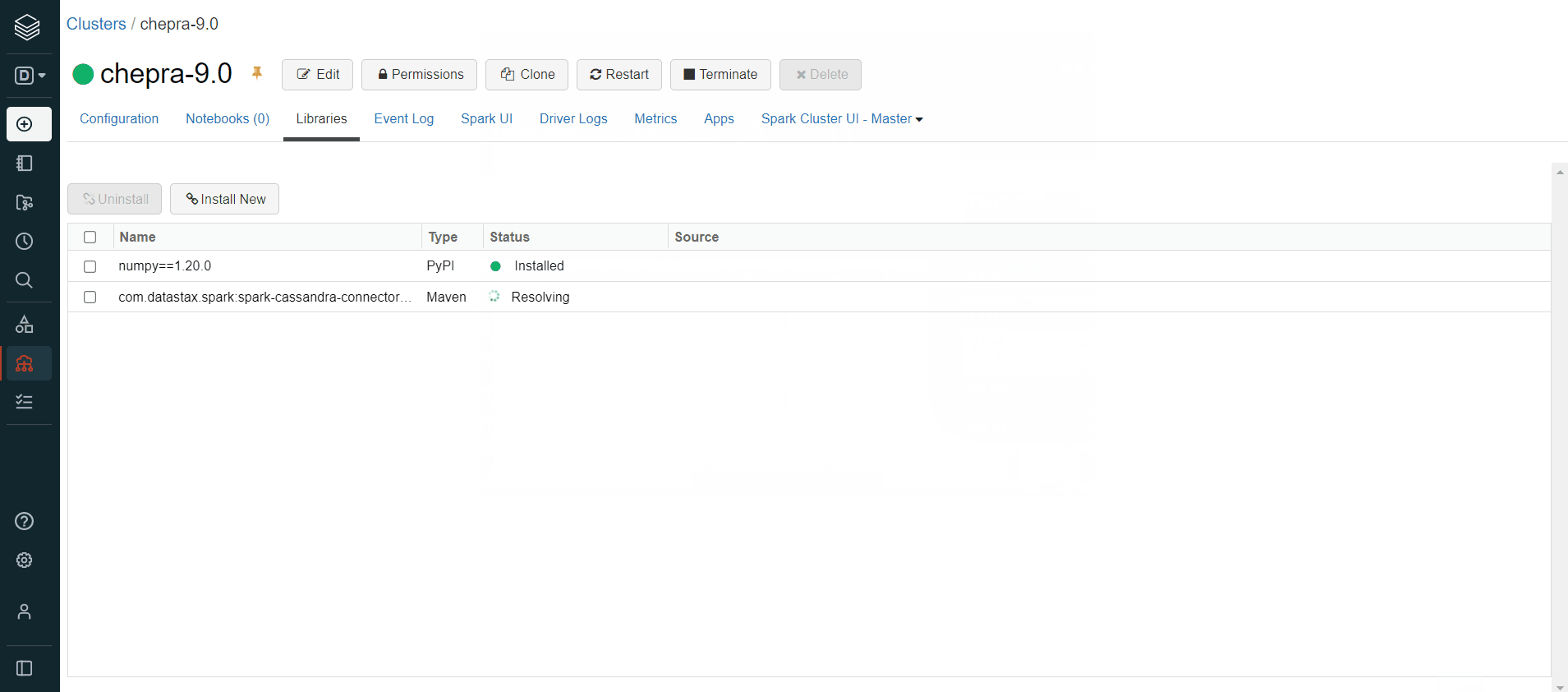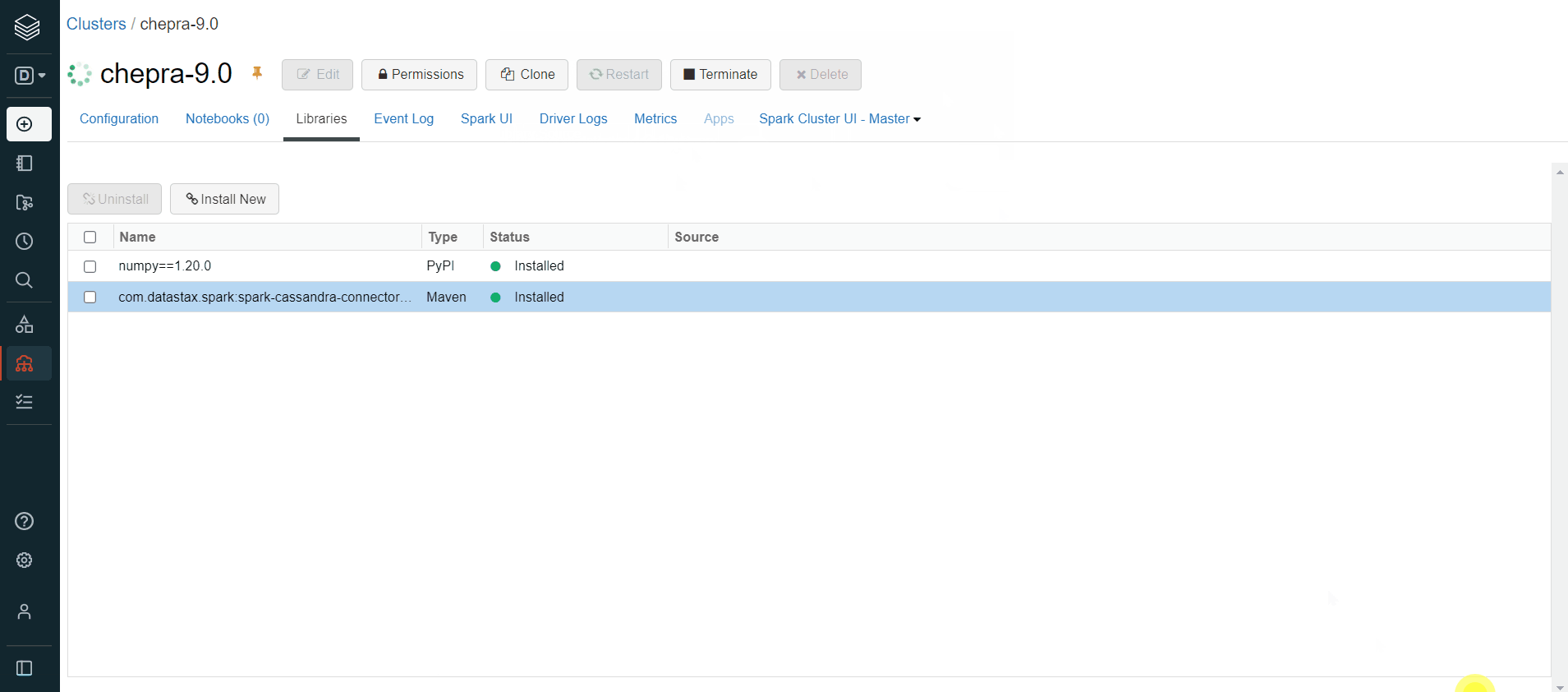
I am trying to upgrade my cluster from runtime 6.4 to 9.0 or 10.0. I am able to do that successfully but I have a notebook that is supposed read data from Cosmos DB (Cassandra) to load into databricks. The jobs runs fine with 6.4 but fails in 9.0 or 10.0.
Considering that fact that upgrading requires, new driver and connector version. I tried to install the libraries from maven and also tried to download jar files from third party sites but I believe I couldn't get to the right connector / driver. Require guidance in getting the right libraries for 9.0 or 10.0 runtime.
Below is the code that I am using:
// To import all the cassandra tables
import org.apache.spark.sql.cassandra._
//Spark connector
import com.datastax.spark.connector._
//import com.datastax.spark.connector._
import com.datastax.spark.connector.cql.CassandraConnector
//import com.datastax.oss.driver.api.core._
//CosmosDB library for multiple retry
import com.microsoft.azure.cosmosdb.cassandra
import org.apache.spark.sql.functions._
import spark.sqlContext.implicits._
import org.apache.spark.storage.StorageLevel
spark.conf.set("spark.cassandra.connection.host","<test>")
spark.conf.set("spark.cassandra.connection.port","<test>")
spark.conf.set("spark.cassandra.connection.ssl.enabled","true")
spark.conf.set("spark.cassandra.auth.username","<test>")
spark.conf.set("spark.cassandra.auth.password","<test>")
spark.conf.set("spark.cassandra.connection.factory", "com.microsoft.azure.cosmosdb.cassandra.CosmosDbConnectionFactory")
spark.conf.set("spark.cassandra.output.batch.size.rows", "1")
spark.conf.set("spark.cassandra.connection.connections_per_executor_max", "10")
spark.conf.set("spark.cassandra.output.concurrent.writes", "1000")
spark.conf.set("spark.cassandra.concurrent.reads", "512")
spark.conf.set("spark.cassandra.output.batch.grouping.buffer.size", "1000")
spark.conf.set("spark.cassandra.connection.keep_alive_ms", "600000000")
spark.conf.set("spark.sql.legacy.allowCreatingManagedTableUsingNonemptyLocation","true")
val paymentdetailsDF = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(Map( "table" -> "test_table", "keyspace" -> "test_keyspace"))
.load

Hello @Amrit Raj Kalashakum ,
Welcome to the Microsoft Q&A platform.
To resolve this issue, make sure you have installed the required dependencies (com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.1.0) on the databricks cluster.
Please do check out the latest dependencies based on the databricks runtime.
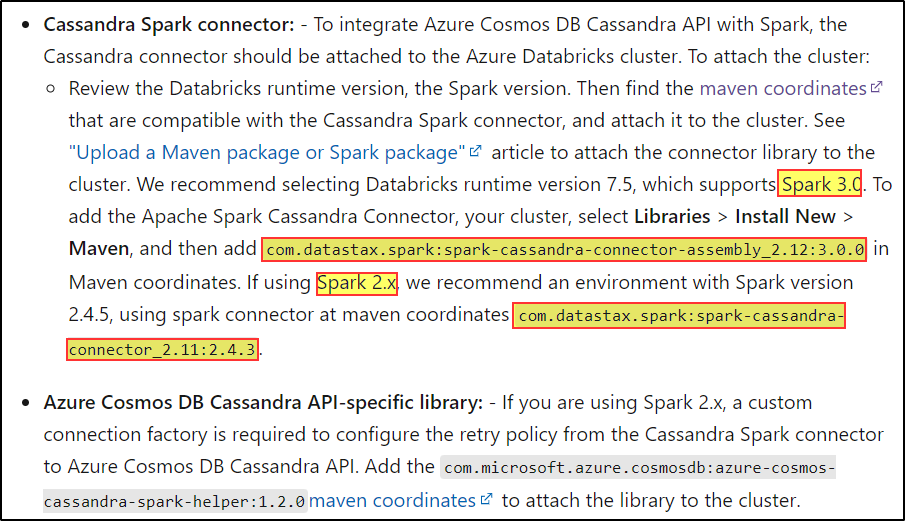
For more details, refer to Access Azure Cosmos DB Cassandra API data from Azure Databricks
In case if you still facing the same issue, could you please share the complete stack trace of the error message which you are experiencing?
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hello Pradeep,
I tried installing the libraries and executed the the above commands. below is the error I am running into.
IOException: Failed to open native connection to Cassandra at {<test>:10350} :: Method com/microsoft/azure/cosmosdb/cassandra/CosmosDbConnectionFactory$.createSession(Lcom/datastax/spark/connector/cql/CassandraConnectorConf;)Lcom/datastax/oss/driver/api/core/CqlSession; is abstract
Caused by: AbstractMethodError: Method com/microsoft/azure/cosmosdb/cassandra/CosmosDbConnectionFactory$.createSession(Lcom/datastax/spark/connector/cql/CassandraConnectorConf;)Lcom/datastax/oss/driver/api/core/CqlSession; is abstract
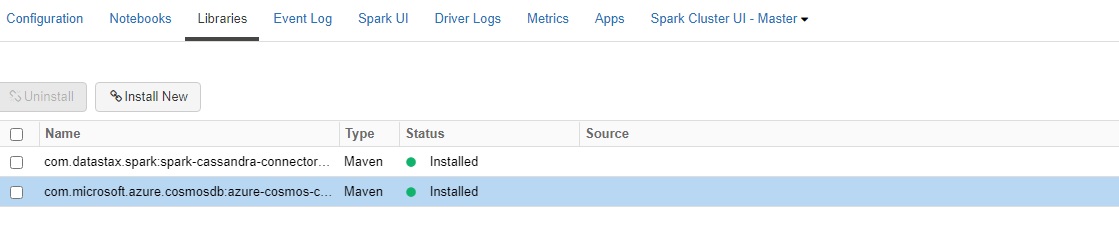
Hello @Amrit Raj Kalashakum ,
Apologize for the delay in response. Is your issue resolved or still facing the same issue?
Hello @Amrit Raj Kalashakum ,
Just checking in if you have had a chance to see the previous response. We need the following information to understand/investigate this issue further.