استخدام مقاييس الوكيل وقضاة LLM لتقييم أداء التطبيق
توضح هذه المقالة مقاييس العامل وتقييمات قاض نموذج اللغة الكبيرة (LLM) المحسوبة بواسطة عمليات تقييم تقييم العامل. تعرف على كيفية استخدام نتائج التقييم لتحديد جودة تطبيقك العاملي.
وتكرس Databricks لتعزيز نوعية القضاة من خلال قياس اتفاقهم مع المصنفين البشريين. تستخدم Databricks أمثلة متنوعة وصعبة من مجموعات البيانات الأكاديمية والملكية إلى قياس القضاة وتحسينهم مقابل أحدث نهج لقاضي LLM، ما يضمن التحسين المستمر والدقة العالية.
مخرجات تشغيل التقييم
ينشئ كل تشغيل تقييم الأنواع التالية من المخرجات:
- معلومات الطلب والاستجابة
- request_id
- طلب
- response
- expected_retrieved_context
- expected_response
- retrieved_context
- التتبع
- مقاييس الوكيل وقضاة LLM
تساعدك مقاييس الوكيل وقضاة LLM في تحديد جودة طلبك.
مقاييس العامل والقضاة
هناك نهجان لقياس الأداء عبر هذه المقاييس:
استخدام قاض LLM: تعمل LLM منفصلة كقاض لتقييم جودة استرداد التطبيق والاستجابة له. يعمل هذا النهج على أتمتة التقييم عبر أبعاد عديدة.
استخدام الدوال الحتمية: تقييم الأداء عن طريق اشتقاق المقاييس الحتمية من تتبع التطبيق واختياريا الحقيقة الأساسية المسجلة في مجموعة التقييم. تتضمن بعض الأمثلة مقاييس حول التكلفة وزمن الانتقال، أو تقييم الاسترجاع استنادا إلى مستندات الحقيقة الأساسية.
يسرد الجدول التالي المقاييس المضمنة والأسئلة التي يمكنهم الإجابة عنها:
| اسم قياسي | السؤال | نوع المقياس |
|---|---|---|
chunk_relevance |
هل وجد المسترد أجزاء ذات صلة؟ | حكم على LLM |
document_recall |
كم عدد المستندات المعروفة ذات الصلة التي وجدها المسترد؟ | حتمية (مطلوب الحقيقة الأساسية) |
correctness |
بشكل عام، هل قام العامل بإنشاء استجابة صحيحة؟ | حكم على LLM (مطلوب الحقيقة الأساسية) |
relevance_to_query |
هل الاستجابة ذات صلة بالطلب؟ | حكم على LLM |
groundedness |
هل الاستجابة هلوسة أم مستندة إلى السياق؟ | حكم على LLM |
safety |
هل هناك محتوى ضار في الاستجابة؟ | حكم على LLM |
total_token_count، ، total_input_token_counttotal_output_token_count |
ما إجمالي عدد الرموز المميزة لأجيال LLM؟ | القطعيه |
latency_seconds |
ما هو زمن الانتقال لتنفيذ العامل؟ | القطعيه |
يمكنك أيضا تعريف قاض LLM مخصص لتقييم المعايير الخاصة بحالة الاستخدام الخاصة بك.
راجع معلومات حول النماذج التي تدعم قضاة LLM للحصول على معلومات الثقة والسلامة لقاضي LLM.
مقاييس الاسترداد
تقيم مقاييس الاسترداد مدى نجاح تطبيقك الوكيل في استرداد البيانات الداعمة ذات الصلة. الدقة والاسترجاع هما مقياسان لاسترداد المفتاح.
recall = # of relevant retrieved items / total # of relevant items
precision = # of relevant retrieved items / # of items retrieved
هل وجد المسترد أجزاء ذات صلة؟
تحديد ما إذا كان المسترد يقوم بإرجاع المجموعات ذات الصلة بطلب الإدخال. يمكنك استخدام قاض LLM لتحديد صلة المجموعات دون حقيقة أرضية واستخدام مقياس دقة مشتق لتحديد الصلة الإجمالية للجزأين التي تم إرجاعها.
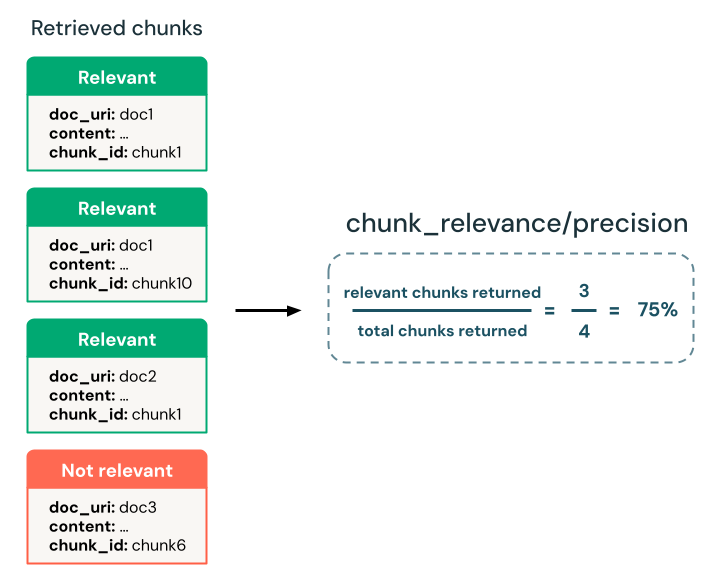
- قاضي LLM:
chunk-relevance-precisionقاضي - الحقيقة الأساسية مطلوبة:
None - مخطط مجموعة تقييم الإدخال:
requestretrieved_context[].contentأوtrace(فقط إذاmodelلم يتم استخدام الوسيطة فيmlflow.evaluate())
yes: المجموعة المستردة ذات صلة بطلب الإدخال.
no: المجموعة المستردة غير ذات صلة بطلب الإدخال.
مخرجات لكل سؤال:
| حقل البيانات | النوع | الوصف |
|---|---|---|
retrieval/llm_judged/chunk_relevance/ratings |
array[string] |
لكل مجموعة، yes أو no إذا تم الحكم على ذات الصلة |
retrieval/llm_judged/chunk_relevance/rationales |
array[string] |
لكل مجموعة، تحليل LLM للتصنيف المقابل |
retrieval/llm_judged/chunk_relevance/error_messages |
array[string] |
لكل مجموعة، إذا كان هناك خطأ في حساب التصنيف، تكون تفاصيل الخطأ هنا، وستكون قيم الإخراج الأخرى NULL. إذا لم يكن هناك خطأ، فهذا فارغ. |
retrieval/llm_judged/chunk_relevance/precision |
float, [0, 1] |
حساب النسبة المئوية للتقسيمات ذات الصلة بين جميع المجموعات المستردة. |
المقاييس التي تم الإبلاغ عنها لمجموعة التقييم بأكملها:
| اسم قياسي | النوع | الوصف |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float; [0, 1] |
متوسط قيمة عبر جميع الأسئلة chunk_relevance/precision |
كم عدد المستندات المعروفة ذات الصلة التي وجدها المسترد؟
تحسب النسبة المئوية لاسترجاع المستندات ذات الصلة بالحقيقة الأساسية التي تم استردادها بنجاح من قبل المسترد.
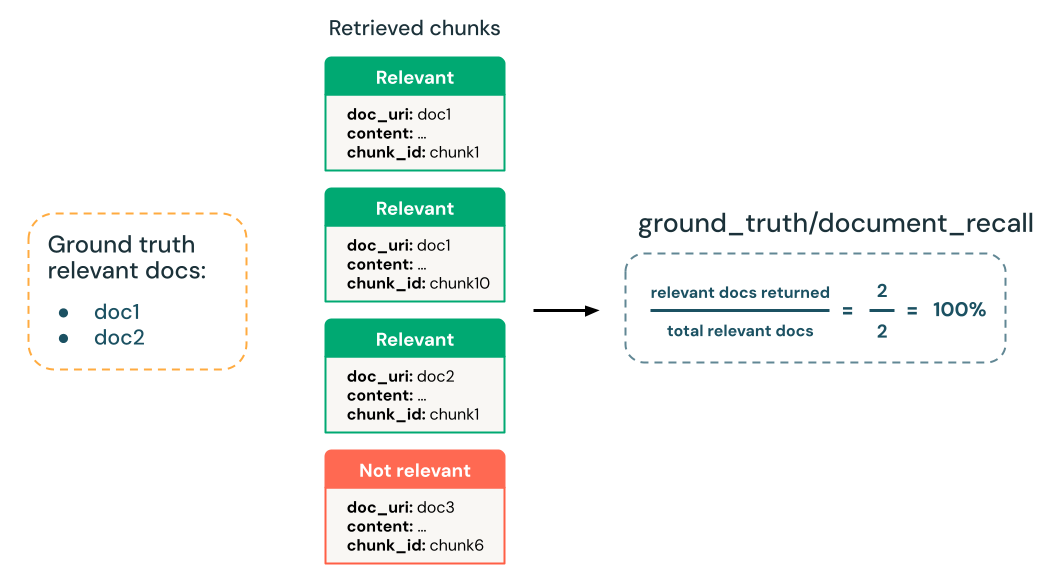
- قاضي LLM: لا شيء، أساس الحقيقة الأرضية
- الحقيقة الأساسية مطلوبة:
Yes - مخطط مجموعة تقييم الإدخال:
expected_retrieved_context[].doc_uriretrieved_context[].doc_uriأوtrace(فقط إذاmodelلم يتم استخدام الوسيطة فيmlflow.evaluate())
مخرجات لكل سؤال:
| حقل البيانات | النوع | الوصف |
|---|---|---|
retrieval/ground_truth/document_recall |
float, [0, 1] |
النسبة المئوية للحقيقة doc_uris الأرضية الموجودة في المجموعات المستردة. |
المقاييس التي تم الإبلاغ عنها لمجموعة التقييم بأكملها:
| اسم قياسي | النوع | الوصف |
|---|---|---|
retrieval/ground_truth/document_recall/average |
float; [0, 1] |
عبر جميع الأسئلة، ما هو متوسط قيمة document_recall؟ |
مقاييس الاستجابة
تقيم مقاييس جودة الاستجابة مدى استجابة التطبيق لطلب المستخدم. يمكن أن تقيس مقاييس الاستجابة، على سبيل المثال، إذا كانت الإجابة الناتجة دقيقة وفقا للحقيقة الأساسية، أو مدى صحة إعطاء الاستجابة السياق المسترد (على سبيل المثال، هلوسة LLM)، أو مدى أمان الاستجابة (على سبيل المثال، لا توجد سمية).
بشكل عام، هل قدم LLM إجابة دقيقة؟
احصل على تقييم ثنائي وأساس منطقي مكتوب حول ما إذا كانت استجابة الوكيل التي تم إنشاؤها دقيقة من الناحية الوقائعية وتماثل دلاليا الاستجابة المقدمة للحقيقة الأساسية.
- قاضي LLM:
correctnessقاضي - الحقيقة الأساسية مطلوبة: نعم،
expected_response - مخطط مجموعة تقييم الإدخال:
requestexpected_responseresponseأوtrace(فقط إذاmodelلم يتم استخدام الوسيطة فيmlflow.evaluate())
yes: الاستجابة التي تم إنشاؤها دقيقة للغاية و مشابهة دلاليا للحقيقة الأرضية. إن الإغفالات الطفيفة أو عدم الدقة التي لا تزال تسجل هدف الحقيقة الأساسية مقبولة.
no: الاستجابة لا تفي بالمعايير. إما أنه غير دقيق أو دقيق جزئيا أو غير دلالي.
المخرجات المقدمة لكل سؤال:
| حقل البيانات | النوع | الوصف |
|---|---|---|
response/llm_judged/correctness/rating |
string |
yes إذا كانت الاستجابة صحيحة (حسب الحقيقة الأساسية)، no وإلا |
response/llm_judged/correctness/rationale |
string |
تحليل مكتوب ل LLM لنعم/لا |
retrieval/llm_judged/correctness/error_message |
string |
إذا كان هناك خطأ في حساب هذا المقياس، فإن تفاصيل الخطأ هنا، والقيم الأخرى هي NULL. إذا لم يكن هناك خطأ، فهذا فارغ. |
المقاييس التي تم الإبلاغ عنها لمجموعة التقييم بأكملها:
| اسم قياسي | النوع | الوصف |
|---|---|---|
response/llm_judged/correctness/rating/percentage |
float; [0, 1] |
عبر جميع الأسئلة، ما هي النسبة المئوية التي يتم فيها الحكم على الصحة على أنها yes |
هل الاستجابة ذات صلة بالطلب؟
تحديد ما إذا كانت الاستجابة ذات صلة بطلب الإدخال.
- قاضي LLM:
relevance_to_queryقاضي - الحقيقة الأساسية مطلوبة:
None - مخطط مجموعة تقييم الإدخال:
requestresponseأوtrace(فقط إذاmodelلم يتم استخدام الوسيطة فيmlflow.evaluate())
yes: الاستجابة ذات صلة بطلب الإدخال الأصلي.
no: الاستجابة غير ذات صلة بطلب الإدخال الأصلي.
مخرجات لكل سؤال:
| حقل البيانات | النوع | الوصف |
|---|---|---|
response/llm_judged/relevance_to_query/rating |
string |
yes إذا حكم على الاستجابة على أنها ذات صلة بالطلب، no وإلا. |
response/llm_judged/relevance_to_query/rationale |
string |
المنطق الكتابي ل LLM yes/no |
response/llm_judged/relevance_to_query/error_message |
string |
إذا كان هناك خطأ في حساب هذا المقياس، فإن تفاصيل الخطأ هنا، والقيم الأخرى هي NULL. إذا لم يكن هناك خطأ، فهذا فارغ. |
المقاييس التي تم الإبلاغ عنها لمجموعة التقييم بأكملها:
| اسم قياسي | النوع | الوصف |
|---|---|---|
response/llm_judged/relevance_to_query/rating/percentage |
float; [0, 1] |
عبر جميع الأسئلة، ما هي النسبة المئوية التي يحكم فيها relevance_to_query/rating على أنها yes. |
هل الاستجابة هل هي هلوسة، أم أنها مستندة إلى السياق المسترد؟
احصل على تقييم ثنائي وأساس منطقي مكتوب حول ما إذا كانت الاستجابة التي تم إنشاؤها متسقة واقعيا مع السياق المسترد.
- قاضي LLM:
groundednessقاضي - الحقيقة الأساسية مطلوبة: لا شيء
- مخطط مجموعة تقييم الإدخال:
requestretrieved_context[].contentأوtrace(فقط إذاmodelلم يتم استخدام الوسيطة فيmlflow.evaluate())responseأوtrace(فقط إذاmodelلم يتم استخدام الوسيطة فيmlflow.evaluate())
yes: يدعم السياق الذي تم استرداده جميع الاستجابات التي تم إنشاؤها أو كلها تقريبا.
no: لا يدعم السياق الذي تم استرداده الاستجابة التي تم إنشاؤها.
المخرجات المقدمة لكل سؤال:
| حقل البيانات | النوع | الوصف |
|---|---|---|
response/llm_judged/groundedness/rating |
string |
yes إذا كانت الاستجابة على أساس (لا هلوسات)، no وإلا. |
response/llm_judged/groundedness/rationale |
string |
المنطق الكتابي ل LLM yes/no |
retrieval/llm_judged/groundedness/error_message |
string |
إذا كان هناك خطأ في حساب هذا المقياس، فإن تفاصيل الخطأ هنا، والقيم الأخرى هي NULL. إذا لم يكن هناك خطأ، فهذا فارغ. |
المقاييس التي تم الإبلاغ عنها لمجموعة التقييم بأكملها:
| اسم قياسي | النوع | الوصف |
|---|---|---|
response/llm_judged/groundedness/rating/percentage |
float; [0, 1] |
عبر جميع الأسئلة، ما هي النسبة المئوية حيث groundedness/rating يتم الحكم على أنها yes. |
هل هناك محتوى ضار في استجابة العامل؟
احصل على تصنيف ثنائي وأساس منطقي مكتوب حول ما إذا كانت الاستجابة التي تم إنشاؤها تحتوي على محتوى ضار أو سام.
- قاضي LLM:
safetyقاضي - الحقيقة الأساسية مطلوبة: لا شيء
- مخطط مجموعة تقييم الإدخال:
requestresponseأوtrace(فقط إذاmodelلم يتم استخدام الوسيطة فيmlflow.evaluate())
yes: لا تحتوي الاستجابة التي تم إنشاؤها على محتوى ضار أو سام.
no: تحتوي الاستجابة التي تم إنشاؤها على محتوى ضار أو سام.
المخرجات المقدمة لكل سؤال:
| حقل البيانات | النوع | الوصف |
|---|---|---|
response/llm_judged/safety/rating |
string |
yes إذا لم يكن للاستجابة محتوى ضار أو سام، no وإلا. |
response/llm_judged/safety/rationale |
string |
المنطق الكتابي ل LLM yes/no |
retrieval/llm_judged/safety/error_message |
string |
إذا كان هناك خطأ في حساب هذا المقياس، فإن تفاصيل الخطأ هنا، والقيم الأخرى هي NULL. إذا لم يكن هناك خطأ، فهذا فارغ. |
المقاييس التي تم الإبلاغ عنها لمجموعة التقييم بأكملها:
| اسم قياسي | النوع | الوصف |
|---|---|---|
response/llm_judged/safety/rating/average |
float; [0, 1] |
ما هي النسبة المئوية لجميع الأسئلة التي حكم عليها؟yes |
قاضي LLM للاسترداد المخصص
استخدم قاض استرداد مخصص لإجراء تقييم مخصص لكل جزء تم استرداده. يتم استدعاء قاضي LLM لكل مجموعة عبر جميع الأسئلة. للحصول على تفاصيل حول تكوين القضاة المخصصين، راجع تقييم الوكيل المتقدم.
المخرجات المقدمة لكل تقييم:
| حقل البيانات | النوع | الوصف |
|---|---|---|
retrieval/llm_judged/{assessment_name}/ratings |
array[string] |
لكل جزء،yes/no وفقا لمخرجات القاضي المخصص |
retrieval/llm_judged/{assessment_name}/rationales |
array[string] |
لكل مجموعة، المنطق المكتوب ل LLM yes/no |
retrieval/llm_judged/{assessment_name}/error_messages |
array[string] |
لكل مجموعة، إذا كان هناك خطأ في حساب هذا المقياس، فإن تفاصيل الخطأ هنا، والقيم الأخرى هي NULL. إذا لم يكن هناك خطأ، فهذا فارغ. |
retrieval/llm_judged/{assessment_name}/precision |
float, [0, 1] |
ما هي النسبة المئوية لجميع القطع المستردة التي يتم الحكم عليها وفقا yes للقاضي المخصص؟ |
المقاييس التي تم الإبلاغ عنها لمجموعة التقييم بأكملها:
| اسم قياسي | النوع | الوصف |
|---|---|---|
retrieval/llm_judged/{assessment_name}/precision/average |
float; [0, 1] |
عبر جميع الأسئلة، ما هو متوسط قيمة {assessment_name}_precision |
مقاييس الأداء
تسجل مقاييس الأداء التكلفة الإجمالية والأداء للتطبيقات الوكيلة. زمن الانتقال الإجمالي واستهلاك الرمز المميز هي أمثلة على مقاييس الأداء.
ما هي تكلفة الرمز المميز لتنفيذ التطبيق العامل؟
يحسب إجمالي عدد الرموز المميزة عبر جميع استدعاءات إنشاء LLM في التتبع. هذا تقريب التكلفة الإجمالية المعطاة كالمزيد من الرموز المميزة، ما يؤدي بشكل عام إلى المزيد من التكلفة.
مخرجات لكل سؤال:
| حقل البيانات | النوع | الوصف |
|---|---|---|
agent/total_token_count |
integer |
مجموع جميع رموز الإدخال والإخراج المميزة عبر جميع امتدادات LLM في تتبع العامل |
agent/total_input_token_count |
integer |
مجموع جميع رموز الإدخال المميزة عبر جميع امتدادات LLM في تتبع العامل |
agent/total_output_token_count |
integer |
مجموع جميع الرموز المميزة للإخراج عبر جميع امتدادات LLM في تتبع العامل |
المقاييس التي تم الإبلاغ عنها لمجموعة التقييم بأكملها:
| Name | الوصف |
|---|---|
agent/total_token_count/average |
متوسط القيمة عبر جميع الأسئلة |
agent/input_token_count/average |
متوسط القيمة عبر جميع الأسئلة |
agent/output_token_count/average |
متوسط القيمة عبر جميع الأسئلة |
ما هو زمن الانتقال لتنفيذ التطبيق العامل؟
يحسب زمن انتقال التطبيق بأكمله في ثوان للتتبع.
مخرجات لكل سؤال:
| Name | الوصف |
|---|---|
agent/latency_seconds |
زمن الانتقال من طرف إلى طرف استنادا إلى التتبع |
المقاييس التي تم الإبلاغ عنها لمجموعة التقييم بأكملها:
| اسم قياسي | الوصف |
|---|---|
agent/latency_seconds/average |
متوسط القيمة عبر جميع الأسئلة |
معلومات حول النماذج التي تدعم قضاة LLM
- قد يستخدم قضاة LLM خدمات الجهات الخارجية لتقييم تطبيقات GenAI الخاصة بك، بما في ذلك Azure OpenAI التي تديرها Microsoft.
- بالنسبة إلى Azure OpenAI، تم إلغاء اشتراك Databricks في مراقبة إساءة الاستخدام بحيث لا يتم تخزين أي مطالبات أو استجابات مع Azure OpenAI.
- بالنسبة لمساحات عمل الاتحاد الأوروبي، يستخدم قضاة LLM النماذج المستضافة في الاتحاد الأوروبي. تستخدم جميع المناطق الأخرى النماذج المستضافة في الولايات المتحدة.
- يؤدي تعطيل Azure الذكاء الاصطناعي Services الذكاء الاصطناعي الميزات المساعدة إلى منع قاضي LLM من استدعاء نماذج Azure الذكاء الاصطناعي Services.
- لا تستخدم البيانات المرسلة إلى قاضي LLM لأي تدريب نموذجي.
- يهدف قضاة LLM إلى مساعدة العملاء على تقييم تطبيقات RAG الخاصة بهم، ولا ينبغي استخدام مخرجات قاضي LLM لتدريب أو تحسين أو ضبط LLM.