Použití clusteru HDInsight Spark k analýze dat v Data Lake Storage Gen1
V tomto článku použijete poznámkový blok Jupyter dostupný s clustery HDInsight Spark ke spuštění úlohy, která čte data z účtu Data Lake Storage.
Požadavky
Účet Azure Data Lake Storage Gen1 Postupujte podle pokynů v tématu Začínáme s Azure Data Lake Storage Gen1 pomocí webu Azure Portal.
Cluster Azure HDInsight Spark se službou Data Lake Storage Gen1 jako úložištěm Postupujte podle pokynů v rychlém startu: Nastavení clusterů ve službě HDInsight.
Příprava dat
Poznámka:
Tento krok nemusíte provádět, pokud jste vytvořili cluster HDInsight se službou Data Lake Storage jako výchozím úložištěm. Proces vytváření clusteru přidá do účtu Data Lake Storage nějaká ukázková data, která zadáte při vytváření clusteru. Přejděte do části Použití clusteru HDInsight Spark se službou Data Lake Storage.
Pokud jste vytvořili cluster HDInsight se službou Data Lake Storage jako další úložiště a objekt blob služby Azure Storage jako výchozí úložiště, měli byste nejprve zkopírovat ukázková data do účtu Data Lake Storage. Ukázková data můžete použít z objektu blob služby Azure Storage přidruženého ke clusteru HDInsight.
Otevřete příkazový řádek a přejděte do adresáře, ve kterém je nainstalována AdlCopy, obvykle
%HOMEPATH%\Documents\adlcopy.Spuštěním následujícího příkazu zkopírujte konkrétní objekt blob ze zdrojového kontejneru do Data Lake Storage:
AdlCopy /source https://<source_account>.blob.core.windows.net/<source_container>/<blob name> /dest swebhdfs://<dest_adls_account>.azuredatalakestore.net/<dest_folder>/ /sourcekey <storage_account_key_for_storage_container>Zkopírujte ukázkový datový soubor HVAC.csv v umístění /HdiSamples/HdiSamples/SensorSampleData/hvac/ do účtu Azure Data Lake Storage. Fragment kódu by měl vypadat takto:
AdlCopy /Source https://mydatastore.blob.core.windows.net/mysparkcluster/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv /dest swebhdfs://mydatalakestore.azuredatalakestore.net/hvac/ /sourcekey uJUfvD6cEvhfLoBae2yyQf8t9/BpbWZ4XoYj4kAS5Jf40pZaMNf0q6a8yqTxktwVgRED4vPHeh/50iS9atS5LQ==Upozorňující
Ujistěte se, že názvy souborů a cest používají správné velká písmena.
Zobrazí se výzva k zadání přihlašovacích údajů pro předplatné Azure, ve kterém máte účet Data Lake Storage. Zobrazí se výstup, který bude podobný následujícímu fragmentu kódu:
Initializing Copy. Copy Started. 100% data copied. Copy Completed. 1 file copied.Datový soubor (HVAC.csv) se zkopíruje do složky /hvac v účtu Data Lake Storage.
Použití clusteru HDInsight Spark se službou Data Lake Storage Gen1
Na webu Azure Portal klikněte na dlaždici clusteru Apache Spark (pokud jste ji připnuli na úvodní panel). Můžete také přejít na cluster pod položkou Procházet vše>Clustery HDInsight.
Z okna clusteru Spark klikněte na tlačítko Rychlé odkazy a pak z okna Řídicí panel clusteru klikněte na tlačítko Poznámkový blok Jupyter. Po vyzvání zadejte přihlašovací údaje správce clusteru.
Poznámka:
Může také otevřít poznámkový blok Jupyter pro váš cluster tak, že otevřete následující adresu URL v prohlížeči. Nahraďte CLUSTERNAME názvem clusteru:
https://CLUSTERNAME.azurehdinsight.net/jupyterVytvořte nový poznámkový blok. Klikněte na tlačítko Nový a pak klikněte na tlačítko PySpark.
Vzhledem k tomu, že jste poznámkový blok vytvořili pomocí jádra PySpark, není nutné explicitně tvořit kontexty. Kontexty Spark a Hive se automaticky vytvoří za vás při spuštění první buňky kódu. Můžete začít importem typů nezbytných pro tento scénář. Chcete-li tak učinit, vložte následující fragment kódu do buňky a stiskněte klávesu SHIFT + ENTER.
from pyspark.sql.types import *Při každém spuštění úlohy v Jupyter se název okna webového prohlížeče zobrazí jako (Zaneprázdněn) společně s názvem poznámkového bloku. Zobrazí se také plný kroužek vedle textu PySpark v pravém horním rohu. Po dokončení úlohy se změní na prázdný kruh.

Načtěte ukázková data do dočasné tabulky pomocí souboru HVAC.csv , který jste zkopírovali do účtu Data Lake Storage Gen1. K datům v účtu Data Lake Storage můžete přistupovat pomocí následujícího vzoru adresy URL.
Pokud jako výchozí úložiště máte Data Lake Storage Gen1, HVAC.csv bude na cestě podobné následující adrese URL:
adl://<data_lake_store_name>.azuredatalakestore.net/<cluster_root>/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvNebo můžete použít zkrácený formát, například následující:
adl:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvPokud máte službu Data Lake Storage jako další úložiště, HVAC.csv bude v umístění, kam jste ho zkopírovali, například:
adl://<data_lake_store_name>.azuredatalakestore.net/<path_to_file>Do prázdné buňky vložte následující příklad kódu, nahraďte MYDATALAKESTORE názvem účtu Data Lake Storage a stiskněte SHIFT+ENTER. Tento ukázkový kód registruje data do dočasné tabulky nazývané TVK.
# Load the data. The path below assumes Data Lake Storage is default storage for the Spark cluster hvacText = sc.textFile("adl://MYDATALAKESTORazuredatalakestore. net/cluster/mysparkclusteHdiSamples/HdiSamples/ SensorSampleData/hvac/HVAC.csv") # Create the schema hvacSchema = StructType([StructField("date", StringTy(), False) ,StructField("time", StringType(), FalseStructField ("targettemp", IntegerType(), FalseStructField("actualtemp", IntegerType(), FalseStructField("buildingID", StringType(), False)]) # Parse the data in hvacText hvac = hvacText.map(lambda s: s.split(",")).filt(lambda s: s [0] != "Date").map(lambda s:(str(s[0]), s(s[1]), int(s[2]), int (s[3]), str(s[6]) )) # Create a data frame hvacdf = sqlContext.createDataFrame(hvac,hvacSchema) # Register the data fram as a table to run queries against hvacdf.registerTempTable("hvac")
Vzhledem k tomu, že používáte jádro PySpark, můžete nyní přímo spustit dotaz SQL na dočasnou tabulku TVK, kterou jste právě vytvořili pomocí
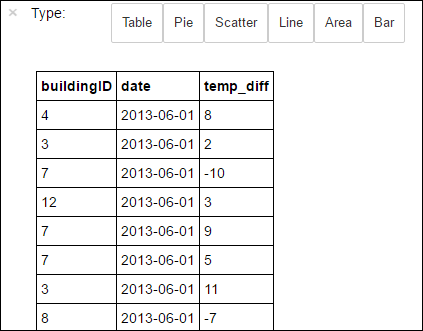
%%sqlmagic. Další informace o%%sqlmagii a dalších magických prostředích dostupných s jádrem PySpark najdete v tématech Jádra dostupná v poznámkových blocích Jupyter s clustery Apache Spark HDInsight.%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Po úspěšném dokončení úlohy se ve výchozím nastavení zobrazí následující tabulkový výstup.
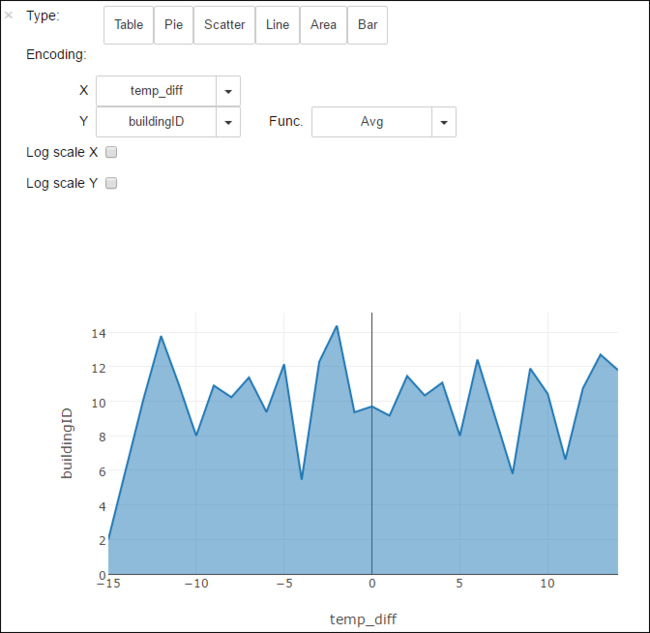
Výsledky můžete také zobrazit v dalších vizualizacích. Například plošný graf pro stejný výstup bude vypadat následovně.
Po dokončení spuštění aplikace byste měli poznámkový blok vypnout a uvolnit tak prostředky. To provedete kliknutím na položku Zavřít a zastavit z nabídky Soubor v poznámkovém bloku. Dojde k vypnutí a zavření poznámkového bloku.
Další kroky
- Vytvoření samostatné aplikace Scala pro spuštění v clusteru Apache Spark
- Použití nástrojů HDInsight v sadě Azure Toolkit for IntelliJ k vytvoření aplikací Apache Spark pro cluster HDInsight Spark s Linuxem
- Použití nástrojů HDInsight v sadě Azure Toolkit for Eclipse k vytvoření aplikací Apache Spark pro cluster HDInsight Spark s Linuxem
- Použití služby Azure Data Lake Storage Gen2 s clustery Azure HDInsight