Transformace jímky při mapování toku dat
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Toky dat jsou k dispozici ve službě Azure Data Factory i v kanálech Azure Synapse. Tento článek se týká mapování toků dat. Pokud s transformacemi začínáte, přečtěte si úvodní článek Transformace dat pomocí mapování toku dat.
Po dokončení transformace dat je pomocí transformace jímky zapište do cílového úložiště. Každý tok dat vyžaduje alespoň jednu transformaci jímky, ale k dokončení toku transformace můžete zapisovat do tolika jímek, kolik je potřeba. Pokud chcete zapisovat do dalších jímek, vytvořte nové datové proudy prostřednictvím nových větví a podmíněných rozdělení.
Každá transformace jímky je přidružená přesně k jednomu objektu datové sady nebo propojené službě. Transformace jímky určuje tvar a umístění dat, do které chcete zapisovat.
Vložené datové sady
Při vytváření transformace jímky zvolte, zda jsou informace o jímce definovány uvnitř objektu datové sady nebo v rámci transformace jímky. Většina formátů je k dispozici pouze v jednom nebo druhém. Informace o použití konkrétního konektoru najdete v příslušném dokumentu konektoru.
Pokud je formát podporován pro vložený i v objektu datové sady, existují výhody obou. Objekty datové sady jsou opakovaně použitelné entity, které je možné použít v jiných tocích dat a aktivitách, jako je kopírování. Tyto opakovaně použitelné entity jsou zvlášť užitečné, když používáte posílené schéma. Datové sady nejsou založené na Sparku. V některých případech může být potřeba přepsat určitá nastavení nebo projekce schématu v transformaci jímky.
Vložené datové sady se doporučují, když používáte flexibilní schémata, jednorázové instance jímky nebo parametrizované jímky. Pokud je jímka silně parametrizovaná, vložené datové sady umožňují nevytvořit "fiktivní" objekt. Vložené datové sady jsou založené na Sparku a jejich vlastnosti jsou nativní pro tok dat.
Pokud chcete použít vloženou datovou sadu, vyberte požadovaný formát v selektoru typu jímky. Místo výběru datové sady jímky vyberte propojenou službu, ke které se chcete připojit.
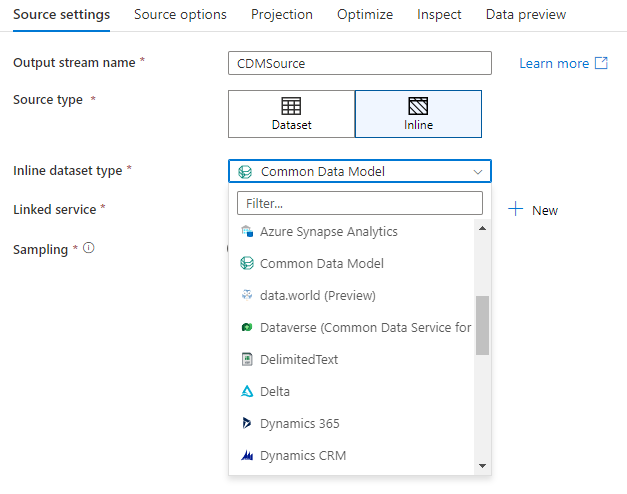
Databáze pracovního prostoru (pouze pracovní prostory Synapse)
Pokud používáte toky dat v pracovních prostorech Azure Synapse, budete mít další možnost, jak data jímit přímo do typu databáze, který je uvnitř vašeho pracovního prostoru Synapse. To zmírní nutnost přidat propojené služby nebo datové sady pro tyto databáze. Databáze vytvořené prostřednictvím šablon databáze Azure Synapse jsou také přístupné, když vyberete databázi pracovního prostoru.
Poznámka:
Konektor Azure Synapse Workspace DB je aktuálně ve verzi Public Preview a v současné době může pracovat pouze s databázemi Spark Lake.
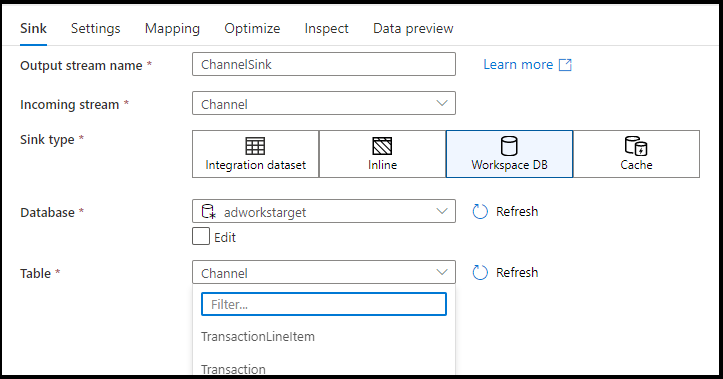
Podporované typy jímky
Mapování toku dat se řídí přístupem extrakce, načítání a transformace (ELT) a pracuje s přípravnými datovými sadami, které jsou všechny v Azure. V současné době je možné v transformaci jímky použít následující datové sady.
| Konektor | Formát | Datová sada nebo vložená datová sada |
|---|---|---|
| Azure Blob Storage | Avro Text s oddělovači Delta JSON ORC Parketové |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB for NoSQL | ✓/- | |
| Azure Data Lake Storage Gen1 | Avro Text s oddělovači JSON ORC Parketové |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 | Avro Common Data Model Text s oddělovači Delta JSON ORC Parketové |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database for MySQL | ✓/✓ | |
| Azure Database for PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL Database | ✓/✓ | |
| Spravovaná instance Azure SQL | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Fabric Lakehouse | ✓/✓ | |
| SFTP | Avro Text s oddělovači JSON ORC Parketové |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Snowflake | ✓/✓ | |
| SQL Server | ✓/✓ |
Nastavení specifické pro tyto konektory se nacházejí na kartě Nastavení. Příklady skriptů pro informace a tok dat v těchto nastaveních najdete v dokumentaci ke konektoru.
Služba má přístup k více než 90 nativním konektorům. Pokud chcete zapisovat data do těchto dalších zdrojů z toku dat, použijte aktivitu kopírování k načtení těchto dat z podporované jímky.
Nastavení jímky
Po přidání jímky nakonfigurujte na kartě Jímka . Tady můžete vybrat nebo vytvořit datovou sadu, do které se vaše jímka zapisuje. Hodnoty vývoje parametrů datové sady je možné konfigurovat v nastavení ladění. (Musí být zapnutý režim ladění.)
Následující video vysvětluje řadu různých možností jímky pro typy souborů s oddělovači textu.
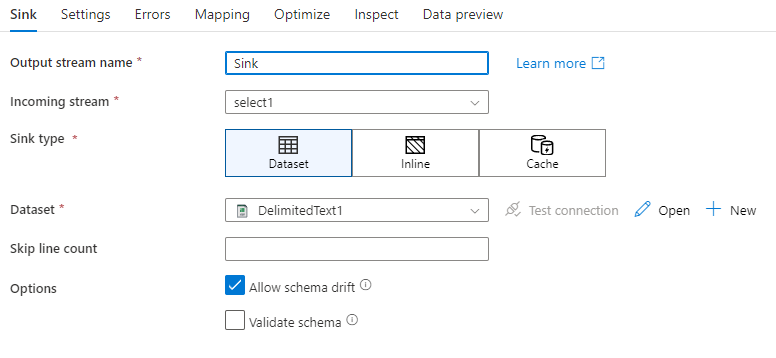
Posun schématu: Posun schématu je schopnost služby nativně zpracovávat flexibilní schémata ve vašich tocích dat, aniž by bylo nutné explicitně definovat změny sloupců. Povolit posun schématu umožňuje psát další sloupce nad tím, co je definováno ve schématu dat jímky.
Ověření schématu: Pokud je vybráno ověření schématu, tok dat selže, pokud se v úložišti jímky nenajde žádný sloupec nebo pokud se datové typy neshodují. Pomocí tohoto nastavení vynucujte, aby schéma jímky splňovalo kontrakt definované projekce. Je užitečné ve scénářích jímky databáze signalizovat, že se změnily názvy nebo typy sloupců.
Jímka mezipaměti
Jímka mezipaměti je, když tok dat zapisuje data do mezipaměti Sparku místo úložiště dat. Při mapování toků dat můžete na tato data v rámci stejného toku odkazovat mnohokrát pomocí vyhledávání v mezipaměti. To je užitečné, když chcete odkazovat na data jako součást výrazu, ale nechcete k nim explicitně spojit sloupce. Běžné příklady, kdy může jímka mezipaměti pomoct, hledá maximální hodnotu v úložišti dat a odpovídající kódy chyb databáze s chybovou zprávou.
Pokud chcete zapisovat do jímky mezipaměti, přidejte transformaci jímky a jako typ jímky vyberte Mezipaměť . Na rozdíl od jiných typů jímky nemusíte vybírat datovou sadu nebo propojenou službu, protože nepíšete do externího úložiště.
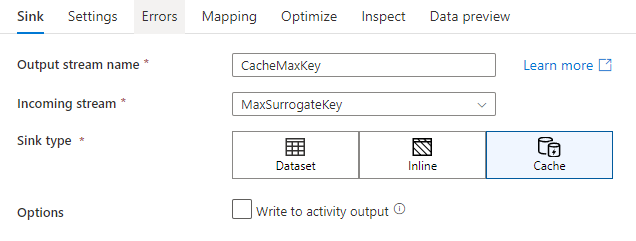
V nastavení jímky můžete volitelně zadat klíčové sloupce jímky mezipaměti. Tyto podmínky se používají jako odpovídající podmínky při použití lookup() funkce ve vyhledávání mezipaměti. Pokud zadáte klíčové sloupce, nemůžete funkci použít outputs() ve vyhledávání mezipaměti. Další informace o syntaxi vyhledávání mezipaměti najdete v tématu vyhledávání v mezipaměti.
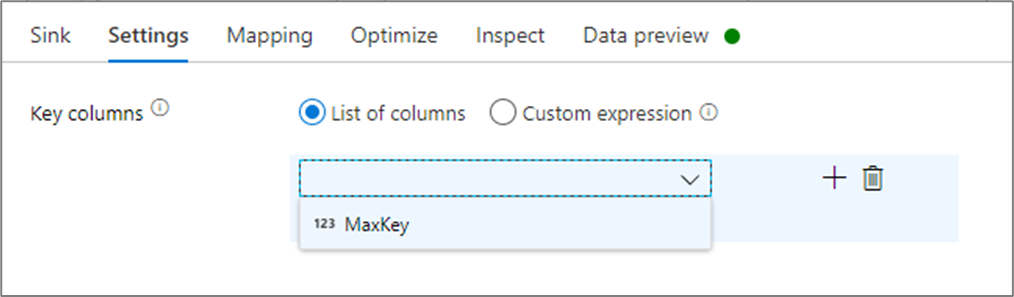
Pokud například zadám sloupec s jedním klíčem column1 v jímce mezipaměti s názvem cacheExample, volání cacheExample#lookup() by měl jeden parametr určující, který řádek v jímce mezipaměti se má shodovat. Funkce vypíše jeden složitý sloupec s dílčími sloupci pro každý namapovaný sloupec.
Poznámka:
Jímka mezipaměti musí být v zcela nezávislém datovém proudu z jakékoli transformace odkazující na ni prostřednictvím vyhledávání mezipaměti. Jímkou mezipaměti musí být také první zapsaná jímka.
Zápis do výstupu aktivity: Jímka uložená v mezipaměti může volitelně zapisovat výstupní data do vstupu další aktivity kanálu. To vám umožní rychle a snadno předávat data z aktivity toku dat, aniž byste je museli uchovávat v úložišti dat.
Metoda aktualizace
U typů jímky databáze bude karta Nastavení obsahovat vlastnost "Metoda aktualizace". Výchozí hodnota je vložení, ale obsahuje také možnosti zaškrtávacího políčka pro aktualizaci, upsert a odstranění. Pokud chcete tyto další možnosti využít, musíte před jímku přidat transformaci alter row. Příkaz Alter Row vám umožní definovat podmínky pro jednotlivé akce databáze. Pokud je zdrojem nativní zdroj CDC, můžete nastavit metody aktualizace bez příkazu Alter Row, protože ADF již znát značky řádků pro vložení, aktualizaci, upsert a odstranění.
Mapování polí
Podobně jako u vybrané transformace můžete na kartě Mapování jímky rozhodnout, které příchozí sloupce se zapíšou. Ve výchozím nastavení se mapují všechny vstupní sloupce, včetně posunovaných sloupců. Toto chování se označuje jako automatické mapování.
Když automatické mapování vypnete, můžete přidat buď pevná mapování založená na sloupcích, nebo mapování založená na pravidlech. Pomocí mapování založených na pravidlech můžete psát výrazy s porovnávání vzorů. Oprava mapování mapuje logické a fyzické názvy sloupců. Další informace o mapování založeném na pravidlech najdete v tématu Vzory sloupců v mapování toku dat.
Vlastní řazení jímek
Ve výchozím nastavení se data zapisují do více jímek v nedeterministickém pořadí. Prováděcí modul zapisuje data paralelně při dokončení logiky transformace a řazení jímky se může lišit při každém spuštění. Pokud chcete zadat přesné řazení jímky, povolte vlastní řazení jímky na kartě Obecné toku dat. Pokud je tato možnost povolená, zapisují se jímky postupně v rostoucím pořadí.
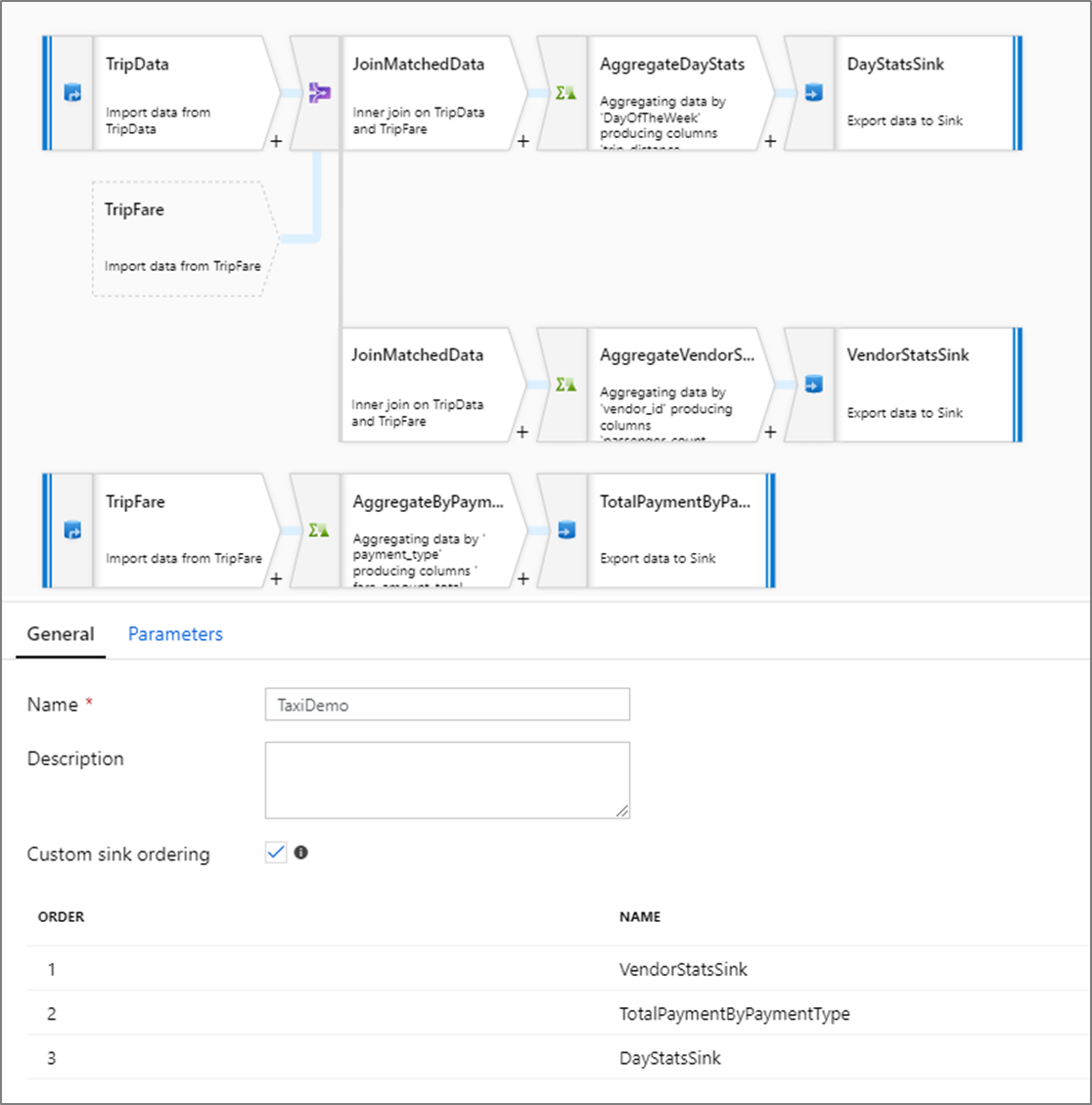
Poznámka:
Při použití vyhledávání uložených v mezipaměti se ujistěte, že pořadí jímek má v mezipaměti nastavené hodnoty 1, nejnižší (nebo první) řazení.
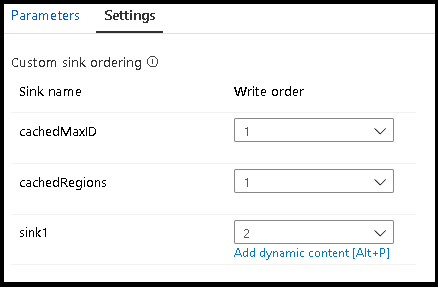
Skupiny jímek
Jímky můžete seskupit tak, že pro řadu jímek použijete stejné číslo objednávky. Služba bude tyto jímky považovat za skupiny, které se můžou spouštět paralelně. Možnosti paralelního spouštění se zobrazí v aktivitě toku dat kanálu.
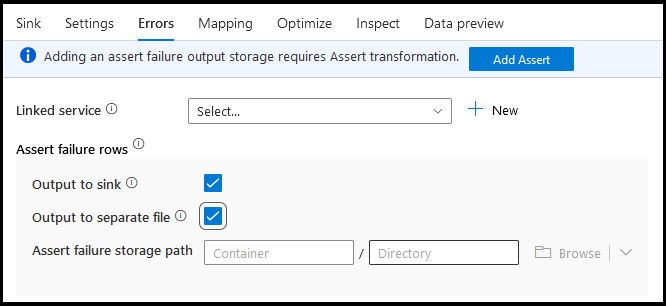
Chyby
Na kartě chyby jímky můžete nakonfigurovat zpracování řádků chyb pro zachycení a přesměrování výstupu pro chyby ovladače databáze a neúspěšné kontrolní výrazy.
Při zápisu do databází můžou některé řádky dat selhat kvůli omezením nastaveným cílem. Spuštění toku dat ve výchozím nastavení selže při první chybě, která se zobrazí. V některých konektorech se můžete rozhodnout pokračovat při chybě , která umožňuje dokončení toku dat i v případě, že jednotlivé řádky obsahují chyby. V současné době je tato funkce dostupná jenom ve službě Azure SQL Database a Azure Synapse. Další informace najdete v tématu Zpracování řádků chyb ve službě Azure SQL DB.
Níže je videokurz o tom, jak v transformaci jímky automaticky používat zpracování řádků chyb databáze.
Pro řádky selhání assert můžete použít upstream transformace Assert ve vašem toku dat a pak přesměrovat neúspěšné kontrolní výrazy do výstupního souboru zde na kartě chyb jímky. Tady máte také možnost ignorovat řádky s chybami kontrolního výrazu a ne všechny tyto řádky vypíšete do cílového úložiště dat jímky.
Náhled dat v jímce
Při načítání náhledu dat v režimu ladění se do jímky nebudou zapisovat žádná data. Snímek toho, jak budou data vypadat, se vrátí, ale do cíle se nic nepíše. Pokud chcete otestovat zápis dat do jímky, spusťte ladění kanálu z plátna kanálu.
Skript toku dat
Příklad
Níže je příklad transformace jímky a skriptu toku dat:
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Související obsah
Teď, když jste vytvořili tok dat, přidejte do kanálu aktivitu toku dat.