Trénování modelů TensorFlow ve velkém měřítku pomocí služby Azure Machine Učení
PLATÍ PRO:  Python SDK azure-ai-ml v2 (aktuální)
Python SDK azure-ai-ml v2 (aktuální)
V tomto článku se dozvíte, jak spustit trénovací skripty TensorFlow ve velkém měřítku pomocí sady Azure Machine Učení Python SDK v2.
Ukázkový kód v tomto článku vytrénuje model TensorFlow ke klasifikaci ručně psaných číslic pomocí hluboké neurální sítě (DNN); registrace modelu; a nasaďte ho do online koncového bodu.
Bez ohledu na to, jestli vyvíjíte model TensorFlow od základů, nebo přenesete existující model do cloudu, můžete použít Azure Machine Učení k horizontálnímu navýšení kapacity opensourcových trénovacích úloh pomocí elastických cloudových výpočetních prostředků. Pomocí služby Azure Machine Učení můžete vytvářet, nasazovat, nasazovat, verze a monitorovat modely na produkční úrovni.
Požadavky
Pokud chcete využít výhod tohoto článku, musíte:
- Přístup k předplatnému Azure Pokud ho ještě nemáte, vytvořte si bezplatný účet.
- Spusťte kód v tomto článku pomocí výpočetní instance azure machine Učení nebo vlastního poznámkového bloku Jupyter.
- Výpočetní instance azure Učení – není potřeba stahovat ani instalovat
- Dokončete kurz Vytvoření prostředků a začněte vytvářet vyhrazený server poznámkových bloků předem načtený pomocí sady SDK a ukázkového úložiště.
- Ve složce hloubkového učení na serveru poznámkového bloku najděte dokončený a rozbalený poznámkový blok tak, že přejdete do tohoto adresáře: úlohy Pythonu > v2 > sdk s >> jedním krokem > tensorflow > train-hyperparameter-tune-deploy-with-tensorflow.
- Server poznámkového bloku Jupyter
- Výpočetní instance azure Učení – není potřeba stahovat ani instalovat
- Stáhněte si následující soubory:
- tf_mnist.py trénovacího skriptu
- bodovací skript score.py
- ukázkový soubor požadavku sample-request.json
Dokončenou verzi poznámkového bloku Jupyter najdete také na stránce ukázek GitHubu.
Než budete moct spustit kód v tomto článku a vytvořit cluster GPU, budete muset požádat o navýšení kvóty pro váš pracovní prostor.
Nastavení úlohy
Tato část nastaví úlohu pro trénování načtením požadovaných balíčků Pythonu, připojením k pracovnímu prostoru, vytvořením výpočetního prostředku pro spuštění úlohy příkazu a vytvořením prostředí pro spuštění úlohy.
Připojení do pracovního prostoru
Nejprve se musíte připojit ke svému pracovnímu prostoru Azure Machine Učení. Pracovní prostor Učení Azure je prostředek nejvyšší úrovně služby. Poskytuje centralizované místo pro práci se všemi artefakty, které vytvoříte při použití služby Azure Machine Učení.
Používáme DefaultAzureCredential k získání přístupu k pracovnímu prostoru. Tyto přihlašovací údaje by měly být schopné zpracovávat většinu scénářů ověřování sady Azure SDK.
Pokud DefaultAzureCredential vám nefunguje, podívejte se nebo Set up authentication vyhledejte azure-identity reference documentation další dostupné přihlašovací údaje.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Pokud chcete k přihlášení a ověření použít prohlížeč, měli byste zrušit komentář k následujícímu kódu a místo toho ho použít.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Dále získejte popisovač pracovního prostoru zadáním ID předplatného, názvu skupiny prostředků a názvu pracovního prostoru. Vyhledání těchto parametrů:
- V pravém horním rohu panelu nástrojů studio Azure Machine Learning vyhledejte název pracovního prostoru.
- Vyberte název pracovního prostoru, aby se zobrazila vaše skupina prostředků a ID předplatného.
- Zkopírujte hodnoty pro skupinu prostředků a ID předplatného do kódu.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)Výsledkem spuštění tohoto skriptu je popisovač pracovního prostoru, který používáte ke správě jiných prostředků a úloh.
Poznámka:
- Při vytváření
MLClientse klient nepřipojí k pracovnímu prostoru. Inicializace klienta je opožděná a při prvním volání bude čekat. V tomto článku k tomu dojde během vytváření výpočetních prostředků.
Vytvoření výpočetního prostředku
Azure Machine Učení potřebuje výpočetní prostředek ke spuštění úlohy. Tento prostředek může být počítač s jedním nebo více uzly s operačním systémem Linux nebo Windows nebo konkrétní výpočetní prostředky infrastruktury, jako je Spark.
V následujícím ukázkovém skriptu zřídíme Linux compute cluster. Azure Machine Learning pricing Zobrazí se stránka s úplným seznamem velikostí a cen virtuálních počítačů. Vzhledem k tomu, že v tomto příkladu potřebujeme cluster GPU, vybereme model STANDARD_NC6 a vytvoříme výpočetní Učení azure machine.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)Vytvoření prostředí úlohy
Ke spuštění úlohy Učení počítače Azure potřebujete prostředí. Prostředí Azure Machine Učení zapouzdřuje závislosti (například modul runtime softwaru a knihovny) potřebné ke spuštění trénovacího skriptu strojového učení na výpočetním prostředku. Toto prostředí se podobá prostředí Pythonu na místním počítači.
Azure Machine Učení umožňuje používat kurátorované (nebo připravené) prostředí, které je užitečné pro běžné scénáře trénování a odvozování, nebo vytvořit vlastní prostředí pomocí image Dockeru nebo konfigurace Conda.
V tomto článku znovu použijete kurátorované prostředí AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpuAzure Machine Učení . Pomocí direktivy @latest použijete nejnovější verzi tohoto prostředí.
curated_env_name = "AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu@latest"Konfigurace a odeslání trénovací úlohy
V této části začneme představením dat pro trénování. Pak probereme, jak spustit trénovací úlohu pomocí trénovacího skriptu, který jsme zadali. Naučíte se sestavit trénovací úlohu konfigurací příkazu pro spuštění trénovacího skriptu. Pak odešlete úlohu trénování, která se spustí na počítači Azure Machine Učení.
Získání trénovacích dat
Použijete data z databáze MNIST (Modified National Institute of Standards and Technology) ručně psaných číslic. Tato data pocházejí z webu Yan LeCun a jsou uložená v účtu úložiště Azure.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Další informace o datové sadě MNIST naleznete na webu Yan LeCun.
Příprava trénovacího skriptu
V tomto článku jsme poskytli trénovací skript tf_mnist.py. V praxi byste měli být schopni vzít libovolný vlastní trénovací skript tak, jak je, a spouštět ho pomocí služby Azure Machine Učení, aniž byste museli upravovat kód.
Zadaný trénovací skript provede následující akce:
- zpracovává předběžné zpracování dat a rozděluje data na testovací a trénovací data;
- trénuje model pomocí dat; A
- vrátí výstupní model.
Během spuštění kanálu použijete MLFlow k protokolování parametrů a metrik. Informace o povolení sledování MLFlow najdete v tématu Sledování experimentů a modelů ML pomocí MLflow.
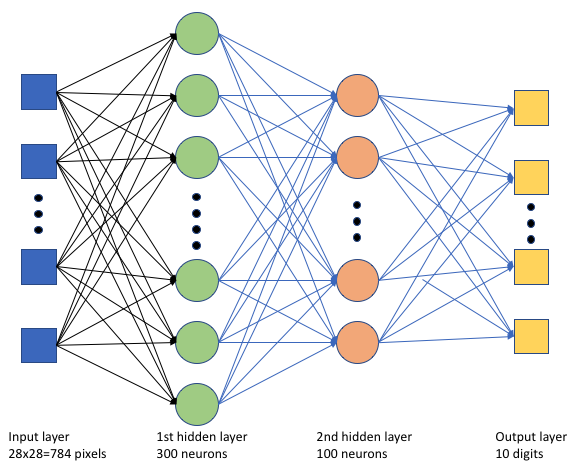
V trénovacím skriptu tf_mnist.pyvytvoříme jednoduchou hlubokou neurální síť (DNN). Tato síť DNN má:
- Vstupní vrstva s 28 * 28 = 784 neurony. Každý neuron představuje obrazový pixel.
- Dvě skryté vrstvy. První skrytá vrstva má 300 neuronů a druhá skrytá vrstva má 100 neuronů.
- Výstupní vrstva s 10 neurony. Každý neuron představuje cílový popisek od 0 do 9.
Sestavení trénovací úlohy
Teď, když máte všechny prostředky potřebné ke spuštění úlohy, je čas ho sestavit pomocí sady Azure Machine Učení Python SDK v2. V tomto příkladu vytváříme .command
Azure Machine Učení command je prostředek, který určuje všechny podrobnosti potřebné ke spuštění trénovacího kódu v cloudu. Mezi tyto podrobnosti patří vstupy a výstupy, typ hardwaru, který se má použít, software k instalaci a způsob spuštění kódu. Obsahuje command informace pro spuštění jednoho příkazu.
Konfigurace příkazu
Ke spuštění trénovacího skriptu a provádění požadovaných úloh použijete obecný účel command . Vytvořte Command objekt pro zadání podrobností konfigurace vaší trénovací úlohy.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=64,
first_layer_neurons=256,
second_layer_neurons=128,
learning_rate=0.01,
),
compute=gpu_compute_target,
environment=curated_env_name,
code="./src/",
command="python tf_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="tf-dnn-image-classify",
display_name="tensorflow-classify-mnist-digit-images-with-dnn",
)Vstupy pro tento příkaz zahrnují umístění dat, velikost dávky, počet neuronů v první a druhé vrstvě a rychlost učení. Všimněte si, že jsme webovou cestu předali přímo jako vstup.
Pro hodnoty parametrů:
- zadejte výpočetní cluster
gpu_compute_target = "gpu-cluster", který jste vytvořili pro spuštění tohoto příkazu; - poskytovat kurátorované prostředí
curated_env_name, které jste deklarovali dříve; - nakonfigurujte samotnou akci příkazového řádku – v tomto případě příkaz je
python tf_mnist.py. Ke vstupům a výstupům v příkazu můžete přistupovat prostřednictvím zápisu${{ ... }}a - konfigurovat metadata, jako je zobrazovaný název a název experimentu; kde experiment je kontejner pro všechny iterace, které provádí v určitém projektu. Všechny úlohy odeslané pod stejným názvem experimentu se zobrazí vedle sebe v studio Azure Machine Learning.
- zadejte výpočetní cluster
V tomto příkladu
UserIdentitypoužijete ke spuštění příkazu příkaz. Použití identity uživatele znamená, že příkaz použije vaši identitu ke spuštění úlohy a přístupu k datům z objektu blob.
Odeslání úlohy
Teď je čas odeslat úlohu, která se má spustit ve službě Azure Machine Učení. Tentokrát použijete create_or_update .ml_client.jobs
ml_client.jobs.create_or_update(job)Po dokončení úloha zaregistruje v pracovním prostoru model (v důsledku trénování) a vypíše odkaz pro zobrazení úlohy v studio Azure Machine Learning.
Upozorňující
Azure Machine Učení spouští trénovací skripty zkopírováním celého zdrojového adresáře. Pokud máte citlivá data, která nechcete nahrát, použijte soubor .ignore nebo je nezahrňte do zdrojového adresáře.
Co se stane během provádění úlohy
Při spuštění úlohy prochází následujícími fázemi:
Příprava: Image Dockeru se vytvoří podle definovaného prostředí. Image se nahraje do registru kontejneru pracovního prostoru a pro pozdější spuštění se ukládá do mezipaměti. Protokoly se také streamují do historie úloh a dají se zobrazit za účelem monitorování průběhu. Pokud je zadané kurátorované prostředí, použije se image uložená v mezipaměti, která toto kurátorované prostředí zálohuje.
Škálování: Cluster se pokusí vertikálně navýšit kapacitu, pokud ke spuštění vyžaduje více uzlů, než je aktuálně k dispozici.
Spuštěno: Všechny skripty ve složce skriptu src se nahrají do cílového výpočetního objektu, úložiště dat se připojí nebo zkopírují a skript se spustí. Výstupy ze stdoutu a složky ./logs se streamují do historie úloh a dají se použít k monitorování úlohy.
Ladění hyperparametrů modelu
Teď, když jste viděli, jak spustit trénování TensorFlow pomocí sady SDK, pojďme se podívat, jestli můžete ještě více zlepšit přesnost modelu. Hyperparametry modelu můžete vyladit a optimalizovat pomocí funkcí služby Azure Machine Učenísweep.
Pokud chcete vyladit hyperparametry modelu, definujte prostor parametrů, ve kterém se má během trénování hledat. Provedete to tak, že nahradíte některé parametry (batch_size, first_layer_neurons, second_layer_neuronsa learning_rate) předané trénovací úloze speciálními vstupy z azure.ml.sweep balíčku.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[32, 64, 128]),
first_layer_neurons=Choice(values=[16, 64, 128, 256, 512]),
second_layer_neurons=Choice(values=[16, 64, 256, 512]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Pak nakonfigurujete uklidit u úlohy příkazu pomocí některých parametrů specifických pro úklid, jako je primární metrika pro sledování a algoritmu vzorkování, který se má použít.
V následujícím kódu použijeme náhodné vzorkování k vyzkoušení různých konfiguračních sad hyperparametrů při pokusu o maximalizaci naší primární metriky validation_acc.
Definujeme také zásady předčasného ukončení , tj BanditPolicy. Tato zásada funguje kontrolou úlohy každé dvě iterace. Pokud primární metrika validation_accspadá mimo 10% rozsah, Azure Machine Učení ukončí úlohu. Tím se model ušetří od pokračování v prozkoumání hyperparametrů, které nemají žádný slib, že by pomohly dosáhnout cílové metriky.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="validation_acc",
goal="Maximize",
max_total_trials=8,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)Teď můžete tuto úlohu odeslat jako předtím. Tentokrát spustíte úlohu uklidení, která přemístit vaši úlohu trénu.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)Úlohu můžete monitorovat pomocí odkazu uživatelského rozhraní studia, který se zobrazí během spuštění úlohy.
Vyhledání a registrace nejlepšího modelu
Po dokončení všech spuštění můžete najít běh, který vytvořil model s nejvyšší přesností.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "model"
path="azureml://jobs/{}/outputs/artifacts/paths/outputs/model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="custom_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)Tento model pak můžete zaregistrovat.
registered_model = ml_client.models.create_or_update(model=model)Nasazení modelu jako online koncového bodu
Po registraci modelu ho můžete nasadit jako online koncový bod – to znamená jako webová služba v cloudu Azure.
K nasazení služby Machine Learning obvykle potřebujete:
- Prostředky modelu, které chcete nasadit. Mezi tyto prostředky patří soubor a metadata modelu, které jste už zaregistrovali ve své trénovací úloze.
- Nějaký kód, který se má spustit jako služba. Kód spustí model na daném vstupním požadavku (vstupním skriptu). Tento vstupní skript obdrží data odeslaná do nasazené webové služby a předá je do modelu. Jakmile model zpracuje data, skript vrátí klientovi odpověď modelu. Skript je specifický pro váš model a musí rozumět datům, která model očekává a vrací. Když použijete model MLFlow, Azure Machine Učení automaticky vytvoří tento skript za vás.
Další informace o nasazení najdete v tématu Nasazení a určení skóre modelu strojového učení pomocí spravovaného online koncového bodu pomocí sady Python SDK v2.
Vytvoření nového online koncového bodu
Jako první krok k nasazení modelu potřebujete vytvořit online koncový bod. Název koncového bodu musí být jedinečný v celé oblasti Azure. V tomto článku vytvoříte jedinečný název pomocí univerzálního jedinečného identifikátoru (UUID).
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "tff-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using TensorFlow",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")Po vytvoření koncového bodu ho můžete načíst následujícím způsobem:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)Nasazení modelu do koncového bodu
Po vytvoření koncového bodu můžete model nasadit pomocí vstupního skriptu. Koncový bod může mít více nasazení. Pomocí pravidel pak koncový bod může směrovat provoz do těchto nasazení.
V následujícím kódu vytvoříte jedno nasazení, které zpracovává 100 % příchozího provozu. Pro nasazení používáme libovolný název barvy (tff-blue). Pro nasazení můžete také použít jakýkoli jiný název, například tff-green nebo tff-red . Kód pro nasazení modelu do koncového bodu provede následující:
- nasadí nejlepší verzi modelu, který jste zaregistrovali dříve;
- vyhodnocí model pomocí
score.pysouboru; a - používá k odvozování stejné kurátorované prostředí (které jste deklarovali dříve).
model = registered_model
from azure.ai.ml.entities import CodeConfiguration
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="tff-blue",
endpoint_name=online_endpoint_name,
model=model,
code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
environment=curated_env_name,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Poznámka:
Očekáváme, že dokončení tohoto nasazení bude chvíli trvat.
Testování nasazení pomocí ukázkového dotazu
Po nasazení modelu do koncového bodu můžete pomocí metody na koncovém bodu předpovědět výstup nasazeného modelu invoke . Chcete-li spustit odvozování, použijte ukázkový soubor sample-request.json požadavku ze složky požadavku .
# # predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request/sample-request.json",
deployment_name="tff-blue",
)Pak můžete vytisknout vrácené předpovědi a vykreslit je spolu se vstupními obrázky. K zvýraznění chybně klasifikovaných ukázek použijte červenou barvu písma a invertovaný obrázek (bílý černobílý).
# compare actual value vs. the predicted values:
import matplotlib.pyplot as plt
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Poznámka:
Vzhledem k tomu, že je přesnost modelu vysoká, je možné, že před zobrazením chybně klasifikované ukázky budete muset buňku spustit několikrát.
Vyčištění prostředků
Pokud koncový bod nebudete používat, odstraňte ho, abyste prostředek přestali používat. Před odstraněním koncového bodu se ujistěte, že žádná další nasazení nepoužívají.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Poznámka:
Očekáváme, že dokončení tohoto vyčištění nějakou dobu trvá.
Další kroky
V tomto článku jste natrénovali a zaregistrovali model TensorFlow. Model jste také nasadili do online koncového bodu. Další informace o službě Azure Machine Učení najdete v těchto dalších článcích.