Co je Apache Kafka ve službě Azure HDInsight
Apache Kafka je open source distribuovaná streamovací platforma, kterou lze použít k vytváření aplikací a kanálů pro streamování dat v reálném čase. Kafka také poskytuje funkci pro zprostředkování zpráv podobnou frontě zpráv, ve které můžete publikovat pojmenované datové proudy a přihlásit se k jejich odběru.
Tady jsou konkrétní charakteristiky systému Kafka ve službě HDInsight:
Jedná se o spravovanou službu, která poskytuje zjednodušený proces konfigurace. Výsledkem je konfigurace otestovaná a podporovaná Microsoftem.
Microsoft poskytuje smlouvu o úrovni služeb (SLA) zajišťující 99,9% dostupnost platformy Kafka. Další informace najdete v dokumentu Informace o smlouvě SLA pro službu HDInsight.
Jako záložní úložiště pro platformu Kafka se používají Spravované disky Azure. Spravované disky mohou pro každého zprostředkovatele Kafka poskytovat až 16 TB úložiště. Informace o konfiguraci spravovaných disků se systémem Kafka ve službě HDInsight najdete v tématu Zvýšení škálovatelnosti Apache Kafka ve službě HDInsight.
Další informace o spravovaných discích najdete v tématu Azure Managed Disks.
Systém Kafka byl navržený s jednorozměrným pohledem na stojan. Azure rozděluje stojan do dvou dimenzí – aktualizační domény a domény selhání. Microsoft poskytuje nástroje, které obnovují rovnováhu oddílů a replik platformy Kafka mezi aktualizačními doménami a doménami selhání.
Další informace najdete v tématu Vysoká dostupnost apache Kafka ve službě HDInsight.
HDInsight umožňuje změnit počet pracovních uzlů (které jsou hostiteli zprostředkovatele Kafka) po vytvoření clusteru. Vertikální škálování je možné provést z webu Azure Portal, Azure PowerShellu a dalších rozhraní pro správu Azure. V případě platformy Kafka byste po operacích škálování měli obnovit rovnováhu replik oddílů. Díky vyrovnání rovnováhy oddílů může platforma Kafka využívat nový počet pracovních uzlů.
HDInsight Kafka nepodporuje vertikální škálování ani snížení počtu zprostředkovatelů v clusteru. Pokud se pokusíte snížit počet uzlů, vrátí se
InvalidKafkaScaleDownRequestErrorCodechyba.Další informace najdete v tématu Vysoká dostupnost apache Kafka ve službě HDInsight.
Protokoly služby Azure Monitor je možné použít k monitorování Kafka ve službě HDInsight. Protokoly služby Azure Monitor zobrazí informace o úrovni virtuálních počítačů, jako jsou metriky disků a síťových adaptérů a metriky JMX ze systému Kafka.
Další informace najdete v tématu Analýza protokolů pro Apache Kafka ve službě HDInsight.
Architektura Apache Kafka ve službě HDInsight
Následující diagram ukazuje obvyklou konfiguraci platformy Kafka s využitím skupin příjemců, dělení a replikace. Díky tomu nabízí paralelní čtení událostí s odolností proti chybám:
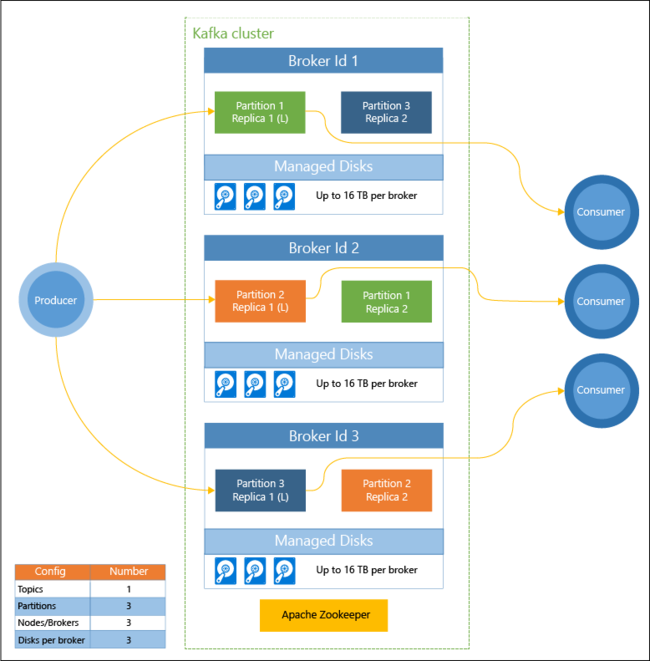
Apache ZooKeeper spravuje stav clusteru Kafka. Služba ZooKeeper je navržená pro souběžné a odolné transakce s nízkou latencí.
Kafka ukládá záznamy (data) v tématech. Záznamy jsou vytvářeny producenty a spotřebovávány konzumenty. Producenti odesílají záznamy do zprostředkovatelů Kafka. Každý pracovní uzel v clusteru HDInsight je zprostředkovatelem Kafka.
Témata rozdělují záznamy do oddílů napříč zprostředkovateli. Při využívání záznamů můžete dosáhnout paralelního zpracování dat díky použití až jednoho konzumenta pro každý oddíl.
K duplikaci oddílů mezi uzly se využívá replikace, která zajišťuje ochranu před výpadky uzlů (zprostředkovatelů). V diagramu je oddíl s označením (L) vedoucím daného oddílu. Provoz producenta se směruje do vedoucích jednotlivých uzlů pomocí stavu, který spravuje ZooKeeper.
Proč používat Apache Kafka ve službě HDInsight?
Tady jsou běžné úlohy a postupy, které je možné provádět s využitím systému Kafka ve službě HDInsight:
| Použít | Popis |
|---|---|
| Replikace dat Apache Kafka | Kafka poskytuje nástroj MirrorMaker, který replikuje data mezi clustery Kafka. Informace o použití MirrorMakeru najdete v tématu Replikace témat Apache Kafka s Apache Kafka ve službě HDInsight. |
| Model zasílání zpráv publikování a odběru | Kafka poskytuje rozhraní API pro producenty pro publikování záznamů do tématu Kafka. Rozhraní API pro příjemce se používá při přihlášení k odběru tématu. Další informace najdete v tématu Začínáme s Apache Kafka ve službě HDInsight. |
| Zpracování datových proudů | Kafka se často používá se Sparkem ke zpracování datových proudů v reálném čase. Kafka 2.1.1 a 2.4.1 (HDInsight verze 4.0 a 5.0) podporují streamovací rozhraní API, které umožňuje vytvářet streamovací řešení bez nutnosti Sparku. Další informace najdete v tématu Začínáme s Apache Kafka ve službě HDInsight. |
| Horizontální škálování | Kafka rozděluje streamy napříč uzly v clusteru HDInsight. Procesy příjemců můžou být přidružené k jednotlivým oddílům pro zajištění vyrovnávání zatížení při využívání záznamů. Další informace najdete v tématu Začínáme s Apache Kafka ve službě HDInsight. |
| Doručení v objednávce | V rámci každého oddílu se záznamy ukládají do datového proudu v pořadí, v jakém byly přijaty. Přidružením jednoho procesu příjemce na oddíl můžete zajistit zpracování záznamů v daném pořadí. Další informace najdete v tématu Začínáme s Apache Kafka ve službě HDInsight. |
| Zasílání zpráv | Vzhledem k tomu, že podporuje model zpráv publikování a odběru, kafka se často používá jako zprostředkovatel zpráv. |
| Sledování aktivit | Vzhledem k tomu, že Kafka poskytuje protokolování záznamů v pořadí, lze ho použít ke sledování a opětovnému vytvoření aktivit. Například akcí uživatelů na webu nebo v aplikaci. |
| Agregace | Pomocí zpracování datových proudů můžete agregovat informace z různých datových proudů a kombinovat a centralizovat informace do provozních dat. |
| Transformace | Pomocí zpracování datových proudů můžete kombinovat a rozšiřovat data z více vstupních témat do jednoho nebo více výstupních témat. |
Další kroky
Následující odkazy popisují používání Apache Kafka ve službě HDInsight: