Най-добри практики за обединяването на данни
Когато настройвате правила за обединяване на данните си в клиентски профил, вземете предвид следните най-добри практики:
Балансирайте времето за обединяване спрямо пълното съвпадение. Опитът да се заснеме всеки възможен мач води до много правила и обединение, което отнема много време.
Добавяйте правила постепенно и проследявайте резултатите. Премахване на правила, които не подобряват резултата от съвпадението.
Дедуплицирайте всяка таблица , така че всеки клиент да бъде представен в един ред.
Използвайте нормализация , за да стандартизирате вариациите в начина, по който са въведени данните, като например Street vs. St. vs. St. vs. St.
Използвайте размито съвпадение стратегически, за да коригирате правописни грешки като bob@contoso.com и bob@contoso.cm. Размитите съвпадения отнемат повече време от точните съвпадения. Винаги проверявайте, за да видите дали допълнителното време, прекарано в размити съвпадения, си струва допълнителния процент на съвпадение.
Стеснете обхвата на съвпаденията с точно съвпадение. Уверете се, че всяко правило с размити условия има поне едно условие за точно съвпадение.
Не съпоставяйте графи, които съдържат силно повтарящи се данни. Уверете се, че графите с размито съвпадение нямат стойности, които се повтарят често, като например стойността по подразбиране на формуляра "Собствено име".
Унификационна производителност
Всяко правило отнема време, за да се изпълни. Модели като сравняване на всяка таблица с всяка друга таблица или опит за улавяне на всяко възможно съвпадение на записа могат да доведат до дълго време за обработка на унификацията. Той също така връща малко, ако има такива, съвпадения в план, който сравнява всяка маса с основна таблица.
Най-добрият подход е да започнете с основен набор от правила, за които знаете, че са необходими, като например сравняване на всяка таблица с основната таблица. Основната ви таблица трябва да бъде таблицата с най-пълните и точни данни. Тази таблица трябва да бъде подредена в горната част на стъпката за обединяване на правилата за съвпадение.
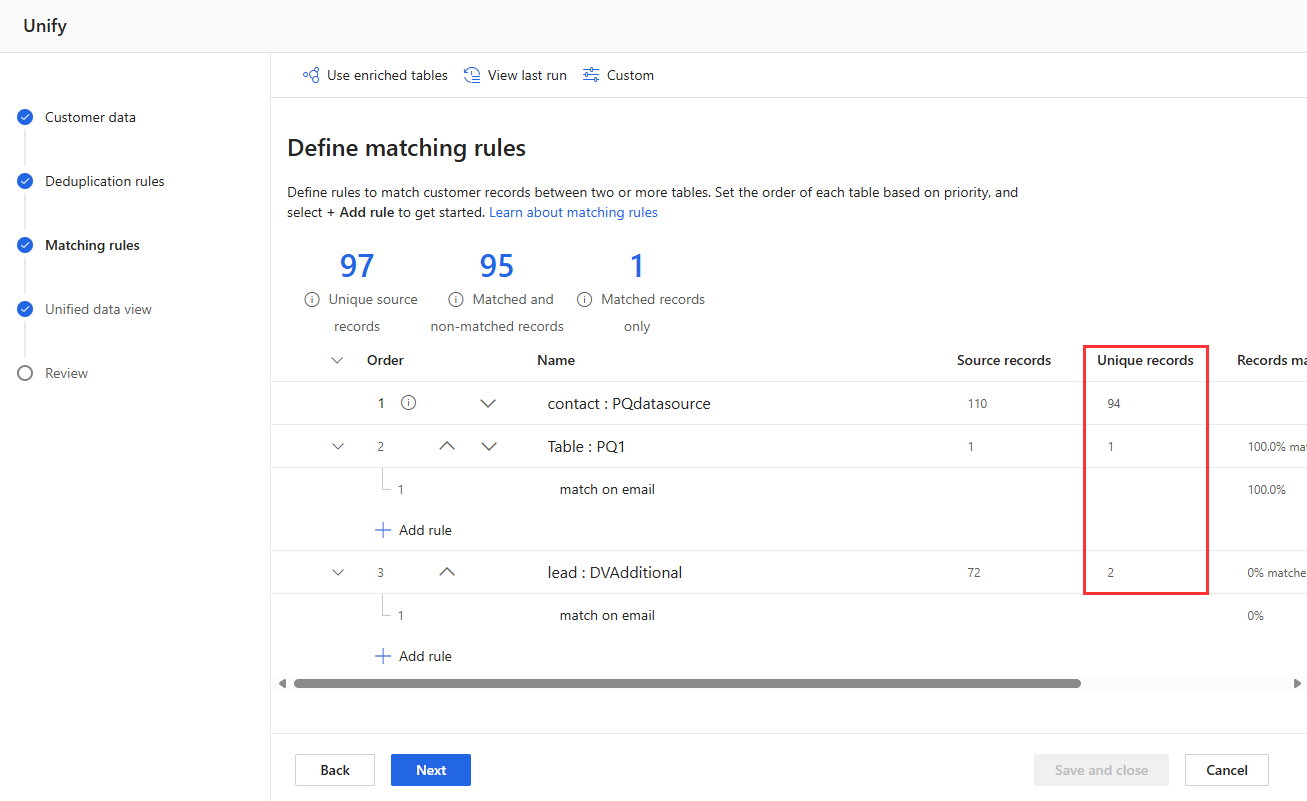
Постепенно добавете няколко правила и вижте колко време отнемат промените и дали резултатите ви се подобряват. Отидете в Настройки>Състояние> на системата и изберете Съвпадение , за да видите колко време отнема дедупликацията и съвпадението за всяко изпълнение на обединението.
Прегледайте статистическите данни за правилата на страниците Правила за дедупликация и Правила за съвпадение, за да видите дали броят на уникалните записи се променя. Ако ново правило съвпада с някои записи и броят на уникалните записи не се променя, тогава предишно правило идентифицира тези съвпадения.
Дедупликация
Използвайте правила за дедупликация, за да премахнете дублиращи се записи на клиенти в таблица, така че един ред във всяка таблица да представлява всеки клиент. Доброто правило идентифицира уникален клиент.
В този прост пример записите 1, 2 и 3 споделят имейл или телефонен номер и представляват едно и също лице.
| ИД | Име | Телефонен номер | Имейл адрес |
|---|---|---|---|
| 1 | Лице 1 | (425) 555-1111 | AAA@A.com |
| 2 | Лице 1 | (425) 555-1111 | BBB@B.com |
| 3 | Лице 1 | (425) 555-2222 | BBB@B.com |
| 4 | Лице 2 | (206) 555-9999 | Person2@contoso.com |
Не искаме да съвпадаме само по име, тъй като това би съвпадало с различни хора с едно и също име.
Създайте Правило 1 с помощта на Име и Телефон, което съвпада със записи 1 и 2.
Създайте Правило 2 с помощта на Име и Имейл, което съвпада със записи 2 и 3.
Комбинацията от Правило 1 и Правило 2 създава една група съвпадения, тъй като те споделят запис 2.
Вие решавате броя на правилата и условията, които уникално идентифицират вашите клиенти. Точните правила зависят от данните, които имате на разположение, качеството на вашите данни и колко изчерпателен искате да бъде процесът на дедупликация.
Победител и алтернативни рекорди
След като правилата се изпълняват и се идентифицират дублиращи се записи, процесът на дедупликация избира "Ред на победителя". Редовете, които не са победители, се наричат "Алтернативни редове". Алтернативните редове се използват в стъпката за обединяване на правилата за съвпадение, за да се съпоставят записите от други маси с реда победител. Редовете се съпоставят с данните в алтернативните редове в допълнение към печелившия ред.
След като добавите правило към таблица, можете да конфигурирате кой ред да изберете като печеливш ред чрез предпочитанията за обединяване. Настройките за обединяване се задават за всяка таблица. Без значение какво правило за сливане е избрано, ако има равенство за печеливш ред, тогава първият ред в реда на данните се използва като тайбрек.
Нормализация
Използвайте нормализиране, за да стандартизирате данните за по-добро съвпадение. Нормализацията работи добре с големи набори от данни.
Нормализираните данни се използват само за целите на сравнението, за да се съпоставят по-ефективно записите на клиентите. Той не променя данните в крайния изход на унифицирания клиентски профил.
| Нормализация | Примери |
|---|---|
| Цифри | Преобразува много Unicode символи, които представляват числа, в прости числа. Примери: ❽ и VIII. са нормализирани до числото 8. Забележка: Символите трябва да бъдат кодирани в Unicode точков формат. |
| Символи | Премахва символи и специални знаци. Примери: !?" #$%&'( )+,.-/:;<=>@^~{}'[ ] |
| Текст с малки букви | Преобразува главните букви в малки букви. Пример: "THIS Is aN EXamplE" се преобразува в "това е пример" |
| Тип – Телефон | Преобразува телефони в различни формати в цифри и отчита вариациите в начина, по който се представят кодовете на държавите и разширенията. Пример: +01 425.555.1212 = 1 (425) 555-1212 |
| Тип - Име | Преобразува над 500 често срещани варианта на имена и заглавия. Примери: "debby" -> "deborah" "prof" и "professor" -> "prof." |
| Тип - Адрес | Преобразува често срещани части от адреси Примери: "улица" -> "улица" и "северозапад" -> "сз" |
| Тип - Организация | Премахва около 50 "шумни думи" като "co", "corp", "corporation" и "ltd". |
| Unicode към ASCII | Преобразува Unicode знаците в техния ASCII буквен еквивалент Пример: Знаците "à", "á", "â", "À", "Á", "Â", "Ã", "Ä", "(A)" и "A" се преобразуват в "a". |
| Интервал | Премахва цялото празно пространство |
| Съпоставяне на псевдоним | Позволява ви да качите персонализиран списък с двойки низове, които след това могат да се използват за обозначаване на низове, които винаги трябва да се считат за точно съвпадение. Използвайте съпоставяне на псевдоними, когато имате конкретни примери за данни, които смятате, че трябва да съвпадат, и не са съпоставени с помощта на някой от другите модели за нормализиране. Пример: Scott and Scooter или MSFT и Microsoft. |
| Персонализирано прескачане | Позволява ви да качите персонализиран списък с низове, които след това могат да се използват за обозначаване на низове, които никога не трябва да се съвпадат. Персонализираното заобикаляне е полезно, когато имате данни с общи стойности, които трябва да се игнорират, като например фиктивен телефонен номер или фиктивен имейл. Пример: Никога не съответствайте на телефона 555-1212 или test@contoso.com |
Точно съвпадение
Използвайте прецизност, за да определите колко близки трябва да бъдат два низа, за да се считат за съвпадение. Настройката за точност по подразбиране изисква точно съвпадение. Всяка друга стойност позволява размито съвпадение за това състояние.
Прецизността може да бъде настроена на ниска (30% съвпадение), средна (60% съвпадение) и висока (80% съвпадение). Или можете да персонализирате и зададете прецизността на стъпки от 1%.
Условия за точно съвпадение
Условията за точно съвпадение се изпълняват първо, за да се получи по-малък набор от стойности за размити съвпадения. За да бъдат ефективни, точните условия на съвпадение трябва да имат разумна степен на уникалност. Ако например всичките ви клиенти живеят в една и съща държава/регион, наличието на точно съвпадение в държавата/региона няма да помогне за стесняване на обхвата.
Колони като полета за пълно име, имейл, телефон или адрес имат добра уникалност и са чудесни колони за използване като точно съвпадение.
Уверете се, че колоната, която използвате за условие за точно съвпадение, няма стойности, които се повтарят често, като например стойност по подразбиране "Собствено име", уловена от формуляр. Прозренията за клиентите могат да профилират колони с данни, за да предоставят представа за най-добрите повтарящи се стойности. Можете да разрешите профилиране на данни във връзки на Azure Data Lake (с помощта на общ модел на данни или делта формат) и Synapse. Профилът на данни се изпълнява при следващо обновяване на източника на данни. За повече информация отидете на Профилиране на данни.
Размито съвпадение
Използвайте размито съвпадение, за да съпоставите низове, които са близки, но не са точни поради правописни грешки или други малки вариации. Използвайте размитото съвпадение стратегически, тъй като е по-бавно от точните съвпадения. Уверете се, че има поне едно условие за точно съвпадение във всяко правило, което има размити условия.
Размитото съвпадение не е предназначено да улови вариации на имена като Сузи и Сюзан. Тези вариации се улавят по-добре с модела за нормализиране Тип: Име или персонализираното съвпадение на псевдонима, където клиентите могат да въведат списъка си с варианти на името, които искат да считат за съвпадения.
Можете да добавите условия към правило, като например съвпадение на собствено име и телефон. Условията в рамките на дадено правило са "И" условия. Всяко условие трябва да съвпада, за да съвпадат редовете. Отделни правила са "ИЛИ" условията. Ако Правило 1 не съвпада с редовете, тогава редовете се сравняват с Правило 2.
Бележка
Само колони с низови типове данни могат да използват размито съвпадение. За колони с други типове данни, като цяло число, double или datetime, полето за точност е само за четене и е зададено на точното съвпадение.
Изчисления на размито съвпадение
Размитите съвпадения се определят чрез изчисляване на оценката на разстоянието между два низа. Ако резултатът отговаря или надвишава прага на точност, низовете се считат за съвпадение.
Разстоянието за редактиране е броят на редакциите, необходими за превръщане на един низ в друг чрез добавяне, изтриване или промяна на знак.
Например, низовете "Жаклин" и "Жаклайн" имат разстояние за редактиране от пет, когато премахнем знаците q, u, e, i и e и вмъкнем знака y.
За да изчислите оценката за редактиране на разстоянието, използвайте следната формула: (Дължина на основния низ – Редактиране на разстоянието) / Дължина на основния низ.
| Основен низ | Низ за сравнение | Резултат |
|---|---|---|
| Жаклин | Жаклин | (10-4)/10=.6 |
| fred@contoso.com | fred@contso.cm | (14-2) / 14 = 0,857 |
| Франклин | франк | (8-3) / 8 = 0.625 |