Použití služby Azure Data Factory k migraci dat z místního serveru Netezza do Azure
PLATÍ PRO: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Azure Data Factory poskytuje výkonný, robustní a nákladově efektivní mechanismus pro migraci dat ve velkém měřítku z místního serveru Netezza do účtu úložiště Azure nebo databáze Azure Synapse Analytics.
Tento článek obsahuje následující informace pro datové inženýry a vývojáře:
- Výkon
- Odolnost kopírování
- Zabezpečení sítě
- Architektura řešení vysoké úrovně
- Osvědčené postupy implementace
Výkon
Azure Data Factory nabízí bezserverovou architekturu, která umožňuje paralelismus na různých úrovních. Pokud jste vývojář, znamená to, že můžete vytvářet kanály, které plně využívají šířku pásma sítě i databáze k maximalizaci propustnosti přesunu dat pro vaše prostředí.
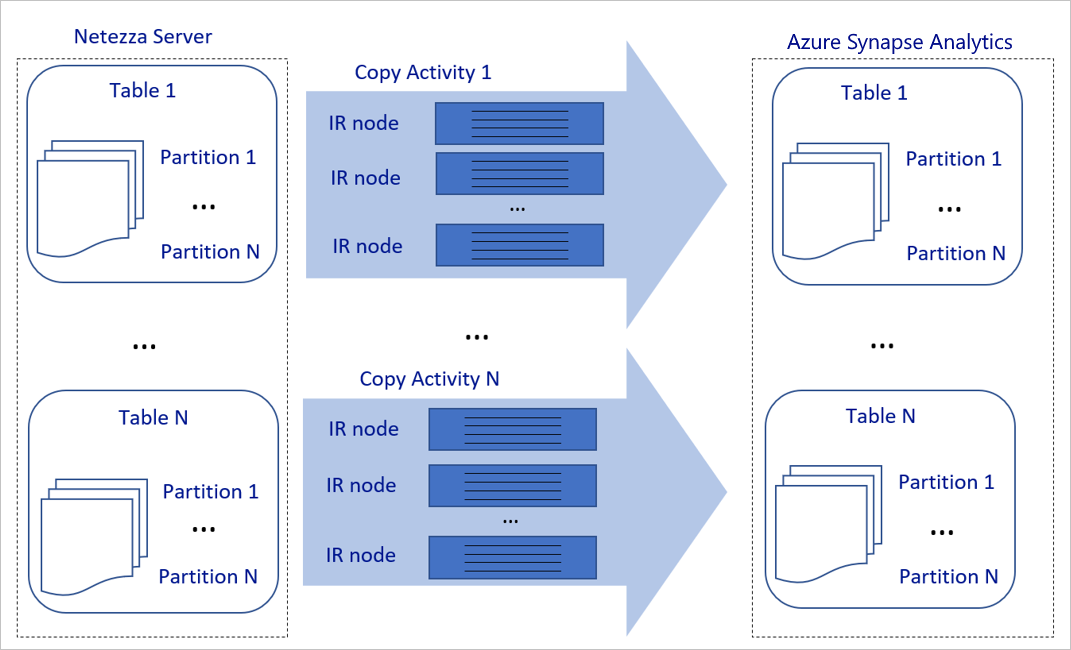
Předchozí diagram lze interpretovat takto:
Jedna aktivita kopírování může využívat škálovatelné výpočetní prostředky. Při použití prostředí Azure Integration Runtime můžete zadat až 256 JEDNOTEK PRO každou aktivitu kopírování bez serveru. S místním prostředím Integration Runtime (místní prostředí IR) můžete ručně vertikálně navýšit kapacitu počítače nebo vertikálně navýšit kapacitu na více počítačů (až na čtyři uzly) a jedna aktivita kopírování distribuuje její oddíl napříč všemi uzly.
Jedna aktivita kopírování čte z úložiště dat a zapisuje je do úložiště dat pomocí více vláken.
Tok řízení služby Azure Data Factory může paralelně spouštět více aktivit kopírování. Může je například spustit pomocí smyčky For Each.
Další informace najdete v aktivita Copy průvodci výkonem a škálovatelností.
Odolnost
Azure Data Factory má v rámci jednoho spuštění aktivity kopírování integrovaný mechanismus opakování, který umožňuje zpracovávat určitou úroveň přechodných selhání v úložištích dat nebo v podkladové síti.
Při aktivitě kopírování ve službě Azure Data Factory máte při kopírování dat mezi úložišti dat zdroje a jímky dva způsoby, jak zpracovat nekompatibilní řádky. Aktivitu kopírování můžete buď přerušit a selhat, nebo můžete pokračovat ve kopírování zbývajících dat přeskočením nekompatibilních řádků dat. Kromě toho, abyste se dozvěděli o příčině selhání, můžete protokolovat nekompatibilní řádky ve službě Azure Blob Storage nebo Azure Data Lake Store, opravit data ve zdroji dat a zkusit aktivitu kopírování zopakovat.
Zabezpečení sítě
Azure Data Factory ve výchozím nastavení přenáší data z místního serveru Netezza do účtu úložiště Azure nebo databáze Azure Synapse Analytics pomocí šifrovaného připojení přes protokol HTTPS (Hypertext Transfer Protocol Secure). HTTPS poskytuje šifrování přenášených dat a zabraňuje odposlouchávání a útokům typu man-in-the-middle.
Případně pokud nechcete, aby se data přenášela přes veřejný internet, můžete dosáhnout vyššího zabezpečení přenosem dat přes privátní partnerský vztah přes Azure Express Route.
V další části se dozvíte, jak dosáhnout vyššího zabezpečení.
Architektura řešení
Tato část popisuje dva způsoby migrace dat.
Migrace dat přes veřejný internet
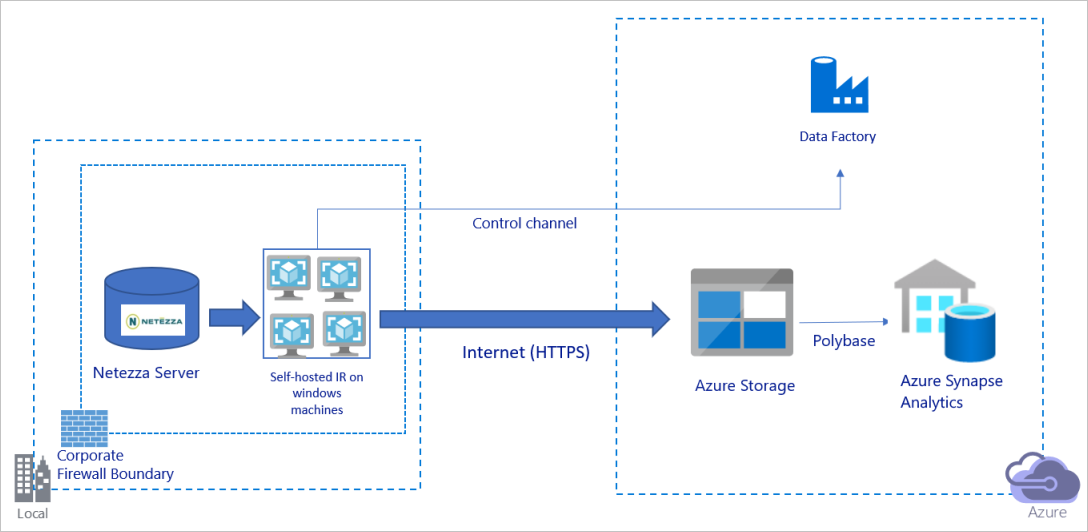
Předchozí diagram lze interpretovat takto:
V této architektuře bezpečně přenášíte data pomocí protokolu HTTPS přes veřejný internet.
K dosažení této architektury je potřeba nainstalovat prostředí Azure Data Factory Integration Runtime (v místním prostředí) na počítač s Windows za podnikovou bránou firewall. Ujistěte se, že tento prostředí Integration Runtime má přímý přístup k serveru Netezza. Pokud chcete plně používat síť a úložiště dat ke kopírování dat, můžete ručně vertikálně navýšit kapacitu počítače nebo vertikálně navýšit kapacitu na více počítačů.
Pomocí této architektury můžete migrovat počáteční data snímků i rozdílová data.
Migrace dat přes privátní síť
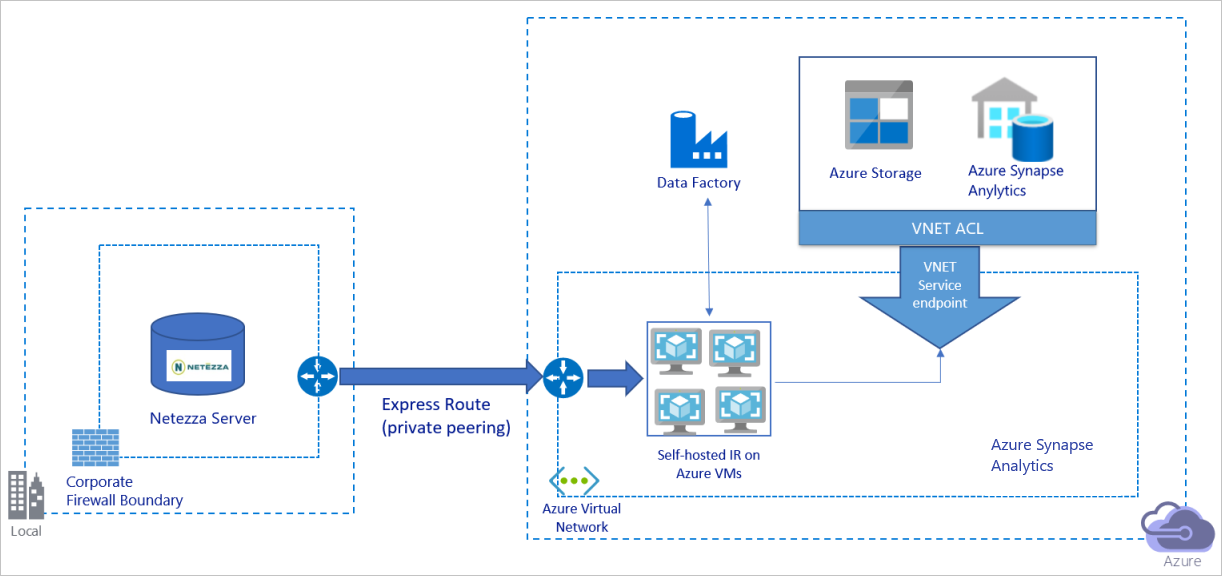
Předchozí diagram lze interpretovat takto:
V této architektuře migrujete data přes privátní partnerský vztah přes Azure Express Route a data nikdy neprocházejí přes veřejný internet.
K dosažení této architektury je potřeba nainstalovat prostředí Azure Data Factory Integration Runtime (v místním prostředí) na virtuální počítač s Windows ve vaší virtuální síti Azure. Pokud chcete plně používat síť a úložiště dat ke kopírování dat, můžete virtuální počítač škálovat ručně nebo škálovat na více virtuálních počítačů.
Pomocí této architektury můžete migrovat počáteční data snímků i rozdílová data.
Implementace osvědčených postupů
Správa ověřování a přihlašovacích údajů
K ověření ve službě Netezza můžete použít ověřování ODBC prostřednictvím připojovací řetězec.
Ověření ve službě Azure Blob Storage:
Důrazně doporučujeme používat spravované identity pro prostředky Azure. Spravované identity založené na automaticky spravované identitě Azure Data Factory v Microsoft Entra ID umožňují konfigurovat kanály bez nutnosti zadávat přihlašovací údaje v definici propojené služby.
Případně se můžete ověřit ve službě Azure Blob Storage pomocí instančního objektu, sdíleného přístupového podpisu nebo klíče účtu úložiště.
Ověření ve službě Azure Data Lake Storage Gen2:
Důrazně doporučujeme používat spravované identity pro prostředky Azure.
Můžete také použít instanční objekt nebo klíč účtu úložiště.
Ověření ve službě Azure Synapse Analytics:
Důrazně doporučujeme používat spravované identity pro prostředky Azure.
Můžete také použít instanční objekt nebo ověřování SQL.
Pokud nepoužíváte spravované identity pro prostředky Azure, důrazně doporučujeme ukládat přihlašovací údaje ve službě Azure Key Vault , aby bylo snazší centrálně spravovat a obměňovat klíče bez nutnosti upravovat propojené služby Azure Data Factory. Toto je také jeden z osvědčených postupů pro CI/CD.
Migrace počátečních dat snímků
U malých tabulek (to znamená tabulek s objemem menší než 100 GB nebo které je možné migrovat do Azure do dvou hodin), můžete pro každou úlohu kopírování načíst data na tabulku. Pokud chcete větší propustnost, můžete spustit několik úloh kopírování služby Azure Data Factory a načíst samostatné tabulky současně.
Pokud chcete v rámci každé úlohy kopírování spouštět paralelní dotazy a kopírovat data podle oddílů, můžete také dosáhnout určité úrovně paralelismu pomocí parallelCopies nastavení vlastnosti s některou z následujících možností oddílu dat:
Pokud chcete dosáhnout vyšší efektivity, doporučujeme začít z datového řezu. Ujistěte se, že hodnota v
parallelCopiesnastavení je menší než celkový počet oddílů řezu dat v tabulce na serveru Netezza.Pokud je objem každého oddílu datového řezu stále velký (například 10 GB nebo vyšší), doporučujeme přepnout na oddíl dynamického rozsahu. Tato možnost poskytuje větší flexibilitu při definování počtu oddílů a objemu každého oddílu podle sloupce oddílu, horní a dolní hranice.
U větších tabulek (tj. tabulek s objemem 100 GB nebo větší nebo které není možné migrovat do Azure do dvou hodin), doporučujeme data rozdělit podle vlastního dotazu a potom vytvořit každou kopii úlohy kopírování po jednotlivých oddílech. Kvůli lepší propustnosti můžete souběžně spouštět více úloh kopírování služby Azure Data Factory. Pro každý cíl úlohy kopírování načítání jednoho oddílu vlastním dotazem můžete zvýšit propustnost povolením paralelismu prostřednictvím datového řezu nebo dynamického rozsahu.
Pokud jakákoli úloha kopírování selže kvůli přechodnému problému se sítí nebo úložištěm dat, můžete znovu spustit neúspěšnou úlohu kopírování a znovu načíst konkrétní oddíl z tabulky. Jiné úlohy kopírování, které načítají jiné oddíly, nejsou ovlivněné.
Při načítání dat do databáze Azure Synapse Analytics doporučujeme povolit PolyBase v rámci úlohy kopírování s úložištěm objektů blob v Azure jako přípravné.
Migrace rozdílových dat
Pokud chcete identifikovat nové nebo aktualizované řádky z tabulky, použijte sloupec časového razítka nebo inkrementující klíč v rámci schématu. Nejnovější hodnotu pak můžete uložit jako horní mez v externí tabulce a pak ji použít k filtrování rozdílových dat při příštím načtení dat.
Každá tabulka může k identifikaci nových nebo aktualizovaných řádků použít jiný sloupec vodoznaku. Doporučujeme vytvořit tabulku externího ovládacího prvku. Každý řádek v tabulce představuje jednu tabulku na serveru Netezza s konkrétním názvem sloupce vodoznaku a vysokou hodnotou vodoznaku.
Konfigurace místního prostředí Integration Runtime
Pokud migrujete data ze serveru Netezza do Azure, ať už je server místní za bránou firewall vaší společnosti nebo v prostředí virtuální sítě, musíte na počítač nebo virtuální počítač s Windows nainstalovat místní prostředí IR, což je modul, který se používá k přesunu dat. Při instalaci místního prostředí IR doporučujeme následující přístup:
Pro každý počítač nebo virtuální počítač s Windows začněte konfigurací 32 vCPU a 128 GB paměti. Během migrace dat můžete dál monitorovat využití procesoru a paměti počítače IR, abyste zjistili, jestli potřebujete vertikálně navýšit kapacitu počítače, abyste dosáhli lepšího výkonu, nebo vertikálně snížit kapacitu počítače, abyste ušetřili náklady.
Horizontální navýšení kapacity můžete také rozšířit přidružením až čtyř uzlů k jednomu místnímu prostředí IR. Jedna úloha kopírování, která běží na místním prostředí IR, automaticky použije všechny uzly virtuálních počítačů ke kopírování dat paralelně. Pro zajištění vysoké dostupnosti začněte čtyřmi uzly virtuálních počítačů, abyste se vyhnuli jedinému bodu selhání během migrace dat.
Omezení oddílů
Osvědčeným postupem je testování výkonu konceptu (POC) se reprezentativní ukázkovou datovou sadou, abyste mohli určit odpovídající velikost oddílu pro každou aktivitu kopírování. Doporučujeme načíst každý oddíl do Azure do dvou hodin.
Pokud chcete zkopírovat tabulku, začněte jednou aktivitou kopírování s jedním místním počítačem IR. Postupně zvětšete parallelCopies nastavení na základě počtu oddílů řezu dat v tabulce. Podívejte se, jestli se celá tabulka může načíst do Azure během dvou hodin podle propustnosti, která je výsledkem úlohy kopírování.
Pokud se nedá načíst do Azure do dvou hodin a kapacita uzlu místního prostředí IR a úložiště dat se plně nepoužívá, postupně zvyšte počet souběžných aktivit kopírování, dokud nedosáhnete limitu sítě nebo limitu šířky pásma úložišť dat.
Sledujte využití procesoru a paměti na místním počítači IR a buďte připraveni vertikálně navýšit kapacitu počítače nebo vertikálně navýšit kapacitu na více počítačů, až zjistíte, že se procesor a paměť plně používají.
Pokud narazíte na chyby omezování, jak je hlášeno aktivitou kopírování ve službě Azure Data Factory, snižte souběžnost nebo parallelCopies nastavení ve službě Azure Data Factory nebo zvažte zvýšení šířky pásma nebo vstupně-výstupních operací za sekundu (IOPS) sítě a úložišť dat.
Odhad cen
Představte si následující kanál, který je vytvořený tak, aby migroval data z místního serveru Netezza do databáze Azure Synapse Analytics:
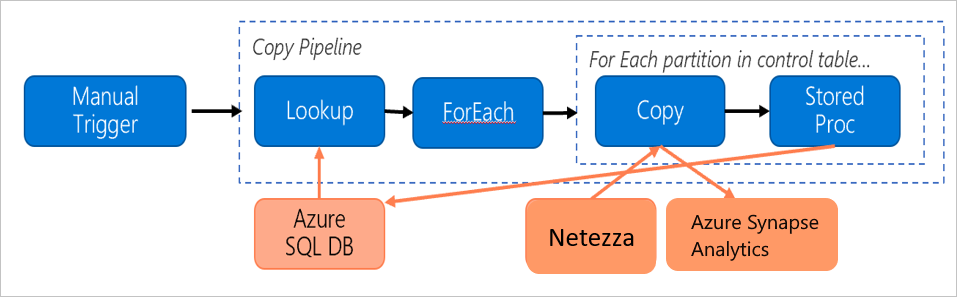
Předpokládejme, že platí následující příkazy:
Celkový objem dat je 50 terabajtů (TB).
Migrujeme data pomocí architektury prvního řešení (server Netezza je místní za bránou firewall).
Svazek o 50 TB je rozdělený na 500 oddílů a každá aktivita kopírování přesune jeden oddíl.
Každá aktivita kopírování je nakonfigurovaná s jedním místním prostředím IR na čtyřech počítačích a dosahuje propustnosti 20 megabajtů za sekundu (MB/s). (V rámci aktivity
parallelCopieskopírování je nastavená hodnota 4 a každé vlákno pro načtení dat z tabulky dosáhne propustnosti 5 MB/s.)Souběžnost ForEach je nastavená na 3 a agregovaná propustnost je 60 MB/s.
Dokončení migrace trvá celkem 243 hodin.
Na základě předchozích předpokladů je zde odhadovaná cena:
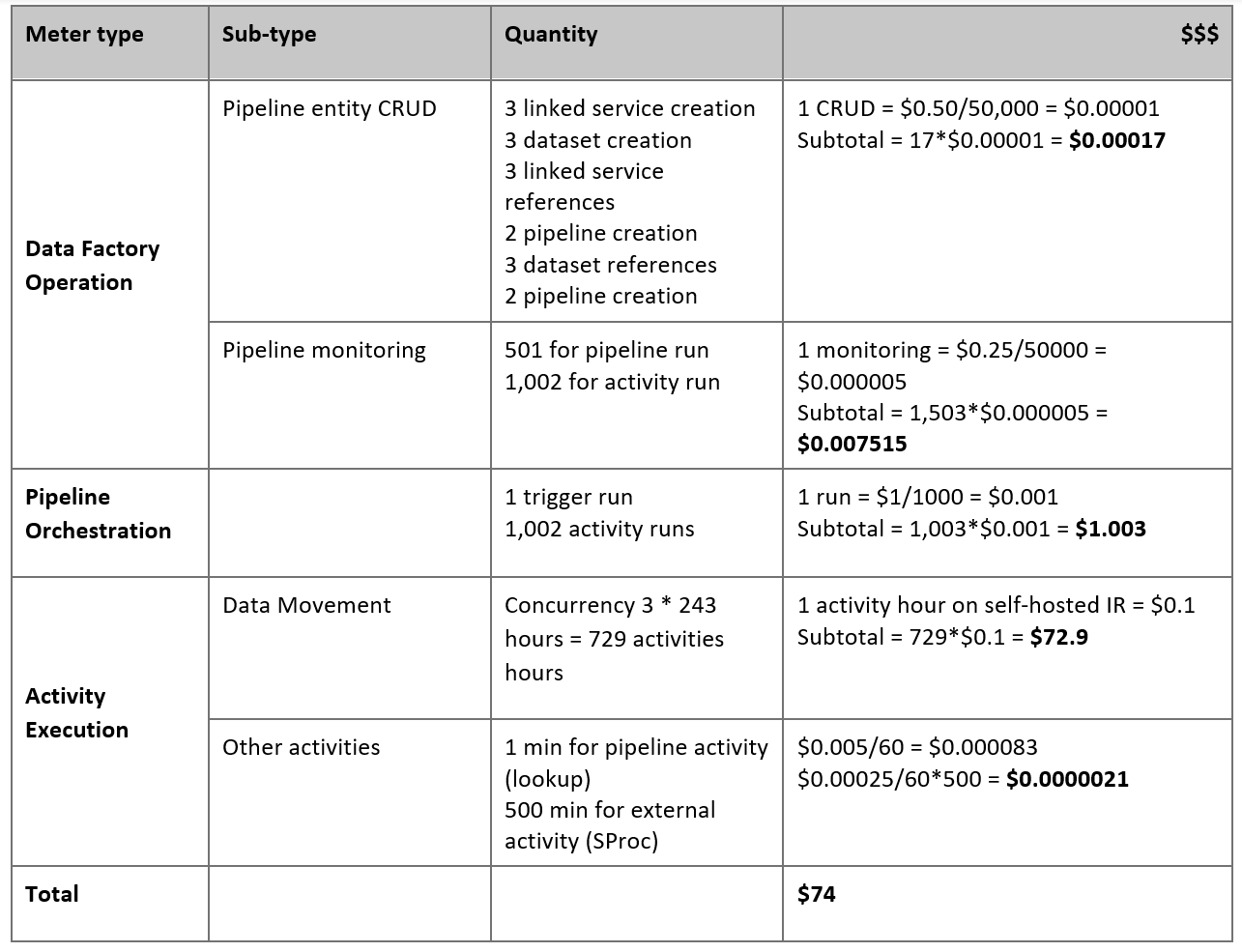
Poznámka:
Ceny zobrazené v předchozí tabulce jsou hypotetické. Vaše skutečné ceny závisí na skutečné propustnosti ve vašem prostředí. Cena počítače s Windows (s nainstalovaným místním prostředím IR) není zahrnutá.
Další odkazy
Další informace najdete v následujících článcích a příručkách:
- Konektor Netezza
- Konektor ODBC
- Konektor služby Azure Blob Storage
- Konektor Azure Data Lake Storage Gen2
- Konektor Azure Synapse Analytics
- průvodce laděním výkonu aktivita Copy
- Vytvoření a konfigurace místního prostředí Integration Runtime
- Vysoká dostupnost a škálovatelnost místního prostředí Integration Runtime
- Aspekty zabezpečení přesunu dat
- Ukládání přihlašovacích údajů ve službě Azure Key Vault
- Přírůstkové kopírování dat z jedné tabulky
- Přírůstkové kopírování dat z více tabulek
- Stránka s cenami služby Azure Data Factory