إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: ملحق التعلم الآلي من Azure CLI v2 (الحالي)
ملحق التعلم الآلي من Azure CLI v2 (الحالي)
في هذه المقالة، سترى كيفية نشر نموذج MLflow الخاص بك إلى نقطة نهاية عبر الإنترنت للاستدلال في الوقت الفعلي. عند نشر نموذج MLflow الخاص بك إلى نقطة نهاية عبر الإنترنت، لا تحتاج إلى تحديد برنامج نصي لتسجيل النقاط أو بيئة، تعرف هذه الوظيفة باسم النشر بدون تعليمات برمجية.
من أجل عدم نشر التعليمات البرمجية، التعلم الآلي من Azure:
- تثبيت حزم Python التي تقوم بإدراجها في ملف conda.yaml ديناميكيا. ونتيجة لذلك، يتم تثبيت التبعيات أثناء وقت تشغيل الحاوية.
- يوفر صورة أساسية MLflow أو بيئة منسقة تحتوي على العناصر التالية:
- الحزمة
azureml-inference-server-http - الحزمة
mlflow-skinny - برنامج نصي لتسجيل النقاط للاستدلال
- الحزمة
Prerequisites
اشتراك Azure. في حال لم يكن لديك اشتراك Azure، فأنشئ حساباً مجانيّاً قبل البدء.
حساب مستخدم يحتوي على واحد على الأقل من أدوار التحكم في الوصول استنادا إلى الدور (Azure RBAC) التالية:
- دور المالك لمساحة عمل التعلم الآلي من Azure
- دور مساهم لمساحة عمل التعلم الآلي من Azure
- دور مخصص لديه
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*أذونات
لمزيد من المعلومات، راجع إدارة الوصول إلى مساحات عمل التعلم الآلي من Azure.
الوصول إلى التعلم الآلي من Azure:
تثبيت Azure CLI والملحق
mlإلى Azure CLI. للحصول على خطوات التثبيت، راجع تثبيت وإعداد CLI (v2).
حول المثال
يوضح لك المثال في هذه المقالة كيفية نشر نموذج MLflow إلى نقطة نهاية عبر الإنترنت لتنفيذ التنبؤات. يستخدم المثال نموذج MLflow الذي يستند إلى مجموعة بيانات مرض السكري. تحتوي مجموعة البيانات هذه على 10 متغيرات أساسية: العمر والجنس ومؤشر كتلة الجسم ومتوسط ضغط الدم و6 قياسات مصل الدم التي تم الحصول عليها من 442 مريضا بمرض السكري. كما أنه يحتوي على استجابة الاهتمام، وهو مقياس كمي لتطور المرض بعد عام واحد من تاريخ البيانات الأساسية.
تم تدريب النموذج باستخدام تراجع scikit-learn . يتم حزم جميع المعالجة المسبقة المطلوبة كبنية أساسية لبرنامج ربط العمليات التجارية، لذلك هذا النموذج هو مسار شامل ينتقل من البيانات الأولية إلى التنبؤات.
تستند المعلومات الواردة في هذه المقالة إلى عينات التعليمات البرمجية من مستودع azureml-examples . إذا قمت باستنساخ المستودع، يمكنك تشغيل الأوامر في هذه المقالة محليا دون الحاجة إلى نسخ ملفات YAML والملفات الأخرى أو لصقها. استخدم الأوامر التالية لاستنساخ المستودع والانتقال إلى المجلد للغة الترميز الخاصة بك:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
المتابعة في Jupyter Notebook
لمتابعة الخطوات الواردة في هذه المقالة، راجع دفتر ملاحظات نشر نموذج MLflow إلى نقاط النهاية عبر الإنترنت في مستودع الأمثلة.
الاتصال بمساحة العمل الخاصة بك
الاتصال بمساحة عمل التعلم الآلي من Azure:
az account set --subscription <subscription-ID>
az configure --defaults workspace=<workspace-name> group=<resource-group-name> location=<location>
تسجيل النموذج
يمكنك نشر النماذج المسجلة فقط إلى نقاط النهاية عبر الإنترنت. تستخدم الخطوات الواردة في هذه المقالة نموذجا مدربا على مجموعة بيانات مرض السكري. في هذه الحالة، لديك بالفعل نسخة محلية من النموذج في المستودع المستنسخ، لذلك تحتاج فقط إلى نشر النموذج إلى السجل في مساحة العمل. يمكنك تخطي هذه الخطوة إذا كان النموذج الذي تريد نشره مسجلا بالفعل.
MODEL_NAME='sklearn-diabetes'
az ml model create --name $MODEL_NAME --type "mlflow_model" --path "endpoints/online/ncd/sklearn-diabetes/model"

ماذا لو تم تسجيل النموذج الخاص بك داخل تشغيل؟
إذا تم تسجيل النموذج الخاص بك داخل تشغيل، يمكنك تسجيله مباشرة.
لتسجيل النموذج، تحتاج إلى معرفة موقع التخزين الخاص به:
- إذا كنت تستخدم ميزة MLflow
autolog، يعتمد المسار إلى النموذج على نوع النموذج وإطار العمل. تحقق من إخراج الوظيفة لتحديد اسم مجلد النموذج. يحتوي هذا المجلد على ملف يسمى MLModel. - إذا كنت تستخدم
log_modelالأسلوب لتسجيل النماذج يدويا، يمكنك تمرير المسار إلى النموذج كوسيطة لهذا الأسلوب. على سبيل المثال، إذا كنت تستخدمmlflow.sklearn.log_model(my_model, "classifier")لتسجيل النموذج،classifierفهو المسار الذي يتم تخزين النموذج عليه.
يمكنك استخدام Azure Machine Learning CLI v2 لإنشاء نموذج من إخراج مهمة التدريب. تستخدم التعليمات البرمجية التالية البيانات الاصطناعية لوظيفة ذات معرف $RUN_ID لتسجيل نموذج يسمى $MODEL_NAME.
$MODEL_PATH هو المسار الذي تستخدمه الوظيفة لتخزين النموذج.
az ml model create --name $MODEL_NAME --path azureml://jobs/$RUN_ID/outputs/artifacts/$MODEL_PATH

نشر نموذج MLflow إلى نقطة نهاية عبر الإنترنت
استخدم التعليمات البرمجية التالية لتكوين الاسم ووضع المصادقة لنقطة النهاية التي تريد توزيع النموذج إليها:
تعيين اسم نقطة نهاية عن طريق تشغيل الأمر التالي. أولا استبدل
YOUR_ENDPOINT_NAMEباسم فريد.export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"لتكوين نقطة النهاية الخاصة بك، قم بإنشاء ملف YAML باسم create-endpoint.yaml يحتوي على الأسطر التالية:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json name: my-endpoint auth_mode: keyإنشاء نقطة النهاية:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/ncd/create-endpoint.yamlتكوين النشر. التوزيع هو مجموعة من الموارد المطلوبة لاستضافة النموذج الذي يقوم بالاستدلال الفعلي.
أنشئ ملف YAML باسم sklearn-deployment.yaml يحتوي على الأسطر التالية:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: sklearn-deployment endpoint_name: my-endpoint model: name: mir-sample-sklearn-ncd-model version: 2 path: sklearn-diabetes/model type: mlflow_model instance_type: Standard_DS3_v2 instance_count: 1Note
يتم دعم الجيل التلقائي من
scoring_scriptوenvironmentفقط لنكهةPyFuncالنموذج. لاستخدام نكهة نموذج مختلفة، راجع تخصيص عمليات نشر نموذج MLflow.إنشاء النشر:
az ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficaz ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficتعيين كافة نسبة استخدام الشبكة إلى النشر. حتى الآن، تحتوي نقطة النهاية على نشر واحد، ولكن لم يتم تعيين أي من حركة المرور الخاصة بها إليها.
هذه الخطوة غير مطلوبة في Azure CLI إذا كنت تستخدم العلامة
--all-trafficأثناء الإنشاء. إذا كنت بحاجة إلى تغيير نسبة استخدام الشبكة، يمكنك استخدامaz ml online-endpoint update --trafficالأمر . لمزيد من المعلومات حول كيفية تحديث حركة المرور، راجع تحديث نسبة استخدام الشبكة تدريجيا.تحديث تكوين نقطة النهاية:
هذه الخطوة غير مطلوبة في Azure CLI إذا كنت تستخدم العلامة
--all-trafficأثناء الإنشاء. إذا كنت بحاجة إلى تغيير حركة المرور، يمكنك استخدامaz ml online-endpoint update --trafficالأمر . لمزيد من المعلومات حول كيفية تحديث حركة المرور، راجع تحديث نسبة استخدام الشبكة تدريجيا.


استدعاء نقطة النهاية
عندما يكون النشر جاهزا، يمكنك استخدامه لخدمة الطلبات. تتمثل إحدى طرق اختبار النشر في استخدام إمكانية استدعاء المضمنة في عميل النشر الخاص بك. في مستودع الأمثلة، يحتوي ملف sample-request-sklearn.json على التعليمات البرمجية JSON التالية. يمكنك استخدامه كملف طلب عينة للنشر.
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
Note
يستخدم input_data هذا الملف المفتاح بدلا من inputs، الذي تستخدمه خدمة MLflow. يتطلب التعلم الآلي من Azure تنسيق إدخال مختلف ليتمكن من إنشاء عقود Swagger تلقائيا لنقاط النهاية. لمزيد من المعلومات حول تنسيقات الإدخال المتوقعة، راجع النشر في خادم MLflow المضمن مقابل النشر في خادم الاستدلال للتعلم الآلي من Microsoft Azure.
إرسال طلب إلى نقطة النهاية:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
يجب أن تكون الاستجابة مشابهة للنص التالي:
[
11633.100167144921,
8522.117402884991
]
Important
بالنسبة إلى MLflow بدون نشر التعليمات البرمجية، لا يتم حاليا دعم الاختبار عبر نقاط النهاية المحلية .
تخصيص عمليات نشر نموذج MLflow
لا يتعين عليك تحديد برنامج نصي لتسجيل النقاط في تعريف التوزيع لنموذج MLflow إلى نقطة نهاية عبر الإنترنت. ولكن يمكنك تحديد برنامج نصي لتسجيل النقاط إذا كنت تريد تخصيص عملية الاستدلال الخاصة بك.
عادة ما تريد تخصيص توزيع نموذج MLflow في الحالات التالية:
- لا يحتوي النموذج على نكهة
PyFunc. - تحتاج إلى تخصيص الطريقة التي تشغل بها النموذج. على سبيل المثال، تحتاج إلى استخدام
mlflow.<flavor>.load_model()نكهة معينة لتحميل النموذج. - تحتاج إلى إجراء المعالجة المسبقة أو المعالجة اللاحقة في روتين التسجيل الخاص بك، لأن النموذج لا يقوم بهذه المعالجة.
- لا يمكن تمثيل إخراج النموذج بشكل جيد في البيانات الجدولية. على سبيل المثال، الإخراج هو موتر يمثل صورة.
Important
إذا قمت بتحديد برنامج نصي لتسجيل النقاط لنشر نموذج MLflow، يجب عليك أيضا تحديد البيئة التي يتم تشغيل التوزيع فيها.
نشر برنامج نصي مخصص لتسجيل النقاط
لنشر نموذج MLflow يستخدم برنامجا نصيا مخصصا لتسجيل النقاط، اتبع الخطوات الواردة في الأقسام التالية.
تحديد مجلد النموذج
حدد المجلد الذي يحتوي على نموذج MLflow الخاص بك عن طريق اتخاذ الخطوات التالية:
انتقل إلى Azure التعلم الآلي studio.
انتقل إلى قسم النماذج .
حدد النموذج الذي تريد نشره وانتقل إلى علامة التبويب البيانات الاصطناعية الخاصة به.
دون المجلد المعروض. عند تسجيل نموذج، يمكنك تحديد هذا المجلد.
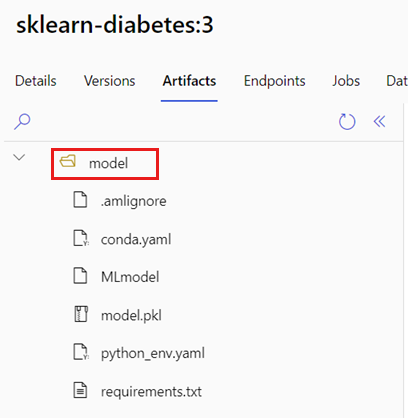

إنشاء برنامج نصي لتسجيل النقاط
يوفر البرنامج النصي لتسجيل النقاط التالي، score.py، مثالا على كيفية إجراء الاستدلال باستخدام نموذج MLflow. يمكنك تكييف هذا البرنامج النصي لاحتياجاتك أو تغيير أي من أجزائه ليعكس السيناريو الخاص بك. لاحظ أن اسم المجلد الذي حددته مسبقا، model، مضمن في الدالة init() .
import logging
import os
import json
import mlflow
from io import StringIO
from mlflow.pyfunc.scoring_server import infer_and_parse_json_input, predictions_to_json
def init():
global model
global input_schema
# "model" is the path of the mlflow artifacts when the model was registered. For automl
# models, this is generally "mlflow-model".
model_path = os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model")
model = mlflow.pyfunc.load_model(model_path)
input_schema = model.metadata.get_input_schema()
def run(raw_data):
json_data = json.loads(raw_data)
if "input_data" not in json_data.keys():
raise Exception("Request must contain a top level key named 'input_data'")
serving_input = json.dumps(json_data["input_data"])
data = infer_and_parse_json_input(serving_input, input_schema)
predictions = model.predict(data)
result = StringIO()
predictions_to_json(predictions, result)
return result.getvalue()
Warning
نصيحة MLflow 2.0: يعمل مثال البرنامج النصي لتسجيل النقاط مع MLflow 1.X وMLflow 2.X. ومع ذلك، يمكن أن تختلف تنسيقات الإدخال والإخراج المتوقعة على هذه الإصدارات. تحقق من تعريف البيئة لمعرفة إصدار MLflow الذي تستخدمه. MLflow 2.0 مدعوم فقط في Python 3.8 والإصدارات الأحدث.
إنشاء بيئة
الخطوة التالية هي إنشاء بيئة يمكنك تشغيل البرنامج النصي لتسجيل النقاط فيها. نظرا لأن النموذج هو نموذج MLflow، يتم تحديد متطلبات conda أيضا في حزمة النموذج. لمزيد من المعلومات حول الملفات المضمنة في نموذج MLflow، راجع تنسيق MLmodel. يمكنك إنشاء البيئة باستخدام تبعيات conda من الملف. ومع ذلك، تحتاج أيضا إلى تضمين الحزمة azureml-inference-server-http المطلوبة للتوزيع عبر الإنترنت في التعلم الآلي من Microsoft Azure.
يمكنك إنشاء ملف تعريف conda باسم conda.yaml يحتوي على الأسطر التالية:
channels:
- conda-forge
dependencies:
- python=3.12
- pip
- pip:
- mlflow
- scikit-learn==1.7.0
- cloudpickle==3.1.1
- psutil==7.0.0
- pandas==2.3.0
- azureml-inference-server-http
name: mlflow-env
Note
dependencies يتضمن قسم ملف conda هذا الحزمةazureml-inference-server-http.
استخدم ملف تبعيات conda هذا لإنشاء البيئة:
يتم إنشاء البيئة مضمنة في تكوين النشر.
إنشاء النشر
في المجلد endpoints/online/ncd، أنشئ ملف تكوين نشر، deployment.yml، يحتوي على الأسطر التالية:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: sklearn-diabetes-custom
endpoint_name: my-endpoint
model: azureml:sklearn-diabetes@latest
environment:
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04
conda_file: sklearn-diabetes/environment/conda.yaml
code_configuration:
code: sklearn-diabetes/src
scoring_script: score.py
instance_type: Standard_F2s_v2
instance_count: 1
إنشاء النشر:
az ml online-deployment create -f endpoints/online/ncd/deployment.yml


خدمة الطلبات
عند اكتمال النشر الخاص بك، يكون جاهزا لخدمة الطلبات. إحدى طرق اختبار النشر هي استخدام invoke الأسلوب مع نموذج ملف طلب مثل الملف التالي، sample-request-sklearn.json:
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
إرسال طلب إلى نقطة النهاية:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
يجب أن تكون الاستجابة مشابهة للنص التالي:
{
"predictions": [
1095.2797413413252,
1134.585328803727
]
}
Warning
نصيحة MLflow 2.0: في MLflow 1.X، لا تحتوي الاستجابة على predictions المفتاح.
تنظيف الموارد
إذا لم تعد بحاجة إلى نقطة النهاية، فاحذف الموارد المقترنة بها:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes