Monitorování stavu datových konektorů
Pokud chcete zajistit kompletní a nepřerušovaný příjem dat ve službě Microsoft Sentinel, sledujte stav, připojení a výkon datových konektorů.
Následující funkce umožňují provádět toto monitorování z Microsoft Sentinelu:
Sešit monitorování stavu shromažďování dat: Tento sešit poskytuje další monitorování, detekuje anomálie a poskytuje přehled o stavu příjmu dat pracovního prostoru. Pomocí logiky sešitu můžete monitorovat obecný stav přijatých dat a vytvářet vlastní zobrazení a upozornění založená na pravidlech.
Tabulka dat SentinelHealth (Preview):Dotazování na tuto tabulku poskytuje přehled o posunech stavu, jako jsou nejnovější události selhání na konektor nebo konektory se změnami z úspěchu na stavy selhání, které můžete použít k vytváření upozornění a dalších automatizovaných akcí. Tabulka dat SentinelHealth je aktuálně podporovaná jenom pro vybrané datové konektory.
Důležité
Tabulka dat SentinelHealth je aktuálně ve verzi PREVIEW. Další právní podmínky týkající se funkcí Azure, které jsou v beta verzi, preview nebo jinak ještě nejsou vydané v obecné dostupnosti, najdete v dodatečných podmínkách použití pro Microsoft Azure Preview.
Zobrazte stav a stav připojených systémů SAP: Zkontrolujte informace o stavu systémů SAP v datovém konektoru SAP a pomocí šablony pravidla upozornění získejte informace o stavu shromažďování dat agenta SAP.
Použití sešitu monitorování stavu
Na portálu Microsoft Sentinel vyberte v části Správa obsahu navigační nabídky centrumobsahu.
V centru obsahu zadejte stav na panelu hledání a vyberte monitorování stavu shromažďování dat z výsledků.
V podokně podrobností vyberte Nainstalovat . Když se zobrazí zpráva s oznámením, že je sešit nainstalovaný, nebo pokud se místo instalace zobrazí konfigurace, přejděte k dalšímu kroku.
V navigační nabídce vyberte Sešity v části Správa hrozeb.
Na stránce Sešity vyberte kartu Šablony, zadejte stav na panelu hledání a vyberte monitorování stavu shromažďování dat z výsledků.
Pokud chcete sešit použít tak, jak je, vyberte Zobrazit šablonu. Pokud však chcete vytvořit upravitelnou kopii sešitu, vyberte Uložit. Po vytvoření kopie vyberte Zobrazit uložený sešit.
Jakmile budete v sešitu, nejprve vyberte předplatné a pracovní prostor , které chcete zobrazit, a pak definujte časové uspořádání pro filtrování dat podle vašich potřeb. Pomocí přepínače Zobrazit nápovědu zobrazíte místní vysvětlení sešitu.
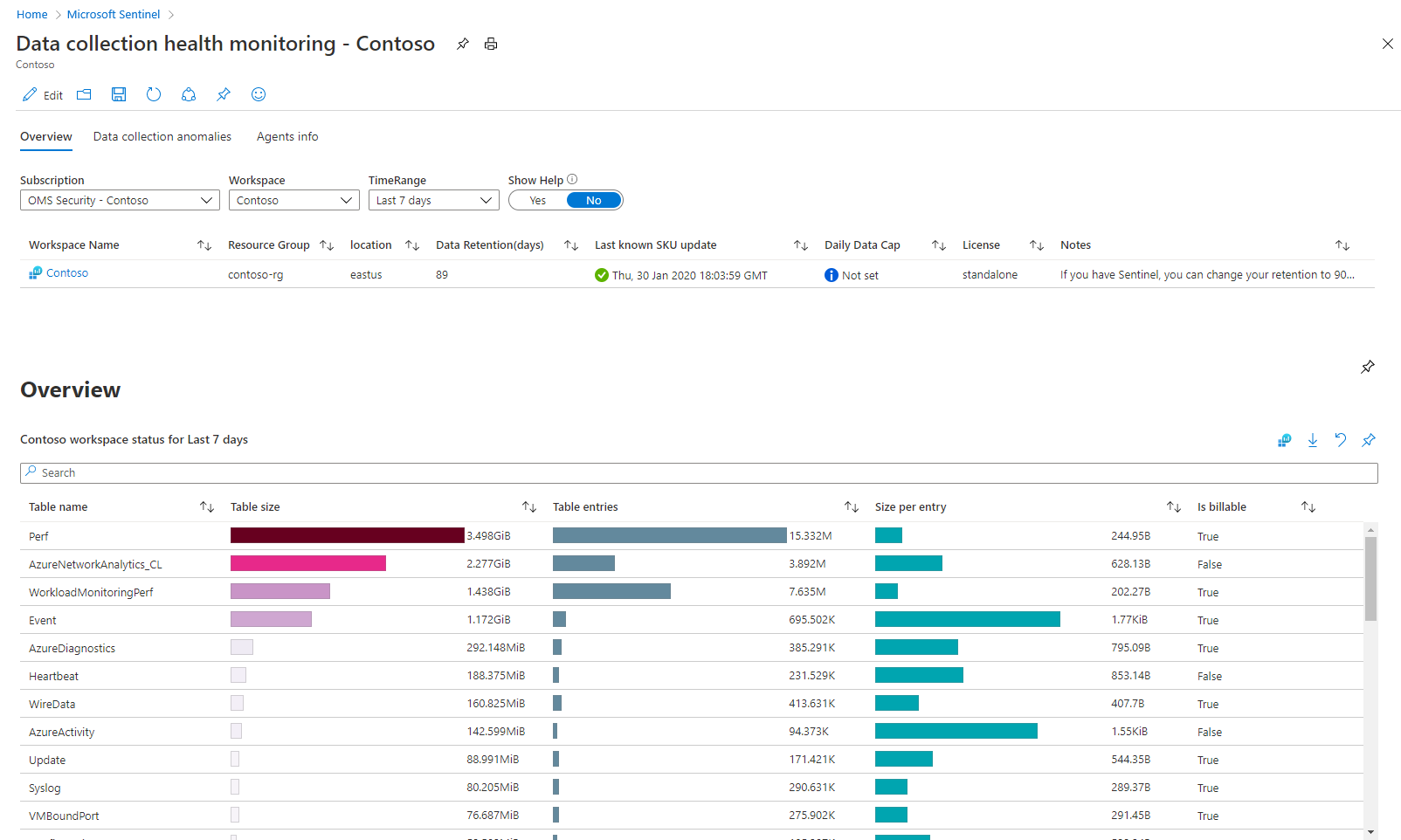

V tomto sešitu jsou tři oddíly s kartami:
Na kartě Přehled se zobrazuje obecný stav příjmu dat ve vybraném pracovním prostoru: objemové míry, míry EPS a čas přijetí posledního protokolu.
Karta Anomálie shromažďování dat vám pomůže odhalit anomálie v procesu shromažďování dat podle tabulky a zdroje dat. Každá karta představuje anomálie pro určitou tabulku (karta Obecné obsahuje kolekci tabulek). Anomálie se počítají pomocí funkce series_decompose_anomalies(), která vrací skóre anomálií. Další informace o této funkci Nastavte pro funkci následující parametry, které se mají vyhodnotit:
AnomálieTimeRange: Tento výběr času se vztahuje pouze na zobrazení anomálií kolekce dat.
SampleInterval: Časový interval, ve kterém se data vzorkují v daném časovém rozsahu. Skóre anomálií se počítá jenom pro data z posledního intervalu.
PositiveAlertThreshold: Tato hodnota definuje prahovou hodnotu kladného skóre anomálií. Přijímá desetinné hodnoty.
NegativeAlertThreshold: Tato hodnota definuje prahovou hodnotu záporného skóre anomálií. Přijímá desetinné hodnoty.

Na kartě Informace o agentech se zobrazují informace o stavu agentů Log Analytics nainstalovaných na různých počítačích, ať už virtuální počítač Azure, jiný cloudový virtuální počítač, místní virtuální počítač nebo fyzický počítač. Můžete monitorovat následující:
Umístění systému
Stav a latence prezenčních signálů
Dostupná paměť a místo na disku
Operace agenta
V této části je nutné vybrat kartu, která popisuje prostředí vašich počítačů: Pokud chcete zobrazit jenom počítače spravované službou Azure Arc, zvolte kartu Počítače spravované v Azure. Pokud chcete zobrazit spravované počítače i počítače mimo Azure s nainstalovaným agentem Log Analytics, zvolte kartu Všechny počítače .



Použití tabulky dat SentinelHealth (Public Preview)
Pokud chcete získat data o stavu datového konektoru z tabulky dat SentinelHealth , musíte nejprve zapnout funkci stavu služby Microsoft Sentinel pro váš pracovní prostor. Další informace najdete v tématu Zapnutí monitorování stavu pro Microsoft Sentinel.
Jakmile je funkce stavu zapnutá, vytvoří se tabulka dat SentinelHealth při první úspěšné nebo neúspěšné události vygenerované pro datové konektory.
Podporované datové konektory
Tabulka dat SentinelHealth se v současné době podporuje jenom pro následující datové konektory:
- Amazon Web Services (CloudTrail a S3)
- Dynamics 365
- Office 365
- Microsoft Defender for Endpoint
- Analýza hrozeb – TAXII
- Platformy analýzy hrozeb
Principy událostí tabulky SentinelHealth
V tabulce SentinelHealth jsou zaznamenány následující typy událostí stavu:
Změna stavu načítání dat Protokoluje se jednou za hodinu, dokud stav datového konektoru zůstane stabilní, a to buď s nepřetržitým úspěchem nebo událostmi selhání. Pokud se stav datového konektoru nezmění, monitorování funguje jenom každou hodinu, aby se zabránilo redundantnímu auditování a zmenšení velikosti tabulky. Pokud stav datového konektoru obsahuje průběžné selhání, do sloupce ExtendedProperties se zahrnou další podrobnosti o selháních.
Pokud se stav datového konektoru změní, ať už z úspěchu na selhání, od selhání po úspěch nebo se změní z důvodů selhání, událost se zaprotokoluje okamžitě, aby váš tým mohl provést proaktivní a okamžitou akci.
Potenciálně přechodné chyby, jako je omezování zdrojové služby, se protokolují až po dobu delší než 60 minut. Tyto 60 minut umožňují službě Microsoft Sentinel překonat přechodný problém v back-endu a zachytit data, aniž by bylo nutné provést žádnou akci uživatele. Chyby, které rozhodně nejsou přechodné, se protokolují okamžitě.
Souhrn selhání Protokolováno jednou za hodinu na konektor a pracovní prostor s agregovaným souhrnem selhání. Souhrnné události selhání se vytvoří jenom v případě, že konektor během dané hodiny zaznamenal chyby dotazování. Obsahují všechny další podrobnosti uvedené ve sloupci ExtendedProperties , například časové období, pro které se zdrojová platforma konektoru dotazovala, a jedinečný seznam selhání, ke kterým došlo během časového období.
Další informace najdete ve schématu sloupců tabulky SentinelHealth.
Spouštění dotazů pro detekci odchylek stavu
Vytvářejte dotazy v tabulce SentinelHealth , které vám pomůžou detekovat odchylky stavu v datových konektorech. Příklad:
Zjištění nejnovějších událostí selhání na konektor:
SentinelHealth
| where TimeGenerated > ago(3d)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId
| where Status == 'Failure'
Detekce konektorů se změnami z neúspěšného stavu na úspěch:
let lastestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextToLastestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (lastestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
lastestStatus
| join kind=inner (nextToLastestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Failure' and LastStatus == 'Success'
Detekce konektorů se změnami z úspěšného stavu na stav selhání:
let lastestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextToLastestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (lastestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
lastestStatus
| join kind=inner (nextToLastestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Success' and LastStatus == 'Failure'
Konfigurace výstrah a automatizovaných akcí pro problémy se stavem
Analytická pravidla Microsoft Sentinelu můžete použít ke konfiguraci automatizace v protokolech Microsoft Sentinelu, pokud chcete být upozorněni a provést okamžitou akci pro posuny stavu datových konektorů, doporučujeme použít pravidla upozornění služby Azure Monitor.
Příklad:
V pravidlu upozornění služby Azure Monitor vyberte pracovní prostor Služby Microsoft Sentinel jako obor pravidla a jako první podmínku vyhledejte vlastní protokol .
Podle potřeby přizpůsobte logiku upozornění, jako je frekvence nebo doba trvání zpětného vyhledávání, a pak pomocí dotazů vyhledejte odchylky stavu.
U akcí pravidla vyberte existující skupinu akcí nebo podle potřeby vytvořte novou, abyste nakonfigurovali nabízená oznámení nebo jiné automatizované akce, jako je aktivace aplikace logiky, webhooku nebo funkce Azure Functions ve vašem systému.
Další informace najdete v přehledu upozornění služby Azure Monitor a v protokolu upozornění služby Azure Monitor.
Další kroky
- Přečtěte si o auditování a monitorování stavu v Microsoft Sentinelu.
- Zapněte auditování a monitorování stavu v Microsoft Sentinelu.
- Monitorujte stav pravidel automatizace a playbooků.
- Monitorujte stav a integritu analytických pravidel.
- Další informace o schématech tabulek SentinelHealth a SentinelAudit