تكامل Apache Spark وApache Hive مع Hive Warehouse Connector في Azure HDInsight
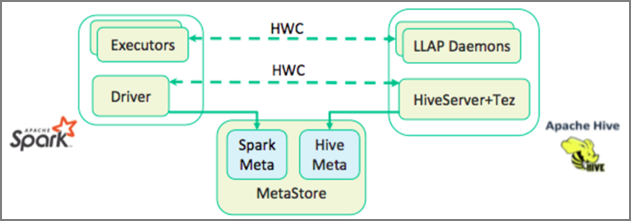
يعد Apache Hive Warehouse Connector (HWC) مكتبة تتيح لك العمل بسهولة أكبر مع Apache Spark وApache Hive. وهو يدعم مهام مثل نقل البيانات بين جداول Spark DataFrames وجداول Hive. أيضاً، عن طريق توجيه بيانات Spark المتدفقة إلى جداول Hive. يعمل Hive Warehouse Connector كجسر بين Spark وHive. كما أنه يدعم Scala وJava وPython كلغات برمجة للتطوير.
يتيح لك Hive Warehouse Connector الاستفادة من الميزات الفريدة لـ Hive وSpark لبناء تطبيقات قوية للبيانات الضخمة.
تقدم Apache Hive دعماً لعمليات قاعدة البيانات التي تكون ذرية ومتسقة ومعزولة ودائمة (ACID). لمزيد من المعلومات حول ACID والعمليات في Hive، راجع Hive Transactions. يوفر Hive أيضاً عناصر تحكم أمنية مفصلة من خلال Apache Ranger والمعالجة التحليلية منخفضة الكمون (LLAP) غير المتوفرة في Apache Spark.
يحتوي Apache Spark على واجهة برمجة تطبيقات دفق منظمة تمنح قدرات الدفق غير متوفرة في Apache Hive. بدءا من HDInsight 4.0 وApache Spark 2.3.1 والإحدث وApache Hive 3.1.0 لها كتالوجات metastore منفصلة، ما يجعل إمكانية التشغيل البيني صعبة.
يسهل Hive Warehouse Connector (HWC) استخدام Spark وHive معاً. تقوم مكتبة HWC بتحميل البيانات من شيطان LLAP إلى منفذي Spark بالتوازي. تجعل هذه العملية أكثر كفاءة وقابلية للتكيف من اتصال JDBC القياسي من Spark إلى Hive. مما يبرز وضعي تنفيذ مختلفين لـ HWC:
- وضع Hive JDBC عبر HiveServer2
- وضع Hive LLAP باستخدام برامج LLAP الخفية [مستحسن]
بشكل افتراضي، يتم تكوين HWC لاستخدام برامج Hive LLAP الخفية. لتنفيذ استعلامات Hive (للقراءة والكتابة) باستخدام الأوضاع أعلاه مع واجهات برمجة التطبيقات الخاصة بها، راجع واجهات برمجة تطبيقات HWC.
بعض العمليات التي يدعمها موصل Warehouse Connector هي:
- وصف جدول
- إنشاء جدول للبيانات بتنسيق ORC
- تحديد بيانات Hive واسترجاع "إطار بيانات"
- كتابة "إطار بيانات" إلى Hive في دفعة
- تنفيذ بيان تحديث Hive
- قراءة بيانات الجدول من Hive، وتحويلها في Spark، وكتابتها إلى جدول Hive جديد
- كتابة "جدول بيانات" أو تدفق "Spark" إلى Hive باستخدام تدفق Hive
إعداد Hive Warehouse Connector
هام
- مثيل HiveServer2 Interactive المثبت على مجموعات Spark 2.4 Enterprise Security Package غير مدعوم للاستخدام مع Hive Warehouse Connector. بدلاً من ذلك، يجب عليك تكوين مجموعة HiveServer2 Interactive منفصلة لاستضافة أحمال العمل HiveServer2 Interactive. تكوين Hive Warehouse Connector الذي يستخدم مجموعة Spark 2.4 واحدة غير مدعوم.
- مكتبة Hive Warehouse Connector (HWC) غير مدعومة للاستخدام مع مجموعات الاستعلام التفاعلية حيث يتم تمكين ميزة إدارة حمل العمل (WLM).
في سيناريو حيث يكون لديك فقط أحمال عمل Spark وتريد استخدام HWC Library، تأكد من عدم تمكين ميزة إدارة حمل العمل في مجموعة الاستعلام التفاعلي (لم يتم تعيين تكوينhive.server2.tez.interactive.queueفي تكوينات Hive).
بالنسبة للسيناريو الذي توجد فيه أحمال عمل Spark (HWC) وأحمال عمل LLAP الأصلية، تحتاج إلى إنشاء مجموعتي استعلام تفاعلي منفصلتين مع قاعدة بيانات metastore المشتركة. مجموعة واحدة لأحمال عمل LLAP الأصلية حيث يمكن تمكين ميزة WLM على أساس الحاجة ومجموعة أخرى لحمل العمل HWC فقط حيث لا ينبغي تكوين ميزة WLM. من المهم ملاحظة أنه يمكنك عرض خطط موارد WLM من كلا نظامي المجموعات حتى إذا تم تمكينها في مجموعة واحدة فقط. لا تقم بإجراء أي تغييرات على خطط الموارد في نظام المجموعة حيث يتم تعطيل ميزة WLM لأنها قد تؤثر على وظيفة WLM في نظام المجموعة الأخرى. - على الرغم من أن Spark يدعم لغة حوسبة R لتبسيط تحليل البيانات، فإن مكتبة Hive Warehouse Connector (HWC) غير مدعومة لاستخدامها مع R. لتنفيذ أحمال عمل HWC، يمكنك تنفيذ الاستعلامات من Spark إلى Hive باستخدام واجهة برمجة تطبيقات HiveWarehouseSession على غرار JDBC التي تدعم Scala وJava وPython فقط.
- تنفيذ الاستعلامات (للقراءة والكتابة) من خلال HiveServer2 عبر وضع JDBC غير مدعوم لأنواع البيانات المعقدة مثل أنواع الصفائف/البنية/الخرائط.
- يدعم HWC الكتابة فقط بتنسيقات ملفات ORC. لا يتم دعم عمليات الكتابة غير ORC (على سبيل المثال: تنسيقات الملفات النصية والـ parquet) عبر HWC.
يحتاج Hive Warehouse Connector إلى مجموعات منفصلة لأحمال عمل Spark والاستعلام التفاعلي. اتبع هذه الخطوات لإعداد هذه المجموعات في Azure HDInsight.
أنواع نظام المجموعة المدعومة والإصدارات
| إصدار HWC | إصدار Spark | إصدار InteractiveQuery |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | Interactive Query 3.1 | HDI 4.0 |
| v2 | Spark 3.1 | HDI 5.0 | Interactive Query 3.1 | HDI 5.0 |
إنشاء مجموعات
أنشئ مجموعة HDInsight Spark 4.0 بحساب تخزين وشبكة Azure افتراضية مخصصة. للحصول على معلومات حول إنشاء مجموعة في Azure Virtual Network، راجع إضافة HDInsight إلى شبكة ظاهرية موجودة.
قم بإنشاء مجموعة HDInsight Interactive Query (LLAP) 4.0 بنفس حساب التخزين وAzure Virtual Network مثل مجموعة Spark.
تكوين إعدادات HWC
اجمع معلومات أولية
من مستعرض ويب، انتقل إلى
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVEحيث LLAPCLUSTERNAME هو اسم مجموعة الاستعلام التفاعلي.انتقل إلى الملخص>HiveServer2 Interactive JDBC URL ولاحظ القيمة. قد تكون القيمة مشابهة لـ:
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive.انتقل إلى Configs>Advanced>Advanced hive-site>hive.zookeeper.quorum ولاحظ القيمة. قد تكون القيمة مشابهة لـ:
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181.انتقل إلى Configs>Advanced>General>hive.metastore.uris and note the value. قد تكون القيمة مشابهة لـ:
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083.انتقل إلى Configs>Advanced>Advanced hive-interactive-site>hive.llap.daemon.service.hosts and note the value. قد تكون القيمة مشابهة لـ:
@llap0.
تكوين إعدادات مجموعة Spark
من متصفح ويب، انتقل إلى
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configsCLUSTERNAME مكان اسم نظام مجموعة Apache Spark.قم بتوسيع Custom spark2-defaults.
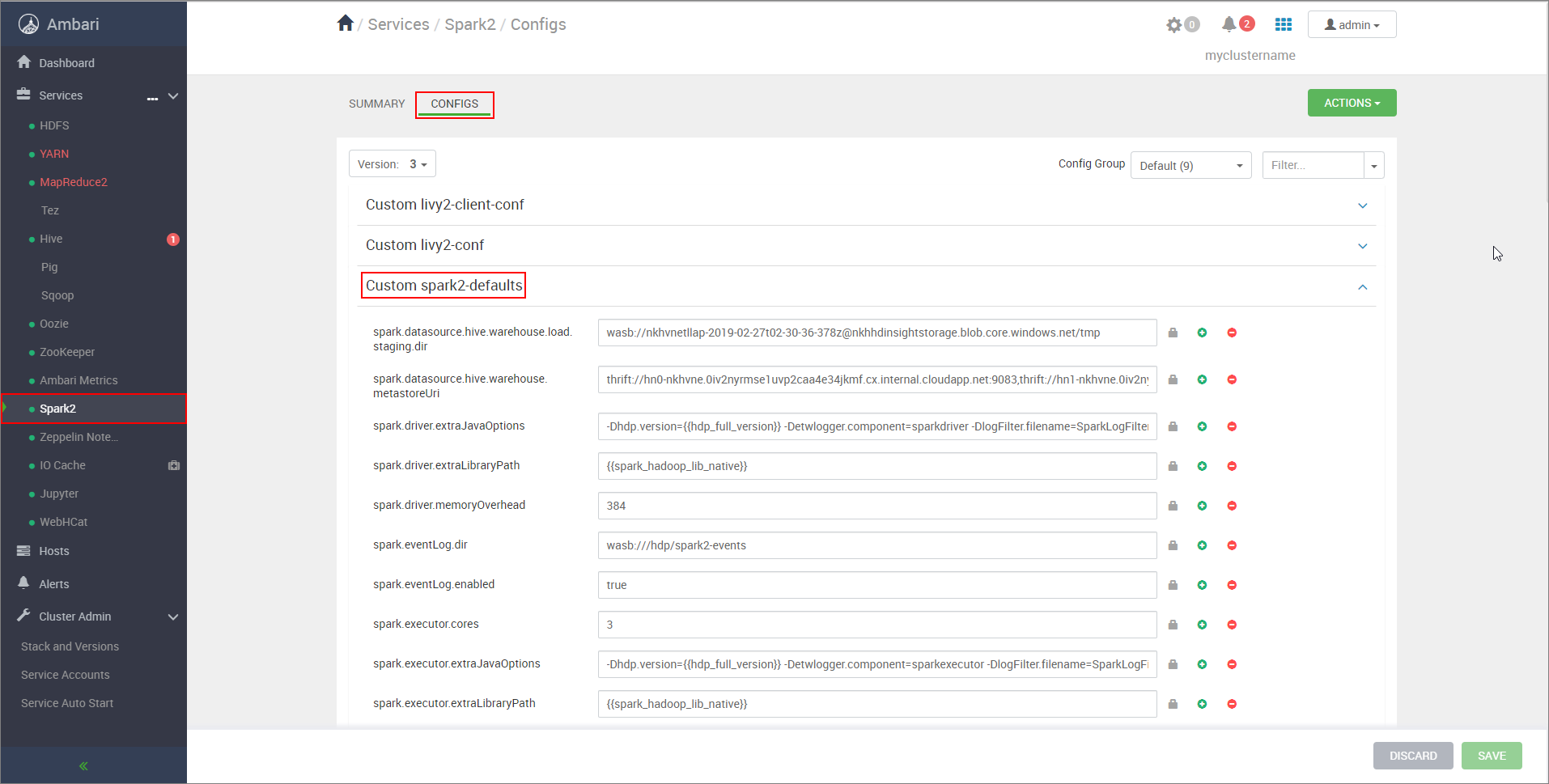
حدد Add Property... لإضافة التكوينات التالية:
التكوين القيمة spark.datasource.hive.warehouse.load.staging.dirإذا كنت تستخدم حساب تخزين ADLS Gen2، فاستخدم abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp
إذا كنت تستخدم حساب تخزين Azure Blob، فاستخدمwasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp.
قم بالتعيين إلى دليل مرحلي مناسب متوافق مع HDFS. إذا كان لديك مجموعتان مختلفتان، يجب أن يكون الدليل المرحلي مجلدا في الدليل المرحلي لحساب تخزين مجموعة LLAP بحيث يمكن ل HiveServer2 الوصول إليه. استبدلSTORAGE_ACCOUNT_NAMEباسم حساب التخزين الذي تستخدمه المجموعة، وSTORAGE_CONTAINER_NAMEباسم حاوية التخزين.spark.sql.hive.hiveserver2.jdbc.urlالقيمة التي حصلت عليها سابقاً من HiveServer2 Interactive JDBC URL spark.datasource.hive.warehouse.metastoreUriالقيمة التي حصلت عليها سابقاً من hive.metastore.uris. spark.security.credentials.hiveserver2.enabledtrueلوضع مجموعة YARN وfalseلوضع عميل YARN.spark.hadoop.hive.zookeeper.quorumالقيمة التي حصلت عليها سابقاً من hive.zookeeper.quorum. spark.hadoop.hive.llap.daemon.service.hostsالقيمة التي حصلت عليها سابقاً من hive.llap.daemon.service.hosts. احفظ التغييرات وأعد تشغيل جميع المكونات المتأثرة.
تكوين مجموعات HWC لحزمة أمان المؤسسة (ESP)
توفر حزمة أمان المؤسسة (ESP) إمكانات على مستوى المؤسسات مثل المصادقة المستندة إلى Active Directory، والدعم متعدد المستخدمين، والتحكم في الوصول المستند إلى الدور لمجموعات Apache Hadoop في Azure HDInsight. لمزيد من المعلومات حول ESP، راجع استخدام حزمة أمان المؤسسة في HDInsight.
بصرف النظر عن التكوينات المذكورة في القسم السابق، أضف التكوين التالي لاستخدام HWC على مجموعات ESP.
من واجهة مستخدم ويب Ambari لمجموعة Spark، انتقل إلى Spark2>CONFIGS>Custom spark2-defaults.
قم بتحديث الخاصية التالية.
التكوين القيمة spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>من مستعرض ويب، انتقل إلى
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summaryحيث CLUSTERNAME هو اسم مجموعة الاستعلام التفاعلي. انقر فوق HiveServer2 Interactive. سترى اسم المجال المؤهل بالكامل (FQDN) للعقدة الرئيسية التي يتم تشغيل LLAP عليها كما هو موضح في لقطة الشاشة. استبدل<llap-headnode>بهذه القيمة.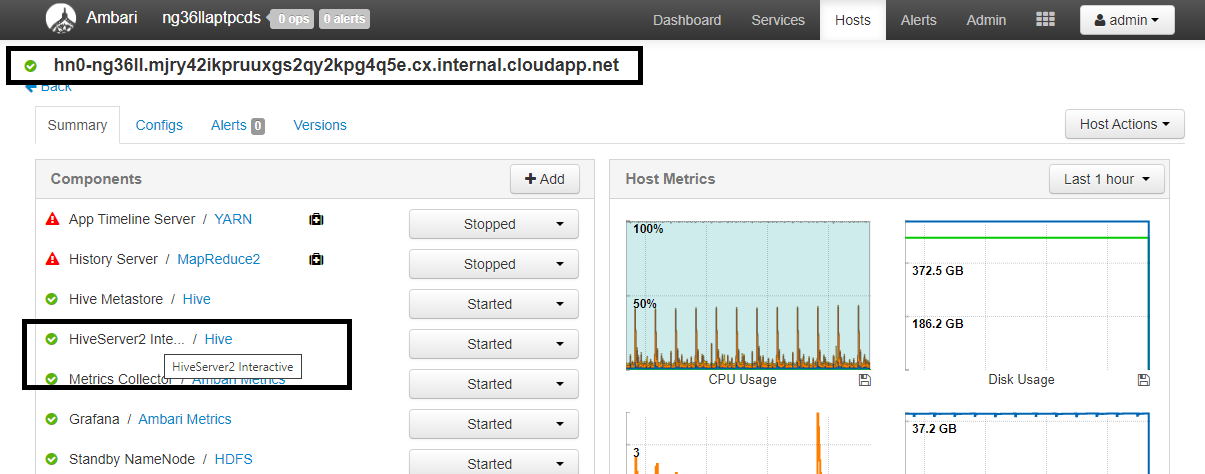
استخدم الأمر ssh للاتصال بنظام مجموعة Interactive Query الخاص بك. ابحث عن المعلمة
default_realmفي ملف/etc/krb5.conf. استبدل<AAD-DOMAIN>بهذه القيمة كسلسلة أحرف كبيرة، وإلا فلن يتم العثور على بيانات الاعتماد.
على سبيل المثال،
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET.
احفظ التغييرات وأعد تشغيل المكونات حسب الحاجة.
استخدام Hive Warehouse Connector
يمكنك الاختيار من بين عدة طرق مختلفة للاتصال بمجموعة الاستعلامات التفاعلية الخاصة بك وتنفيذ الاستعلامات باستخدام موصل Hive Warehouse. تتضمن الطرق المدعومة الأدوات التالية:
فيما يلي بعض الأمثلة للاتصال بـ HWC من Spark.
Spark-shell
هذه طريقة لتشغيل Spark بشكل تفاعلي من خلال إصدار معدّل من Scala shell.
استخدم الأمر ssh للاتصال بنظام مجموعة Apache Spark الخاص بك. قم بتحرير الأمر أدناه عن طريق استبدال اسم نظام المجموعة باسم نظام مجموعتك ثم إدخال الأمر:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netمن جلسة ssh الخاصة بك، قم بتنفيذ الأمر التالي لملاحظة إصدار
hive-warehouse-connector-assembly:ls /usr/hdp/current/hive_warehouse_connectorقم بتحرير التعليمة البرمجية أدناه باستخدام الإصدار
hive-warehouse-connector-assemblyالمحدد أعلاه. ثم نفّذ الأمر لبدء spark shell:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseبعد بدء تشغيل spark shell، يمكن بدء تشغيل مثيل hive Warehouse الاتصال or باستخدام الأوامر التالية:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-submit
يعد إرسال Spark أداة مساعدة لإرسال أي برنامج Spark (أو مهمة) إلى مجموعات Spark.
ستقوم مهمة spark-submit بإعداد وتكوين Spark وHive Warehouse الاتصال or وفقا لإرشاداتنا، وتنفيذ البرنامج الذي نمرره إليه، ثم تحرير الموارد التي كانت قيد الاستخدام بشكل نظيف.
بمجرد إنشاء التعليمة البرمجية scala/java مع التبعيات في جرة تجميع، استخدم الأمر أدناه لتشغيل تطبيق Spark. استبدل <VERSION>و <APP_JAR_PATH> بالقيم الفعلية.
وضع عميل YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarوضع مجموعة الغزل
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
تستخدم هذه الأداة المساعدة أيضا عندما نكون قد كتبنا التطبيق بأكمله في pySpark وتعبئته في .py ملفات (Python)، حتى نتمكن من إرسال التعليمات البرمجية بأكملها إلى مجموعة Spark للتنفيذ.
بالنسبة لتطبيقات Python، مرر ملف .py بدلا من /<APP_JAR_PATH>/myHwcAppProject.jar، وأضف ملف التكوين أدناه (Python .zip) إلى مسار البحث باستخدام --py-files.
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
قم بتشغيل الاستعلامات على مجموعات حزمة أمان Enterprise (ESP)
استخدم kinit قبل بدء إطلاق spark-shell أو spark-submit. استبدل USERNAME باسم حساب المجال بأذونات للوصول إلى نظام المجموعة، ثم قم بتنفيذ الأمر التالي:
kinit USERNAME
تأمين البيانات على مجموعات Spark ESP
قم بإنشاء جدول
demoمع بعض نماذج البيانات بإدخال الأوامر التالية:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');اعرض محتويات الجدول باستخدام الأمر التالي. قبل تطبيق النهج،
demoيعرض الجدول العمود الكامل.hive.executeQuery("SELECT * FROM demo").show()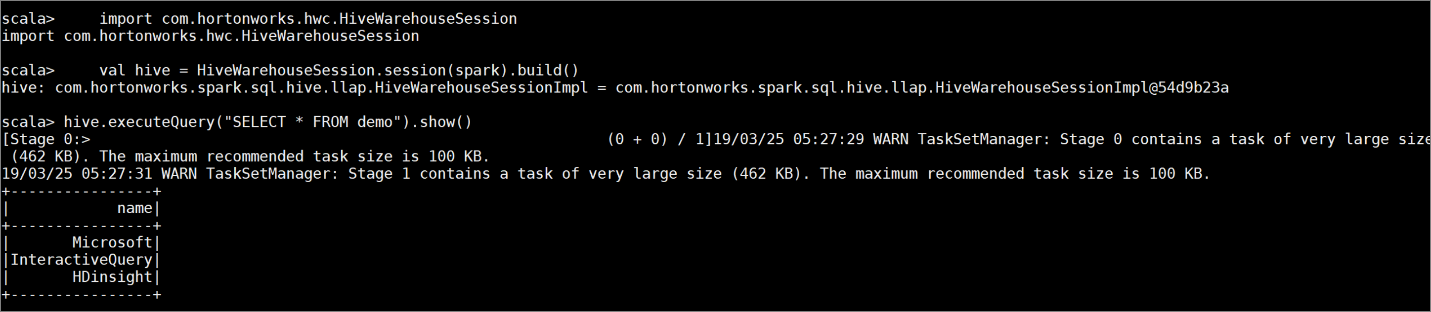
قم بتطبيق نهج إخفاء العمود التي تعرض فقط الأحرف الأربعة الأخيرة من العمود.
انتقل إلى Ranger Admin UI at
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/.انقر فوق خدمة Hive للمجموعة الخاصة بك ضمن Hive.
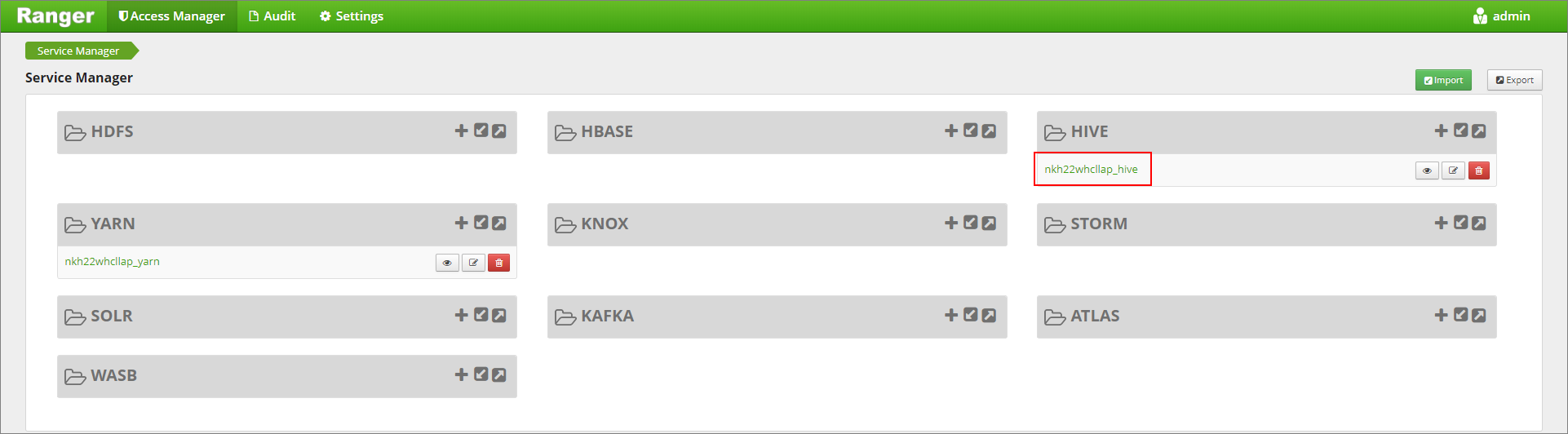
انقر فوق علامة التبويب Masking ثم Add New Policy
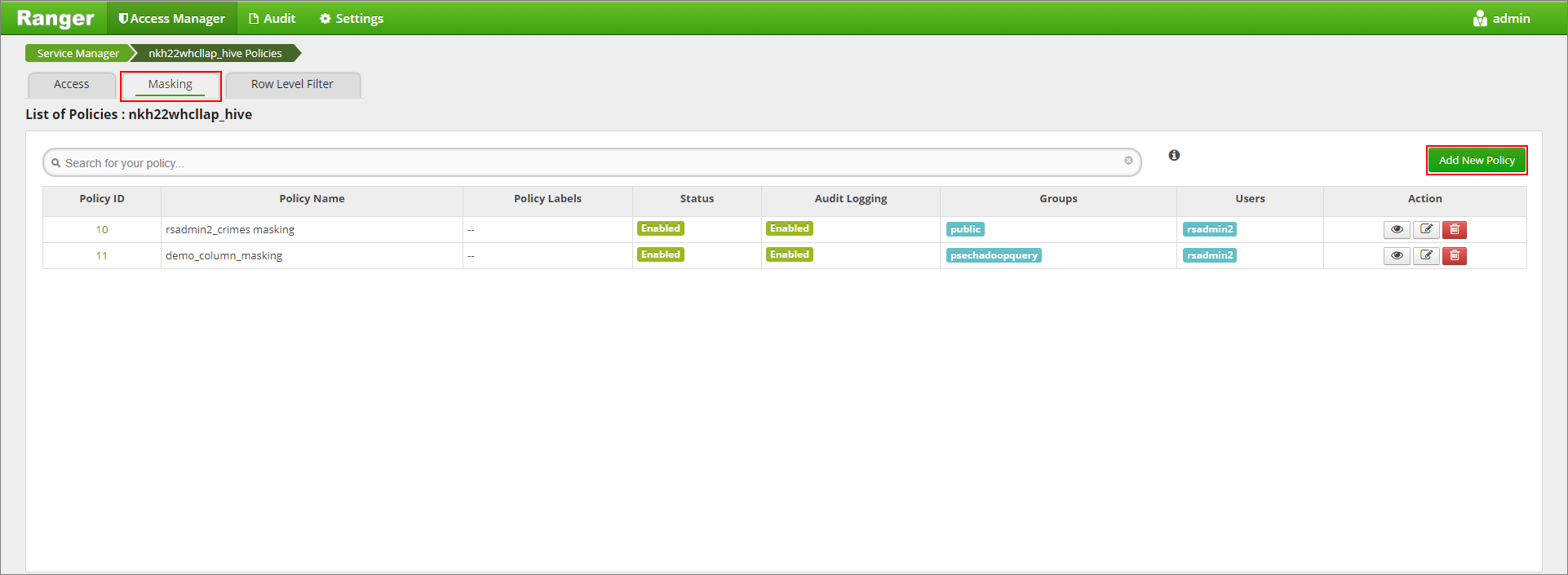
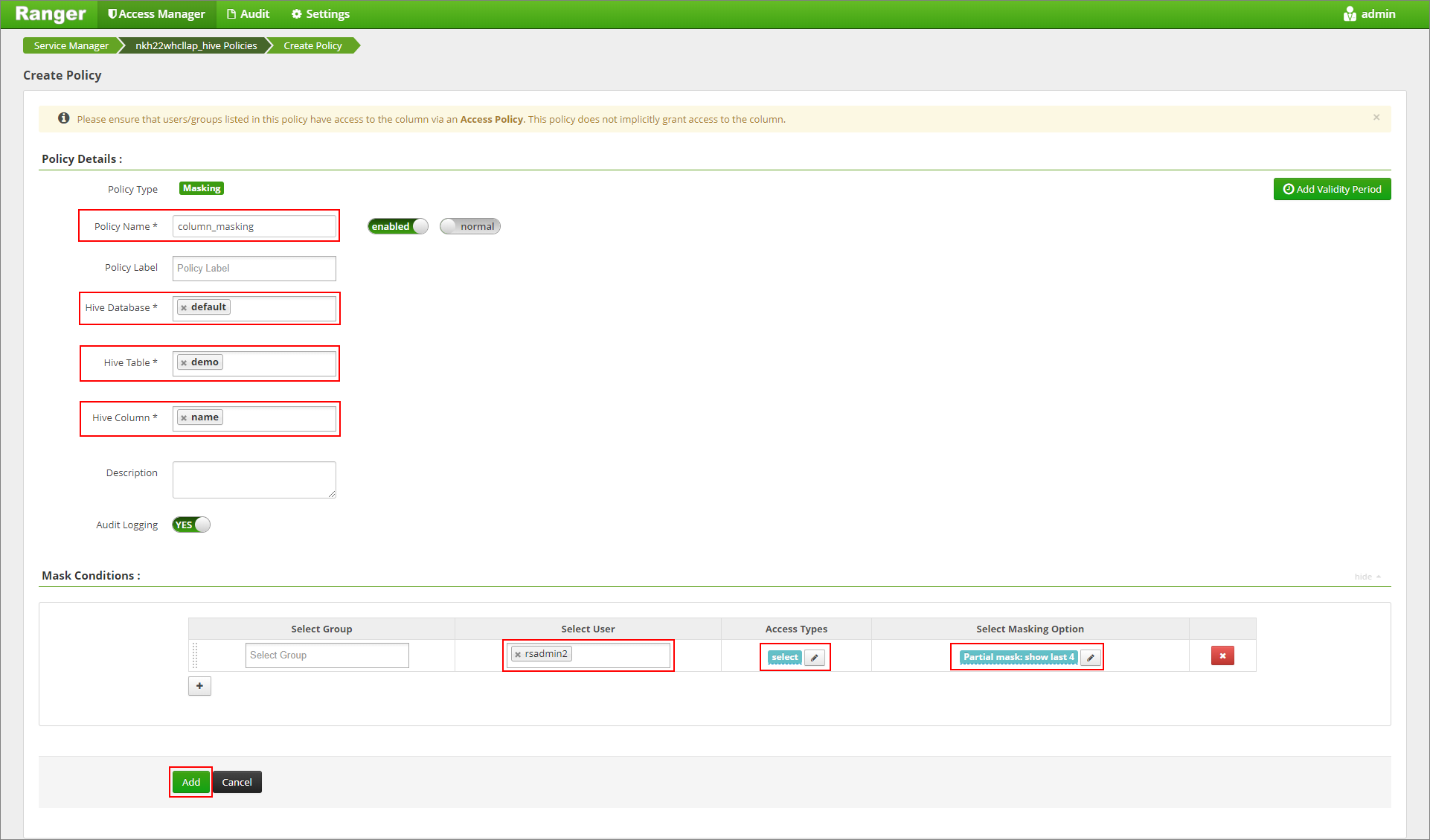
أدخل اسم النهج المطلوب. حدد قاعدة البيانات: Default, Hive table: demo، عمود Hive: الاسم, User: rsadmin2, Access Types: حدد وPartial mask: show last 4 من القائمة Select Masking Option. انقر فوق إضافة.
عرض محتويات الجدول مرة أخرى. بعد تطبيق نهج الحارس، يمكننا رؤية الأحرف الأربعة الأخيرة فقط من العمود.
