إعداد AutoML لتدريب نماذج رؤية الكمبيوتر
ينطبق على: ملحق ML Azure CLI v2 (الحالي)Python SDK azure-ai-ml v2 (الحالي)
ملحق ML Azure CLI v2 (الحالي)Python SDK azure-ai-ml v2 (الحالي)
في هذه المقالة، ستتعلم كيفية تدريب نماذج رؤية الكمبيوتر على بيانات الصور باستخدام التعلم الآلي الآلي. يمكنك تدريب النماذج باستخدام ملحق Azure التعلم الآلي CLI v2 أو Azure التعلم الآلي Python SDK v2.
يدعم التعلم الآلي التلقائي تدريب النموذج لمهام رؤية الكمبيوتر، مثل تصنيف الصور وكشف العناصر وتجزئة المثيل. يتم حاليا دعم تأليف نماذج AutoML لمهام رؤية الكمبيوتر عبر Python SDK للتعلم الآلي من Azure. يمكن الوصول إلى تجارب التجريب الناتجة والنماذج والمخرجات من واجهة مستخدم Azure التعلم الآلي studio. تعرّف على المزيد حول التعلم الآلي التلقائي لمهام رؤية الكمبيوتر على بيانات الصورة.
المتطلبات الأساسية
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
- مساحة عمل للتعلم الآلي من Microsoft Azure. لإنشاء مساحة العمل، انظر إنشاء موارد مساحة العمل .
- قم بالتثبيت وإعداد CLI (الإصدار 2) والتأكد من تثبيت الملحق
ml.
تحديد نوع المهمة
يدعم التعلم الآلي التلقائي للصور أنواع المهام التالية:
| نوع المهمة | صيغة أوامر وظيفة AutoML |
|---|---|
| تصنيف الصور | الإصدار 2 من CLI: image_classification الإصدار 2 من SDK: image_classification() |
| تصنيف الصور متعدد التسميات | الإصدار 2 من CLI: image_classification_multilabel الإصدار 2 من SDK: image_classification_multilabel() |
| كشف عنصر الصورة | الإصدار 2 من CLI: image_object_detection الإصدار 2 من SDK: image_object_detection() |
| تجزئة مثيل الصورة | الإصدار 2 من CLI: image_instance_segmentation الإصدار 2 من SDK: image_instance_segmentation() |
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
نوع المهمة هذا هو معلمة مطلوبة ويمكن تعيينه باستخدام المفتاح task.
على سبيل المثال:
task: image_object_detection
بيانات التدريب والتحقق من الصحة
من أجل إنشاء نماذج رؤية الكمبيوتر، عليك إحضار بيانات الصورة المسماة كإدخال لتدريب النموذج في شكل MLTable. يمكنك إنشاء MLTable من بيانات التدريب بتنسيق JSONL.
إذا كانت بيانات التدريب بتنسيق مختلف (مثل pascal VOC أو COCO)، يمكنك تطبيق البرامج النصية المساعدة المضمنة مع نماذج دفاتر الملاحظات لتحويل البيانات إلى JSONL. تعرّف على المزيد حول كيفية إعداد البيانات لمهام رؤية الكمبيوتر باستخدام التعلم الآلي المؤتمت.
إشعار
يجب أن تحتوي بيانات التدريب على 10 صور على الأقل لكي تتمكن من إرسال وظيفة AutoML.
تحذير
يُدعم إنشاء MLTable من البيانات بتنسيق JSONL باستخدام SDK وCLI فقط لهذه الإمكانية. لا يتم دعم إنشاء MLTable عبر واجهة المستخدم في الوقت الحالي.
نماذج مخططات JSONL
تعتمد بنية TabularDataset على المهمة الموجودة. بالنسبة إلى أنواع مهام رؤية الكمبيوتر، تتكون من الحقول التالية:
| الحقل | الوصف |
|---|---|
image_url |
يحتوي على مسار الملف كعنصر StreamInfo |
image_details |
تتكون معلومات بيانات تعريف الصورة من الارتفاع والعرض والتنسيق. هذا الحقل اختياري، وبالتالي قد يكون موجودًا أو غير موجود. |
label |
تمثيل json لتسمية الصورة حسب نوع المهمة. |
التعليمات البرمجية التالية هي نموذج ملف JSONL لتصنيف الصور:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
تمثل التعليمة البرمجية التالية نموذج ملف JSONL لكشف العناصر:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
استهلاك البيانات
بمجرد أن تكون بياناتك بتنسيق JSONL، يمكنك إنشاء التدريب والتحقق من صحة MLTable كما هو موضح أدناه.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
لا يفرض التعلم الآلي التلقائي أي قيود على حجم بيانات التدريب أو التحقق من الصحة لمهام رؤية الكمبيوتر. الحد الأقصى لحجم مجموعة البيانات محدود فقط بواسطة طبقة التخزين خلف مجموعة البيانات (مثال: مخزن كائن ثنائي كبير الحجم). لا يوجد حد أدنى لعدد الصور أو التسميات. ومع ذلك، نوصي بالبدء بما لا يقل عن 10-15 عينة لكل تسمية لضمان تدريب نموذج الإخراج بشكل كاف. كلما ارتفع العدد الإجمالي للتسميات/الفئات، زادت العينات التي تحتاجها لكل تسمية.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
بيانات التدريب هي معلمة مطلوبة ويتم تمريرها باستخدام training_data المفتاح . يمكنك تحديد MLtable آخر حسب اختيارك كبيانات التحقق من الصحة باستخدام المفتاح validation_data. إذا لم يتم تحديد بيانات التحقق من الصحة، يتم استخدام 20٪ من بيانات التدريب الخاصة بك للتحقق من الصحة بشكل افتراضي، إلا إذا قمت بتمرير validation_data_size وسيطة بقيمة مختلفة.
اسم العمود الهدف هو معلمة مطلوبة ويُستخدم كهدف لمهمة التعلم الآلي الخاضعة للإشراف. يتم تمريره باستخدام target_column_name المفتاح. على سبيل المثال،
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
حساب لتشغيل التجربة
يمكن توفير هدف حساب للتعلم الآلي التلقائي لإجراء تدريب نموذج. تتطلب نماذج التعلم الآلي التلقائي لمهام رؤية الكمبيوتر وحدات SKU لـ GPU ودعم مجموعات NC وND. نوصي بسلسلة NCsv3 (مع وحدات معالجة الرسومات v100) لتدريب أسرع. يستخدم هدف الحوسبة مع وحدة SKU متعددة وحدات معالجة الرسومات VM وحدات معالجة الرسومات المتعددة لتسريع التدريب أيضا. بالإضافة إلى ذلك، عند إعداد هدف حساب مع عقد متعددة، يمكنك إجراء تدريب أسرع على النموذج من خلال التوازي عند ضبط المعلمات الفائقة لنموذجك.
إشعار
إذا كنت تستخدم مثيل حساب كهدف حساب، فيرجى التأكد من عدم تشغيل مهام AutoML متعددة في نفس الوقت. أيضا، يرجى التأكد من تعيين إلى max_concurrent_trials 1 في حدود وظيفتك.
يتم تمرير هدف الحساب باستخدام المعلمة compute. على سبيل المثال:
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
compute: azureml:gpu-cluster
تكوين التجارب
بالنسبة لمهام رؤية الكمبيوتر، يمكنك تشغيل الإصدارات التجريبية الفردية أو عمليات المسح اليدوي أو المسح التلقائي. نوصي بالبدء بمسح تلقائي للحصول على نموذج أساسي أول. بعد ذلك، يمكنك تجربة التجارب الفردية مع نماذج معينة وتكوينات hyperparameter. وأخيرا، مع المسح اليدوي يمكنك استكشاف قيم متعددة للمقاييس الفائقة بالقرب من النماذج الأكثر وعدا وتكوينات المعلمات الفائقة. يتجنب سير العمل هذا المكون من ثلاث خطوات (المسح التلقائي، والتجارب الفردية، والمسح اليدوي) البحث في مساحة المعلمة الفائقة بالكامل، والتي تنمو بشكل كبير في عدد المعلمات الفائقة.
يمكن أن تؤدي عمليات المسح التلقائي إلى نتائج تنافسية للعديد من مجموعات البيانات. بالإضافة إلى ذلك، فإنها لا تتطلب معرفة متقدمة ببنى النموذج، بل تأخذ في الاعتبار ارتباطات المعلمات الفائقة وتعمل بسلاسة عبر إعدادات الأجهزة المختلفة. كل هذه الأسباب تجعلها خيارا قويا للمرحلة المبكرة من عملية التجريب الخاصة بك.
المقياس الأساسي
تستخدم مهمة تدريب AutoML مقياسا أساسيا لتحسين النموذج وضبط المعلمات الفائقة. يعتمد المقياس الأساسي على نوع المهمة كما هو موضح أدناه؛ قيم القياس الأساسية الأخرى غير مدعومة حاليا.
- دقة تصنيف الصور
- التقاطع فوق الاتحاد لتصنيف الصور متعدد التسميات
- متوسط متوسط الدقة للكشف عن كائن الصورة
- متوسط الدقة المتوسطة لتجزئة مثيل الصورة
حدود الوظائف
يمكنك التحكم في الموارد التي تم إنفاقها على مهمة تدريب AutoML Image عن طريق تحديد timeout_minutes، max_trials و max_concurrent_trials للمهمة في إعدادات الحد كما هو موضح في المثال أدناه.
| المعلمة | تفاصيل |
|---|---|
max_trials |
معلمة للحد الأقصى لعدد التجارب التي يجب مسحها. يجب أن يكون عدداً صحيحاً بين 1 و1000. عند استكشاف المعلمات الفائقة الافتراضية فقط لبنية نموذج معين، قم بتعيين هذه المعلمة إلى 1. القيمة الافتراضية هي 1. |
max_concurrent_trials |
الحد الأقصى لعدد الإصدارات التجريبية التي يمكن تشغيلها بشكل متزامن. في حال عدم التحديد، يجب أن يكون عدداً صحيحاً بين 1 و100. القيمة الافتراضية هي 1. ملاحظة: max_concurrent_trials يتم تحديده max_trials داخليا. على سبيل المثال، إذا كان المستخدم يعين max_concurrent_trials=4، max_trials=2فسيتم تحديث القيم داخليا ك max_concurrent_trials=2، max_trials=2. |
timeout_minutes |
مقدار الوقت بالدقائق قبل انتهاء التجربة. إذا لم يتم تحديد أي شيء، فإن timeout_minutes التجربة الافتراضية هي سبعة أيام (60 يوما كحد أقصى) |
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
مسح المعلمات الفائقة للنموذج تلقائيا (AutoMode)
هام
تُعد هذه الميزة قيد الإصدار الأولي العام في الوقت الحالي. يتم توفير إصدار المعاينة هذا من دون اتفاقية مستوى الخدمة. بعض الميزات ربما لا تكون مدعمة أو بها بعض القدرات المقيدة. لمزيد من المعلومات، راجع شروط الاستخدام التكميلية لمعاينات Microsoft Azure.
من الصعب التنبؤ بأفضل بنية نموذج ومقاييس فائقة لمجموعة بيانات. أيضا، في بعض الحالات قد يكون الوقت البشري المخصص لضبط المعلمات الفائقة محدودا. بالنسبة لمهام رؤية الكمبيوتر، يمكنك تحديد أي عدد من التجارب ويحدد النظام تلقائيا منطقة مساحة المعلمة الفائقة للمسح. لا يتعين عليك تحديد مساحة بحث hyperparameter أو أسلوب أخذ العينات أو نهج الإنهاء المبكر.
تشغيل AutoMode
يمكنك تشغيل عمليات المسح التلقائي عن طريق تعيين max_trials قيمة أكبر من 1 في limits وعدم تحديد مساحة البحث وطريقة أخذ العينات ونهج الإنهاء. نطلق على هذه الوظيفة AutoMode؛ يرجى الاطلاع على المثال التالي.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
limits:
max_trials: 10
max_concurrent_trials: 2
من المحتمل أن يعمل عدد من التجارب بين 10 و20 بشكل جيد على العديد من مجموعات البيانات. لا يزال من الممكن تعيين ميزانية الوقت لمهمة AutoML، ولكن نوصي بالقيام بذلك فقط إذا كان كل إصدار تجريبي قد يستغرق وقتا طويلا.
تحذير
لا يتم دعم بدء عمليات المسح التلقائي عبر واجهة المستخدم في الوقت الحالي.
التجارب الفردية
في الإصدارات التجريبية الفردية، يمكنك التحكم مباشرة في بنية النموذج والمقاييس الفائقة. يتم تمرير بنية النموذج عبر المعلمة model_name .
بنيات النموذج المدعومة
يلخص الجدول التالي النماذج القديمة المدعومة لكل مهمة رؤية كمبيوتر. سيؤدي استخدام هذه النماذج القديمة فقط إلى تشغيل التشغيل باستخدام وقت التشغيل القديم (حيث يتم إرسال كل تشغيل فردي أو إصدار تجريبي كمهمة أمر). يرجى الاطلاع أدناه على دعم HuggingFace وMMDetection.
| المهمة | بنى النموذج | صيغة أوامر سلسلة حرفيةdefault_model* المشار إليه بـ * |
|---|---|---|
| تصنيف الصورة (متعدد الفئات ومتعددة التسميات) |
MobileNet: نماذج خفيفة الوزن لتطبيقات الجوال ResNet: الشبكات المتبقية ResNeSt: شبكات تقسيم الانتباه SE-ResNeXt50: شبكات الضغط والتحفيز ViT: شبكات محول الرؤية |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (صغير) vitb16r224* (قاعدة) vitl16r224 (كبير) |
| كشف الكائنات | YOLOv5: نموذج الكشف عن الكائنات في مرحلة واحدة RCNN ResNet FPN أسرع: نموذجان للكشف عن الكائنات في المرحلة RetinaNet ResNet FPN: معالجة عدم توازن الفئة مع فقدان التركيز ملاحظة: ارجع إلى model_sizeالمعلمة الفائقة لأحجام نموذج YOLOv5. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| تجزئة مثيل الصورة | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
بنيات النموذج المدعومة - HuggingFace وMMDetection (معاينة)
باستخدام الواجهة الخلفية الجديدة التي تعمل على البنية الأساسية لبرنامج ربط العمليات التجارية Azure التعلم الآلي، يمكنك بالإضافة إلى ذلك استخدام أي نموذج لتصنيف الصور من HuggingFace Hub الذي يعد جزءا من مكتبة المحولات (مثل microsoft/beit-base-patch16-224)، بالإضافة إلى أي الكشف عن الكائنات أو نموذج تجزئة المثيل من MMDetection الإصدار 3.1.0 Model Zoo (مثل atss_r50_fpn_1x_coco).
بالإضافة إلى دعم أي نموذج من HuggingFace Transfomers وMMDetection 3.1.0، نقدم أيضا قائمة بالنماذج المنسقة من هذه المكتبات في سجل azureml. تم اختبار هذه النماذج المنسقة بدقة واستخدام المعلمات الفائقة الافتراضية المختارة من قياس الأداء الواسع لضمان التدريب الفعال. يلخص الجدول أدناه هذه النماذج المنسقة.
| المهمة | بنى النموذج | صيغة أوامر سلسلة حرفية |
|---|---|---|
| تصنيف الصورة (متعدد الفئات ومتعددة التسميات) |
بيت فيتامين DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| الكشف عن العنصر | Sparse R-CNN DETR قابل للتشويه VFNet YOLOF Swin |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| تجزئة المثيل | Swin | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
نقوم بتحديث قائمة النماذج المنسقة باستمرار. يمكنك الحصول على أحدث قائمة بالنماذج المنسقة لمهمة معينة باستخدام Python SDK:
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
إخراج:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
سيؤدي استخدام أي نموذج HuggingFace أو MMDetection إلى تشغيل التشغيل باستخدام مكونات البنية الأساسية لبرنامج ربط العمليات التجارية. إذا تم استخدام كل من النماذج القديمة و HuggingFace/MMdetection، فسيتم تشغيل جميع عمليات التشغيل/الإصدارات التجريبية باستخدام المكونات.
بالإضافة إلى التحكم في بنية النموذج، يمكنك أيضا ضبط المعلمات الفائقة المستخدمة لتدريب النموذج. في حين أن العديد من المعلمات الفائقة المكشوفة غير محددة للنموذج، هناك مثيلات تكون فيها المعلمات الفائقة خاصة بالمهمة أو خاصة بالنموذج. تعرّف على المزيد حول المعلمات الفائقة المتوفرة لهذه المثيلات.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
إذا كنت ترغب في استخدام قيم المعلمات الفائقة الافتراضية لبنية معينة (على سبيل المثال yolov5)، يمكنك تحديدها باستخدام مفتاح model_name في قسم training_parameters. على سبيل المثال،
training_parameters:
model_name: yolov5
مسح المعلمات الفائقة للنموذج يدويا
عند تدريب نماذج رؤية الكمبيوتر، يعتمد أداء النموذج اعتماداً كبيراً على قيم المعلمة الفائقة المحددة. في كثير من الأحيان، قد ترغب في ضبط المعلمات الفائقة للحصول على الأداء الأمثل. بالنسبة لمهام رؤية الكمبيوتر، يمكنك مسح المعلمات الفائقة للعثور على الإعدادات المثلى لنموذجك. تطبق هذه الميزة إمكانات ضبط المعلمات الفائقة في التعلم الآلي من Microsoft Azure. تعرّف على كيفية ضبط المعلمات الفائقة.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
تحديد مساحة البحث عن المعلمة
يمكنك تحديد بنيات النموذج والمقاييس الفائقة للمسح في مساحة المعلمة. يمكنك إما تحديد بنية نموذج واحد أو عدة بنية.
- راجع الإصدارات التجريبية الفردية لقائمة بنيات النموذج المدعومة لكل نوع مهمة.
- اطّلع على المعلمات الفائقة المعلمات الفائقة لمهام رؤية الكمبيوتر لكل نوع مهمة لرؤية الكمبيوتر.
- اطّلع على تفاصيل حول التوزيعات المدعومة للمعلمات الفائقة المنفصلة والمستمرة.
أساليب أخذ العينات للمسح
عند مسح المعلمات الفائقة، عليك تحديد أسلوب أخذ العينات لاستخدامه للمسح على مساحة المعلمة المحددة. يتم حاليًا دعم أساليب أخذ العينات التالية مع المعلمة sampling_algorithm:
| نوع أخذ العينات | صيغة أوامر وظيفة AutoML |
|---|---|
| أخذ عينات عشوائية | random |
| أخذ عينات الشبكة | grid |
| أخذ العينات البايزية | bayesian |
إشعار
حاليا يدعم أخذ العينات العشوائية والشبكية فقط مسافات المعلمات الفائقة الشرطية.
نُهج الإنهاء المبكر
يمكنك إنهاء الإصدارات التجريبية ذات الأداء الضعيف تلقائيا باستخدام نهج الإنهاء المبكر. يعمل الإنهاء المبكر على تحسين الكفاءة الحسابية، مما يوفر موارد الحوسبة التي كانت ستنفق لولا ذلك على تجارب أقل وعدا. يدعم التعلم الآلي التلقائي للصور نُهج الإنهاء المبكر التالية باستخدام المعلمة early_termination. إذا لم يتم تحديد نهج إنهاء، يتم تشغيل جميع الإصدارات التجريبية حتى الاكتمال.
| نهج الإنهاء المبكر | صيغة أوامر وظيفة AutoML |
|---|---|
| سياسة اللصوص | الإصدار 2 من CLI: bandit الإصدار 2 من SDK: BanditPolicy() |
| نهج الإيقاف الوسيط | الإصدار 2 من CLI: median_stopping الإصدار 2 من SDK: MedianStoppingPolicy() |
| نهج تحديد الاقتطاع | الإصدار 2 من CLI: truncation_selection الإصدار 2 من SDK: TruncationSelectionPolicy() |
تعرّف على المزيد حول كيفية تكوين نهج الإنهاء المبكر لمسح المعلمات الفائقة.
إشعار
للحصول على عينة تكوين مسح كاملة، يرجى الرجوع إلى هذا البرنامج التعليمي.
يمكنك تكوين جميع المعلمات ذات الصلة بالمسح كما هو موضح في المثال التالي.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
الإعدادات الثابتة
يمكنك تمرير الإعدادات أو المعلمات الثابتة التي لا تتغير أثناء مسح مساحة المعلمة كما هو موضح في المثال التالي.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
training_parameters:
early_stopping: True
evaluation_frequency: 1
زيادة البيانات
بشكل عام، يمكن أن يتحسن أداء نموذج التعلم العميق في كثير من الأحيان بمزيد من البيانات. زيادة البيانات هي تقنية عملية لتضخيم حجم البيانات وتقلب مجموعة البيانات، مما يساعد على منع الملاءمة الزائدة وتحسين قدرة النموذج على التعميم على البيانات غير المرئية. يطبق التعلم الآلي التلقائي تقنيات مختلفة لزيادة البيانات حسب مهمة رؤية الكمبيوتر، قبل تغذية الصور المدخلة إلى النموذج. لا يوجد حالياً معلمة فائقة مكشوفة للتحكم في زيادة البيانات.
| المهمة | مجموعة البيانات المتأثرة | تطبيق تقنية (تقنيات) زيادة البيانات |
|---|---|---|
| تصنيف الصور (متعدد الفئات ومتعدد الملصقات) | التدريب التحقق من الصحة واختباره |
تغيير الحجم والقص العشوائي، والعكس الأفقي، وتشويه الألوان (السطوع والتباين والتشبع واللون)، والتطبيع باستخدام متوسط ImageNet من خلال القناة والانحراف المعياري تغيير الحجم وقص المركز والتسوية |
| كشف العنصر وتجزئة المثيل | التدريب التحقق من الصحة واختباره |
اقتصاص عشوائي حول المربعات المحيطة، والتوسيع، والعكس الأفقي، والتطبيع، وتغيير الحجم التسوية وتغيير الحجم |
| كشف العنصر باستخدام yolov5 | التدريب التحقق من الصحة واختباره |
فسيفساء، أفين عشوائي (تدوير، ترجمة، مقياس، مقص)، انعكاس أفقي تغيير حجم تنسيق letterbox |
حاليا يتم تطبيق التعزيزات المعرفة أعلاه بشكل افتراضي على التعلم الآلي التلقائي لمهمة الصورة. لتوفير التحكم في عمليات التعزيز، يعرض التعلم الآلي التلقائي للصور أقل من اثنتين من العلامات لإيقاف تشغيل بعض عمليات التعزيز. حاليا، يتم دعم هذه العلامات فقط لمهام الكشف عن الكائنات وتجزئة المثيل.
- apply_mosaic_for_yolo: هذه العلامة خاصة فقط بنموذج Yolo. يؤدي تعيينه إلى False إلى إيقاف تشغيل زيادة بيانات الفسيفساء، والتي يتم تطبيقها في وقت التدريب.
- apply_automl_train_augmentations: يؤدي تعيين هذه العلامة إلى خطأ إلى إيقاف تشغيل الزيادة المطبقة أثناء وقت التدريب لنماذج الكشف عن الكائنات وتجزئة المثيل. للحصول على عمليات زيادة، راجع التفاصيل في الجدول أعلاه.
- بالنسبة لنموذج الكشف عن الكائنات غير yolo ونماذج تجزئة المثيل، توقف هذه العلامة عمليات التعزيز الثلاثة الأولى فقط. على سبيل المثال: اقتصاص عشوائي حول المربعات المحيطة، والتوسيع، والعكس الأفقي. لا يزال يتم تطبيق التطبيع وتغيير حجم الزيادة بغض النظر عن هذه العلامة.
- بالنسبة لنموذج Yolo، توقف هذه العلامة عن تكبيرات الزعانف العشوائية والأفقية.
يتم دعم هاتين العلامتين عبر advanced_settings ضمن training_parameters ويمكن التحكم فيهما بالطريقة التالية.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
لاحظ أن هاتين العلامتين مستقلتان عن بعضهما البعض ويمكن استخدامهما أيضا في تركيبة باستخدام الإعدادات التالية.
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
في تجاربنا، وجدنا أن هذه التعزيزات تساعد النموذج على التعميم بشكل أفضل. لذلك، عند إيقاف تشغيل هذه التعزيزات، نوصي المستخدمين بدمجها مع عمليات زيادة أخرى دون اتصال للحصول على نتائج أفضل.
تدريب تزايدي (اختياري)
بمجرد الانتهاء من مهمة التدريب، يمكنك اختيار تدريب النموذج بشكل أكبر عن طريق تحميل نقطة فحص النموذج المدربة. يمكنك إما استخدام نفس مجموعة البيانات أو مجموعة مختلفة للتدريب التزايدي. إذا كنت راضيا عن النموذج، يمكنك اختيار إيقاف التدريب واستخدام النموذج الحالي.
تمرير نقطة التحقق عبر معرف الوظيفة
يمكنك تمرير معرف الوظيفة الذي تريد تحميل نقطة التحقق منه.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
إرسال وظيفة AutoML
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
لإرسال وظيفة AutoML، يمكنك تشغيل أمر CLI v2 التالي مع المسار إلى ملف .yml واسم مساحة العمل ومجموعة الموارد ومعرّف الاشتراك.
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
المخرجات ومقاييس التقييم
تنشئ مهام التدريب الآلي على التعلم الآلي ملفات نموذج الإخراج ومقاييس التقييم والسجلات وبيانات التوزيع الاصطناعية مثل ملف التسجيل وملف البيئة. يمكن عرض هذه الملفات والمقاييس من علامة تبويب المخرجات والسجلات والمقاييس للوظائف التابعة.
تلميح
تحقق من كيفية الانتقال إلى نتائج المهمة من قسم عرض نتائج المهمة.
للحصول على تعريفات وأمثلة للمخططات البيانية عن الأداء والمقاييس المقدمة لكل وظيفة، راجع تقييم نتائج تجربة التعلم الآلي التلقائي.
تسجيل النموذج وتوزيعه
بمجرد اكتمال المهمة، يمكنك تسجيل النموذج الذي تم إنشاؤه من أفضل تجربة (التكوين الذي أدى إلى أفضل مقياس أساسي). يمكنك إما تسجيل النموذج بعد التنزيل أو عن طريق تحديد مسار azureml مع معرّف الوظيفة المقابل. ملاحظة: عندما تريد تغيير إعدادات الاستدلال الموضحة أدناه، تحتاج إلى تنزيل النموذج وتغيير settings.json والتسجيل باستخدام مجلد النموذج المحدث.
الحصول على أفضل تجربة
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
CLI example not available, please use Python SDK.
تسجيل النموذج
سجّل النموذج إما باستخدام مسار azureml أو المسار الذي تم تنزيله محليًا.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
بعد تسجيل النموذج الذي تريد استخدامه، يمكنك توزيعه باستخدام نقطة النهاية المُدارة عبر الإنترنت deploy-managed-online-endpoint
تكوين نقطة النهاية عبر الإنترنت
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
أنشئ نقطة النهاية
باستخدام الذي MLClient تم إنشاؤه سابقا، نقوم بإنشاء نقطة النهاية في مساحة العمل. يبدأ هذا الأمر إنشاء نقطة النهاية ويعيد استجابة تأكيد أثناء استمرار إنشاء نقطة النهاية.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
تكوين التوزيع عبر الإنترنت
يشكل التوزيع مجموعة من الموارد اللازمة لاستضافة النموذج الذي يقوم بالاستدلال الفعلي. سننشئ توزيع لنقطة النهاية الخاصة بنا باستخدام الفئة ManagedOnlineDeployment. يمكنك استخدام وحدات SKU لوحدة معالجة الرسومات أو وحدة المعالجة المركزية الظاهرية لمجموعة التوزيع لديك.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
إنشاء النشر
باستخدام MLClient الذي تم إنشاؤه مسبقاً، سننشئ الآن التوزيع في مساحة العمل. سيبدأ هذا الأمر في إنشاء التوزيع ويعيد استجابة التأكيد أثناء استمرار إنشاء التوزيع.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
تحديث نسبة استخدام الشبكة:
يُعيّن التوزيع الحالي بشكل افتراضي لتلقي 0% من نسبة استخدام الشبكة. يمكنك تعيين النسبة المئوية لنسبة استخدام الشبكة التي يجب أن يتلقاها التوزيع الحالي. مجموع النسب المئوية لنسبة استخدام الشبكة لجميع عمليات التوزيع ذات نقطة نهاية واحدة يجب ألا يتجاوز 100٪.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
بدلاً من ذلك، يمكنك توزيع النموذج من واجهة مستخدم استوديو التعلم الآلي من Microsoft Azure. انتقل إلى النموذج الذي ترغب في نشره في علامة تبويب النماذج لوظيفة التعلم الآلي المؤتمت وحدد نشر وحدد Deploy to real-time endpoint .
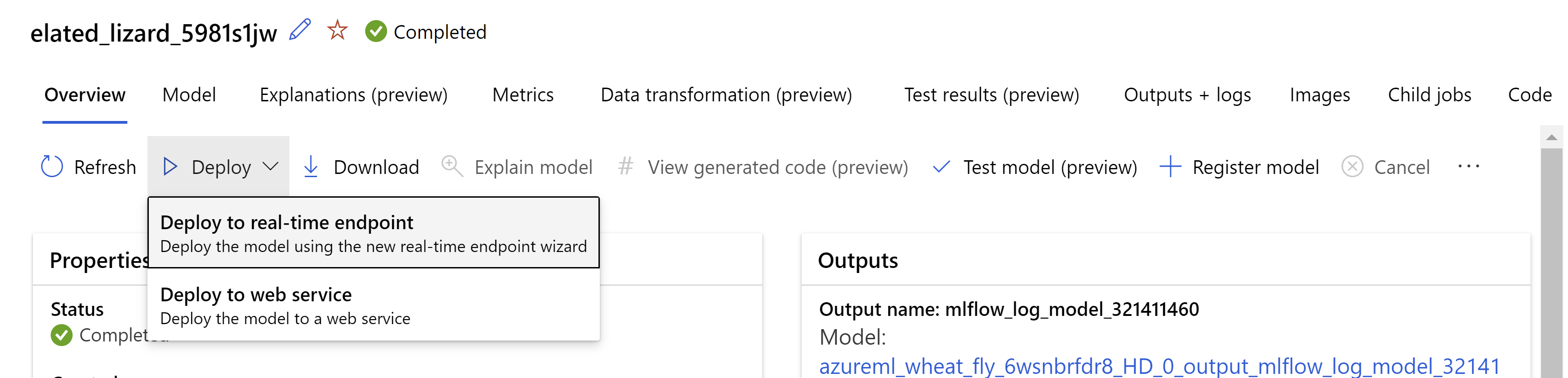 .
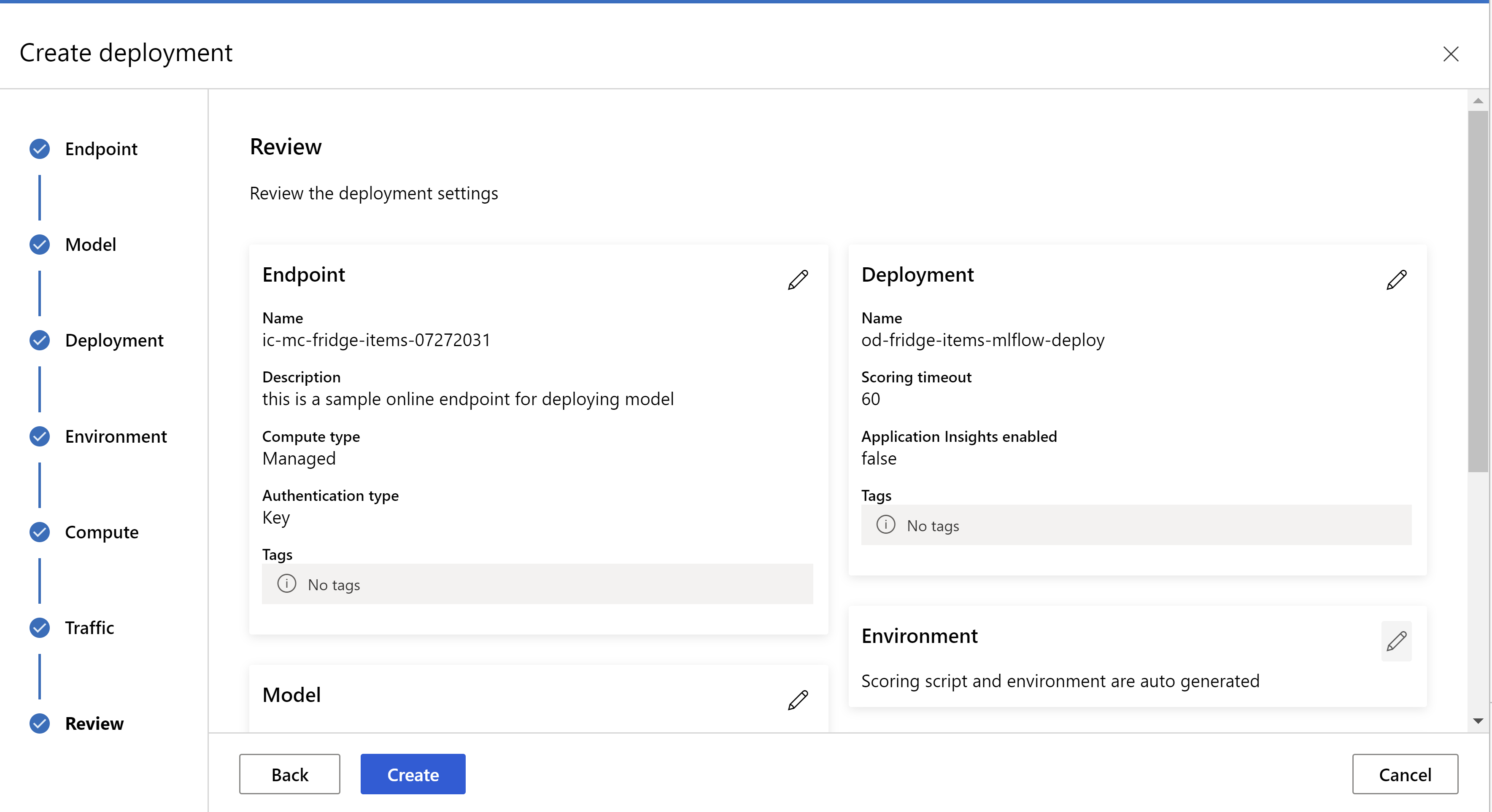
.
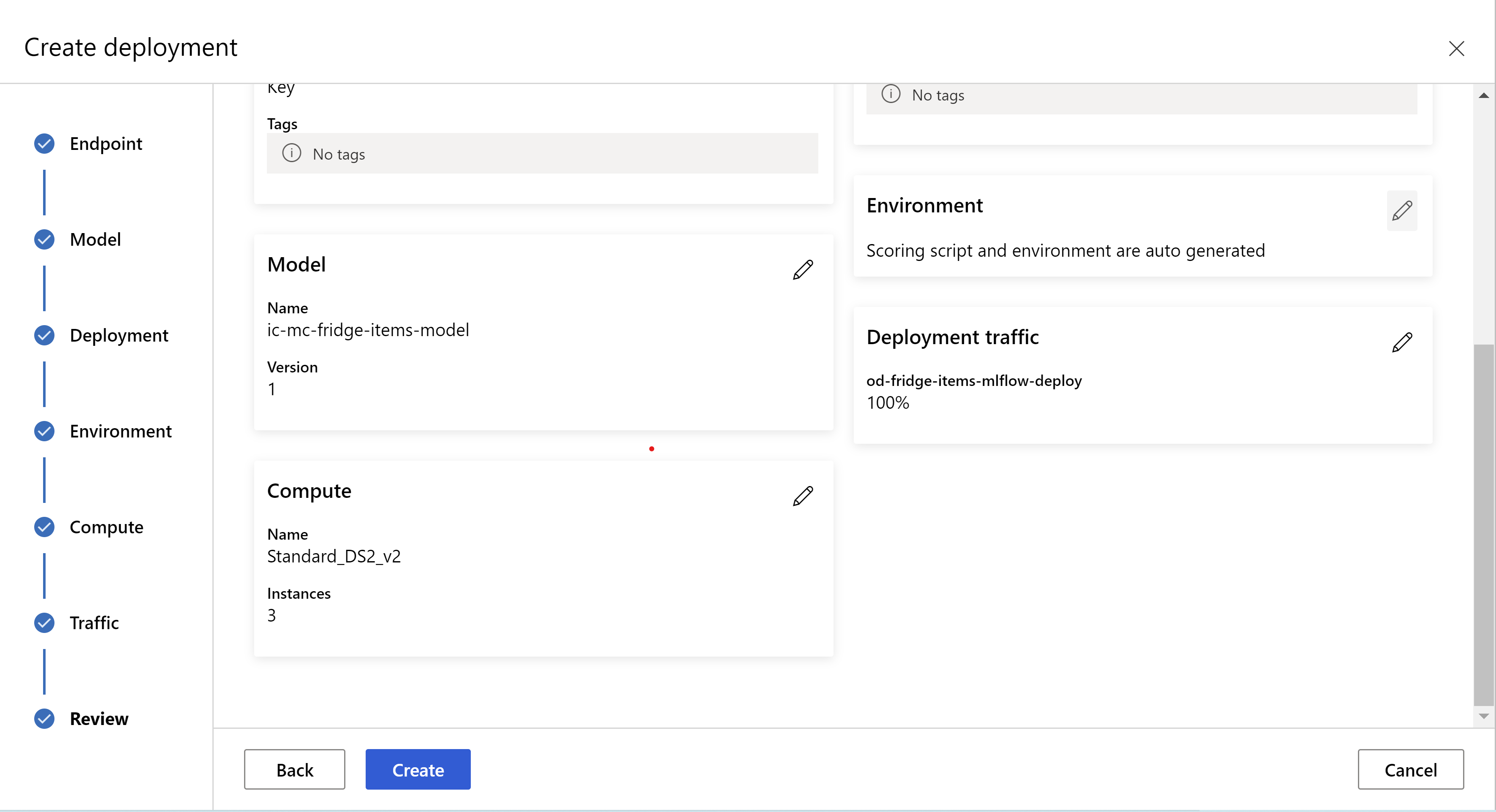
هكذا تبدو صفحة "المراجعة". يمكننا تحديد نوع المثيل وعدد المثيلات وتعيين نسبة استخدام الشبكة للتوزيع الحالي.
 .
.
 .
.
تحديث إعدادات الاستدلال
نزّلنا في الخطوة السابقة ملف mlflow-model/artifacts/settings.json من أفضل نموذج. والذي يمكن استخدامه لتحديث إعدادات الاستدلال قبل تسجيل النموذج. على الرغم من أنه من المستحسن استخدام نفس المعلمات مثل التدريب للحصول على أفضل أداء.
تحتوي كل مهمة من المهام (وبعض النماذج) على مجموعة من المعلمات. بشكل افتراضي، نستخدم نفس القيم للمعلمات التي تم استخدامها أثناء التدريب والتحقق من الصحة. اعتماداً على السلوك الذي نحتاجه عند استخدام النموذج للاستدلال، يمكننا تغيير هذه المعلمات. يمكنك العثور أدناه على قائمة المعلمات لكل نوع مهمة ونموذج.
| المهمة | اسم المعلمة | الإعداد الافتراضي |
|---|---|---|
| تصنيف الصور (متعدد الفئات ومتعدد الملصقات) | valid_resize_sizevalid_crop_size |
256 224 |
| كشف الكائنات | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0.5 100 |
الكشف عن العناصر باستخدام yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 متوسطة 0.1 0.5 |
| تجزئة مثيل الصورة | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0.5 100 0.5 100 خطأ JPG |
للحصول على وصف مفصل حول المعلمات الفائقة الخاصة بالمهمة، راجع Hyperparameters لمهام رؤية الكمبيوتر في التعلم الآلي التلقائي.
إذا كنت تريد استخدام التجانب، وتريد التحكم في سلوك التجانب، تتوفر المعلمات التالية: tile_grid_size وtile_overlap_ratio وtile_predictions_nms_thresh. لمزيد من التفاصيل حول هذه المعلمات، تحقق من تدريب نموذج صغير للكشف عن الكائنات باستخدام AutoML.
اختبر التوزيع
تحقق من قسم اختبار التوزيع هذا لاختبار التوزيع وتصور الاكتشافات من النموذج.
إنشاء تفسيرات للتنبؤات
هام
هذه الإعدادات حاليا في المعاينة العامة. يتم توفيرها دون اتفاقية على مستوى الخدمة. بعض الميزات ربما لا تكون مدعمة أو بها بعض القدرات المقيدة. لمزيد من المعلومات، راجع شروط الاستخدام التكميلية لمعاينات Microsoft Azure.
تحذير
يتم دعم Model Explainability فقط للتصنيفمتعدد الفئات والتصنيف متعدد التسميات.
بعض مزايا استخدام الذكاء الاصطناعي القابلة للشرح (XAI) مع AutoML للصور:
- تحسين الشفافية في تنبؤات نموذج الرؤية المعقدة
- يساعد المستخدمين على فهم الميزات/وحدات البكسل المهمة في صورة الإدخال التي تساهم في تنبؤات النموذج
- يساعد في استكشاف أخطاء النماذج وإصلاحها
- يساعد في اكتشاف التحيز
تفسيرات
التفسيرات هي سمات الميزة أو الأوزان المعطاة لكل بكسل في صورة الإدخال بناء على مساهمتها في تنبؤ النموذج. يمكن أن يكون كل وزن سالبا (مرتبطا سلبا بالتنبؤ) أو موجبا (مرتبطا بشكل إيجابي بالتنبؤ). يتم حساب هذه الإسنادات مقابل الفئة المتوقعة. بالنسبة للتصنيف متعدد الفئات، يتم إنشاء مصفوفة إسناد واحدة بالضبط من الحجم [3, valid_crop_size, valid_crop_size] لكل عينة، بينما بالنسبة للتصنيف متعدد التسميات، يتم إنشاء مصفوفة الإسناد من الحجم [3, valid_crop_size, valid_crop_size] لكل تسمية/فئة متوقعة لكل عينة.
باستخدام الذكاء الاصطناعي القابلة للتفسير في AutoML للصور على نقطة النهاية المنشورة، يمكن للمستخدمين الحصول على مرئيات للتفسيرات (الإسنادات متراكبة على صورة إدخال) و/أو الإسنادات (صفيف متعدد الأبعاد من الحجم [3, valid_crop_size, valid_crop_size]) لكل صورة. وبصرف النظر عن المرئيات، يمكن للمستخدمين أيضا الحصول على مصفوفات الإسناد للحصول على مزيد من التحكم في التفسيرات (مثل إنشاء تصورات مخصصة باستخدام الإسنادات أو فحص أجزاء من الإسنادات). تستخدم جميع خوارزميات التفسير صور مربعة مقتصة بحجم valid_crop_size لإنشاء السمات.
يمكن إنشاء التفسيرات إما من نقطة النهاية عبر الإنترنت أو نقطة نهاية الدفعة. بمجرد الانتهاء من النشر، يمكن استخدام نقطة النهاية هذه لإنشاء تفسيرات للتنبؤات. في عمليات النشر عبر الإنترنت، تأكد من تمرير request_settings = OnlineRequestSettings(request_timeout_ms=90000) المعلمة إلى ManagedOnlineDeployment وتعيين request_timeout_ms إلى قيمتها القصوى لتجنب مشكلات المهلة أثناء إنشاء تفسيرات (راجع قسم تسجيل النموذج ونشره). بعض أساليب الشرح (XAI) مثل xrai استهلاك المزيد من الوقت (خصيصا للتصنيف متعدد التسميات لأننا بحاجة إلى إنشاء إسنادات و/أو مرئيات مقابل كل تسمية متوقعة). لذلك، نوصي بأي مثيل GPU للحصول على تفسيرات أسرع. لمزيد من المعلومات حول مخطط الإدخال والإخراج لإنشاء تفسيرات، راجع مستندات المخطط.
ندعم خوارزميات قابلية التفسير المتطورة التالية في AutoML للصور:
- XRAI (xrai)
- تدرجات متكاملة (integrated_gradients)
- GradCAM الموجه (guided_gradcam)
- Guided BackPropagation (guided_backprop)
يصف الجدول التالي معلمات ضبط خوارزمية قابلية الشرح الخاصة ب XRAI والتدرجات المتكاملة. لا يتطلب توفير الخلفية الموجه وكاميرا الدرجات الإرشادية أي معلمات ضبط.
| خوارزمية XAI | معلمات محددة للخوارزمية | القيم الافتراضية |
|---|---|---|
xrai |
1. n_steps: عدد الخطوات المستخدمة بواسطة أسلوب التقريب. يؤدي العدد الأكبر من الخطوات إلى تقريب أفضل للإسنادات (التفسيرات). نطاق n_steps هو [2، inf)، ولكن يبدأ أداء الإسنادات في التقارب بعد 50 خطوة. Optional, Int 2. xrai_fast: ما إذا كنت تريد استخدام إصدار أسرع من XRAI. إذا ، Trueفإن وقت الحساب للتفسيرات أسرع ولكنه يؤدي إلى تفسيرات أقل دقة (الإسنادات) Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps: عدد الخطوات المستخدمة بواسطة أسلوب التقريب. يؤدي العدد الأكبر من الخطوات إلى إسنادات أفضل (تفسيرات). نطاق n_steps هو [2، inf)، ولكن يبدأ أداء الإسنادات في التقارب بعد 50 خطوة.Optional, Int 2. approximation_method: طريقة لتقريب التكامل. أساليب التقريب المتوفرة هي riemann_middle و gausslegendre.Optional, String |
n_steps = 50 approximation_method = riemann_middle |
تستخدم خوارزمية XRAI داخليا تدرجات متكاملة. لذلك، n_steps المعلمة مطلوبة من قبل كل من التدرجات المتكاملة وخوارزميات XRAI. يستهلك عدد أكبر من الخطوات مزيدا من الوقت لتقريب التفسيرات وقد يؤدي ذلك إلى حدوث مشكلات في المهلة على نقطة النهاية عبر الإنترنت.
نوصي باستخدام خوارزميات التدرجات المتدرجة الإرشادية > XRAI > GradCAM > المتكاملة للحصول على تفسيرات أفضل، بينما > يوصى باستخدام التدرجات > المتدرجة المتكاملة ل GradCAM الإرشادية GradCAM > للحصول على تفسيرات أسرع بالترتيب المحدد.
يبدو نموذج الطلب إلى نقطة النهاية عبر الإنترنت كما يلي. ينشئ هذا الطلب تفسيرات عند model_explainability تعيين إلى True. ينشئ الطلب التالي مرئيات وإسنادات باستخدام إصدار أسرع من خوارزمية XRAI مع 50 خطوة.
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
لمزيد من المعلومات حول إنشاء تفسيرات، راجع مستودع دفتر ملاحظات GitHub لعينات التعلم الآلي المؤتمتة.
تفسير المرئيات
تقوم نقطة النهاية المنشورة بإرجاع سلسلة الصور المشفرة base64 إذا تم تعيين كل من model_explainability و visualizations إلى True. فك ترميز سلسلة base64 كما هو موضح في دفاتر الملاحظات أو استخدام التعليمات البرمجية التالية لفك ترميز سلاسل الصور base64 وتصورها في التنبؤ.
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
توضح الصورة التالية تصور التفسيرات لنموذج صورة إدخال.

يحتوي الشكل base64 الذي تم فك ترميزه على أربعة أقسام صور داخل شبكة 2 × 2.
- الصورة في الزاوية العلوية اليمنى (0، 0) هي صورة الإدخال المقتصة
- الصورة في الزاوية العلوية اليسرى (0، 1) هي خريطة التمثيل اللوني للإسنادات على مقياس ألوان bgyw (أزرق أخضر أصفر أبيض) حيث تكون مساهمة وحدات البكسل البيضاء في الفئة المتوقعة هي الأعلى والبكسل الأزرق هو الأدنى.
- الصورة في الزاوية السفلية اليمنى (1، 0) هي خريطة التمثيل اللوني المخلوطة من السمات على صورة الإدخال المقتصة
- الصورة في الزاوية السفلية اليسرى (1، 1) هي صورة الإدخال المقتصة مع أعلى 30 بالمائة من وحدات البكسل استنادا إلى درجات الإسناد.
تفسير الإسنادات
ترجع نقطة النهاية المنشورة الإسنادات إذا تم تعيين كل من model_explainability و attributions إلى True. لمزيد من التفاصيل، راجع دفاتر ملاحظات التصنيف متعدد الفئات والتصنيف متعدد التسميات.
تمنح هذه الإسنادات مزيدا من التحكم للمستخدمين لإنشاء مرئيات مخصصة أو لفحص درجات الإسناد على مستوى البكسل. يصف مقتطف التعليمات البرمجية التالي طريقة لإنشاء مرئيات مخصصة باستخدام مصفوفة الإسناد. لمزيد من المعلومات حول مخطط الإسنادات للتصنيف متعدد الفئات والتصنيف متعدد التسميات ، راجع مستندات المخطط.
استخدم القيم و valid_crop_size الدقيقة valid_resize_size للنموذج المحدد لإنشاء التفسيرات (القيم الافتراضية هي 256 و 224 على التوالي). تستخدم التعليمات البرمجية التالية وظيفة مرئيات Captum لإنشاء مرئيات مخصصة. يمكن للمستخدمين الاستفادة من أي مكتبة أخرى لإنشاء مرئيات. لمزيد من التفاصيل، يرجى الرجوع إلى الأدوات المساعدة لتصور captum.
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
مجموعات البيانات الكبيرة
إذا كنت تستخدم AutoML للتدريب على مجموعات البيانات الكبيرة، فهناك بعض الإعدادات التجريبية التي قد تكون مفيدة.
هام
هذه الإعدادات حاليا في المعاينة العامة. يتم توفيرها دون اتفاقية على مستوى الخدمة. بعض الميزات ربما لا تكون مدعمة أو بها بعض القدرات المقيدة. لمزيد من المعلومات، راجع شروط الاستخدام التكميلية لمعاينات Microsoft Azure.
تدريب متعدد GPU ومتعددة العقد
بشكل افتراضي، يتدرب كل نموذج على جهاز ظاهري واحد. إذا كان تدريب نموذج يستغرق وقتا طويلا، فقد يساعد استخدام الأجهزة الظاهرية التي تحتوي على وحدات معالجة الرسومات المتعددة. يجب أن ينخفض وقت تدريب نموذج على مجموعات البيانات الكبيرة بنسبة خطية تقريبا إلى عدد وحدات معالجة الرسومات المستخدمة. (على سبيل المثال، يجب أن يتدرب النموذج مرتين تقريبا بسرعة على جهاز ظاهري مع اثنين من وحدات معالجة الرسومات كما هو الحال على الجهاز الظاهري مع وحدة معالجة الرسومات واحدة.) إذا كان وقت تدريب نموذج لا يزال مرتفعا على جهاز ظاهري مع وحدات معالجة الرسومات المتعددة، يمكنك زيادة عدد الأجهزة الظاهرية المستخدمة لتدريب كل نموذج. على غرار التدريب متعدد وحدات معالجة الرسومات، يجب أن ينخفض وقت تدريب نموذج على مجموعات البيانات الكبيرة أيضا بنسبة خطية تقريبا إلى عدد الأجهزة الظاهرية المستخدمة. عند تدريب نموذج عبر أجهزة ظاهرية متعددة، تأكد من استخدام SKU حساب يدعم InfiniBand للحصول على أفضل النتائج. يمكنك تكوين عدد الأجهزة الظاهرية المستخدمة لتدريب نموذج واحد عن طريق تعيين node_count_per_trial خاصية مهمة AutoML.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
properties:
node_count_per_trial: "2"
دفق ملفات الصور من التخزين
بشكل افتراضي، يتم تنزيل جميع ملفات الصور على القرص قبل تدريب النموذج. إذا كان حجم ملفات الصور أكبر من مساحة القرص المتوفرة، تفشل المهمة. بدلا من تنزيل جميع الصور على القرص، يمكنك تحديد دفق ملفات الصور من تخزين Azure حسب الحاجة أثناء التدريب. يتم دفق ملفات الصور من تخزين Azure مباشرة إلى ذاكرة النظام، وتجاوز القرص. في الوقت نفسه، يتم تخزين أكبر عدد ممكن من الملفات من التخزين مؤقتا على القرص لتقليل عدد طلبات التخزين.
إشعار
إذا تم تمكين الدفق، فتأكد من وجود حساب تخزين Azure في نفس المنطقة مثل الحساب لتقليل التكلفة وزمن الانتقال.
ينطبق على:ملحق CLI للتعلم الآلي من Microsoft Azure v2 (الحالي)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
مثال دفاتر الملاحظات
راجع أمثلة التعليمات البرمجية التفصيلية وحالات الاستخدام في مستودع دفتر الملاحظات GitHub لعينات التعلم الآلي. تحقق من المجلدات باستخدام بادئة "automl-image-" للحصول على عينات خاصة بإنشاء نماذج رؤية الكمبيوتر.
أمثلة على التعليمات البرمجية
راجع الأمثلة التفصيلية للتعليمات البرمجية وحالات الاستخدام في مستودع azureml-examples لعينات التعلم الآلي.