جمع البيانات من النماذج في الإنتاج
ينطبق على: Python SDK azureml الإصدار 1
Python SDK azureml الإصدار 1
توضح هذه المقالة كيفية جمع البيانات من نموذج التعلم الآلي الموزع على مجموعة Azure Kubernetes Service (AKS). ثم يتم تخزين البيانات التي تم جمعها في تخزين Azure Blob.
بمجرد تمكين الجمع، تساعدك البيانات التي تجمعها على:
راقب انحرافات البيانات في بيانات الإنتاج التي تجمعها.
تحليل البيانات المجمعة باستخدام Power BI أو Azure Databricks
اتخذ قرارات أفضل بشأن وقت إعادة تدريب نموذجك أو تحسينه.
أعد تدريب نموذجك بالبيانات التي تم جمعها.
التقييدات
- يمكن أن تعمل ميزة جمع بيانات النموذج فقط مع صورة Ubuntu 18.04.
هام
اعتبارا من 03/10/2023، تم الآن إهمال صورة Ubuntu 18.04. سيتم إسقاط دعم صور Ubuntu 18.04 بدءا من يناير 2023 عندما تصل إلى EOL في 30 أبريل 2023.
ميزة MDC غير متوافقة مع أي صورة أخرى غير Ubuntu 18.04، والتي لا تتوفر بعد إهمال صورة Ubuntu 18.04.
mMore information التي يمكنك الرجوع إليها:
ملاحظة
ميزة جمع البيانات قيد المعاينة حاليا، ولا يوصى بأي ميزات معاينة لأحمال عمل الإنتاج.
ما يتم جمعه وأين يذهب
يمكن جمع البيانات التالية:
نموذج بيانات الإدخال من خدمات الويب المنتشرة في مجموعة AKS. لا يتم تجميع الصوت والصورة والفيديو.
تنبؤات النموذج باستخدام بيانات إدخال الإنتاج.
ملاحظة
التجميع والحسابات المسبقة على هذه البيانات ليست حالياً جزءاً من خدمة التجميع.
يتم حفظ الإخراج في تخزين Blob. نظراً لأنه تتم إضافة البيانات إلى تخزين Blob، يمكنك اختيار أداتك المفضلة لتشغيل التحليل.
يتبع المسار إلى بيانات الإخراج في blob بناء الجملة هذا:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
ملاحظة
في إصدارات Azure Machine Learning SDK لـ Python الأقدم من الإصدار 0.1.0a16، تم تسمية الوسيطة designationidentifier. إذا قمت بتطوير التعليمات البرمجية الخاصة بك باستخدام إصدار سابق، فستحتاج إلى تحديثها وفقاً لذلك.
المتطلبات الأساسية
إذا لم يكن لديك اشتراك Azure، فأنشئ حساباً مجانياً قبل أن تبدأ.
يجب تثبيت مساحة عمل التعلم الآلي، ودليل محلي يحتوي على البرامج النصية الخاصة بك، وAzure Machine Learning SDK لـ Python. لمعرفة كيفية تثبيتها، راجع كيفية تكوين بيئة التطوير.
أنت بحاجة إلى نموذج تعلم آلي مدرب ليتم توزيعه في AKS. إذا لم يكن لديك نموذج، فراجع البرنامج التعليمي تدريب نموذج تصنيف الصور.
أنت بحاجة إلى مجموعة AKS. للحصول على معلومات حول كيفية إنشاء نموذج وتوزيعه، راجع توزيع نماذج التعلم الآلي إلى Azure.
استخدم صورة docker استنادًا إلى Ubuntu 18.04، والتي يتم شحنها مع
libssl 1.0.0، التبعية الأساسية لـ modeldatacollector. يمكنك الرجوع إلى الصور التي تم إنشاؤها مسبقًا.
تشغيل جمع البيانات
يمكنك تمكين جمع البيانات بغض النظر عن النموذج الذي توزعه من خلال التعلم الآلي أو أدوات أخرى.
لتمكين جمع البيانات، تحتاج إلى:
افتح ملف التسجيل.
إضافة التعليمات البرمجية التالية إلى أعلى الملف:
from azureml.monitoring import ModelDataCollectorقم بتعريف متغيرات جمع البيانات في دالة
initالخاصة بك:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId هي معلمة اختيارية. لا تحتاج إلى استخدامه إذا كان نموذجك لا يتطلب ذلك. يساعدك استخدام CorrelationId في تعيين البيانات الأخرى بسهولة أكبر، مثل LoanNumber أو CustomerId.
يتم استخدام معلمة المعرف لاحقاً لبناء بنية المجلد في blob الخاص بك. يمكنك استخدامه للتمييز بين البيانات الأوَّلية والبيانات المعالجة.
أضف سطور التعليمات البرمجية التالية إلى الوظيفة
run(input_df):data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure Blobلا يتم تعيين جمع البيانات تلقائياً على صحيح عند توزيع خدمة في AKS. قم بتحديث ملف التكوين الخاص بك، كما في المثال التالي:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)يمكنك أيضاً تمكين Application Insights لمراقبة الخدمة عن طريق تغيير هذا التكوين:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)لإنشاء صورة جديدة وتوزيع نموذج التعلم الآلي، راجع توزيع نماذج التعلم الآلي إلى Azure.
أضف حزمة نقطة "Azure-Monitoring" إلى تبعيات الشروط الخاصة ببيئة خدمة الويب:
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
تعطيل جمع البيانات
يمكنك التوقف عن جمع البيانات في أي وقت. استخدم التعليمة البرمجية Python لتعطيل جمع البيانات.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
التحقق من صحة البيانات الخاصة بك وتحليلها
يمكنك اختيار الأداة التي تفضلها لتحليل البيانات التي تم جمعها في تخزين Blob الخاص بك.
الوصول بسرعة إلى بيانات blob الخاصة بك
تسجيل الدخول إلى مدخل Microsoft Azure .
افتح مساحة العمل الخاصة بك.
اختار التخزين.

اتبع المسار إلى بيانات إخراج blob باستخدام هذه الصيغة:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

تحليل بيانات النموذج باستخدام Power BI
نزّل وافتح Power BI Desktop.
حدد Get Data وحدد Azure Blob Storage.
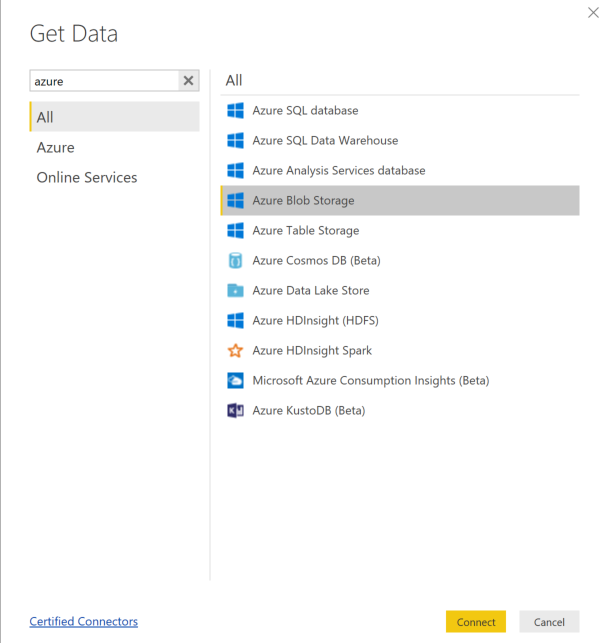
أضف اسم حساب التخزين الخاص بك وأدخل مفتاح التخزين الخاص بك. يمكنك العثور على هذه المعلومات عن طريق تحديد Settings>Access keys في blob.
حدد حاوية model data وحدد Edit.
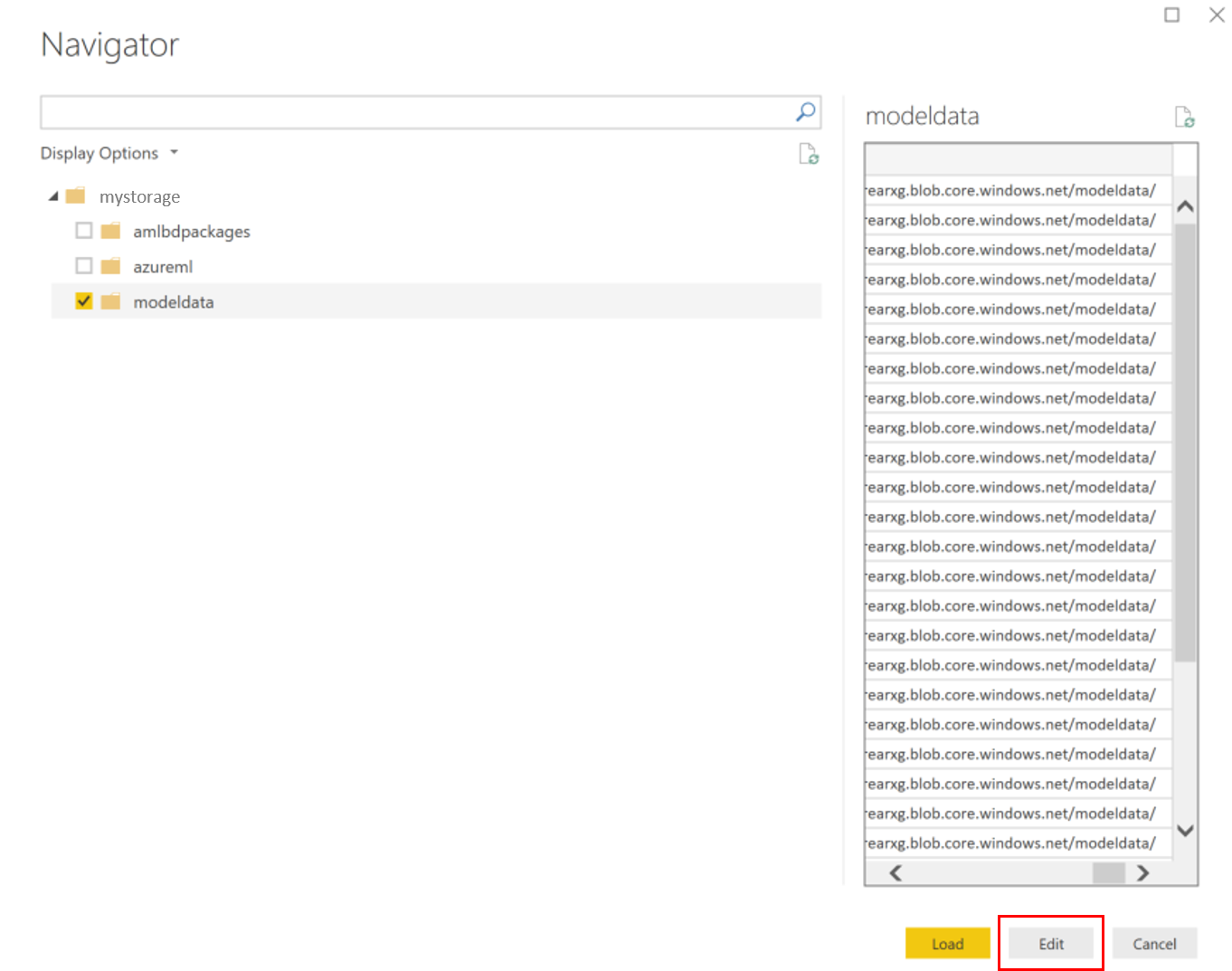
في محرر الاستعلام، انقر أسفل عمود Name وأضف حساب التخزين الخاص بك.
أدخل مسار النموذج الخاص بك في عامل التصفية. إذا كنت تريد البحث فقط في ملفات من عام أو شهر معين، فما عليك سوى توسيع مسار عامل التصفية. على سبيل المثال، للنظر في بيانات شهر مارس فقط، استخدم مسار عامل التصفية هذا:
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<التعيين>/<السنة>/3
قم بتصفية البيانات ذات الصلة بك بناءً على قيم الاسم. إذا قمت بتخزين التنبؤات والمدخلات، فستحتاج إلى إنشاء استعلام لكل منها.
حدد الأسهم المزدوجة لأسفل بجوار عنوان العمود Content لدمج الملفات.
حدد "OK". التحميل المسبق للبيانات.
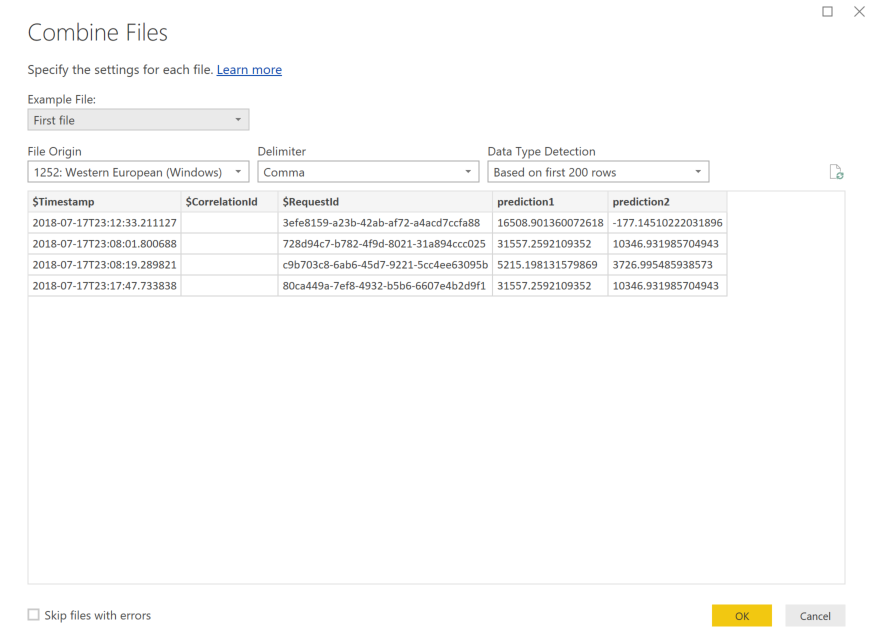
حدد Close and Apply.
إذا أضفت مدخلات وتوقعات، فسيتم ترتيب جداولك تلقائياً حسب قيم معرّف الطلب.
ابدأ في إنشاء تقاريرك المخصصة على بيانات نموذجك.




تحليل بيانات النموذج باستخدام Azure Databricks
انتقل إلى مساحة عمل Databricks الخاصة بك.
في مساحة عمل Databricks الخاصة بك، حدد Upload Data.

حدد Create New Table وحدد Other Data Sources>Azure Blob Storage>Create Table in Notebook.
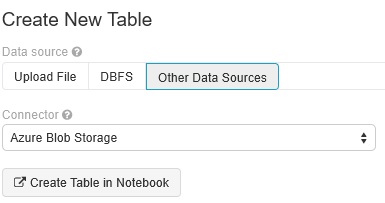
تحديث موقع البيانات الخاصة بك. وفيما يلي مثال على ذلك:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/*/*/data.csv" file_type = "csv"
اتبع الخطوات الموجودة في القالب لعرض بياناتك وتحليلها.



الخطوات التالية
اكتشاف انحراف البيانات في البيانات التي جمعتها.