Získání pozice obličeje pomocí viseme
Poznámka:
Pokud chcete prozkoumat národní prostředí podporovaná pro ID viseme a obrazce prolnutí, projděte si seznam všech podporovaných národních prostředí. Škálovatelná vektorová grafika (SVG) je podporována pouze pro en-US národní prostředí.
Viseme je vizuální popis fonemu v mluveném jazyce. Definuje pozici obličeje a úst, když člověk mluví. Každý viseme znázorňuje klíčové pozice obličeje pro určitou sadu fonetů.
Pomocí visem můžete řídit pohyb modelů 2D a 3D avatarů, aby pozice obličeje byly co nejlépe v souladu se syntetickou řečí. Je například možné:
- Vytvořte animovaného virtuálního hlasového asistenta pro inteligentní veřejné terminály a vytvořte integrované služby s více režimy pro vaše zákazníky.
- Vytvářejte imerzivní vysílání zpráv a vylepšete zkušenosti posluchačů s přirozenými pohyby tváří a úst.
- Vygenerujte interaktivní herní avatary a kreslené postavy, které můžou mluvit s dynamickým obsahem.
- Udělejte efektivnější výuku jazyků, která pomáhají posluchačům jazyka porozumět chování jednotlivých slov a foonemu.
- Lidé s poruchou sluchu může také vizuálně vyzvednout zvuk a "rt-read" řečový obsah, který ukazuje visemes na animované tváři.
Další informace o visemech najdete v tomto úvodním videu.
Celkový pracovní postup vytváření viseme s využitím řeči
Neurální text na řeč (Neurální TTS) změní vstupní text nebo jazyk SSML (Speech Synthesis Markup Language) na lifelike syntetizovaný řeč. Zvukový výstup řeči může být doprovázen viseme ID, SVG (Scalable Vector Graphics) nebo směšovat obrazce. Pomocí 2D nebo 3D vykreslovacího modulu můžete pomocí těchto událostí viseme animovat avatara.
Celkový pracovní postup viseme je znázorněný v následujícím vývojovém diagramu:
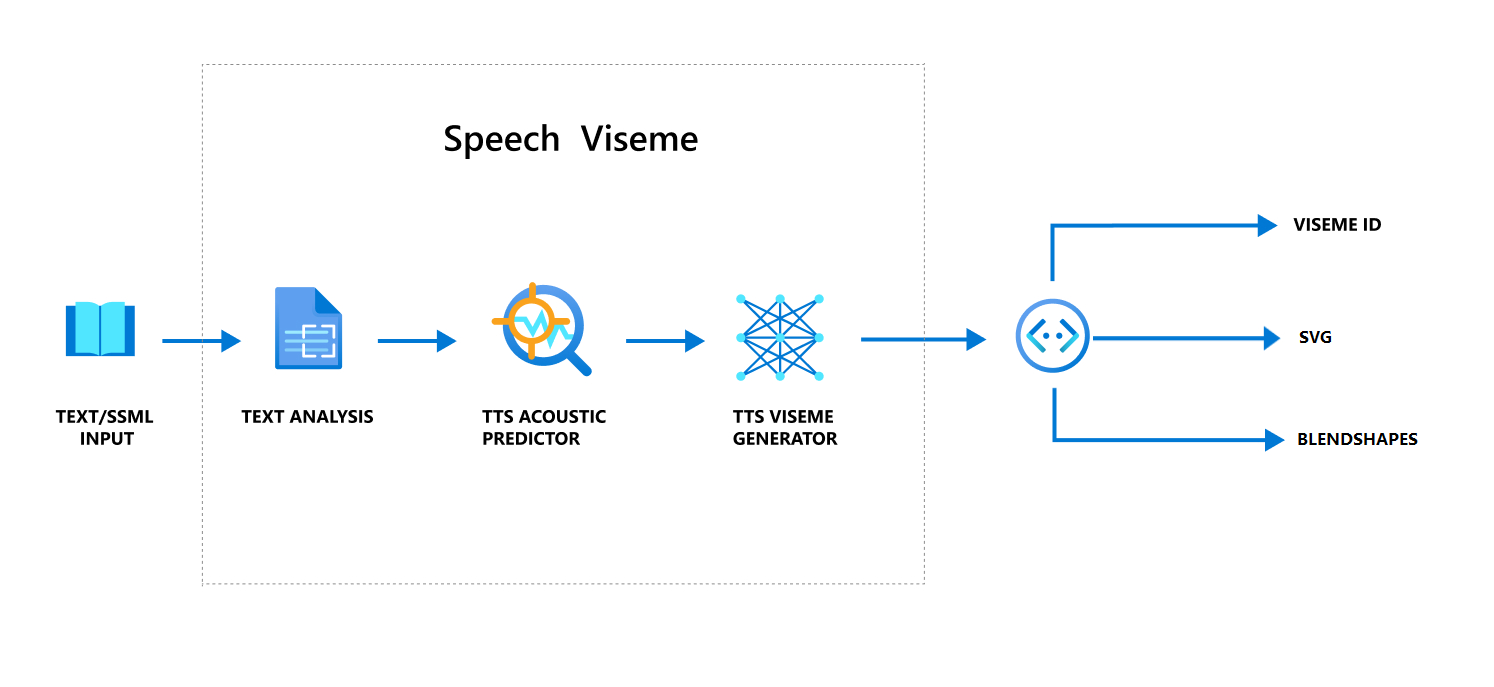
Viseme ID
ID Viseme odkazuje na celé číslo, které určuje viseme. Nabízíme 22 různých visemů, z nichž každá znázorňuje umístění úst pro určitou sadu foonech. Mezi visemy a fonemi neexistuje žádná korespondence 1:1. Často několik foonech odpovídá jednomu visemu, protože vypadaly stejně na tváři reproduktoru při jejich vytváření, například s a z. Konkrétnější informace najdete v tabulce pro mapování foonech na ID viseme.
Zvukový výstup řeči může být doprovázen id viseme a Audio offset. Označuje Audio offset časové razítko posunu, které představuje počáteční čas každého viseme v ticks (100 nanosekund).
Mapování fofonmů na viseme
Visemes se liší podle jazyka a národního prostředí. Každé národní prostředí má sadu visemí, které odpovídají jeho konkrétním fonemům. Dokumentace k fonetickým abecedám SSML mapuje ID viseme na odpovídající fonetické fonety mezinárodní Telefon tické abecedy (IPA). V tabulce v této části je znázorněna relace mapování mezi ID viseme a umístěními úst a uvádí typické fonely IPA pro každé ID viseme.
| Viseme ID | IPA | Pozice úst |
|---|---|---|
| 0 | Ticho |  |
| 0 | æ, , əʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | ɛ, ʊ |
 |
| 5 | ɝ |
 |
| 6 | j, , iɪ |
 |
| 7 | w, u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s, z |
 |
| 16 | ʃ, tʃ, , dʒʒ |
 |
| 17 | ð |
 |
| 18 | f, v |
 |
| 19 | d, t, , nθ |
 |
| 20 | k, , gŋ |
 |
| 21 | p, , bm |
 |
Animace 2D SVG
Pro 2D znaky můžete navrhnout znak, který vyhovuje vašemu scénáři, a použít svG (Scalable Vector Graphics) pro každé ID viseme k získání pozice časově založené na tváři.
Díky dočasným značkám, které jsou k dispozici v události viseme, se tyto dobře navržené soubory SVG zpracovávají s úpravami vyhlazování a poskytují robustní animaci uživatelům. Na následujícím obrázku je například červený lichý znak navržený pro výuku jazyků.

Animace 3D obrazců
Tvary prolnutí můžete použít k řízení pohybu obličeje 3D znaku, který jste navrhli.
Řetězec JSON prolnutí obrazců je reprezentován jako dvojrozměrná matice. Každý řádek představuje rámec. Každý rámec (v 60 FPS) obsahuje matici 55 obličejových pozic.
Získání událostí viseme pomocí sady Speech SDK
Pokud chcete získat viseme s syntetizovanou řečí, přihlaste se k odběru VisemeReceived události v sadě Speech SDK.
Poznámka:
Pokud chcete požádat o výstup SVG nebo prolnutí obrazců, měli byste použít mstts:viseme prvek v SSML. Podrobnosti najdete v tématu použití elementu viseme v SSML.
Následující fragment kódu ukazuje, jak se přihlásit k odběru události viseme:
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
Tady je příklad výstupu viseme.
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
Po získání výstupu viseme můžete pomocí těchto událostí řídit animaci znaků. Můžete vytvářet vlastní znaky a automaticky je animovat.