Co je rozpoznávání klíčových slov?
Rozpoznávání klíčových slov rozpozná slovo nebo krátkou frázi v rámci datového proudu zvuku. Tato technika se také označuje jako vyhledávání klíčových slov.
Nejběžnějším případem rozpoznávání klíčových slov je aktivace hlasem virtuálních asistentů. Například "Hey Cortana" je klíčové slovo pro asistenta Cortany. Po rozpoznání klíčového slova se provede akce specifická pro konkrétní scénář. U scénářů virtuálních asistentů je běžnou výslednou akcí rozpoznávání řeči zvuku, které následuje za klíčovým slovem.
Obecně platí, že virtuální asistenti vždy naslouchají. Rozpoznávání klíčových slov funguje jako hranice ochrany osobních údajů pro uživatele. Požadavek na klíčové slovo funguje jako brána, která brání přenosu nesouvisejícího uživatelského zvuku z místního zařízení do cloudu.
Kvůli vyvážení přesnosti, latence a výpočetní složitosti se rozpoznávání klíčových slov implementuje jako systém s více fázemi. U všech fází mimo první se zvuk zpracuje pouze v případě, že fáze před ní rozpozná klíčové slovo zájmu.
Aktuální systém je navržený s několika fázemi, které pokrývají hraniční zařízení a cloud:
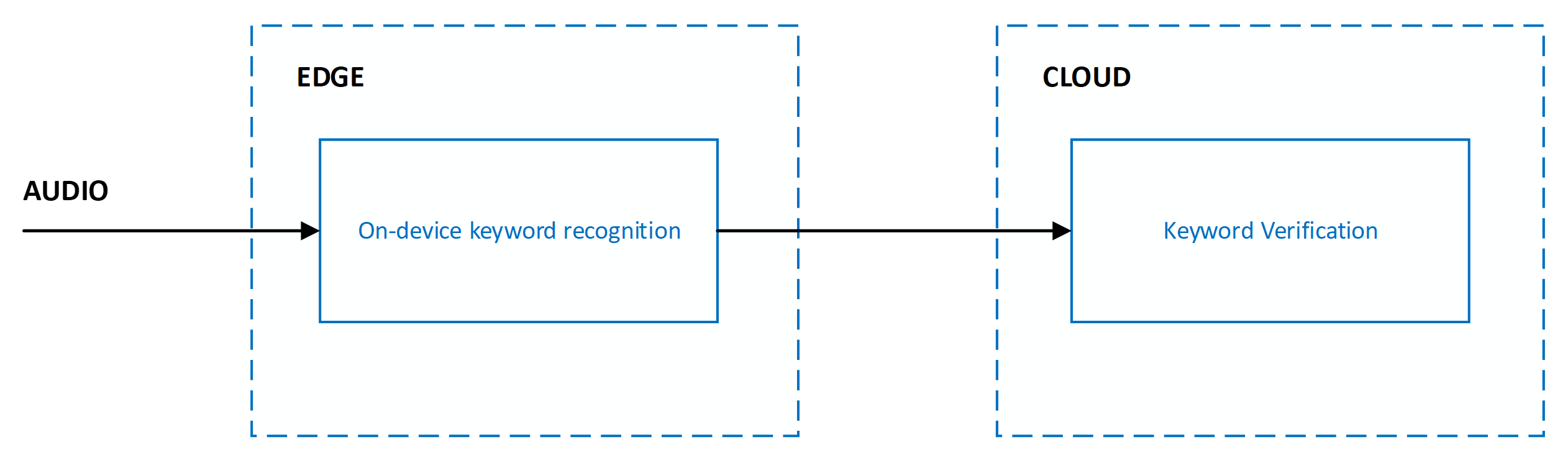
Přesnost rozpoznávání klíčových slov se měří pomocí následujících metrik:
- Správná míra přijetí: Měří schopnost systému rozpoznat klíčové slovo, když ho uživatel mluví. Správná míra přijetí se také označuje jako pravdivá kladná míra.
- Míra nepravdivého přijetí: Měří schopnost systému filtrovat zvuk, který není klíčovým slovem mluveným uživatelem. Falešná míra přijetí se také označuje jako falešně pozitivní míra.
Cílem je maximalizovat správnou míru přijetí a současně minimalizovat míru nepravdivého přijetí. Aktuální systém je navržený tak, aby detekoval klíčové slovo nebo frázi před krátkou tichou. Rozpoznávání klíčového slova uprostřed věty nebo promluvy se nepodporuje.
Vlastní klíčové slovo pro modely na zařízení
Pomocí portálu Custom Keyword v nástroji Speech Studio můžete vygenerovat modely rozpoznávání klíčových slov, které se spouštějí na okraji, zadáním libovolného slova nebo krátké fráze. Model klíčových slov si můžete dále přizpůsobit výběrem správných výslovností.
Ceny
Použití vlastního klíčového slova ke generování modelů, včetně základních i pokročilých modelů, není nijak nákladné. Při použití s jinými funkcemi služby Speech, jako je převod řeči na text, není nijak nákladné spouštět modely na zařízení se sadou Speech SDK.
Typy modelů
Vlastní klíčové slovo můžete použít k vygenerování dvou typů modelů na zařízení pro libovolné klíčové slovo.
| Typ modelu | Popis |
|---|---|
| Basic | Nejvhodnější pro účely demo nebo rychlého vytváření prototypů. Modely se generují pomocí běžného základního modelu a jejich příprava může trvat až 15 minut. Modely nemusí mít optimální charakteristiky přesnosti. |
| Rozšířený | Nejvhodnější pro účely integrace produktů. Modely se generují s přizpůsobením společného základního modelu pomocí simulovaných trénovacích dat ke zlepšení charakteristik přesnosti. Příprava modelů může trvat až 48 hodin. |
Poznámka:
Seznam oblastí, které podporují typ rozšířeného modelu, si můžete prohlédnout v dokumentaci k podpoře oblasti rozpoznávání klíčových slov.
Žádný typ modelu nevyžaduje, abyste nahráli trénovací data. Vlastní klíčové slovo plně zpracovává generování dat a trénování modelu.
Výslovnosti
Když vytvoříte nový model, vlastní klíčové slovo automaticky vygeneruje možné výslovnosti zadaného klíčového slova. Každou výslovnost si můžete poslechnout a vybrat všechny varianty, které přesně představují způsob, jakým uživatelé očekávají, že klíčové slovo říkají. Neměly by být vybrány všechny ostatní výslovnosti.
Je důležité se zamyslet nad výslovnostmi, které vyberete, abyste zajistili nejlepší charakteristiky přesnosti. Pokud například zvolíte více výslovností, než potřebujete, může se zobrazit vyšší míra nepravdivého přijetí. Pokud zvolíte příliš málo výslovností, kde nejsou pokryty všechny očekávané varianty, můžete získat nižší správné míry přijetí.
Testovací modely
Jakmile vlastní klíčové slovo vygeneruje modely na zařízení, můžete modely testovat přímo na portálu. Pomocí portálu můžete mluvit přímo do prohlížeče a získat výsledky rozpoznávání klíčových slov.
Ověření klíčového slova
Ověření klíčových slov je cloudová služba, která snižuje účinek falešně přijímaných z modelů na zařízeních s robustními modely běžícími v Azure. Ladění nebo trénování se nevyžaduje, aby ověření klíčových slov fungovalo s klíčovým slovem. Přírůstkové aktualizace modelu se neustále nasazují do služby, aby se zlepšila přesnost a latence a byly transparentní pro klientské aplikace.
Ceny
Ověření klíčového slova se vždy používá v kombinaci s řečí na text. Za použití ověřování klíčových slov nad rámec nákladů na převod řeči na text se neplatí žádné náklady.
Ověření klíčových slov a převod řeči na text
Při použití ověření klíčových slov je vždy v kombinaci s řečí na text. Obě služby běží paralelně, což znamená, že se do obou služeb odesílá zvuk pro souběžné zpracování.
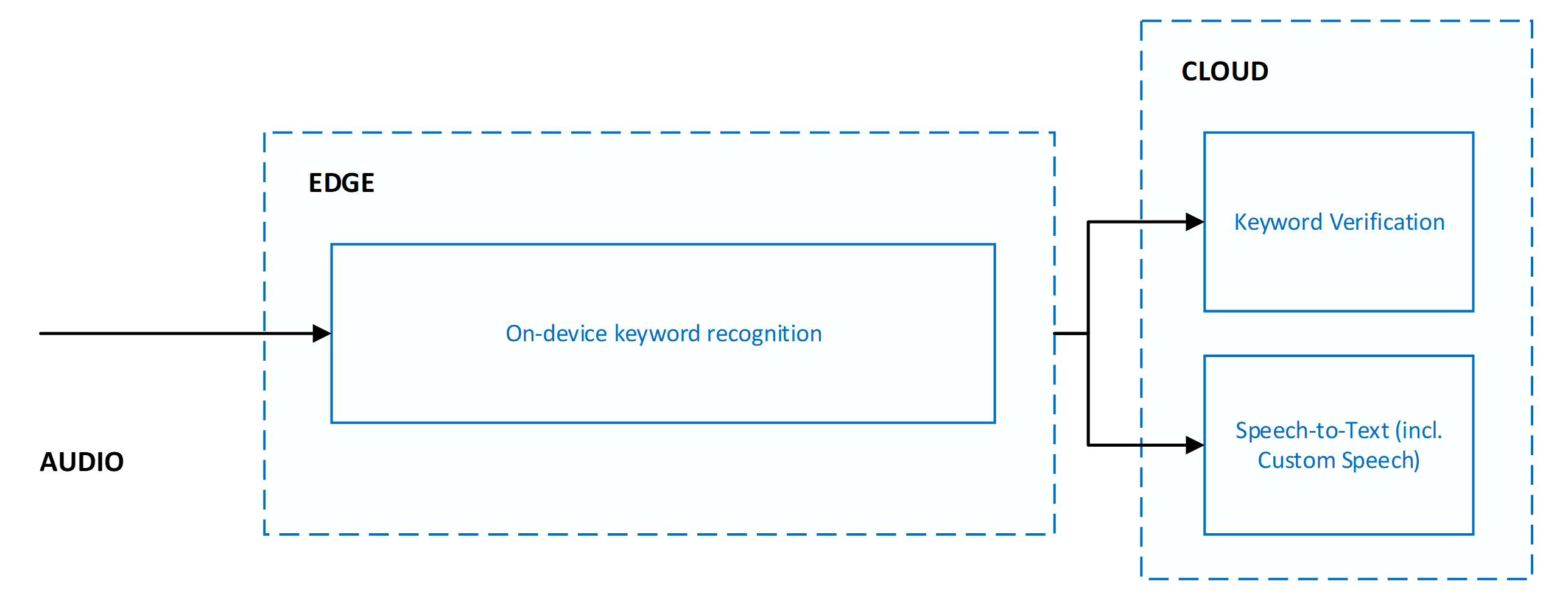
Paralelní spouštění ověřování klíčových slov a řeči na text přináší následující výhody:
- Žádná jiná latence výsledků řeči na text: Paralelní spuštění znamená, že ověření klíčových slov nepřidá žádnou latenci. Klient přijímá výsledky převodu řeči na text tak rychle. Pokud ověření klíčového slova určuje, že klíčové slovo nebylo ve zvuku, zpracování řeči na text se ukončí. Tato akce chrání před zbytečným zpracováním textu. Zpracování síťového a cloudového modelu zvyšuje latenci hlasové aktivace vnímané uživatelem. Další informace najdete v tématu Doporučení a pokyny.
- Předpona vynuceného klíčového slova ve výsledcích převodu řeči na text: Zpracování řeči na text zajišťuje, že výsledky odeslané klientovi mají předponu klíčového slova. Toto chování umožňuje zvýšit přesnost ve výsledcích řeči na text pro řeč, která následuje za klíčovým slovem.
- Zvýšení časového limitu řeči na text: Vzhledem k očekávané přítomnosti klíčového slova na začátku zvuku umožňuje převod řeči na text delší dobu až pět sekund po klíčovém slově, než určí konec řeči a ukončí zpracování textu. Toto chování zajišťuje správné zpracování uživatelského prostředí pro fázované příkazy (<příkaz> pozastavení<>klíčového slova<>) a zřetězených příkazů (<příkaz klíčového slova).><>
Důležité informace o ověření klíčových slov a latenci
Pro každou žádost o službu vrátí ověření klíčového slova jednu ze dvou odpovědí: přijato nebo odmítnuto. Latence zpracování se liší v závislosti na délce klíčového slova a délce zvukového segmentu, u které se očekává, že bude klíčové slovo obsahovat. Latence zpracování nezahrnuje náklady na síť mezi klientem a službami Speech.
| Odpověď na ověření klíčového slova | Popis |
|---|---|
| Akceptováno | Označuje, že služba věřila, že klíčové slovo bylo přítomno ve zvukovém streamu poskytovaném jako součást požadavku. |
| Zamítnuto | Označuje, že služba věřila, že klíčové slovo nebylo k dispozici ve zvukovém streamu poskytnutém jako součást požadavku. |
Odmítnuté případy často přinášejí vyšší latenci, protože služba zpracovává více zvuku než akceptované případy. Ve výchozím nastavení ověření klíčového slova zpracovává maximálně dva sekundy zvuku a hledá klíčové slovo. Pokud se klíčové slovo ve dvou sekundách nenajde, služba vyprší časový limit a signalizuje odmítnutou odpověď klientovi.
Použití ověřování klíčových slov s modely na zařízení z vlastního klíčového slova
Sada Speech SDK umožňuje bezproblémové použití modelů na zařízení generovaných pomocí vlastního klíčového slova s ověřením klíčových slov a převodem řeči na text. Transparentně zpracovává:
- Audio gating to keyword verification and speech recognition based on-device model.
- Komunikace klíčového slova s ověřením klíčových slov
- Komunikace dalších metadat do cloudu pro orchestraci kompletního scénáře
Nemusíte explicitně zadávat žádné parametry konfigurace. Všechny potřebné informace se automaticky extrahují z modelu na zařízení vygenerovaném vlastním klíčovým slovem.
Ukázky a kurzy, které jsou zde propojené, ukazují, jak používat sadu Speech SDK:
- Ukázky hlasového asistenta na GitHubu
- Kurz: Voice enable your assistant built using Azure AI Bot Service with the C# Speech SDK
- Kurz: Vytvoření vlastní aplikace příkazů pomocí jednoduchých hlasových příkazů
Integrace a scénáře sady Speech SDK
Sada Speech SDK umožňuje snadné použití přizpůsobených modelů rozpoznávání klíčových slov na zařízení vygenerovaných pomocí vlastního klíčového slova a ověření klíčových slov. Aby bylo možné zajistit splnění potřeb vašeho produktu, sada SDK podporuje následující dva scénáře:
| Scénář | Popis | Ukázky |
|---|---|---|
| Kompletní rozpoznávání klíčových slov s využitím řeči na text | Nejvhodnější pro produkty, které používají přizpůsobený model klíčových slov na zařízení z vlastního klíčového slova s ověřením klíčových slov a převodem řeči na text. Tento scénář je nejběžnější. | |
| Rozpoznávání klíčových slov offline | Nejvhodnější pro produkty bez síťového připojení, které používají přizpůsobený model klíčových slov na zařízení z vlastního klíčového slova. |