Nastavení clusterů ve službě HDInsight se softwarem Apache Hadoop, Apache Spark, Apache Kafka a dalšími
Zjistěte, jak nastavit a nakonfigurovat Apache Hadoop, Apache Spark, Apache Kafka, Interactive Query nebo Apache HBase nebo HDInsight. Zjistěte také, jak přizpůsobit clustery a přidat zabezpečení tím, že je připojíte k doméně.
Cluster Hadoop se skládá z několika virtuálních počítačů (uzlů), které se používají k distribuovanému zpracování úloh. Azure HDInsight zpracovává podrobnosti o implementaci instalace a konfigurace jednotlivých uzlů, takže musíte zadat pouze obecné informace o konfiguraci.
Důležité
Účtování clusteru HDInsight začne vytvořením clusteru a skončí jeho odstraněním. Účtuje se poměrnou částí po minutách, takže byste cluster měli odstranit vždy, když už se nepoužívá. Zjistěte, jak odstranit cluster.
Pokud používáte více clusterů společně, budete chtít vytvořit virtuální síť a pokud používáte cluster Sparku, budete také chtít použít Připojení or služby Hive Warehouse. Další informace najdete v tématu Plánování virtuální sítě pro Azure HDInsight a integrace Apache Sparku a Apache Hivu s Připojení orem Hive Warehouse.
Metody nastavení clusteru
Následující tabulka uvádí různé metody, které můžete použít k nastavení clusteru HDInsight.
| Clustery vytvořené pomocí | Webový prohlížeč | Příkazový řádek | REST API | Sada SDK |
|---|---|---|---|---|
| Azure Portal | ✅ | |||
| Azure Data Factory | ✅ | ✅ | ✅ | ✅ |
| Azure CLI | ✅ | |||
| Azure PowerShell | ✅ | |||
| cURL | ✅ | ✅ | ||
| Šablony Azure Resource Manageru | ✅ |
Tento článek vás provede nastavením na webu Azure Portal, kde můžete vytvořit cluster HDInsight.
Základy
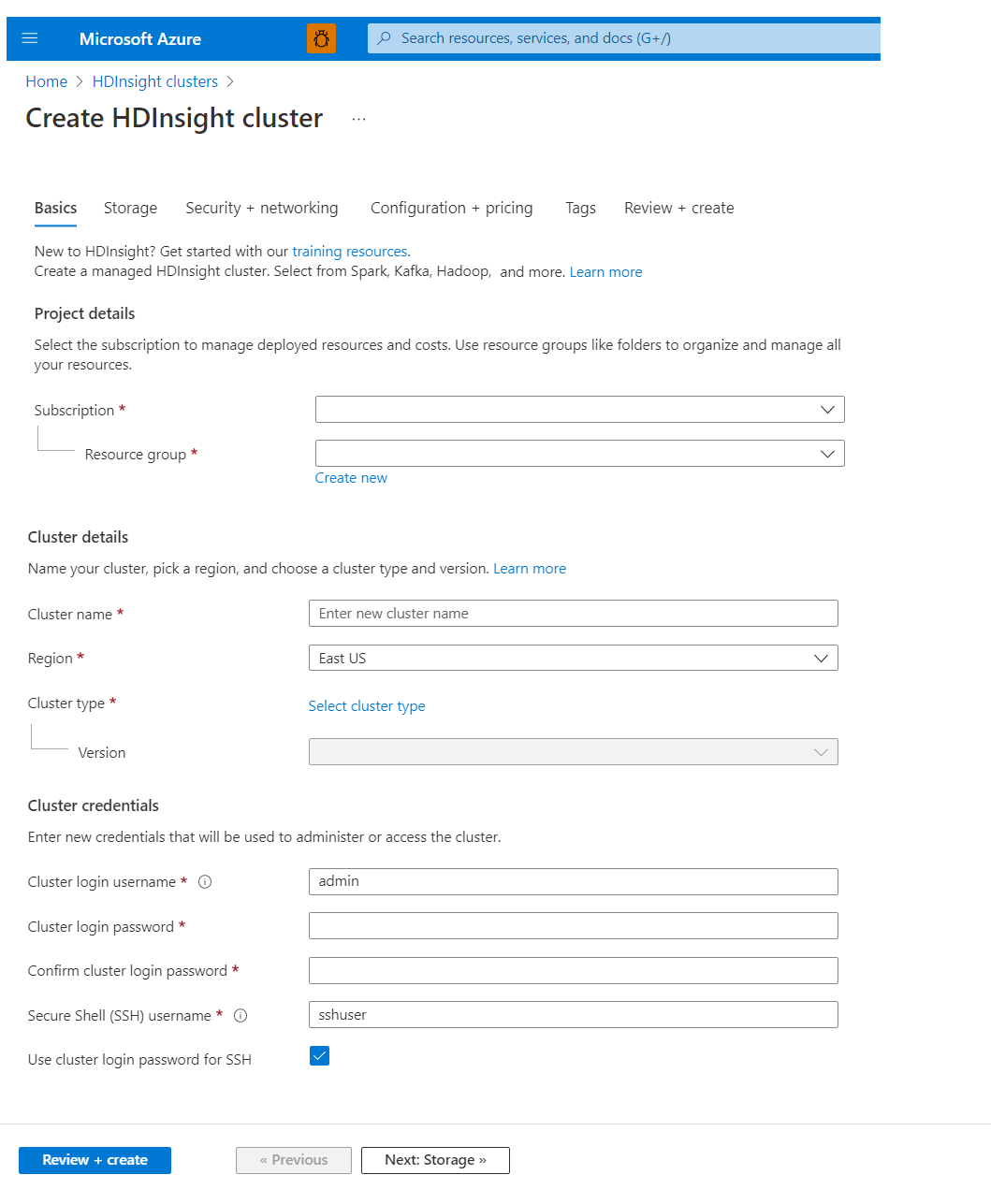
Podrobnosti projektu
Azure Resource Manager vám pomůže pracovat s prostředky ve vaší aplikaci jako se skupinou, která se označuje jako skupina prostředků Azure. Všechny prostředky aplikace můžete nasadit, aktualizovat, monitorovat nebo odstranit v jediné koordinované operaci.
Podrobnosti o clusteru
Název clusteru
Názvy clusterů HDInsight mají následující omezení:
- Povolené znaky: a-z, 0-9, A-Z
- Maximální délka: 59
- Rezervované názvy: aplikace
- Obor pojmenování clusteru je určený pro všechny Azure napříč všemi předplatnými. Název clusteru proto musí být jedinečný po celém světě.
- Prvních šest znaků musí být v rámci virtuální sítě jedinečné.
Oblast
Umístění clusteru nemusíte explicitně zadávat: Cluster je ve stejném umístění jako výchozí úložiště. Pokud chcete zobrazit seznam podporovaných oblastí, vyberte rozevírací seznam Oblastí s cenami služby HDInsight.
Typ clusteru
Azure HDInsight v současné době poskytuje následující typy clusterů, z nichž každá má sadu komponent, které poskytují určité funkce.
Důležité
Clustery HDInsight jsou k dispozici v různých typech, z nichž každá je určená pro jednu úlohu nebo technologii. Neexistuje žádná podporovaná metoda pro vytvoření clusteru, který kombinuje více typů, jako je HBase v jednom clusteru. Pokud vaše řešení vyžaduje technologie rozložené mezi více typů clusterů HDInsight, může virtuální síť Azure připojit požadované typy clusterů.
| Typ clusteru | Funkce |
|---|---|
| Hadoop | Dávkové dotazování a analýza uložených dat |
| HBase | Zpracování velkých objemů bez schématu, dat NoSQL |
| Interaktivní dotaz | Ukládání do mezipaměti v paměti pro interaktivní a rychlejší dotazy Hive |
| Kafka | Distribuovaná platforma streamování, která se dá použít k vytváření datových kanálů a aplikací streamování v reálném čase |
| Spark | Zpracování v paměti, interaktivní dotazy, zpracování mikrodávkových datových proudů |
Verze
Zvolte verzi SLUŽBY HDInsight pro tento cluster. Další informace najdete v části Podporované verze služby HDInsight.
Přihlašovací údaje clusteru
Pomocí clusterů HDInsight můžete během vytváření clusteru nakonfigurovat dva uživatelské účty:
- Uživatelské jméno pro přihlášení ke clusteru: Výchozí uživatelské jméno je správce. Používá základní konfiguraci na webu Azure Portal. Někdy se tomu říká "Uživatel clusteru" nebo "Uživatel HTTP".
- Uživatelské jméno Secure Shell (SSH): Slouží k připojení ke clusteru přes SSH. Další informace najdete v tématu Použití SSH se službou HDInsight.
Uživatelské jméno HTTP má následující omezení:
- Povolené speciální znaky:
_a@ - Nepovolené znaky:
#;."',/:!*?$(){}[]<>|&--=+%~^space' - Maximální délka: 20
Uživatelské jméno SSH má následující omezení:
- Povolené speciální znaky:
_a@ - Nepovolené znaky:
#;."',/:!*?$(){}[]<>|&--=+%~^space' - Maximální délka: 64
- Rezervované názvy: hadoop, users, oozie, hive, mapred, ambari-qa, zookeeper, tez, hdfs, sqoop, yarn, hcat, ams, hbase, administrator, admin, user, user1, test, user2, test1, user3, admin1, 1, 123, a,
actuseradm, admin2, aspnet, backup, console, David, guest, John, owner, root, server, sql, support, support_388945a0, sys, test2, test3, user4, user5, spark
Úložiště
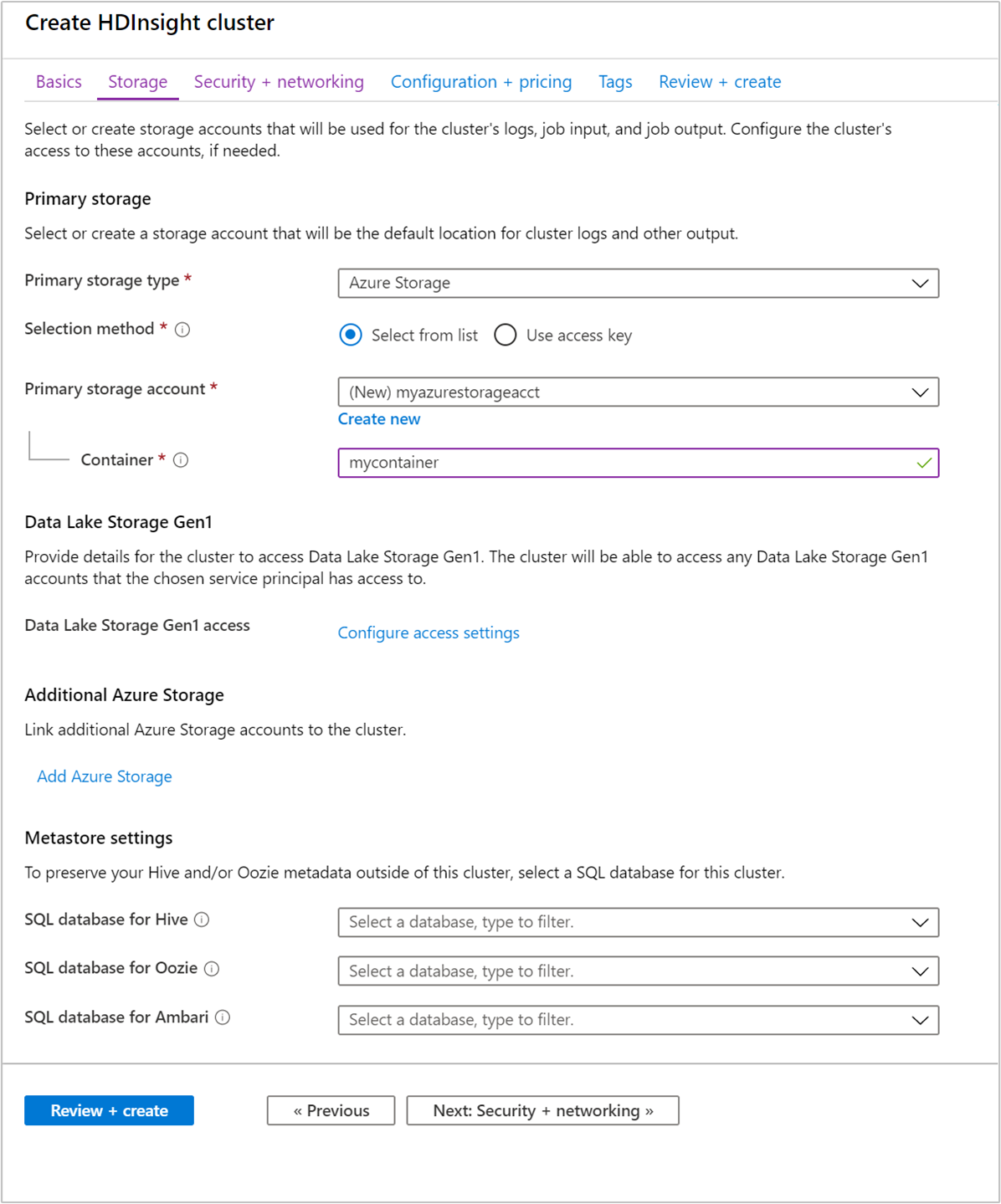
I když místní instalace Systému Hadoop používá systém SOUBORŮ HDFS (Hadoop Distributed File System) pro úložiště v clusteru, v cloudu používáte koncové body úložiště připojené ke clusteru. Použití cloudového úložiště znamená, že můžete bezpečně odstranit clustery HDInsight používané k výpočtu a přitom zachovat data.
Clustery HDInsight můžou používat následující možnosti úložiště:
- Azure Data Lake Storage Gen2
- Azure Data Lake Storage Gen1
- Azure Storage pro obecné účely v2
- Azure Storage pro obecné účely v1
- Objekt blob bloku služby Azure Storage (podporovaný pouze jako sekundární úložiště)
Další informace o možnostech úložiště s HDInsight najdete v tématu Porovnání možností úložiště pro použití s clustery Azure HDInsight.
Upozorňující
Použití dalšího účtu úložiště v jiném umístění než cluster HDInsight se nepodporuje.
Během konfigurace zadáte pro výchozí koncový bod úložiště kontejner objektů blob účtu služby Azure Storage nebo Data Lake Storage. Výchozí úložiště obsahuje protokoly aplikací a systémů. Volitelně můžete zadat další propojené účty Azure Storage a účty Data Lake Storage, ke kterým má cluster přístup. Cluster HDInsight a závislé účty úložiště musí být ve stejném umístění Azure.
Poznámka:
Funkce , která vyžaduje zabezpečený přenos , vynucuje všechny požadavky na váš účet prostřednictvím zabezpečeného připojení. Tuto funkci podporuje pouze cluster HDInsight verze 3.6 nebo novější. Další informace najdete v tématu Vytvoření clusteru Apache Hadoop s účty úložiště zabezpečeného přenosu ve službě Azure HDInsight.
Důležité
Povolení zabezpečeného přenosu úložiště po vytvoření clusteru může vést k chybám při používání účtu úložiště a nedoporučuje se. Lepší je vytvořit nový cluster pomocí účtu úložiště s povoleným zabezpečeným přenosem.
Poznámka:
Azure HDInsight automaticky nepřenese, nepřesune nebo zkopíruje data uložená ve službě Azure Storage z jedné oblasti do druhé.
Nastavení metastoru
Můžete vytvořit volitelné metastory Hive nebo Apache Oozie. Ne všechny typy clusterů však podporují metastory a Služba Azure Synapse Analytics není kompatibilní s metastory.
Další informace najdete v tématu Použití externích úložišť metadat ve službě Azure HDInsight.
Důležité
Při vytváření vlastního metastoru nepoužívejte pomlčky, pomlčky ani mezery v názvu databáze. To může způsobit selhání procesu vytváření clusteru.
Databáze SQL pro Hive
Pokud chcete zachovat tabulky Hive po odstranění clusteru HDInsight, použijte vlastní metastore. Pak můžete metastor připojit k jinému clusteru HDInsight.
Metastor HDInsight vytvořený pro jednu verzi clusteru HDInsight nejde sdílet napříč různými verzemi clusteru HDInsight. Seznam verzí HDInsight najdete v tématu Podporované verze SLUŽBY HDInsight.
Důležité
Výchozí metastore poskytuje azure SQL Database s limitem 5 DTU úrovně Basic (nejde upgradovat).! Vhodné pro základní testovací účely. Pro velké nebo produkční úlohy doporučujeme migrovat do externího metastoru.
Databáze SQL pro Oozie
Pokud chcete zvýšit výkon při použití Oozie, použijte vlastní metastor. Po odstranění clusteru může metastor také poskytnout přístup k datům úlohy Oozie.
Databáze SQL pro Ambari
Ambari se používá k monitorování clusterů HDInsight, provádění změn konfigurace a ukládání informací o správě clusteru, včetně historie úloh. Vlastní funkce databáze Ambari umožňuje nasadit nový cluster a nastavit Ambari v externí databázi, kterou spravujete. Další informace naleznete v tématu Vlastní databáze Ambari.
Důležité
Vlastní metastore Oozie nelze znovu použít. Pokud chcete použít vlastní metastore Oozie, musíte při vytváření clusteru HDInsight poskytnout prázdnou službu Azure SQL Database.
Zabezpečení + sítě
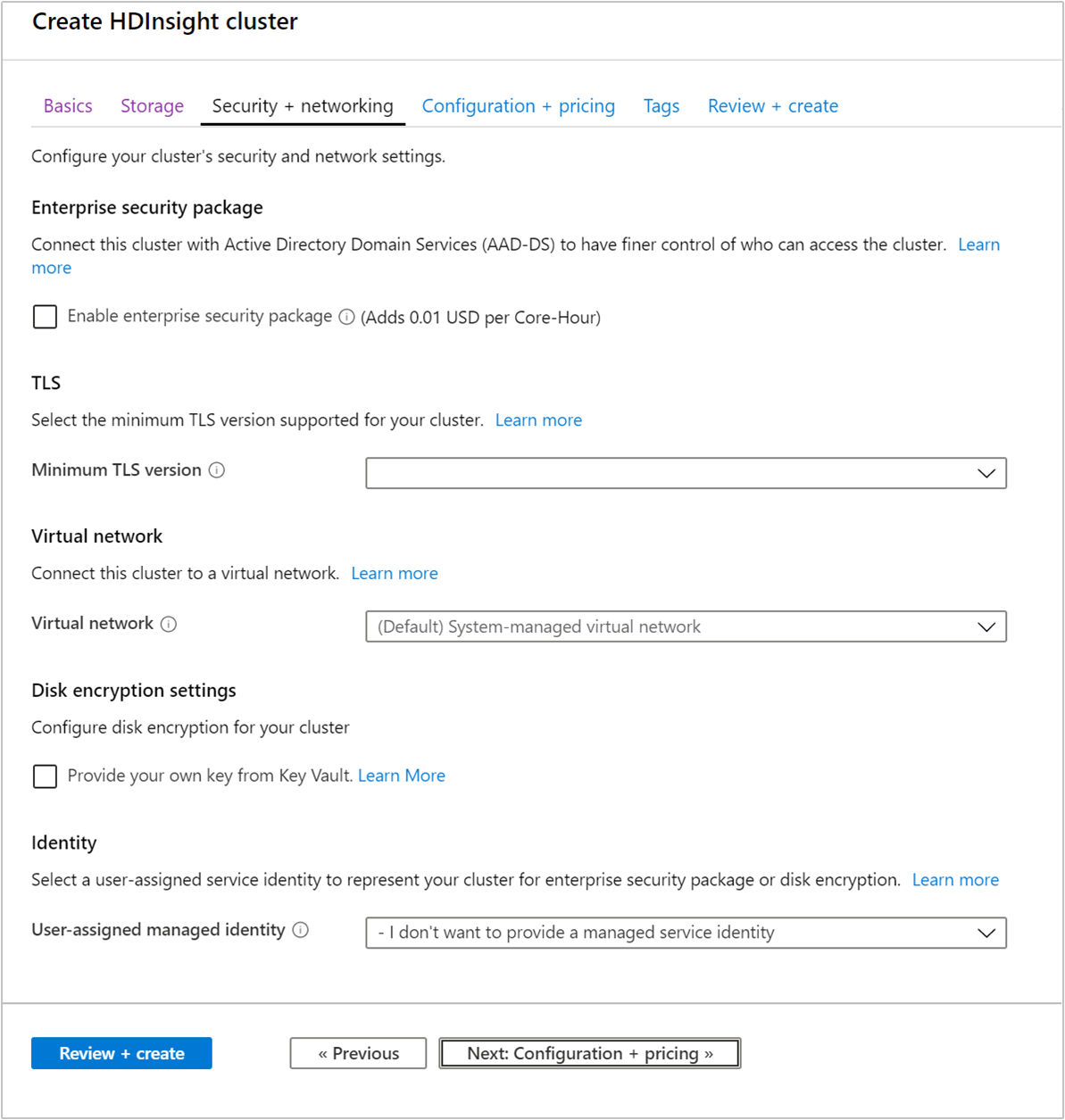
Balíček zabezpečení podniku
U typů clusterů Hadoop, Spark, HBase, Kafka a Interactive Query můžete povolit balíček zabezpečení podniku. Tento balíček nabízí možnost zajistit bezpečnější nastavení clusteru pomocí Apache Rangeru a integrace s ID Microsoft Entra. Další informace najdete v tématu Přehled podnikového zabezpečení ve službě Azure HDInsight.
Balíček zabezpečení podniku umožňuje integrovat HDInsight se službou Active Directory a Apache Ranger. Pomocí balíčku zabezpečení Enterprise je možné vytvořit více uživatelů.
Další informace o vytváření clusteru HDInsight připojeného k doméně najdete v tématu Vytvoření prostředí sandboxu HDInsight připojené k doméně.
Protokol TLS
Další informace naleznete v tématu Transport Layer Security
Virtuální síť
Pokud vaše řešení vyžaduje technologie rozložené mezi více typů clusterů HDInsight, může virtuální síť Azure připojit požadované typy clusterů. Tato konfigurace umožňuje clusterům a veškerý kód, který do nich nasadíte, komunikovat přímo mezi sebou.
Další informace o použití virtuální sítě Azure se službou HDInsight najdete v tématu Plánování virtuální sítě pro HDInsight.
Příklad použití dvou typů clusterů ve virtuální síti Azure najdete v tématu Použití strukturovaného streamování Apache Spark s Apache Kafka. Další informace o používání služby HDInsight s virtuální sítí, včetně konkrétních požadavků na konfiguraci pro virtuální síť, najdete v tématu Plánování virtuální sítě pro HDInsight.
Nastavení šifrování disku
Další informace najdete v tématu Šifrování disku spravovaného zákazníkem.
Proxy REST Kafka
Toto nastavení je k dispozici pouze pro typ clusteru Kafka. Další informace najdete v tématu Použití proxy serveru REST.
Identita
Další informace najdete v tématu Spravované identity ve službě Azure HDInsight.
Konfigurace a ceny
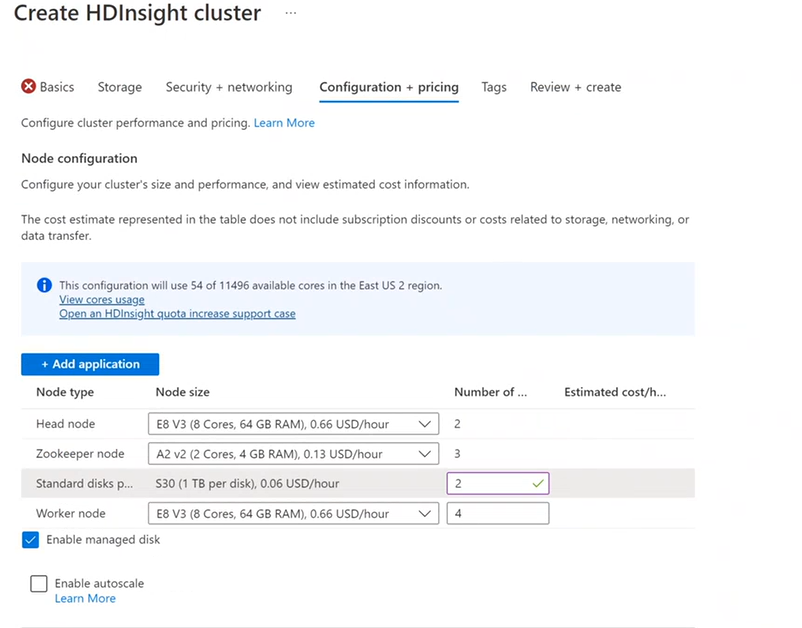
Za využití uzlu se vám účtuje, dokud cluster existuje. Fakturace se spustí při vytvoření clusteru a zastaví se při odstranění clusteru. Clustery nelze zrušit nebo blokovat.
Konfigurace uzlů
Každý typ clusteru má vlastní počet uzlů, terminologii pro uzly a výchozí velikost virtuálního počítače. V následující tabulce je počet uzlů pro každý typ uzlu v závorkách.
| Typ | Uzly | Obrázek |
|---|---|---|
| Hadoop | Hlavní uzel (2), pracovní uzel (1+) | 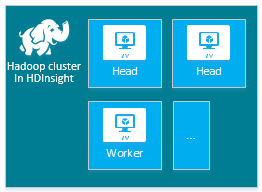
|
| HBase | Hlavní server (2), oblastní server (1+), hlavní uzel/Uzel ZooKeeper (3) | 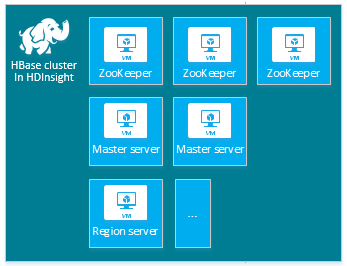
|
| Spark | Hlavní uzel (2), pracovní uzel (1+), uzel ZooKeeper (3) (zdarma pro velikost virtuálního počítače ZooKeeper) | 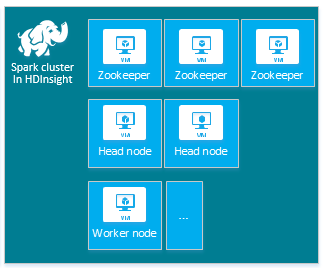
|
Další informace najdete v tématu Výchozí konfigurace uzlů a velikosti virtuálních počítačů pro clustery v tématu Co jsou komponenty a verze Systému Hadoop ve službě HDInsight?
Náklady na clustery HDInsight se určují podle počtu uzlů a velikostí virtuálních počítačů pro uzly.
Různé typy clusterů mají různé typy uzlů, počet uzlů a velikosti uzlů:
- Výchozí typ clusteru Hadoop:
Dva hlavní uzly
Čtyři pracovní uzly
Pokud právě zkoušíte HDInsight, doporučujeme použít jeden pracovní uzel. Další informace o cenách služby HDInsight najdete v tématu Ceny služby HDInsight.
Poznámka:
Limit velikosti clusteru se mezi předplatnými Azure liší. Pokud chcete limit zvýšit, obraťte se na podporu fakturace Azure.
Když ke konfiguraci clusteru použijete Azure Portal, velikost uzlu je k dispozici na kartě Konfigurace a ceny . Na portálu se také zobrazí náklady spojené s různými velikostmi uzlů.
Velikosti virtuálních počítačů
Při nasazování clusterů zvolte výpočetní prostředky na základě řešení, které plánujete nasadit. Pro clustery HDInsight se používají následující virtuální počítače:
- Virtuální počítače řady A a D1-4: Velikosti virtuálních počítačů s Linuxem pro obecné účely
- Virtuální počítač řady D11-14: Velikosti virtuálních počítačů s Linuxem optimalizované pro paměť
Pokud chcete zjistit, jakou hodnotu byste měli použít k určení velikosti virtuálního počítače při vytváření clusteru pomocí různých sad SDK nebo při používání Azure PowerShellu, podívejte se na velikosti virtuálních počítačů, které se mají použít pro clustery HDInsight. V tomto propojeném článku použijte hodnotu ve sloupci Velikost tabulek.
Důležité
Pokud potřebujete v clusteru více než 32 pracovních uzlů, musíte vybrat velikost hlavního uzlu s alespoň 8 jádry a 14 GB paměti RAM.
Další informace najdete v tématu Velikosti virtuálních počítačů. Informace o cenáchrůznýchch
Příloha disku
Poznámka:
Přidané disky jsou nakonfigurované pouze pro místní adresáře Správce uzlů, nikoli pro adresáře datových uzlů.
Cluster HDInsight se dodává s předem definovaným místem na disku na základě skladové položky. Pokud spouštíte některé velké aplikace, může to vést k nedostatku místa na disku s úplnou chybou LinkId=221672#ERROR_NOT_ENOUGH_DISK_SPACE disku a selháním úloh.
Do clusteru je možné přidat další disky pomocí místního adresáře NodeManager nové funkce. V době vytváření clusteru Hive a Spark je možné vybrat a přidat do pracovních uzlů počet disků. Vybraný disk, který bude mít velikost 1 TB, by byl součástí místních adresářů NodeManager.
- Na kartě Konfigurace a ceny
- Výběr možnosti Povolit spravovaný disk
- Z disků Úrovně Standard zadejte počet disků.
- Volba pracovního uzlu
Počet disků můžete ověřit na kartě Zkontrolovat a vytvořit v části Konfigurace clusteru.
Přidání aplikace
Aplikace HDInsight je aplikace, kterou mohou uživatelé nainstalovat do clusteru HDInsight založeného na Linuxu. Můžete používat aplikace poskytované Microsoftem, třetími stranami nebo vámi vyvinutými. Další informace najdete v tématu Instalace aplikací Apache Hadoop třetích stran ve službě Azure HDInsight.
Většina aplikací HDInsight se instaluje na prázdný hraniční uzel. Prázdný hraniční uzel je virtuální počítač s Linuxem se stejnými klientskými nástroji nainstalovanými a nakonfigurovanými jako v hlavním uzlu. Hraniční uzel můžete použít pro přístup ke clusteru, testování klientských aplikací a jejich hostování. Další informace najdete v tématu Použití prázdných hraničních uzlů ve službě HDInsight.
Akce skriptů
Během vytváření můžete nainstalovat další komponenty nebo přizpůsobit konfiguraci clusteru pomocí skriptů. Tyto skripty se vyvolávají prostřednictvím akce skriptu, což je možnost konfigurace, kterou lze použít z webu Azure Portal, rutin prostředí Windows PowerShell služby HDInsight nebo sady HDInsight .NET SDK. Další informace naleznete v tématu Přizpůsobení clusteru HDInsight pomocí akce skriptu.
Některé nativní komponenty Java, jako je Apache Mahout a Cascading, je možné spustit v clusteru jako soubory Java Archive (JAR). Tyto soubory JAR je možné distribuovat do služby Azure Storage a odesílat je do clusterů HDInsight pomocí mechanismů odesílání úloh Hadoop. Další informace naleznete v tématu Odeslání úloh Apache Hadoop programově.
Poznámka:
Pokud máte problémy s nasazením souborů JAR do clusterů HDInsight nebo voláním souborů JAR v clusterech HDInsight, obraťte se na podpora Microsoftu.
Služba HDInsight nepodporuje kaskádové vytváření a nemá nárok na podpora Microsoftu. Seznam podporovaných komponent najdete v tématu Co je nového ve verzích clusteru poskytovaných službou HDInsight.
Někdy chcete během procesu vytváření nakonfigurovat následující konfigurační soubory:
- clusterIdentity.xml
- core-site.xml
- gateway.xml
- hbase-env.xml
- hbase-site.xml
- hdfs-site.xml
- hive-env.xml
- hive-site.xml
- mapred-site
- oozie-site.xml
- oozie-env.xml
- tez-site.xml
- webhcat-site.xml
- yarn-site.xml
Další informace najdete v tématu Přizpůsobení clusterů HDInsight pomocí bootstrap.