Transact-SQL
A Microsoft extension to the ANSI SQL language that includes procedural programming, local variables, and various support functions.
4,552 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERF%3C/text%3E%3C/svg%3E)
Greeting guys
i want to delete duplicated primary keys in a table based on update date :
Ex i have this table :
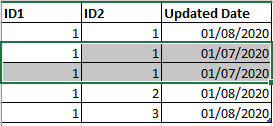
i want to delete the duplicated lines based on the primary key (ID1 and ID 2 are my primary key ) . i want to keep the line with the last Updated date
the results of this example will be :
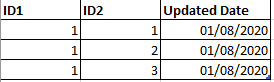
Thanks in advance all

Hi Rami,
Please remember to accept the answers if they helped. Your action would be helpful to other users who encounter the same issue and read this thread.
Thank you for understanding!
Best regards
Melissa

By the way, if you never need such duplicates, you can replace your INSERT statement with a corresponding MERGE, or a combination if UPDATE and INSERT, so that you will not need to remove the old records later.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYK%3C/text%3E%3C/svg%3E)
You can try the following classic approach.
The ROW_NUMBER() is a window function that assigns a sequential integer to each row within the partition of a result set. The row number starts with 1 for the first row in each partition. Eventually, we delete duplicate rows where seq(uence) > 1
SQL
-- DDL and sample data population, start
DECLARE @tbl TABLE (ID1 INT, ID2 INT, Updated DATE);
INSERT INTO @tbl (ID1, ID2, Updated)
VALUES
( 1, 1, '2020-01-08'),
( 1, 1, '2020-01-07'),
( 1, 1, '2020-01-07'),
( 1, 2, '2020-01-08'),
( 1, 3, '2020-01-08');
-- DDL and sample data population, end
;WITH rs AS
(
SELECT *
, ROW_NUMBER() OVER (PARTITION BY ID1, ID2 ORDER BY Updated DESC) AS seq
FROM @tbl
)
DELETE FROM rs
WHERE seq >1;
-- test
SELECT * FROM @tbl;
Output
+-----+-----+------------+
| ID1 | ID2 | Updated |
+-----+-----+------------+
| 1 | 1 | 2020-01-08 |
| 1 | 2 | 2020-01-08 |
| 1 | 3 | 2020-01-08 |
+-----+-----+------------+
Check an intuitive approach too:
delete from MyTable
from MyTable as t
where exists ( select * from MyTable where id1 = t.ID1 and ID2 = t.ID2 and [Updated Date] > t.[Updated Date] )
Although, it does not remove duplicate rows.
Hi RamiFrikha,
Please refer below two methods:
Method One :
DELETE A
FROM @tbl a
JOIN (SELECT ID1,ID2, MAX(Updated) AS MaxTime FROM @tbl GROUP BY ID1,ID2) B
ON A.ID1 = B.ID2 and A.ID2=B.ID2
WHERE A.Updated<B.MaxTime
SELECT * FROM @tbl
Method Two:
;WITH rs AS
(
SELECT *
, RANK() OVER (PARTITION BY ID1, ID2 ORDER BY Updated DESC) AS RN
FROM @tbl
)
DELETE FROM rs
WHERE RN >1;
SELECT * FROM @tbl;
Output:
ID1 ID2 Updated
1 1 2020-01-08
1 2 2020-01-08
1 3 2020-01-08
If the response helped, do "Accept Answer" and upvote it.
Best regards
Melissa
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EG%3C/text%3E%3C/svg%3E)
Based on your sample data, the columns ID1 and ID2 are not a primary key in the table since you cannot insert the duplicate key values into the table. For example:
CREATE TABLE [dbo].[tbl](
[ID1] [int] NOT NULL,
[ID2] [int] NOT NULL,
[UpdatedDate] [date] NOT NULL,
CONSTRAINT [PK_tbl] PRIMARY KEY CLUSTERED
(
[ID1] ASC, [ID2] ASC
)
) ON [PRIMARY];
GO
If you want to insert your sample values:
INSERT INTO tbl (ID1, ID2, UpdatedDate) VALUES
(1, 1, '2020-01-08'),
(1, 1, '2020-01-07'),
(1, 1, '2020-01-07'),
(1, 2, '2020-01-08'),
(1, 3, '2020-01-08');
you will get the following error message:
Msg 2627, Level 14, State 1, Line 22
Violation of PRIMARY KEY constraint 'PK_tbl'. Cannot insert duplicate key in object 'dbo.tbl'. The duplicate key value is (1, 1).
I guess you want to add a primary key on the columns ID1 and ID2 after you clean up the duplicates. As YitzhakKhabinsky-0887 mentioned, you can use a window function ROW_NUMBER() to remove the duplicates and then add a primary key:
ALTER TABLE [dbo].[tbl]
ADD CONSTRAINT [PK_tbl] PRIMARY KEY CLUSTERED
(
[ID1] ASC,
[ID2] ASC
);
GO