تقييم نتائج تجربة التعلم الآلي المؤتمت
في هذه المقالة، تعرف على كيفية تقييم النماذج التي تم تدريبها بواسطة تجربة التعلم الآلي (ML) المؤتمت ومقارنتها. على مدار تجربة التعلم الآلي، يتم إنشاء العديد من الوظائف وكل وظيفة تخلق نموذجًا. بالنسبة لكل نموذج، يُنشئ التعلم الآلي المؤتمت مقاييس ومخططات للتقييم تساعدك على قياس أداء النموذج. يمكنك أيضا إنشاء لوحة معلومات الذكاء الاصطناعي مسؤولة لإجراء تقييم شامل وتصحيح أخطاء أفضل نموذج موصى به بشكل افتراضي. يتضمن ذلك رؤى مثل تفسيرات النموذج والإنصاف ومستكشف الأداء ومستكشف البيانات وتحليل أخطاء النموذج. تعرف على المزيد حول كيفية إنشاء لوحة معلومات الذكاء الاصطناعي مسؤولة.
على سبيل المثال، يُنشئ التعلم الآلي المؤتمت المخططات التالية بناءً على نوع التجربة.
هام
العناصر التي تم وضع علامة عليها (إصدار أولي) في هذه المقالة موجودة حالياً في الإصدار الأولي العام. تتوفر نسخة الإصدار الأولي دون اتفاقية مستوى الخدمة، ولا يوصى به لأحمال عمل الإنتاج. بعض الميزات ربما لا تكون مدعمة أو بها بعض القدرات المقيدة. لمزيد من المعلومات، راجع شروط الاستخدام التكميلية لمعاينات Microsoft Azure.
المتطلبات الأساسية
- اشتراك Azure. (إذا لم يكن لديك اشتراك في Azure، يُمكنك إنشاء حساب مجاني قبل البدء)
- تجربة Azure التعلم الآلي التي تم إنشاؤها باستخدام إما:
- استوديو التعلم الآلي من Azure (لا يلزم وجود رمز)
- التعلم الآلي من Azure Python SDK
عرض نتائج الوظائف
بعد اكتمال تجربة التعلم الآلي، يمكن العثور على سجل عمليات التشغيل عبر:
- متصفح مع استوديو التعلم الآلي من Azure
- دفتر Jupyter باستخدام عنصر واجهة المستخدم RunDetails Jupyter
توضح الخطوات ومقاطع الفيديو التالية كيفية عرض سجل التشغيل ونموذج مقاييس التقييم والرسوم البيانية في الاستوديو:
- سجّل الدخول إلى الاستوديو وانتقل إلى مساحة العمل الخاصة بك.
- في القائمة اليسرى، حدد Jobs.
- حدد تجربتك من قائمة التجارب.
- في الجدول الموجود أسفل الصفحة، حدد تشغيل التعلم الآلي المؤتمت.
- في علامة تبويب النماذج، حدد اسم الخوارزمية للنموذج الذي تريد تقييمه.
- في علامة تبويب المقاييس، استخدم مربعات الاختيار الموجودة على اليسار لعرض المقاييس والمخططات.
مقاييس التصنيف
يحسب التعلم الآلي المؤتمت مقاييس الأداء لكل نموذج تصنيف تم إنشاؤه لتجربتك. تستند هذه المقاييس إلى تنفيذ scikit Learn.
يتم تحديد العديد من مقاييس التصنيف للتصنيف الثنائي على فئتين، وتتطلب متوسط أكثر من الفئات لإنتاج درجة واحدة للتصنيف متعدد الفئات. يوفر Scikit-Learn العديد من طرق المتوسط، ثلاثة منها يعرض التعلم الآلي: الكلي والجزئي والمرجح.
- الكلي - احسب القياس لكل فئة واحسب المتوسط غير المرجح
- الجزئي - احسب المقياس عالميًا عن طريق حساب إجمالي الإيجابيات الحقيقية والسلبيات الكاذبة والإيجابيات الكاذبة (بغض النظر عن الفئات).
- المرجح - احسب القياس لكل فئة وأخذ المتوسط المرجح بناءً على عدد العينات لكل فئة.
في حين أن كل طريقة حساب متوسط لها فوائدها، فإن أحد الاعتبارات الشائعة عند اختيار الطريقة المناسبة هو عدم توازن الفئة. إذا كانت الفصول تحتوي على أعداد مختلفة من العينات، فقد يكون من المفيد استخدام متوسط ماكرو حيث يتم إعطاء فئات الأقليات ترجيحًا متساويًا لفئات الأغلبية. تعرف على المزيد عن المقاييس الثنائية مقابل المقاييس متعددة الفئات في التعلم الآلي المؤتمت.
يلخص الجدول التالي مقاييس أداء النموذج التي يحسبها التعلم الآلي المؤتمت لكل نموذج تصنيف تم إنشاؤه لتجربتك. لمزيد من التفاصيل، راجع وثائق scikit-Learn المرتبطة في حقل الحساب لكل مقياس.
إشعار
راجع قسم مقاييس الصور للحصول على تفاصيل إضافية حول مقاييس نماذج تصنيف الصور.
| مقياس | الوصف | الحساب |
|---|---|---|
| AUC | AUC هي المنطقة الواقعة تحت منحنى خصائص تشغيل جهاز الاستقبال. الهدف: أقرب إلى 1 كلما كان ذلك أفضل النطاق: [0، 1] تتضمن أسماء المقاييس المدعومة، AUC_macro، المتوسط الحسابي للجامعة الأمريكية بالقاهرة لكل فئة.AUC_micro، محسوبة بإحصاء إجمالي الإيجابيات الحقيقية والسلبيات الكاذبة والإيجابيات الكاذبة. AUC_weighted، المتوسط الحسابي للنتيجة لكل فئة، مرجحًا بعدد المثيلات الحقيقية في كل فئة. AUC_binary، قيمة AUC من خلال معاملة فئة معينة على أنها فئة true ودمج جميع الفئات الأخرى كفئة false. |
حساب |
| الدقة | الدقة هي نسبة التنبؤات التي تتطابق تمامًا مع تسميات الفئات الحقيقية. الهدف: أقرب إلى 1 كلما كان ذلك أفضل النطاق: [0، 1] |
حساب |
| average_precision | يلخص متوسط الدقة منحنى الاسترجاع الدقيق باعتباره المتوسط المرجح للدقة التي تم تحقيقها عند كل عتبة، مع زيادة الاسترجاع عن العتبة السابقة المستخدمة كوزن. الهدف: أقرب إلى 1 كلما كان ذلك أفضل النطاق: [0، 1] تشمل أسماء المقاييس المدعومة، average_precision_score_macro، المتوسط الحسابي لمتوسط درجات الدقة لكل فئة.average_precision_score_micro، محسوبة بإحصاء إجمالي الإيجابيات الحقيقية والسلبيات الكاذبة والإيجابيات الكاذبة.average_precision_score_weighted، المتوسط الحسابي لمتوسط درجات الدقة لكل فئة، مرجحًا بعدد المثيلات الحقيقية في كل فئة. average_precision_score_binary، قيمة متوسط الدقة من خلال معالجة فئة معينة كفئة true ودمج جميع الفئات الأخرى كفئة false. |
حساب |
| balanced_accuracy | الدقة المتوازنة هي الوسيلة الحسابية للتذكر لكل فئة. الهدف: أقرب إلى 1 كلما كان ذلك أفضل النطاق: [0، 1] |
حساب |
| f1_score | درجة F1 هي الوسيلة التوافقية للدقة والاسترجاع. إنه مقياس متوازن جيد لكل من الإيجابيات الكاذبة والسلبيات الكاذبة. ومع ذلك، فإنه لا يأخذ بعين الاعتبار السلبيات الحقيقية. الهدف: أقرب إلى 1 كلما كان ذلك أفضل النطاق: [0، 1] تشمل أسماء المقاييس المدعومة، f1_score_macro: المتوسط الحسابي لدرجة F1 لكل فئة. f1_score_micro: تُحسب بإحصاء إجمالي الإيجابيات الحقيقية والسلبيات الكاذبة والإيجابيات الكاذبة. f1_score_weighted: المتوسط الموزون حسب فئة تكرار الدرجة F1 لكل فئة. f1_score_binary, قيمة f1 من خلال معاملة فئة معينة كفئة true ودمج جميع الفئات الأخرى كفئة false. |
حساب |
| log_loss | هذه هي وظيفة الخسارة المستخدمة في الانحدار اللوجستي (متعدد الحدود) وامتداداته مثل الشبكات العصبية، والتي تُعرَّف على أنها احتمالية السجل السلبي للتسميات الحقيقية بالنظر إلى تنبؤات المصنف الاحتمالي. الهدف: أقرب إلى 0 كلما كان ذلك أفضل النطاق: [0، inf) |
حساب |
| norm_macro_recall | استدعاء الماكرو الطبيعي هو استدعاء متوسط الماكرو وتوحيده، بحيث يكون للأداء العشوائي درجة 0، والأداء المثالي له درجة 1. الهدف: أقرب إلى 1 كلما كان ذلك أفضل النطاق: [0، 1] |
(recall_score_macro - R) / (1 - R) حيث، R هي القيمة المتوقعة لـ recall_score_macro للتنبؤات العشوائية.R = 0.5 للتصنيف الثنائي. R = (1 / C) لمشاكل التصنيف فئة C. |
| matthews_correlation | معامل ارتباط ماثيوز هو مقياس متوازن للدقة، يمكن استخدامه حتى لو كان أحد الصفوف يحتوي على العديد من العينات أكثر من الآخر. يشير المعامل 1 إلى تنبؤ مثالي، و0 توقع عشوائي، و-1 تنبؤ عكسي. الهدف: أقرب إلى 1 كلما كان ذلك أفضل النطاق: [-1، 1] |
حساب |
| الدقة | الدقة هي قدرة النموذج على تجنب تصنيف العينات السلبية على أنها إيجابية. الهدف: أقرب إلى 1 كلما كان ذلك أفضل النطاق: [0، 1] تتضمن أسماء المقاييس المدعومة، precision_score_macro، المتوسط الحسابي للدقة لكل فئة. precision_score_micro، محسوبة عالميًا من خلال حساب إجمالي الإيجابيات الحقيقية والإيجابية الخاطئة. precision_score_weighted، المتوسط الحسابي للدقة لكل فئة، مرجحًا بعدد الأمثلة الحقيقية في كل فئة. precision_score_binary، قيمة الدقة من خلال معالجة فئة معينة كفئة true ودمج جميع الفئات الأخرى كفئة false. |
حساب |
| استدعاء | الاسترجاع هو قدرة النموذج على اكتشاف جميع العينات الإيجابية. الهدف: أقرب إلى 1 كلما كان ذلك أفضل النطاق: [0، 1] تتضمن أسماء المقاييس المدعومة، recall_score_macro: المتوسط الحسابي للتذكر لكل فئة. recall_score_micro: تُحسب عالميًا عن طريق حساب إجمالي الإيجابيات الحقيقية والسلبيات الكاذبة والإيجابيات الكاذبة.recall_score_weighted: المتوسط الحسابي للتذكر لكل فئة، مرجحًا بعدد الأمثلة الحقيقية في كل فئة. recall_score_binary، وقيمة الاستدعاء من خلال معاملة فئة معينة على أنها فئة true ودمج جميع الفئات الأخرى كفئة false. |
حساب |
| weighted_accuracy | الدقة الموزونة هي الدقة حيث يتم وزن كل عينة من خلال العدد الإجمالي للعينات التي تنتمي إلى نفس الفئة. الهدف: أقرب إلى 1 كلما كان ذلك أفضل النطاق: [0، 1] |
حساب |
مقاييس التصنيف الثنائي مقابل متعدد الطبقات
يكتشف التعلم الآلي المؤتمت تلقائيًا ما إذا كانت البيانات ثنائية ويسمح أيضًا للمستخدمين بتنشيط مقاييس التصنيف الثنائي حتى إذا كانت البيانات متعددة الفئات عن طريق تحديد فئة true. يتم الإبلاغ عن مقاييس التصنيف متعددة الفئات إذا كانت مجموعة البيانات تحتوي على فئتين أو أكثر. يتم الإبلاغ عن مقاييس التصنيف الثنائي فقط عندما تكون البيانات ثنائية.
ملاحظة، مقاييس التصنيف متعددة الفئات مخصصة للتصنيف متعدد الفئات. عند تطبيقها على مجموعة بيانات ثنائية، لا تتعامل هذه المقاييس مع أي فئة كفئة true ، كما قد تتوقع. تكون المقاييس المخصصة بوضوح للفئات المتعددة ملحقة بـ micro أو macro أو weighted. تشمل الأمثلة average_precision_score وf1_score وprecision_score وrecall_score وAUC. على سبيل المثال، بدلاً من حساب الاسترجاع كـ tp / (tp + fn)، متوسط استدعاء متوسط متعدد الفئات (micro أو macro أو weighted) عبر كلا الفئتين من مجموعة بيانات التصنيف الثنائي. هذا يعادل حساب استدعاء الفئة true والفئة false بشكل منفصل، ثم أخذ متوسط الاثنين.
بالإضافة إلى ذلك، على الرغم من دعم الاكتشاف التلقائي للتصنيف الثنائي، لا يزال يوصى دائمًا بتحديد الفئة true يدويًا للتأكد من حساب مقاييس التصنيف الثنائي للفئة الصحيحة.
لتنشيط المقاييس الخاصة بمجموعات بيانات التصنيف الثنائي عندما تكون مجموعة البيانات نفسها متعددة الطبقات، يحتاج المستخدمون فقط إلى تحديد الفئة التي سيتم التعامل معها على أنها فئة true وسيتم حساب هذه المقاييس.
مقياس الالتباس
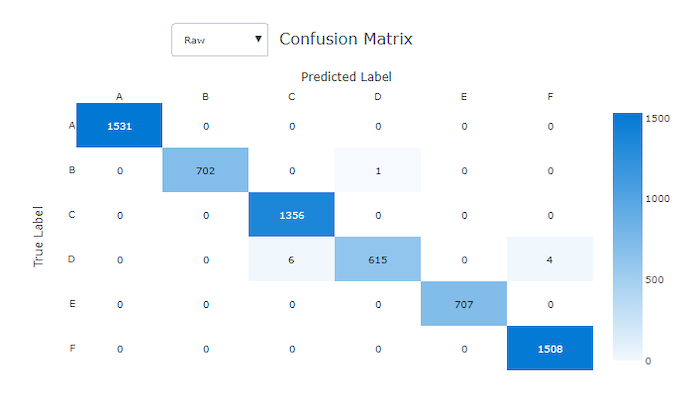
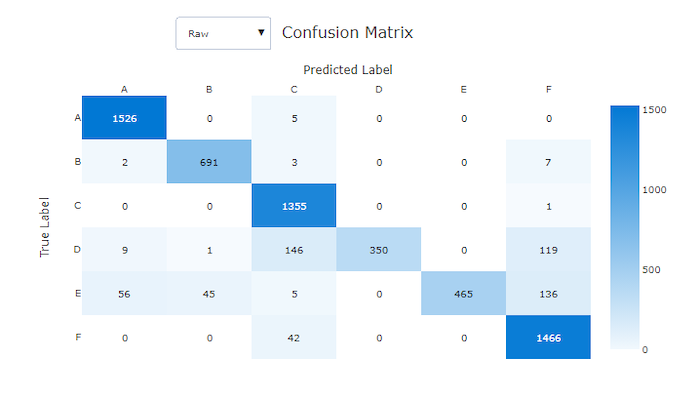
توفر مصفوفات الارتباك صورة مرئية لكيفية قيام نموذج التعلم الآلي بارتكاب أخطاء منهجية في تنبؤاته لنماذج التصنيف. تأتي كلمة "ارتباك" في الاسم من نماذج "محيرة" أو تسمية خاطئة. تحتوي الخلية الموجودة في الصف i والعمود j في مصفوفة الارتباك على عدد العينات في مجموعة بيانات التقييم التي تنتمي إلى الفئة C_i والتي تم تصنيفها بواسطة النموذج على أنها فئة C_j.
في الاستوديو، تشير الخلية المظلمة إلى عدد أكبر من العينات. سيؤدي تحديد طريقة العرض الطبيعية في القائمة المنسدلة إلى تسوية كل صف مصفوفة لإظهار النسبة المئوية للفئة C_i المتوقع أن تكون فئة C_j. تتمثل فائدة طريقة العرض Raw الافتراضية في أنه يمكنك معرفة ما إذا كان عدم التوازن في توزيع الفئات الفعلية قد تسبب في قيام النموذج بتصنيف عينات من فئة الأقلية بشكل خاطئ، وهي مشكلة شائعة في مجموعات البيانات غير المتوازنة.
تحتوي مصفوفة الارتباك للنموذج الجيد على معظم العينات على طول القطر.
مصفوفة الارتباك لنموذج جيد
مصفوفة الارتباك لنموذج سيء
منحنى ROC
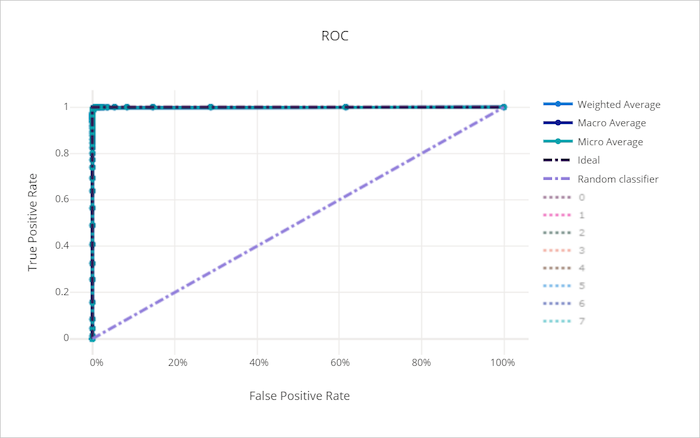
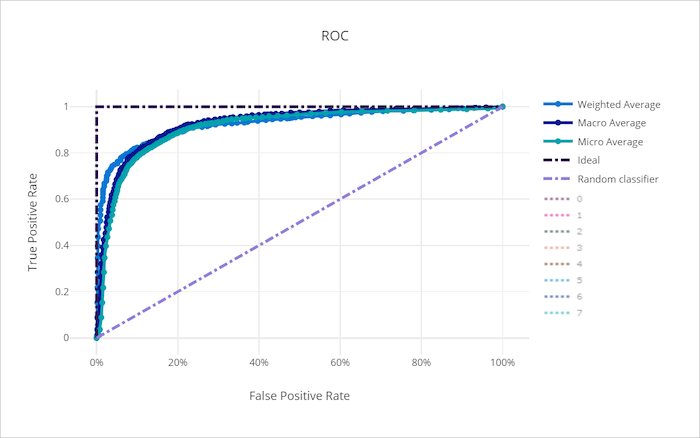
يرسم منحنى خاصية تشغيل المستقبل (ROC) العلاقة بين المعدل الإيجابي الحقيقي (TPR) والمعدل الإيجابي الخاطئ (FPR) مع تغير عتبة القرار. يمكن أن يكون منحنى ROC أقل إفادة عند تدريب النماذج على مجموعات البيانات ذات المستوى العالي من عدم التوازن، حيث يمكن لفئة الأغلبية إغراق مساهمات فئات الأقليات.
يمكن تفسير المنطقة الواقعة تحت المنحنى (AUC) على أنها نسبة العينات المصنفة بشكل صحيح. بتعبير أدق، فإن الجامعة الأمريكية بالقاهرة هي احتمال أن يصنف المصنف عينة إيجابية تم اختيارها عشوائيًا أعلى من عينة سلبية تم اختيارها عشوائيًا. يعطي شكل المنحنى حدسًا للعلاقة بين TPR وFPR كدالة لعتبة التصنيف أو حدود القرار.
المنحنى الذي يقترب من الزاوية العلوية اليسرى من الرسم البياني يقترب من 100٪ TPR و0٪ FPR، وهو أفضل نموذج ممكن. سينتج النموذج العشوائي منحنى ROC بمحاذاة الخط y = x من الركن الأيسر السفلي إلى أعلى اليمين. أسوأ من النموذج العشوائي سيكون له منحنى ROC ينخفض تحت خط y = x.
تلميح
بالنسبة لتجارب التصنيف، يمكن استخدام كل من المخططات الخطية المنتجة لنماذج التعلم الآلي المؤتمت لتقييم النموذج لكل فئة أو متوسطه على جميع الفئات. يمكنك التبديل بين طرق العرض المختلفة هذه بالنقر فوق تسميات الفصل في وسيلة الإيضاح الموجودة على يمين المخطط.
منحنى ROC لنموذج جيد
منحنى ROC لنموذج سيء
منحنى الاسترجاع الدقيق
يرسم منحنى الاسترجاع الدقيق العلاقة بين الدقة والاستدعاء مع تغير عتبة القرار. الاسترجاع هو قدرة النموذج على اكتشاف جميع العينات الإيجابية والدقة هي قدرة النموذج على تجنب تصنيف العينات السلبية على أنها إيجابية. قد تتطلب بعض مشكلات العمل قدرًا أكبر من الاسترجاع وبعض الدقة العالية اعتمادًا على الأهمية النسبية لتجنب السلبيات الخاطئة مقابل الإيجابيات الزائفة.
تلميح
بالنسبة لتجارب التصنيف، يمكن استخدام كل من المخططات الخطية المنتجة لنماذج التعلم الآلي المؤتمت لتقييم النموذج لكل فئة أو متوسطه على جميع الفئات. يمكنك التبديل بين طرق العرض المختلفة هذه بالنقر فوق تسميات الفصل في وسيلة الإيضاح الموجودة على يمين المخطط.
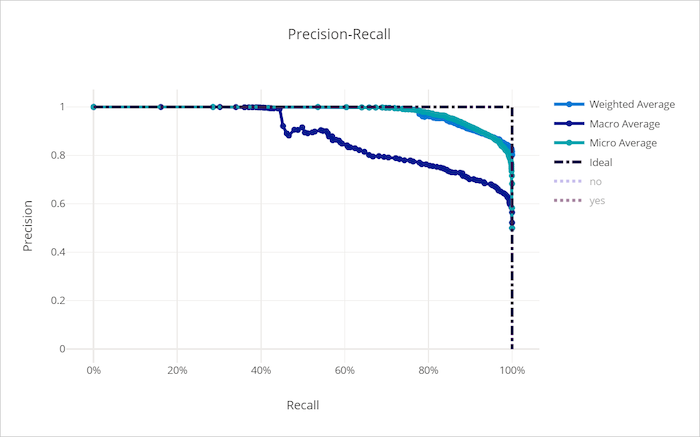
منحنى استدعاء الدقة لنموذج جيد
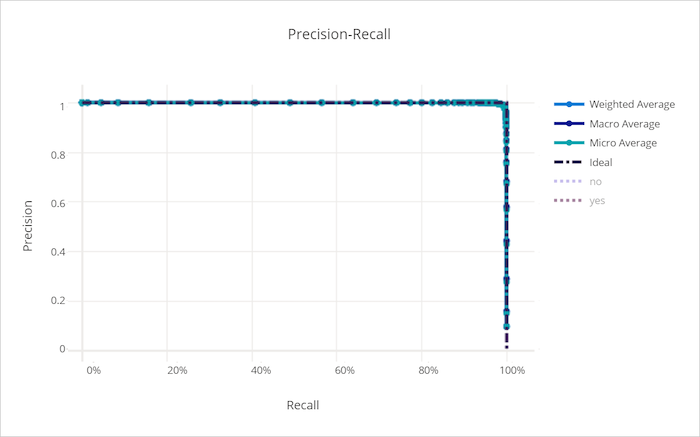
منحنى استدعاء الدقة لنموذج سيء
منحنى المكاسب التراكمية
يرسم منحنى المكاسب التراكمية النسبة المئوية للعينات الإيجابية المصنفة بشكل صحيح كدالة للنسبة المئوية للعينات التي تم النظر فيها حيث نأخذ بعين الاعتبار العينات في ترتيب الاحتمال المتوقع.
لحساب الكسب، قم أولاً بفرز جميع العينات من أعلى إلى أدنى احتمالية تنبأ بها النموذج. ثم خذ x% من أعلى توقعات الثقة. اقسم عدد العينات الموجبة المكتشفة في ذلك x% على العدد الإجمالي للعينات الإيجابية للحصول على الكسب. المكسب التراكمي هو النسبة المئوية للعينات الإيجابية التي نكتشفها عند النظر في نسبة مئوية من البيانات التي من المرجح أن تنتمي إلى الفئة الإيجابية.
سيعمل النموذج المثالي على ترتيب جميع العينات الإيجابية فوق جميع العينات السلبية، مما يعطي منحنى مكاسب تراكمية مكونًا من جزأين مستقيمين. الأول هو خط ذو ميل 1 / x من (0, 0) إلى (x, 1) حيث x هو جزء من العينات التي تنتمي إلى الفئة الموجبة (1 / num_classes إذا كانت الفئات متوازنة). والثاني خط أفقي من (x, 1) إلى (1, 1). في المقطع الأول، يتم تصنيف جميع العينات الموجبة بشكل صحيح ويذهب الكسب التراكمي إلى 100% ضمن أول x% من العينات التي تم النظر فيها.
سيكون للنموذج العشوائي الأساسي منحنى مكاسب تراكمية يتبع y = x حيث تم اكتشاف x% من العينات التي تم النظر فيها فقط حوالي x% من إجمالي العينات الإيجابية. سيكون للنموذج المثالي لمجموعة البيانات المتوازنة منحنى متوسط جزئي وخط متوسط ماكرو له ميل num_classes حتى يصبح الكسب التراكمي 100% ثم أفقيًا حتى تصبح نسبة البيانات 100.
تلميح
بالنسبة لتجارب التصنيف، يمكن استخدام كل من المخططات الخطية المنتجة لنماذج التعلم الآلي المؤتمت لتقييم النموذج لكل فئة أو متوسطه على جميع الفئات. يمكنك التبديل بين طرق العرض المختلفة هذه بالنقر فوق تسميات الفصل في وسيلة الإيضاح الموجودة على يمين المخطط.
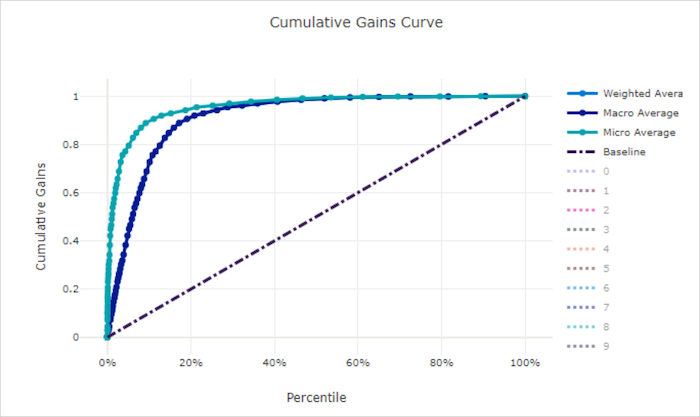
منحنى المكاسب التراكمية لنموذج جيد
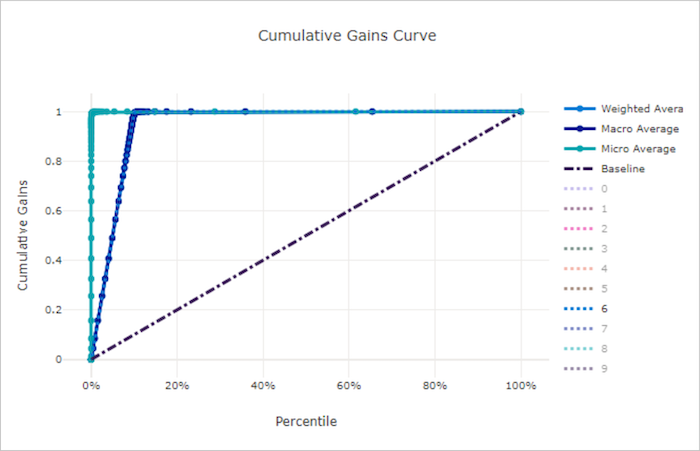
منحنى المكاسب التراكمية لنموذج سيء
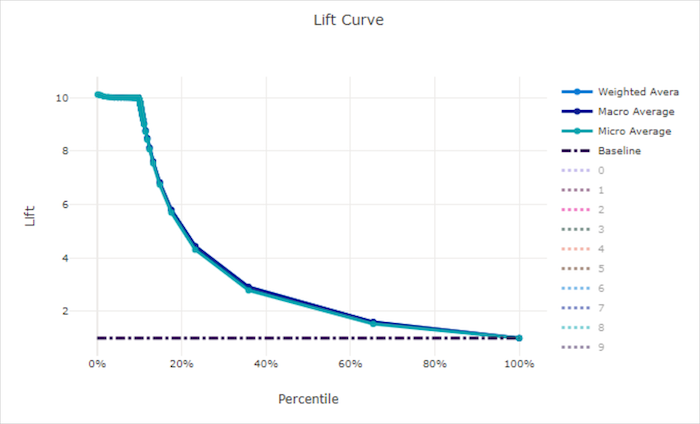
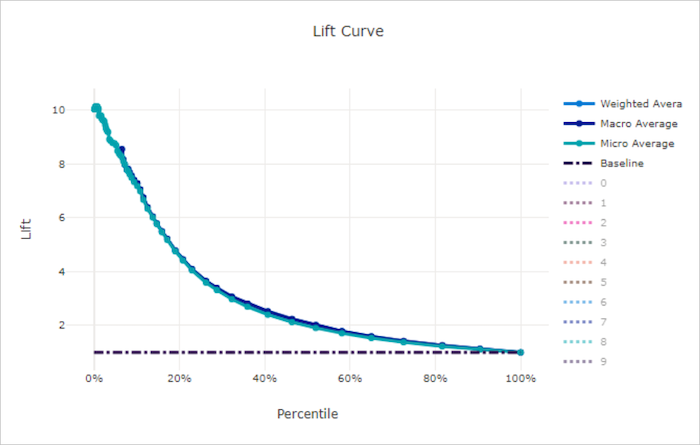
منحنى الرفع
يوضح منحنى الرفع عدد المرات التي يؤدي فيها النموذج أداءً أفضل مقارنةً بالنموذج العشوائي. يتم تعريف الرفع على أنه نسبة الكسب التراكمي إلى الكسب التراكمي لنموذج عشوائي (والذي يجب أن يكون دائمًا 1).
يأخذ هذا الأداء النسبي في الاعتبار حقيقة أن التصنيف يزداد صعوبة مع زيادة عدد الفئات. (يتنبأ نموذج عشوائي بشكل غير صحيح بجزء أكبر من العينات من مجموعة بيانات تحتوي على 10 فئات مقارنة بمجموعة بيانات ذات فئتين)
منحنى الارتفاع الأساسي هو y = 1 الخط الذي يتوافق فيه أداء النموذج مع أداء النموذج العشوائي. بشكل عام، سيكون منحنى الرفع للنموذج الجيد أعلى على هذا المخطط وأبعد من المحور السيني، مما يوضح أنه عندما يكون النموذج أكثر ثقة في تنبؤاته، فإنه يؤدي عدة مرات أفضل من التخمين العشوائي.
تلميح
بالنسبة لتجارب التصنيف، يمكن استخدام كل من المخططات الخطية المنتجة لنماذج التعلم الآلي المؤتمت لتقييم النموذج لكل فئة أو متوسطه على جميع الفئات. يمكنك التبديل بين طرق العرض المختلفة هذه بالنقر فوق تسميات الفصل في وسيلة الإيضاح الموجودة على يمين المخطط.
منحنى الرفع لنموذج جيد
منحنى الرفع لنموذج سيء
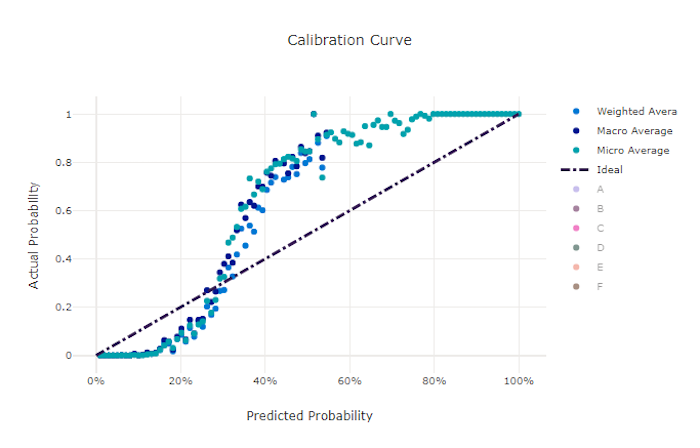
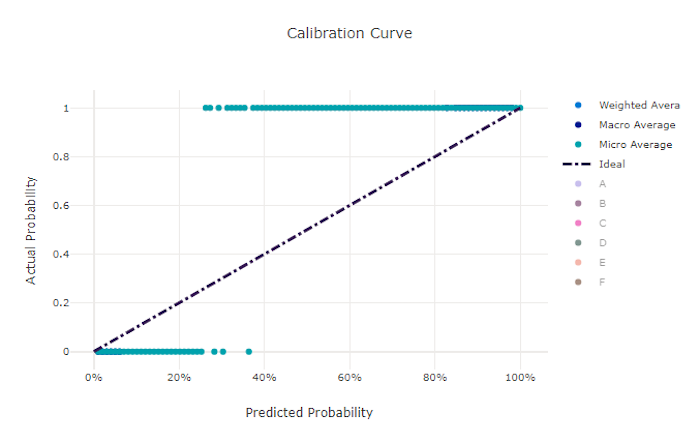
منحنى المعايرة
يرسم منحنى المعايرة ثقة النموذج في تنبؤاته مقابل نسبة العينات الإيجابية في كل مستوى ثقة. النموذج الذي تمت معايرته جيدًا سيصنف بشكل صحيح 100٪ من التنبؤات التي يعين لها ثقة بنسبة 100٪، و50٪ من التنبؤات يعين ثقة بنسبة 50٪، و20٪ من التنبؤات يعينها ثقة بنسبة 20٪، وهكذا. سيكون للنموذج الذي تمت معايرته بشكل مثالي منحنى معايرة يتبع الخط y = x حيث يتنبأ النموذج تمامًا باحتمال أن تنتمي العينات إلى كل فئة.
سوف يتنبأ النموذج المفرط الثقة بالاحتمالات القريبة من الصفر وواحد، ونادرًا ما يكون غير مؤكد بشأن فئة كل عينة وسيبدو منحنى المعايرة مشابهًا لـ "S" المتخلف. سيعيّن النموذج غير الواثق احتمالية أقل في المتوسط للفئة التي يتوقعها وسيبدو منحنى المعايرة المرتبط به مشابهًا لـ "S". لا يوضح منحنى المعايرة قدرة النموذج على التصنيف بشكل صحيح، ولكن بدلاً من ذلك قدرته على تعيين الثقة بشكل صحيح لتوقعاته. لا يزال من الممكن أن يحتوي النموذج السيئ على منحنى معايرة جيد إذا قام النموذج بتعيين ثقة منخفضة وعدم يقين مرتفع بشكل صحيح.
إشعار
يكون منحنى المعايرة حساسًا لعدد العينات، لذلك يمكن أن تنتج مجموعة صغيرة من التحقق من الصحة نتائج مشوشة يصعب تفسيرها. هذا لا يعني بالضرورة أن النموذج لم يتم معايرته بشكل جيد.
منحنى المعايرة لنموذج جيد
منحنى المعايرة لنموذج سيء
مقاييس الانحدار/التنبؤ
يحسب التعلم الآلي المؤتمت نفس مقاييس الأداء لكل نموذج تم إنشاؤه، بغض النظر عما إذا كانت تجربة انحدار أو توقع. تخضع هذه المقاييس أيضًا للتطبيع لتمكين المقارنة بين النماذج المدربة على البيانات ذات النطاقات المختلفة. لمعرفة المزيد، راجع التسوية المتري.
يلخص الجدول التالي مقاييس أداء النموذج التي تم إنشاؤها لتجارب الانحدار والتنبؤ. مثل مقاييس التصنيف، تستند هذه المقاييس أيضًا إلى تطبيقات scikit Learn. ترتبط وثائق scikit Learn المناسبة وفقًا لذلك، في حقل الحساب.
| مقياس | الوصف | الحساب |
|---|---|---|
| explained_variance | التباين الموضح يقيس المدى الذي يراعي فيه النموذج التباين في المتغير المستهدف. إنها النسبة المئوية للانخفاض في تباين البيانات الأصلية لتباين الأخطاء. عندما يكون متوسط الأخطاء 0، فإنه يساوي معامل التحديد (راجع r2_score أدناه). الهدف: أقرب إلى 1 كلما كان ذلك أفضل النطاقnf: (-inf, 1] |
حساب |
| mean_absolute_error | متوسط الخطأ المطلق هو القيمة المتوقعة للقيمة المطلقة للفرق بين الهدف والتنبؤ. الهدف: أقرب إلى 0 كلما كان ذلك أفضل النطاق: [0، inf) انواع: mean_absolute_error normalized_mean_absolute_error، المتوسط_absolute_error مقسومًا على نطاق البيانات. |
حساب |
| mean_absolute_percentage_error | متوسط النسبة المئوية للخطأ المطلق (MAPE) هو مقياس لمتوسط الفرق بين القيمة المتوقعة والقيمة الفعلية. الهدف: أقرب إلى 0 كلما كان ذلك أفضل النطاق: [0، inf) |
|
| median_absolute_error | متوسط الخطأ المطلق هو متوسط جميع الفروق المطلقة بين الهدف والتنبؤ. هذه الخسارة قوية للقيم المتطرفة. الهدف: أقرب إلى 0 كلما كان ذلك أفضل النطاق: [0، inf) انواع: median_absolute_errornormalized_median_absolute_error: median_absolute_error مقسومًا على نطاق البيانات. |
حساب |
| r2_score | R2 (معامل التحديد) يقيس التخفيض النسبي في متوسط الخطأ التربيعي (MSE) بالنسبة إلى التباين الكلي للبيانات المرصودة. الهدف: أقرب إلى 1 كلما كان ذلك أفضل النطاق: [-1، 1] ملاحظة: غالبًا ما يحتوي R2 على النطاق (-inf، 1]. يمكن أن يكون MSE أكبر من التباين الملحوظ، لذلك يمكن أن يكون لـ R2 قيم سلبية كبيرة بشكل تعسفي، اعتمادًا على البيانات وتوقعات النموذج. سجلت مقاطع التعلم الآلي المؤتمت درجات R2 عند -1، لذا فإن القيمة -1 لـ R2 تعني على الأرجح أن النتيجة الحقيقية لـ R2 أقل من -1. ضع في اعتبارك قيم المقاييس الأخرى وخصائص البيانات عند تفسير درجة R2 السلبية. |
حساب |
| root_mean_squared_error | جذر متوسط الخطأ التربيعي (RMSE) هو الجذر التربيعي للفرق التربيعي المتوقع بين الهدف والتنبؤ. بالنسبة للمقدر غير المتحيز، فإن RMSE تساوي الانحراف المعياري. الهدف: أقرب إلى 0 كلما كان ذلك أفضل النطاق: [0، inf) الأنواع: root_mean_squared_error normalized_root_mean_squared_error: الخطأ root_mean_squared_error مقسومًا على نطاق البيانات. |
حساب |
| root_mean_squared_log_error | الجذر التربيعي لخطأ السجل التربيعي هو الجذر التربيعي للخطأ اللوغاريتمي التربيعي المتوقع. الهدف: أقرب إلى 0 كلما كان ذلك أفضل النطاق: [0، inf) انواع: root_mean_squared_log_error normalized_root_mean_squared_log_error: root_mean_squared_log_error مقسومًا على نطاق البيانات. |
حساب |
| spearman_correlation | ارتباط سبيرمان هو مقياس غير معلمي لرتابة العلاقة بين مجموعتي بيانات. على عكس ارتباط بيرسون، لا تفترض علاقة سبيرمان أن مجموعتي البيانات يتم توزيعهما بشكل طبيعي. مثل معاملات الارتباط الأخرى، يختلف سبيرمان بين -1 و1 مع عدم وجود أي ارتباط. تشير الارتباطات -1 أو 1 إلى علاقة رتيبة دقيقة. سبيرمان هو مقياس ارتباط ترتيب الترتيب مما يعني أن التغييرات على القيم المتوقعة أو الفعلية لن تغير نتيجة سبيرمان إذا لم يغير ترتيب القيم المتوقعة أو الفعلية. الهدف: أقرب إلى 1 كلما كان ذلك أفضل النطاق: [-1، 1] |
حساب |
التطبيع المتري
يعمل التعلم الآلي التلقائي على تطبيع مقاييس الانحدار والتنبؤ التي تمكن المقارنة بين النماذج المدربة على البيانات ذات النطاقات المختلفة. النموذج المدرَّب على بيانات ذات نطاق أكبر به خطأ أعلى من النموذج نفسه المُدرَّب على البيانات ذات النطاق الأصغر، ما لم يتم تسوية هذا الخطأ.
على الرغم من عدم وجود طريقة قياسية لتطبيع مقاييس الخطأ، فإن التعلم الآلي المؤتمت يتبع النهج الشائع لتقسيم الخطأ على نطاق البيانات: normalized_error = error / (y_max - y_min)
إشعار
لا يتم حفظ نطاق البيانات مع النموذج. إذا قمت بالاستدلال بنفس النموذج في مجموعة اختبار الانتظار، فقد يتغير y_min وy_max وفقًا لبيانات الاختبار وقد لا يتم استخدام المقاييس الموحدة بشكل مباشر لمقارنة أداء النموذج في مجموعات التدريب والاختبار. يمكنك تمرير قيمة y_min وy_max من مجموعة التدريب الخاصة بك لجعل المقارنة عادلة.
مقاييس التنبؤ: التطبيع والتجميع
يتطلب حساب مقاييس تقييم نموذج التنبؤ بعض الاعتبارات الخاصة عندما تحتوي البيانات على سلاسل زمنية متعددة. هناك خياران طبيعيان لتجميع المقاييس عبر سلاسل متعددة:
- متوسط الماكرو حيث يتم إعطاء مقاييس التقييم من كل سلسلة وزنا متساويا،
- متوسط صغير حيث يكون لمقاييس التقييم لكل تنبؤ وزن متساو.
هذه الحالات لها قياسات مباشرة إلى الماكرو والمتوسط الصغير في التصنيف متعدد الفئات.
يمكن أن يكون التمييز بين الماكرو والمتوسط الصغير مهما عند تحديد مقياس أساسي لاختيار النموذج. على سبيل المثال، ضع في اعتبارك سيناريو البيع بالتجزئة حيث تريد التنبؤ بالطلب على مجموعة مختارة من المنتجات الاستهلاكية. تبيع بعض المنتجات بأحجام أعلى بكثير من غيرها. إذا اخترت RMSE متوسطا صغيرا كمقياس أساسي، فمن الممكن أن تساهم العناصر ذات الحجم الكبير بغالبية خطأ النمذجة، وبالتالي، السيطرة على المقياس. قد تفضل خوارزمية تحديد النموذج النماذج بدقة أعلى على العناصر ذات الحجم الكبير مقارنة بالعناصر ذات الحجم المنخفض. في المقابل، يعطي RMSE متوسط الماكرو والمتسوية العناصر منخفضة الحجم وزنا متساويا تقريبا للعناصر ذات الحجم الكبير.
يوضح الجدول التالي أي من مقاييس التنبؤ التلقائي تستخدم الماكرو مقابل المتوسط الصغير:
| متوسط الماكرو | متوسط صغير |
|---|---|
normalized_mean_absolute_error, normalized_median_absolute_error, normalized_root_mean_squared_error, normalized_root_mean_squared_log_error |
mean_absolute_error, median_absolute_error, root_mean_squared_error, root_mean_squared_log_error, r2_score, explained_variance, spearman_correlation, mean_absolute_percentage_error |
لاحظ أن المقاييس متوسطة الماكرو تعمل على تطبيع كل سلسلة بشكل منفصل. ثم يتم حساب متوسط المقاييس التي تمت تسويتها من كل سلسلة لإعطاء النتيجة النهائية. يعتمد الاختيار الصحيح للماكرو مقابل micro على سيناريو العمل، ولكننا نوصي عموما باستخدام normalized_root_mean_squared_error.
المخلفات
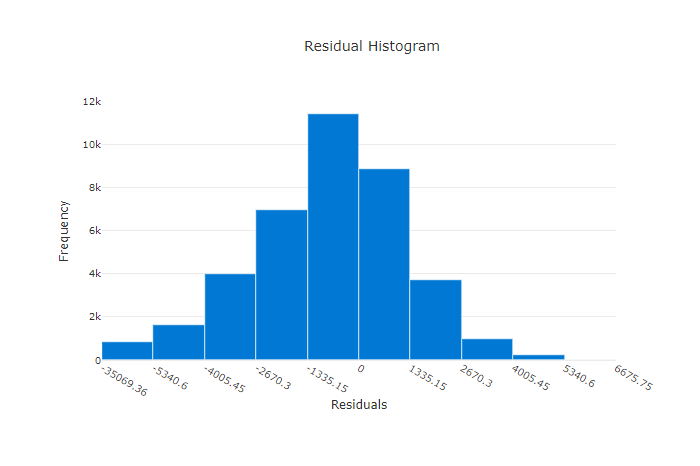
مخطط القيم المتبقية هو رسم بياني لأخطاء التنبؤ (القيم المتبقية) الناتجة عن تجارب الانحدار والتنبؤ. يتم حساب القيم المتبقية على أنها y_predicted - y_true لجميع العينات ثم يتم عرضها كمدرج تكراري لإظهار انحياز النموذج.
في هذا المثال، لاحظ أن كلا النموذجين متحيزان قليلاً للتنبؤ بأقل من القيمة الفعلية. هذا ليس نادرًا بالنسبة لمجموعة البيانات ذات التوزيع المنحرف للأهداف الفعلية، ولكنه يشير إلى أداء نموذج أسوأ. سيكون للنموذج الجيد توزيع متبقيات يبلغ ذروته عند الصفر مع وجود القليل من المخلفات في أقصى الحدود. سيكون للنموذج الأسوأ توزيع بقايا موزعة مع عدد أقل من العينات حول الصفر.
الرسم البياني المتبقي لنموذج جيد
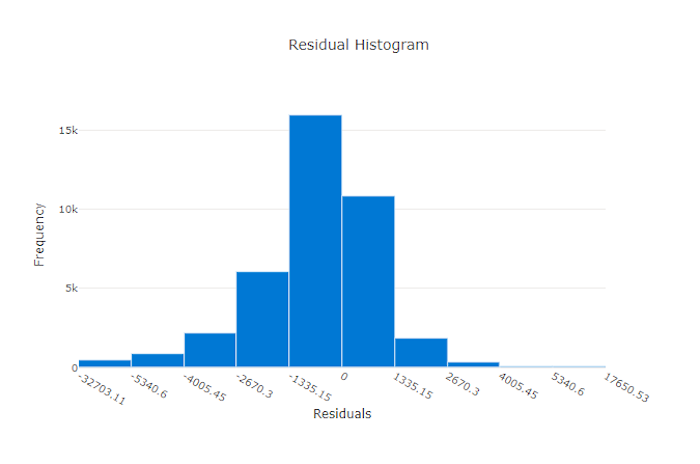
مخطط المتبقي لنموذج سيء
توقع مقابل صحيح
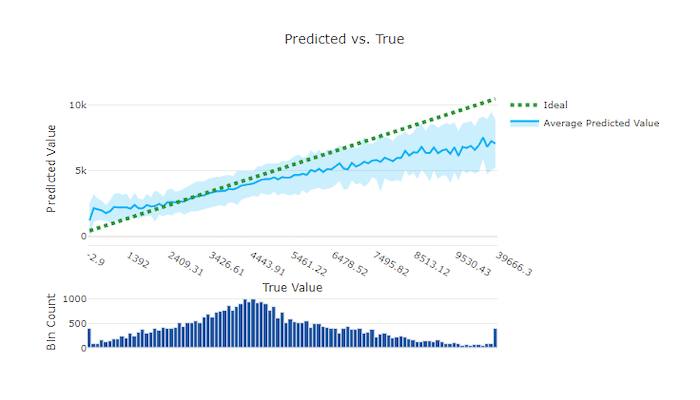
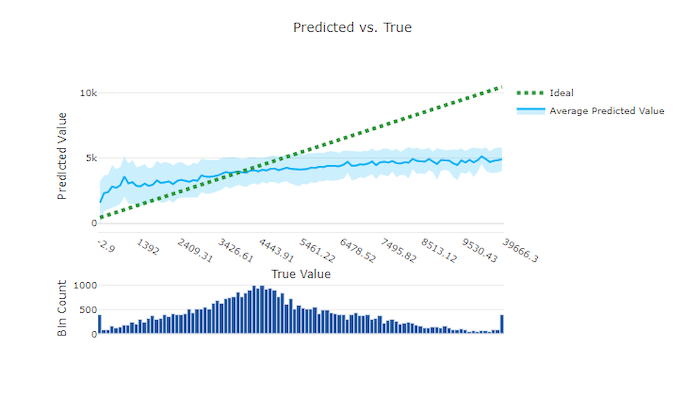
لتجربة الانحدار والتنبؤ، يرسم الرسم البياني المتوقع مقابل الحقيقي العلاقة بين الميزة المستهدفة (القيم الحقيقية/الفعلية) وتوقعات النموذج. يتم تجميع القيم الحقيقية على طول المحور السيني ولكل حاوية متوسط القيمة المتوقعة يتم رسمها بأشرطة الخطأ. يتيح لك ذلك معرفة ما إذا كان النموذج منحازًا للتنبؤ بقيم معينة. يعرض الخط متوسط التنبؤ وتشير المنطقة المظللة إلى تباين التنبؤات حول هذا المتوسط.
غالبًا ما يكون للقيمة الحقيقية الأكثر شيوعًا أكثر التنبؤات دقة مع أدنى تباين. تعد المسافة بين خط الاتجاه والخط المثالي y = x حيث توجد قيم حقيقية قليلة مقياسًا جيدًا لأداء النموذج على القيم المتطرفة. يمكنك استخدام المدرج التكراري في الجزء السفلي من المخطط لتبرير توزيع البيانات الفعلي. يمكن أن يؤدي تضمين المزيد من عينات البيانات حيث يكون التوزيع متناثرًا إلى تحسين أداء النموذج على البيانات غير المرئية.
في هذا المثال، لاحظ أن النموذج الأفضل يحتوي على خط متوقع مقابل خط حقيقي أقرب إلى الخط المثالي y = x.
الرسم البياني المتوقع مقابل المخطط الحقيقي لنموذج جيد
الرسم البياني المتوقع مقابل الحقيقي لنموذج سيء
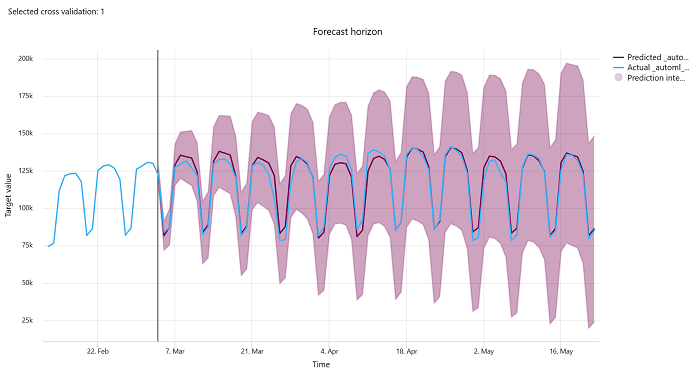
أفق التنبؤ
بالنسبة لتجارب التنبؤ، يرسم مخطط أفق التنبؤ العلاقة بين القيمة المتوقعة للنماذج والقيم الفعلية التي تم تعيينها بمرور الوقت لكل أضعاف التحقق من الصحة، حتى 5 أضعاف. يحدد المحور السيني الوقت بناءً على التردد الذي قدمته أثناء إعداد التدريب. يشير الخط العمودي في المخطط إلى نقطة أفق التنبؤ التي يشار إليها أيضًا باسم خط الأفق، وهي الفترة الزمنية التي قد ترغب في بدء إنشاء التنبؤات فيها. على يسار خط أفق التنبؤ، يمكنك عرض بيانات التدريب التاريخية لتصور الاتجاهات السابقة بشكل أفضل. إلى يمين أفق التنبؤ، يمكنك تصور التنبؤات (الخط الأرجواني) مقابل القيم الفعلية (الخط الأزرق) لمختلف طيات التحقق من الصحة ومعرفات السلاسل الزمنية. تشير المنطقة الأرجوانية المظللة إلى فترات الثقة أو تباين التنبؤات حول هذا المتوسط.
يمكنك اختيار طية التحقق المتقاطعة ومجموعات معرف السلاسل الزمنية لعرضها بالنقر فوق رمز القلم الرصاص في الزاوية العلوية اليمنى من المخطط. اختر من بين أول 5 طيات للتحقق من الصحة وما يصل إلى 20 معرّفًا مختلفًا للسلاسل الزمنية لتصور الرسم البياني للسلسلة الزمنية المختلفة الخاصة بك.
هام
يتوفر هذا المخطط في تشغيل التدريب للنماذج التي تم إنشاؤها من بيانات التدريب والتحقق من الصحة وكذلك في تشغيل الاختبار استنادا إلى بيانات التدريب وبيانات الاختبار. نسمح بما يصل إلى 20 نقطة بيانات قبل وما يصل إلى 80 نقطة بيانات بعد أصل التنبؤ. بالنسبة لنماذج DNN، يعرض هذا المخطط في تشغيل التدريب بيانات من الفترة الأخيرة، أي بعد تدريب النموذج بالكامل. يمكن أن يكون لهذا المخطط في تشغيل الاختبار فجوة قبل خط الأفق إذا تم توفير بيانات التحقق من الصحة بشكل صريح أثناء تشغيل التدريب. وذلك لأن بيانات التدريب وبيانات الاختبار تستخدم في تشغيل الاختبار تاركة بيانات التحقق مما يؤدي إلى فجوة.
مقاييس نماذج الصور (معاينة)
يستخدم التعلم الآلي المؤتمت الصور من مجموعة بيانات التحقق لتقييم أداء النموذج. يتم قياس أداء النموذج على مستوى الحقبة لفهم كيفية تقدم التدريب. تنقضي حقبة عندما يتم تمرير مجموعة بيانات كاملة للأمام وللخلف عبر الشبكة العصبية مرة واحدة بالضبط.
مقاييس تصنيف الصور
المقياس الأساسي للتقييم هو دقة نماذج التصنيف الثنائية ومتعددة الفئات وIoU (التقاطع عبر الاتحاد) لنماذج التصنيف متعددة العلامات. مقاييس التصنيف لنماذج تصنيف الصور هي نفسها تلك المحددة في قسم مقاييس التصنيف. يتم أيضًا تسجيل قيم الخسارة المرتبطة بالعصر والتي يمكن أن تساعد في مراقبة كيفية تقدم التدريب وتحديد ما إذا كان النموذج مناسبًا أو غير مناسب.
يرتبط كل توقع من نموذج التصنيف بدرجة ثقة، والتي تشير إلى مستوى الثقة الذي تم به إجراء التنبؤ. يتم تقييم نماذج تصنيف الصور متعددة الملصقات افتراضيًا باستخدام عتبة درجة 0.5 مما يعني أن التنبؤات التي تتمتع على الأقل بهذا المستوى من الثقة سيتم اعتبارها تنبؤًا إيجابيًا للفئة المرتبطة. لا يستخدم التصنيف متعدد الفئات حدًا للنتيجة ولكن بدلاً من ذلك، تعتبر الفئة ذات الحد الأقصى لدرجة الثقة بمثابة توقع.
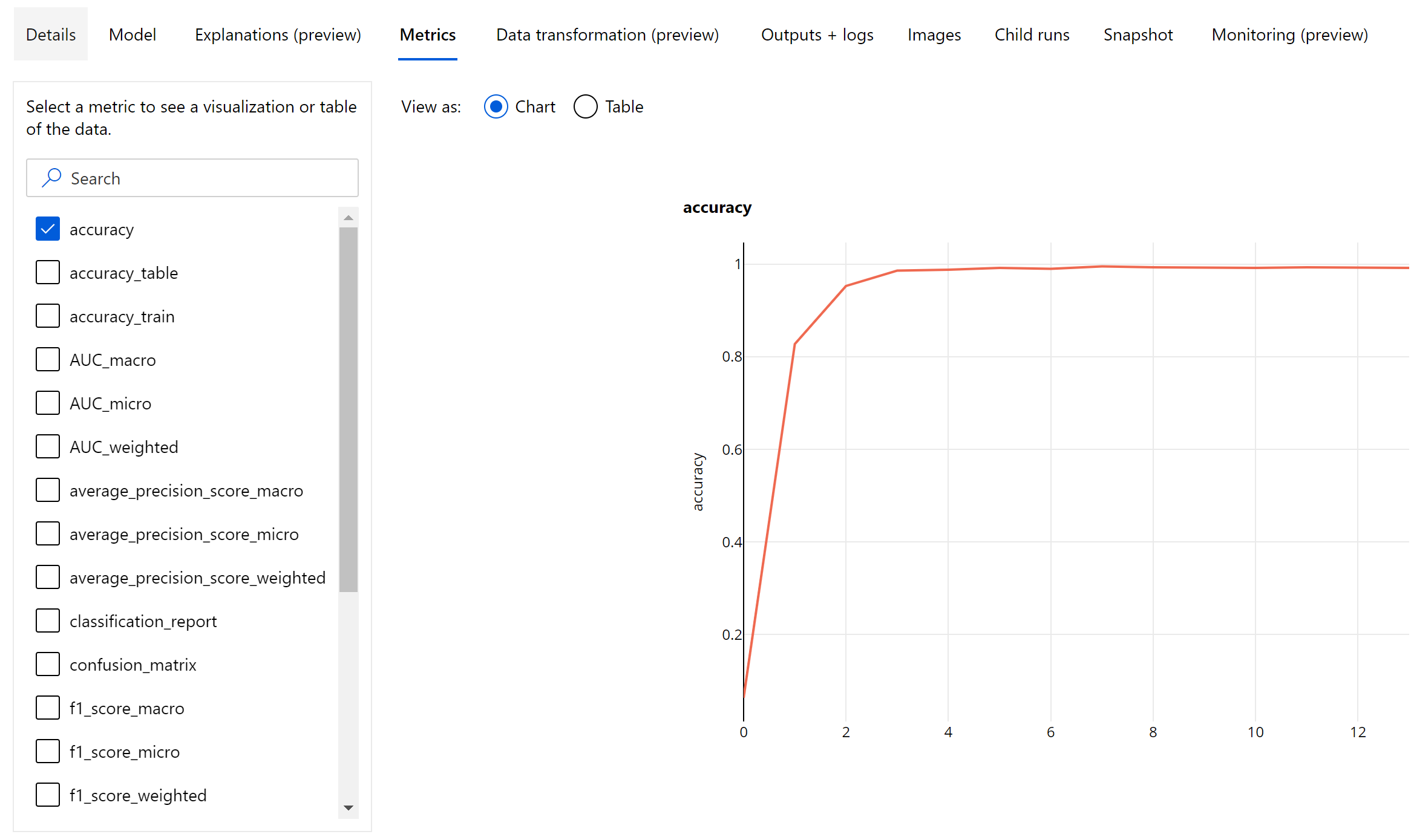
المقاييس على مستوى الحقبة لتصنيف الصور
بخلاف مقاييس التصنيف لمجموعات البيانات المجدولة، تسجل نماذج تصنيف الصور جميع مقاييس التصنيف على مستوى الحقبة كما هو موضح أدناه.
مقاييس الملخص لتصنيف الصور
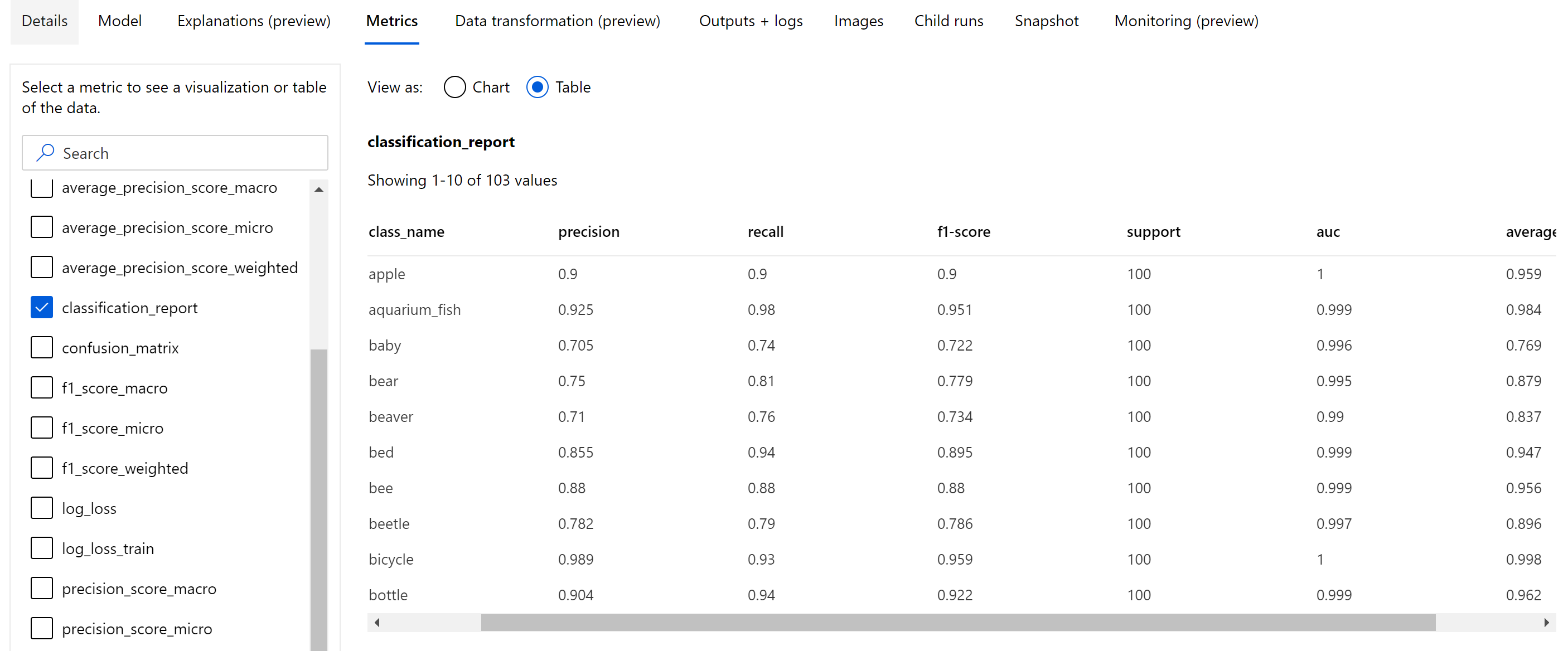
بصرف النظر عن المقاييس العددية التي يتم تسجيلها على مستوى الحقبة، يسجل نموذج تصنيف الصور أيضًا مقاييس الملخص مثل مصفوفة الارتباك ومخططات التصنيف بما في ذلك منحنى ROC ومنحنى الاسترجاع الدقيق وتقرير التصنيف للنموذج من أفضل حقبة نحصل فيها على أعلى درجة (دقة) أولية.
يوفر تقرير التصنيف قيمًا على مستوى الفصل للمقاييس مثل الدقة، والاستدعاء، ودرجة f1، والدعم، وauc، ومتوسط الدقة مع مستوى مختلف من المتوسط - الجزئي والكلي والمرجح كما هو موضح أدناه. يرجى الرجوع إلى تعريفات المقاييس من قسم مقاييس التصنيف.
مقاييس الكشف عن الكائنات وتجزئة المثيل
يرتبط كل توقع من اكتشاف كائن الصورة أو نموذج تجزئة المثيل بدرجة ثقة.
يتم إخراج التنبؤات التي تحتوي على درجة ثقة أكبر من عتبة الدرجة كتنبؤات ويتم استخدامها في الحساب المتري، والقيمة الافتراضية لها خاصة بالنموذج ويمكن الرجوع إليها من صفحة ضبط المعلمة الفائقة (box_score_thresholdالمعلمة الفائقة).
يعتمد الحساب المتري لاكتشاف كائن الصورة ونموذج تجزئة المثيل على قياس التداخل المحدد بواسطة مقياس يسمى IoU (التقاطع عبر الاتحاد) والذي يتم حسابه عن طريق قسمة منطقة التداخل بين الحقيقة الأساسية والتنبؤات على مساحة اتحاد الحقيقة الأرضية والتنبؤات. تتم مقارنة IoU المحسوبة من كل تنبؤ بعتبة تداخل تسمى عتبة IoU والتي تحدد مدى تداخل التنبؤ مع الحقيقة الأرضية المشروحة من قبل المستخدم من أجل اعتباره تنبؤًا إيجابيًا. إذا كانت IoU المحسوبة من التوقع أقل من عتبة التداخل، فلن يتم اعتبار التوقع بمثابة تنبؤ إيجابي للفئة المرتبطة.
المقياس الأساسي لتقييم اكتشاف كائن الصورة ونماذج تجزئة المثيل هو متوسط الدقة (mAP). MAP هي القيمة المتوسطة لمتوسط الدقة (AP) عبر جميع الفئات. تدعم نماذج التعلم الآلي المؤتمت لاكتشاف الكائنات حساب الخريطة باستخدام الطريقتين الشائعتين أدناه.
مقاييس Pascal VOC:
Pascal VOC mAP هي الطريقة الافتراضية لحساب الخريطة لنماذج تجزئة الكائنات/الكشف عن الكائنات. تحسب طريقة Pascal VOC style mAP في المنطقة الواقعة أسفل إصدار من منحنى الاسترجاع الدقيق. الأول p(rᵢ)، وهي الدقة عند الاستدعاء، يتم حسابها لجميع قيم الاسترجاع الفريدة. ثم يتم استبدال p(rᵢ) بأقصى دقة تم الحصول عليها لأي استدعاء r' >= rᵢ. تتناقص قيمة الدقة بشكل رتيب في هذا الإصدار من المنحنى. يتم تقييم مقياس Pascal VOC mAP افتراضيًا بحد أدنى 0.5 IoU. يتوفر شرح مفصل لهذا المفهوم في هذه المدونة.
مقاييس COCO:
تستخدم طريقة تقييم COCO طريقة محرفة من 101 نقطة لحساب AP جنبًا إلى جنب مع متوسط أكثر من عشرة عتبات IoU. AP@[.5:.95] يتوافق مع متوسط AP لـ IoU من 0.5 إلى 0.95 بحجم خطوة 0.05. يسجل التعلم الآلي المؤتمت جميع المقاييس الاثني عشر المحددة بواسطة طريقة COCO بما في ذلك AP وAR (متوسط الاسترجاع) بمقاييس مختلفة في سجلات التطبيق بينما تعرض واجهة مستخدم المقاييس فقط الخريطة عند عتبة IoU 0.5.
تلميح
يمكن أن يستخدم تقييم نموذج اكتشاف كائن الصورة مقاييس coco إذا تم تعيين المعلمة التشعبية validation_metric_type لتكون "coco" كما هو موضح في قسم ضبط المعلمة التشعبية.
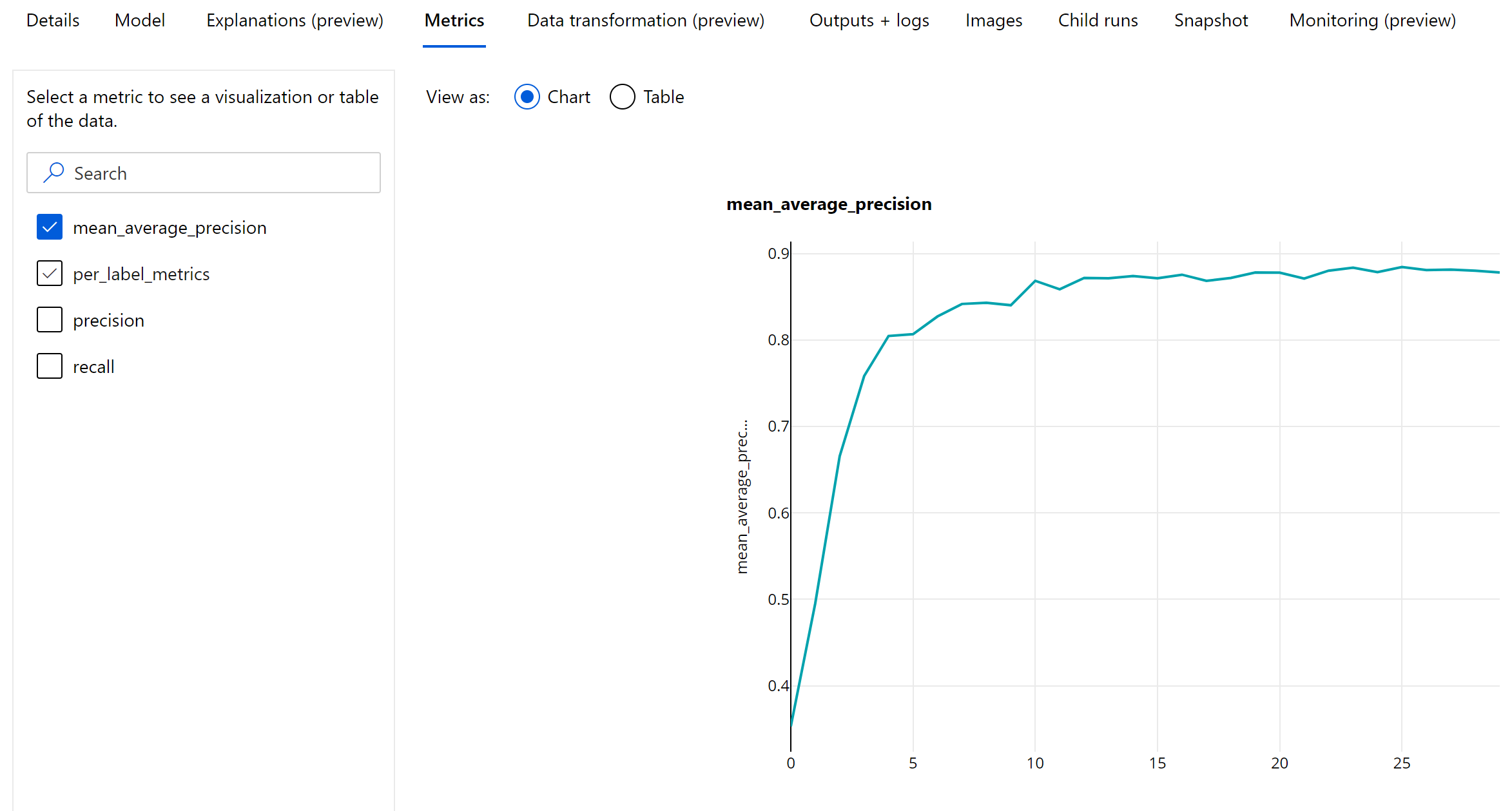
مقاييس مستوى الحقبة لاكتشاف الكائن وتجزئة المثيل
يتم تسجيل قيم MAP والدقة والاستدعاء على مستوى الحقبة لنماذج تجزئة كائن الصورة/المثيل. يتم أيضًا تسجيل مقاييس الخريطة والدقة والاستدعاء على مستوى الفصل بالاسم "per_label_metrics". ينبغي عرض "per_label_metrics" كجدول.
إشعار
لا تتوفر المقاييس على مستوى الحقبة للدقة والاستدعاء وper_label_metrics عند استخدام طريقة "coco".
لوحة معلومات الذكاء الاصطناعي المسؤولة لأفضل نموذج موصى به ل AutoML (معاينة)
توفر لوحة معلومات الذكاء الاصطناعي المسؤول في Azure التعلم الآلي واجهة واحدة لمساعدتك على تنفيذ الذكاء الاصطناعي المسؤول في الممارسة العملية بفعالية وكفاءة. يتم دعم لوحة معلومات الذكاء الاصطناعي المسؤولة فقط باستخدام البيانات الجدولية ويتم دعمها فقط على نماذج التصنيف والانحدار. وهو يجمع بين العديد من أدوات الذكاء الاصطناعي المسؤولة الناضجة في مجالات:
- تقييم أداء النموذج والإنصاف
- استكشاف البيانات
- قابلية التعلم الآلي للتفسير
- تحليل الخطأ
في حين أن مقاييس ومخططات تقييم النموذج جيدة لقياس الجودة العامة للنموذج، فإن عمليات مثل فحص عدالة النموذج، وعرض تفسيراته (المعروفة أيضا باسم مجموعة البيانات التي تتميز بنموذج يستخدم لإجراء تنبؤاته)، فإن فحص أخطاءه والنقاط العمياء المحتملة ضرورية عند ممارسة الذكاء الاصطناعي المسؤولة. لهذا السبب يوفر التعلم الآلي التلقائي لوحة معلومات الذكاء الاصطناعي مسؤولة لمساعدتك في مراقبة مجموعة متنوعة من الرؤى لنموذجك. تعرف على كيفية عرض لوحة معلومات الذكاء الاصطناعي المسؤول في استوديو Azure التعلم الآلي.
تعرف على كيفية إنشاء لوحة المعلومات هذه عبر واجهة المستخدم أو SDK.
تفسيرات النموذج وأهمية الميزات
في حين أن مقاييس ومخططات تقييم النموذج جيدة لقياس الجودة العامة للنموذج، فإن فحص مجموعة البيانات التي يستخدمها النموذج لإجراء تنبؤات أمر ضروري عند ممارسة الذكاء الاصطناعي المسؤولة. هذا هو السبب في أن التعلم الآلي يوفر لوحة معلومات تفسيرات نموذجية لقياس والإبلاغ عن المساهمات النسبية لميزات مجموعة البيانات. راجع كيفية عرض لوحة معلومات التفسيرات في استوديو التعلم الآلي من Azure.
إشعار
التفسير، أفضل تفسير للنموذج، غير متاح لتجارب تنبؤ التعلم الآلي المؤتمت التي توصي بالخوارزميات التالية كأفضل نموذج أو مجموعة:
- TCNForecaster
- AutoArima
- ExponentialSmoothing
- Prophet
- Average
- Naive
- المتوسط الموسمي
- السذاجة الموسمية
الخطوات التالية
- جرب نماذج شرح نموذج التعلم الآلي للكمبيوتر الدفتري.
- في حالة وجود أسئلة بشأن التعلم الآلي المؤتمت، تواصل مع askautomatedml@microsoft.com.