Nastavení trénování AutoML bez kódu pro tabulková data pomocí uživatelského rozhraní studia
V tomto článku se dozvíte, jak nastavit trénovací úlohy AutoML bez jediného řádku kódu pomocí služby Azure Machine Učení automatizovaného strojového učení v studio Azure Machine Learning.
Automatizované strojové učení, AutoML, je proces, ve kterém je vybraný nejlepší algoritmus strojového učení pro konkrétní data. Tento proces umožňuje rychle generovat modely strojového učení. Přečtěte si další informace o tom, jak Azure Machine Učení implementuje automatizované strojové učení.
Pro kompletní příklad vyzkoušejte kurz: AutoML – trénování modelů klasifikace bez kódu.
Pro prostředí založené na kódu Pythonu nakonfigurujte experimenty automatizovaného strojového učení pomocí sady Azure Machine Učení SDK.
Požadavky
Předplatné Azure. Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet. Vyzkoušejte si bezplatnou nebo placenou verzi služby Azure Machine Učení ještě dnes.
Pracovní prostor služby Azure Machine Learning. Viz Vytvoření prostředků pracovního prostoru.
Začínáme
Přihlaste se k studio Azure Machine Learning.
Vyberte své předplatné a pracovní prostor.
Přejděte do levého podokna. V části Vytváření obsahu vyberte automatizované strojové učení.

Pokud experimenty provádíte poprvé, zobrazí se prázdný seznam a odkazy na dokumentaci.
V opačném případě se zobrazí seznam posledních experimentů automatizovaného strojového učení, včetně experimentů vytvořených pomocí sady SDK.
Vytvoření a spuštění experimentu
Vyberte + Nová automatizovaná úloha ML a vyplňte formulář.
Vyberte datový prostředek z kontejneru úložiště nebo vytvořte nový datový prostředek. Datový prostředek je možné vytvořit z místních souborů, webových adres URL, úložišť dat nebo otevřených datových sad Azure. Přečtěte si další informace o vytváření datových assetů.
Důležité
Požadavky na trénovací data:
- Data musí být v tabulkové podobě.
- Hodnota, kterou chcete predikovat (cílový sloupec), musí být v datech.
Pokud chcete vytvořit novou datovou sadu ze souboru v místním počítači, vyberte +Vytvořit datovou sadu a pak vyberte Z místního souboru.
Výběrem možnosti Další otevřete formulář úložiště dat a výběru souboru. , vyberete, kam se má datová sada nahrát; výchozí kontejner úložiště, který se automaticky vytvoří s vaším pracovním prostorem, nebo zvolte kontejner úložiště, který chcete pro experiment použít.
- Pokud jsou vaše data za virtuální sítí, musíte funkci přeskočit , abyste měli jistotu, že má pracovní prostor přístup k vašim datům. Další informace najdete v tématu Použití studio Azure Machine Learning ve virtuální síti Azure.
Výběrem možnosti Procházet nahrajete datový soubor pro datovou sadu.
Zkontrolujte přesnost formuláře Nastavení a náhledu. Formulář je inteligentně vyplněný na základě typu souboru.
Pole Popis File format Definuje rozložení a typ dat uložených v souboru. Delimiter Jeden nebo více znaků pro určení hranice mezi samostatnými, nezávislými oblastmi v prostém textu nebo jinými datovými proudy. Kódování Určuje, jaký bit tabulky schématu znaků se má použít ke čtení datové sady. Záhlaví sloupců Určuje, jak se budou zacházet s hlavičkami datové sady( pokud existuje). Přeskočit řádky Určuje, kolik řádků se v datové sadě přeskočí( pokud existuje). Vyberte Další.
Formulář Schéma je inteligentně vyplněný na základě výběrů ve formuláři Nastavení a náhledu. Tady nakonfigurujte datový typ pro každý sloupec, zkontrolujte názvy sloupců a vyberte sloupce, které se mají do experimentu zahrnout .
Vyberte Další.
Formulář Potvrdit podrobnosti je souhrn informací, které byly dříve vyplněny v základních informacích a Nastavení a náhledu formulářů. Máte také možnost vytvořit pro datovou sadu profilaci s využitím výpočetních prostředků s povolenou profilací.
Vyberte Další.
Jakmile se zobrazí nově vytvořená datová sada, vyberte ji. Můžete si také prohlédnout náhled datové sady a ukázkové statistiky.
Ve formuláři Konfigurovat úlohu vyberte Vytvořit nový a jako název experimentu zadejte Tutorial-automl-deploy .
Vyberte cílový sloupec; toto je sloupec, u kterého chcete provádět predikce.
Vyberte výpočetní typ pro profilaci dat a trénovací úlohu. Můžete vybrat výpočetní cluster nebo výpočetní instanci.
V rozevíracím seznamu existujících výpočetních prostředků vyberte výpočetní prostředky. Pokud chcete vytvořit nový výpočetní objekt, postupujte podle pokynů v kroku 8.
Vyberte Vytvořit nový výpočetní objekt , abyste pro tento experiment nakonfigurovali výpočetní kontext.
Pole Popis Název výpočetních prostředků Zadejte jedinečný název, který identifikuje váš výpočetní kontext. Priorita virtuálního počítače Virtuální počítače s nízkou prioritou jsou levnější, ale nezaručují výpočetní uzly. Typ virtuálního počítače Jako typ virtuálního počítače vyberte procesor nebo GPU. Velikost virtuálního počítače Vyberte velikost virtuálního počítače pro výpočetní prostředky. Minimální a maximální počet uzlů Pokud chcete profilovat data, musíte zadat jeden nebo více uzlů. Zadejte maximální počet uzlů výpočetních prostředků. Výchozí hodnota je šest uzlů pro službu Azure Machine Učení Compute. Rozšířené nastavení Tato nastavení umožňují nakonfigurovat uživatelský účet a existující virtuální síť pro experiment. Vyberte Vytvořit. Vytvoření nového výpočetního objektu může trvat několik minut.
Vyberte Další.
Ve formuláři Typ a nastavení úlohy vyberte typ úkolu: klasifikace, regrese nebo prognózování. Další informace najdete v podporovaných typech úloh.
Pro klasifikaci můžete také povolit hluboké učení.
Pro prognózování můžete:
Povolte hluboké učení.
Vybrat sloupec času: Tento sloupec obsahuje časová data, která se mají použít.
Vyberte horizont prognózy: Určuje, kolik časových jednotek (minuty, hodiny, dny, týdny, měsíce nebo roky) bude model schopen předpovědět do budoucnosti. Čím dál do budoucna je model nutný k predikci, tím méně přesný model se stane. Přečtěte si další informace o prognózování a horizontu prognóz.
(Volitelné) Zobrazení nastavení konfigurace přidání: Další nastavení, která můžete použít k lepšímu řízení trénovací úlohy. V opačném případě se výchozí hodnoty použijí na základě výběru experimentu a dat.
Další konfigurace Popis Primární metrika Hlavní metrika použitá pro bodování modelu Přečtěte si další informace o metrikách modelu. Povolení stackingu souborů Souborové učení zlepšuje výsledky strojového učení a prediktivní výkon kombinováním více modelů na rozdíl od použití jednotlivých modelů. Přečtěte si další informace o souborových modelech. Blokované modely Vyberte modely, které chcete vyloučit z trénovací úlohy.
Povolení modelů je k dispozici pouze pro experimenty sady SDK.
Podívejte se na podporované algoritmy pro každý typ úlohy.Vysvětlit nejlepší model Automaticky zobrazuje vysvětlitelnost nejlepšího modelu vytvořeného automatizovaným strojovém učení. Popisek kladné třídy Popisek, který bude automatizované strojové učení používat k výpočtu binárních metrik. (Volitelné) Zobrazit nastavení featurizace: Pokud se rozhodnete povolit automatickou featurizaci ve formuláři Další nastavení konfigurace, použijí se výchozí techniky featurizace. V nastavení funkce Zobrazit funkciaturizace můžete tyto výchozí hodnoty změnit a odpovídajícím způsobem přizpůsobit. Zjistěte, jak přizpůsobit featurizace.
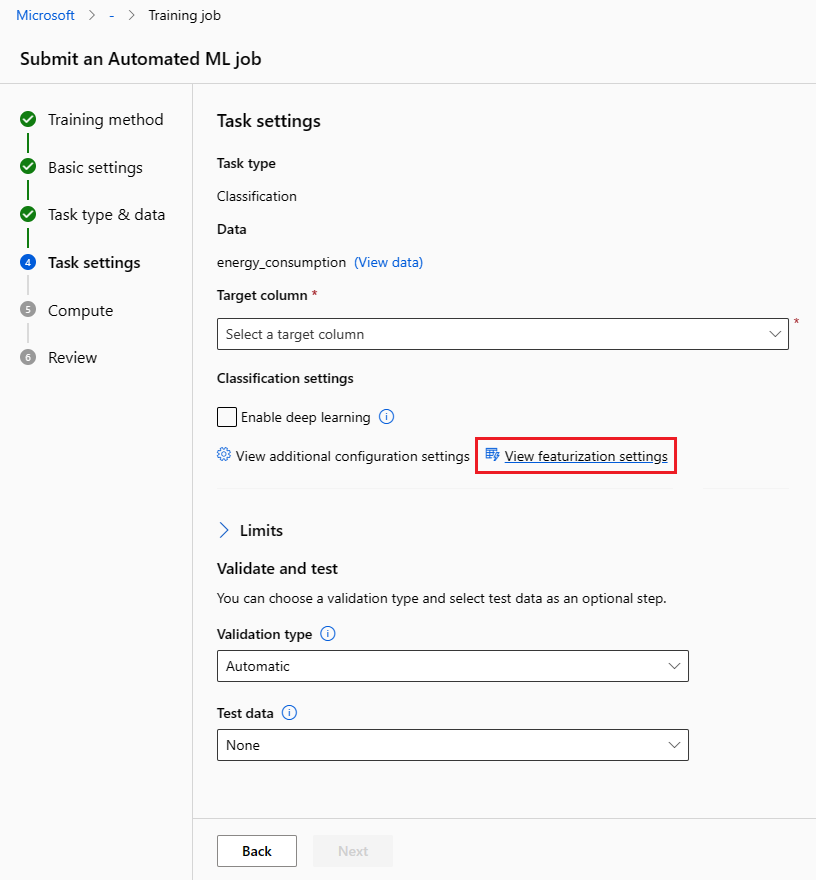
Formulář [Volitelné] Limity umožňuje provést následující akce.
Možnost Popis Maximální počet zkušebních verzí Maximální počet pokusů, z nichž každý má jinou kombinaci algoritmu a hyperparametrů, které se mají vyzkoušet během úlohy AutoML Musí být celé číslo od 1 do 1000. Maximální počet souběžných zkušebních verzí Maximální počet zkušebních úloh, které lze spustit paralelně. Musí být celé číslo od 1 do 1000. Maximální počet uzlů Maximální početuzlůch Prahová hodnota skóre metriky Po dosažení této prahové hodnoty pro metriku iterace se úloha trénování ukončí. Mějte na paměti, že smysluplné modely mají korelaci > 0, jinak by měly být stejně dobré jako odhad průměrné prahové hodnoty metriky mezi hranicemi [0, 10]. Časový limit experimentu (minuty) Maximální doba v minutách, po které může celý experiment běžet. Po dosažení tohoto limitu systém zruší úlohu AutoML včetně všech zkušebních verzí (podřízených úloh). Časový limit iterace (minuty) Maximální doba v minutách, po kterou může každá zkušební úloha běžet. Po dosažení tohoto limitu systém zkušební verzi zruší. Povolení předčasného ukončení Tuto úlohu ukončete, pokud se skóre v krátkodobém horizontu nezlepšuje. [ Volitelné] Ověření a testovací formulář umožňuje provést následující akce.
a. Zadejte typ ověření, který se má použít pro vaši trénovací úlohu. Pokud explicitně nezadáte ani parametr validation_datan_cross_validations , automatizované strojové učení použije výchozí techniky v závislosti na počtu řádků zadaných v jedné datové sadě training_data.
| Velikost trénovacích dat | Technika ověřování |
|---|---|
| Větší než 20 000 řádků | Použije se rozdělení dat trénování/ověření. Výchozí hodnota je 10 % počáteční trénovací sady dat jako ověřovací sady. Tato ověřovací sada se pak používá pro výpočet metrik. |
| Menší než 20 000& řádků | Použije se přístup křížového ověřování. Výchozí počet záhybů závisí na počtu řádků. Pokud je datová sada menší než 1 000 řádků, použije se 10 složených záhybů. Pokud jsou řádky v rozmezí 1 000 až 20 000, použijí se tři záhyby. |
b. Zadejte testovací datovou sadu (Preview) pro vyhodnocení doporučeného modelu, který pro vás automatizované strojové učení vygeneruje na konci experimentu. Při zadání testovacích dat se na konci experimentu automaticky aktivuje testovací úloha. Tato testovací úloha je pouze úloha na nejlepším modelu, který doporučuje automatizované strojové učení. Zjistěte, jak získat výsledky úlohy vzdáleného testu.
Důležité
Poskytnutí testovací datové sady pro vyhodnocení vygenerovaných modelů je funkce Preview. Tato funkce je experimentální funkce ve verzi Preview a může se kdykoli změnit.
* Testovací data jsou považována za samostatnou od trénování a ověřování, aby nedošlo k předsudkům výsledků testovací úlohy doporučeného modelu. Přečtěte si další informace o předsudkech během ověřování modelu.
* Můžete buď zadat vlastní testovací datovou sadu, nebo se rozhodnout použít procento trénovací datové sady. Testovací data musí být ve formě objektu Azure Machine Učení TabularDataset.
* Schéma testovací datové sady by mělo odpovídat trénovací datové sadě. Cílový sloupec je nepovinný, ale pokud není žádný cílový sloupec označený jako žádný testovací metrika, nevypočítá se.
* Testovací datová sada by neměla být stejná jako trénovací datová sada nebo ověřovací datová sada.
* Úlohy prognózování nepodporují rozdělení trénování/testování.
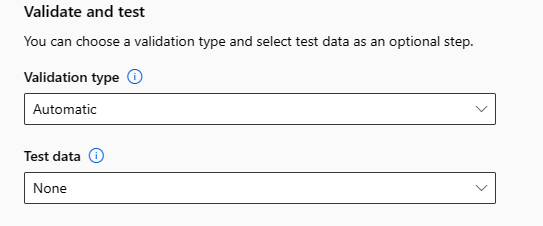
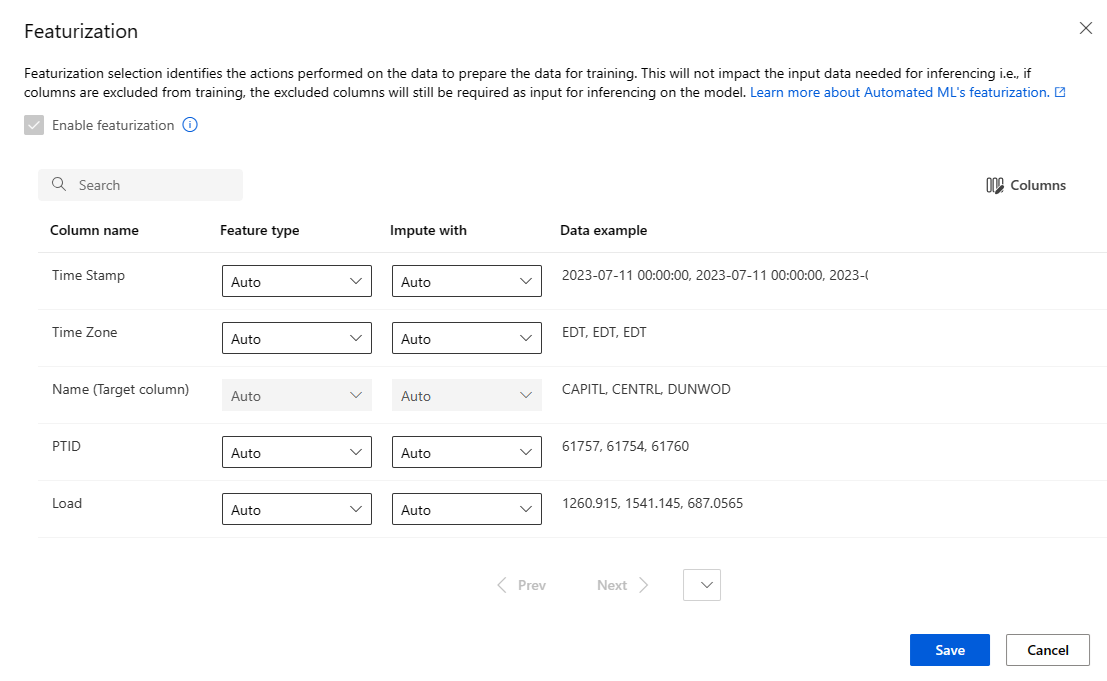
Přizpůsobení featurizace
Ve formuláři Featurizace můžete povolit nebo zakázat automatickou featurizaci a přizpůsobit nastavení automatické featurizace pro experiment. Pokud chcete tento formulář otevřít, přečtěte si krok 10 v části Vytvoření a spuštění experimentu .
Následující tabulka shrnuje vlastní nastavení, která jsou aktuálně dostupná prostřednictvím studia.
| Column | Vlastní nastavení |
|---|---|
| Typ funkce | Umožňuje změnit typ hodnoty pro vybraný sloupec. |
| Imputovat pomocí | Vyberte, jakou hodnotu mají být v datech imputované chybějící hodnoty. |
Spuštění experimentu a zobrazení výsledků
Vyberte Dokončit a spusťte experiment. Proces přípravy experimentu může trvat až 10 minut. U každého kanálu může další 2 až 3 minuty trvat, než se dokončí úlohy trénování. Pokud jste pro nejlepší doporučený model zadali generování řídicího panelu RAI, může to trvat až 40 minut.
Poznámka:
Algoritmy automatizovaného strojového učení mají vlastní náhodnost, která může způsobit mírné variace konečného skóre metrik doporučeného modelu, jako je přesnost. Automatizované strojové učení také provádí operace s daty, jako je rozdělení trénování testu, rozdělení ověření trénování nebo křížové ověření v případě potřeby. Pokud tedy spustíte experiment se stejným nastavením konfigurace a primární metrikou vícekrát, pravděpodobně se v každém experimentu zobrazí konečné skóre metriky.
Zobrazení podrobností o experimentu
Otevře se obrazovka Podrobnosti úlohy na kartě Podrobnosti . Tato obrazovka zobrazuje souhrn úlohy experimentu včetně stavového řádku v horní části vedle čísla úlohy.
Na kartě Modely je seznam vytvořených modelů seřazený podle skóre metriky. Ve výchozím nastavení se na prvním místě seznamu zobrazí model, který na základě zvolené metriky získá nejvyšší skóre. Při pokusu o další modely se úloha trénování přidá do seznamu. Tady můžete rychle porovnat metriky pro zatím vytvořené modely.
Zobrazení podrobností o trénovací úloze
Pokud chcete zobrazit podrobnosti o trénovací úloze, přejděte k podrobnostem o všech dokončených modelech.
Grafy metrik výkonu specifické pro model můžete zobrazit na kartě Metriky . Přečtěte si další informace o grafech.
Tady najdete také podrobnosti o všech vlastnostech modelu spolu s přidruženým kódem, podřízenými úlohami a obrázky.
Zobrazení výsledků vzdálené úlohy testu (Preview)
Pokud jste zadali testovací datovou sadu nebo jste se rozhodli pro rozdělení trénování/testu během nastavení experimentu– na formuláři Ověření a testování , automatizované strojové učení ve výchozím nastavení automaticky testuje doporučený model. Díky tomu automatizované strojové učení vypočítá testovací metriky, aby určil kvalitu doporučeného modelu a jeho predikce.
Důležité
Testování modelů pomocí testovací datové sady pro vyhodnocení vygenerovaných modelů je funkce preview. Tato funkce je experimentální funkce ve verzi Preview a může se kdykoli změnit.
Upozorňující
Tato funkce není k dispozici pro následující scénáře automatizovaného strojového učení.
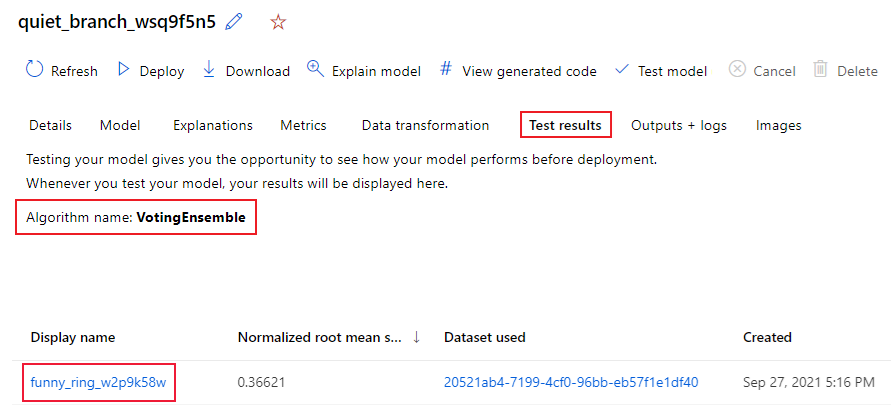
Pokud chcete zobrazit metriky testovací úlohy doporučeného modelu,
- Přejděte na stránku Modely a vyberte nejlepší model.
- Vyberte kartu Výsledky testu (Preview).
- Vyberte požadovanou úlohu a zobrazte kartu Metriky .
Zobrazení předpovědí testů použitých k výpočtu testovacích metrik:
- Přejděte do dolní části stránky a výběrem odkazu v části Výstupní datová sada otevřete datovou sadu.
- Na stránce Datové sady vyberte kartu Prozkoumat a zobrazte předpovědi z testovací úlohy.
- Případně můžete soubor predikce zobrazit nebo stáhnout z karty Výstupy + protokoly , rozbalte složku Predikce a vyhledejte soubor
predicted.csv.
- Případně můžete soubor predikce zobrazit nebo stáhnout z karty Výstupy + protokoly , rozbalte složku Predikce a vyhledejte soubor
Případně můžete soubor predikcí zobrazit nebo stáhnout z karty Výstupy a protokoly, rozbalte složku Predikce a vyhledejte soubor predictions.csv.
Úloha testu modelu vygeneruje soubor predictions.csv, který je uložený ve výchozím úložišti dat vytvořeném s pracovním prostorem. Toto úložiště dat je viditelné všem uživatelům se stejným předplatným. Testovací úlohy se nedoporučují pro scénáře, pokud některé z informací používaných pro testovací úlohu nebo vytvořené testovací úlohou musí zůstat soukromé.
Testování existujícího automatizovaného modelu ML (Preview)
Důležité
Testování modelů pomocí testovací datové sady pro vyhodnocení vygenerovaných modelů je funkce preview. Tato funkce je experimentální funkce ve verzi Preview a může se kdykoli změnit.
Upozorňující
Tato funkce není k dispozici pro následující scénáře automatizovaného strojového učení.
Po dokončení experimentu můžete otestovat modely, které pro vás automatizované strojové učení vygeneruje. Pokud chcete otestovat jiný automatizovaný model strojového učení, nikoli doporučený model, můžete to provést pomocí následujících kroků.
Vyberte existující úlohu experimentu automatizovaného strojového učení.
Přejděte na kartu Modely úlohy a vyberte dokončený model, který chcete otestovat.
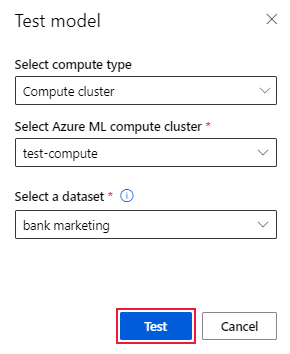
Na stránce Podrobnosti modelu vyberte tlačítko Test model(Preview) a otevřete podokno Testovací model.
V podokně Testovací model vyberte výpočetní cluster a testovací datovou sadu, kterou chcete použít pro testovací úlohu.
Klikněte na tlačítko Testovat. Schéma testovací datové sady by se mělo shodovat s trénovací datovou sadou, ale cílový sloupec je volitelný.
Po úspěšném vytvoření testovací úlohy modelu se na stránce Podrobnosti zobrazí zpráva o úspěchu. Výběrem karty Výsledky testu zobrazíte průběh úlohy.
Pokud chcete zobrazit výsledky testovací úlohy, otevřete stránku Podrobnosti a postupujte podle kroků v části Zobrazení výsledků vzdálené úlohy testu.
Řídicí panel zodpovědné umělé inteligence (Preview)
Pokud chcete lépe porozumět vašemu modelu, můžete zobrazit různé přehledy o modelu pomocí řídicího panelu Zodpovědné Ai. Umožňuje vyhodnotit a ladit svůj nejlepší model automatizovaného strojového učení. Řídicí panel zodpovědné umělé inteligence vyhodnotí chyby modelu a problémy s nestranností, diagnostikuje, proč k těmto chybám dochází vyhodnocením trénování nebo testovacích dat a pozorováním vysvětlení modelu. Tyto přehledy vám společně můžou pomoct vytvořit důvěru s vaším modelem a předat procesy auditu. Zodpovědné řídicí panely AI nejde vygenerovat pro stávající model automatizovaného strojového učení. Vytvoří se pouze pro nejlepší doporučený model při vytvoření nové úlohy AutoML. Uživatelé by měli dál používat vysvětlení modelů (Preview), dokud nebude podpora pro stávající modely poskytována.
Pokud chcete vygenerovat řídicí panel zodpovědné umělé inteligence pro konkrétní model,
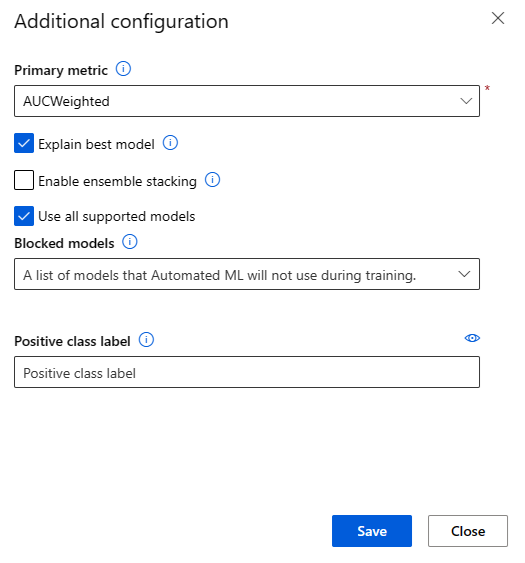
Při odesílání úlohy automatizovaného strojového učení přejděte do části Nastavení úloh na levém navigačním panelu a vyberte možnost Zobrazit další nastavení konfigurace.
V novém formuláři, který se zobrazí po výběru, zaškrtněte políčko Vysvětlit nejlepší model .
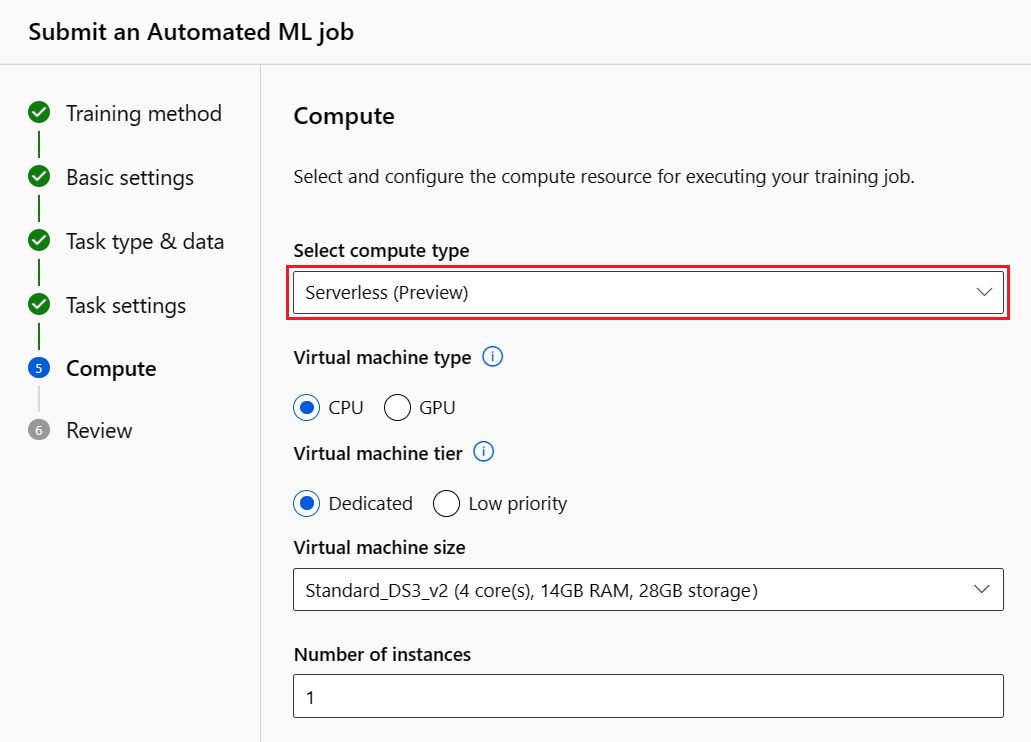
Přejděte na stránku Výpočetní prostředky ve formuláři nastavení a zvolte možnost Bezserverová pro výpočetní prostředky.
Po dokončení přejděte na stránku Modely úlohy automatizovaného strojového učení, která obsahuje seznam trénovaných modelů. Vyberte odkaz Zobrazit zodpovědný řídicí panel AI:
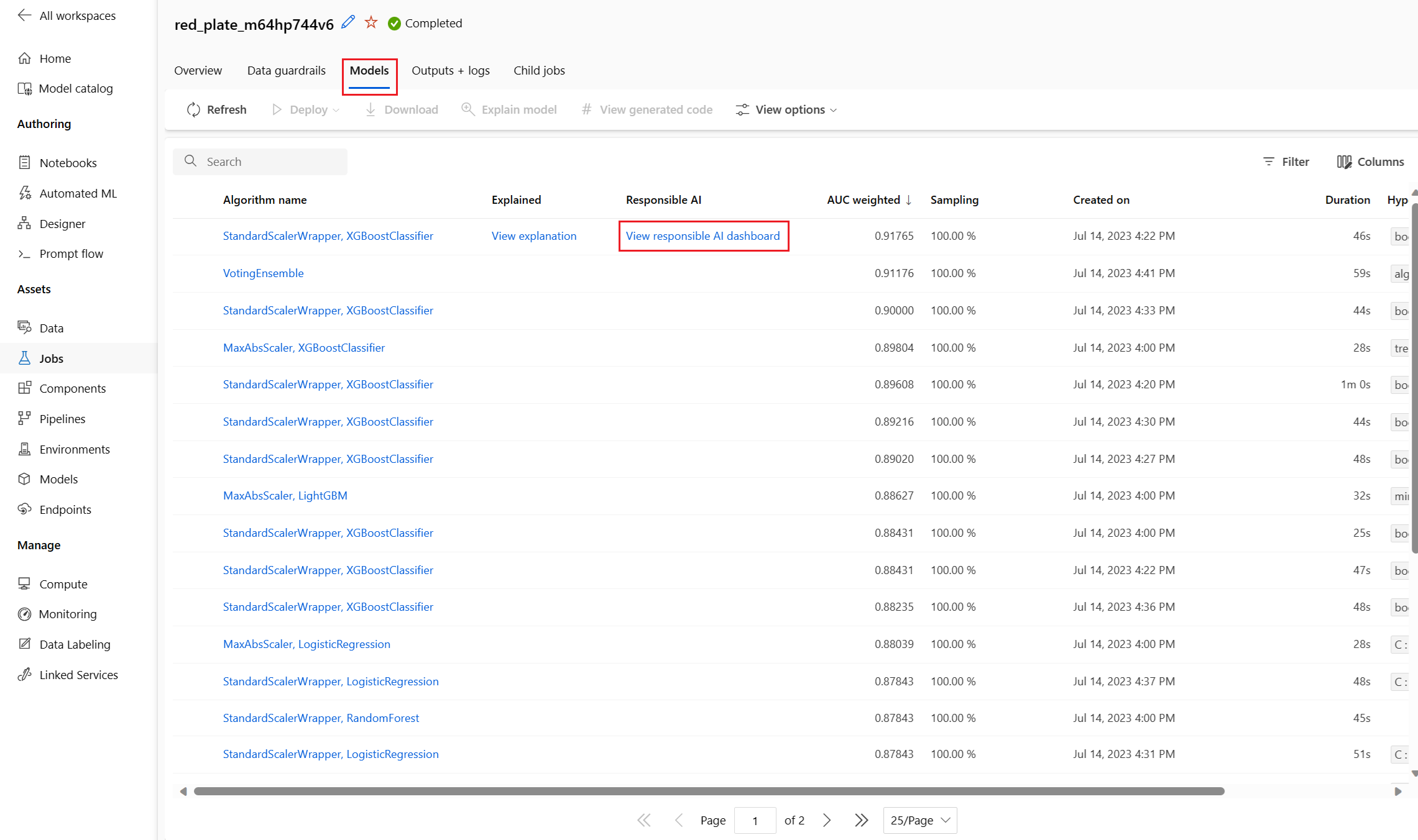
Pro tento model se zobrazí řídicí panel Zodpovědné AI, jak je znázorněno na tomto obrázku:
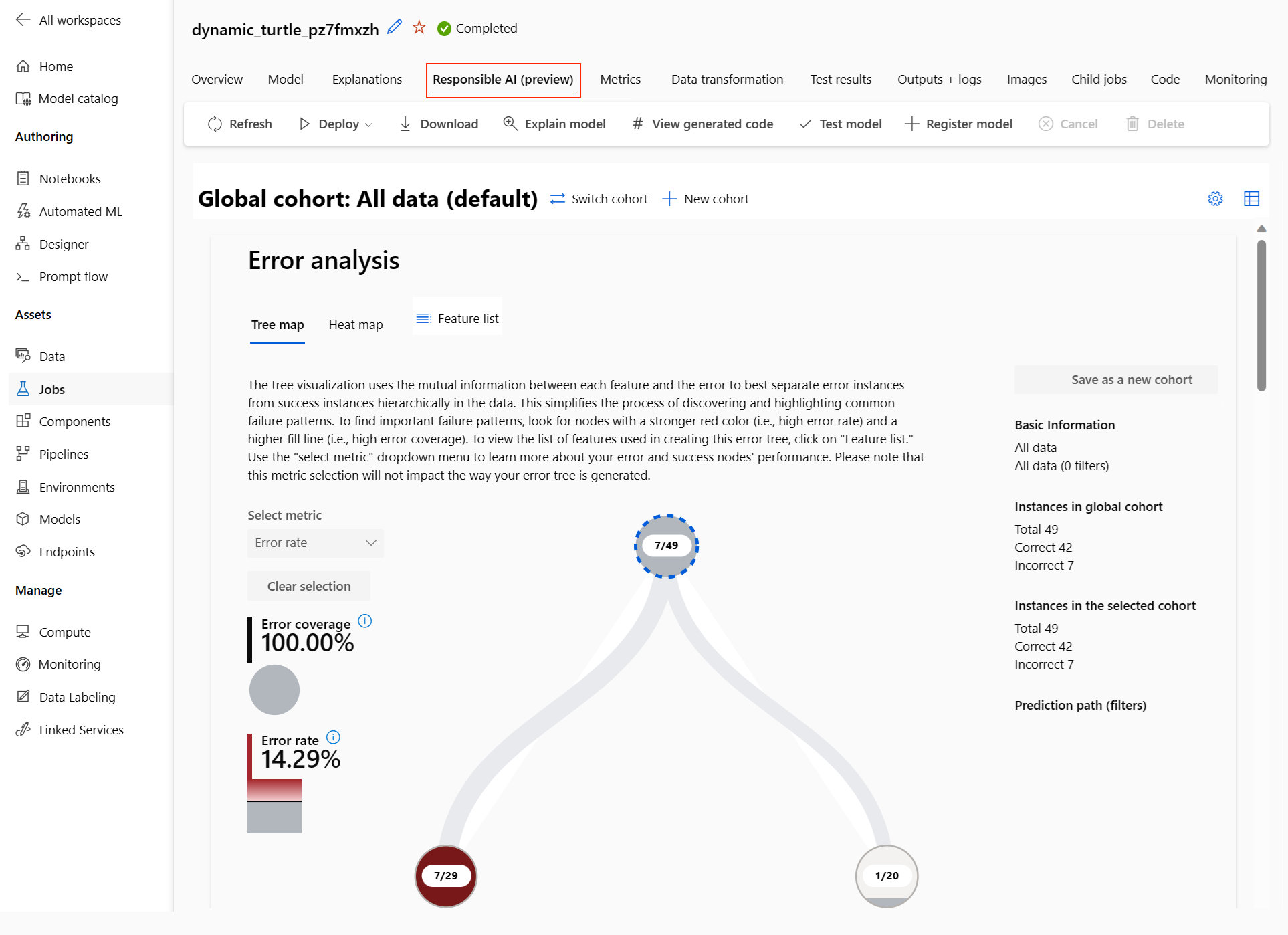
Na řídicím panelu najdete čtyři komponenty aktivované pro nejlepší model automatizovaného strojového učení:
| Komponenta | Co komponenta zobrazuje? | Jak si přečíst graf? |
|---|---|---|
| Analýza chyb | Analýzu chyb použijte v případě, že potřebujete: Získejte hluboké znalosti o tom, jak se selhání modelu distribuují napříč datovou sadou a napříč několika dimenzemi vstupu a funkcí. Rozdělte agregované metriky výkonu tak, aby automaticky zjistily chybné kohorty, abyste mohli informovat cílené kroky pro zmírnění rizik. |
Grafy analýzy chyb |
| Přehled modelů a nestrannost | Tato komponenta slouží k: Získejte hluboké znalosti o výkonu modelu napříč různými kohortami dat. Když se podíváte na metriky nestrannosti, porozumíte problémům s nestranností modelu. Tyto metriky můžou vyhodnotit a porovnat chování modelu napříč podskupinami identifikovanými z hlediska citlivých (nebo nesmyslných) funkcí. |
Přehled modelů a grafy nestrannosti |
| Vysvětlení modelů | Pomocí komponenty vysvětlení modelu můžete vygenerovat popisy předpovědí modelu strojového učení, které jsou srozumitelné pro člověka: Globální vysvětlení: Jaké funkce mají například vliv na celkové chování modelu přidělování úvěrů? Místní vysvětlení: Proč byla například žádost o půjčku zákazníka schválena nebo odmítnuta? |
Model Explainability Charts |
| Analýza dat | Analýzu dat použijte v případě, že potřebujete: Prozkoumejte statistiky datové sady tak, že vyberete různé filtry pro rozdělení dat do různých dimenzí (označovaných také jako kohorty). Porozumíte distribuci datové sady mezi různé kohorty a skupiny funkcí. Určete, jestli vaše zjištění týkající se spravedlnosti, analýzy chyb a kauzality (odvozené z jiných komponent řídicího panelu) představují výsledek distribuce datové sady. Rozhodněte se, ve kterých oblastech se mají shromažďovat další data, abyste zmírnit chyby, které pocházejí z problémů reprezentace, šumu popisků, šumu funkcí, předsudků popisků a podobných faktorů. |
Grafy Data Exploreru |
- Můžete dále vytvářet kohorty (podskupiny datových bodů, které sdílejí zadané charakteristiky), abyste se zaměřili na analýzu jednotlivých komponent na různé kohorty. V levém horním rohu řídicího panelu se vždy zobrazí název kohorty, která se aktuálně používá na řídicím panelu. Výchozí zobrazení na řídicím panelu je celá datová sada s názvem Všechna data (ve výchozím nastavení). Další informace o globálním řízení řídicího panelu najdete tady.
Úpravy a odesílání úloh (Preview)
Důležité
Možnost kopírovat, upravovat a odesílat nový experiment na základě existujícího experimentu je funkce ve verzi Preview. Tato funkce je experimentální funkce ve verzi Preview a může se kdykoli změnit.
Ve scénářích, ve kterých chcete vytvořit nový experiment na základě nastavení existujícího experimentu, nabízí automatizované strojové učení možnost k tomu použít tlačítko Upravit a odeslat v uživatelském rozhraní studia.
Tato funkce je omezená na experimenty zahájené z uživatelského rozhraní studia a vyžaduje, aby schéma dat nového experimentu odpovídalo schématu původního experimentu.
Tlačítko Upravit a odeslat otevře průvodce vytvořením nové úlohy automatizovaného strojového učení s předem vyplněnými daty, výpočetními prostředky a nastavením experimentu. Jednotlivé formuláře můžete procházet a podle potřeby upravovat výběry pro nový experiment.
Nasazení modelu
Jakmile budete mít nejlepší model, je čas ho nasadit jako webovou službu, která předpovídá na nová data.
Tip
Pokud chcete nasadit model vygenerovaný prostřednictvím automl balíčku pomocí sady Python SDK, musíte ho zaregistrovat do pracovního prostoru.
Jakmile je model zaregistrovaný, najděte ho v sadě Studio tak , že v levém podokně vyberete Modely . Po otevření modelu můžete v horní části obrazovky vybrat tlačítko Nasadit a postupovat podle pokynů popsaných v kroku 2 části Nasazení modelu.
Automatizované strojové učení pomáhá s nasazením modelu bez psaní kódu:
Máte několik možností nasazení.
Možnost 1: Nasaďte nejlepší model podle vámi definovaných kritérií metrik.
- Po dokončení experimentu přejděte na stránku nadřazené úlohy výběrem možnosti Úloha 1 v horní části obrazovky.
- Vyberte model uvedený v části Nejlepší souhrn modelu.
- V levém horním rohu okna vyberte Nasadit .
Možnost 2: Nasazení konkrétní iterace modelu z tohoto experimentu
- Na kartě Modely vyberte požadovaný model.
- V levém horním rohu okna vyberte Nasadit .
Naplňte podokno Nasadit model .
Pole Hodnota Name Zadejte jedinečný název nasazení. Popis Zadejte popis, abyste lépe identifikovali, k čemu toto nasazení slouží. Typ výpočetních prostředků Vyberte typ koncového bodu, který chcete nasadit: Azure Kubernetes Service (AKS) nebo Azure Container Instance (ACI). Název výpočetních prostředků Platí jenom pro AKS: Vyberte název clusteru AKS, do kterého chcete nasadit. Povolit ověřování Vyberte, pokud chcete povolit ověřování založené na tokenech nebo klíčích. Použití vlastních prostředků nasazení Tuto funkci povolte, pokud chcete nahrát vlastní hodnoticí skript a soubor prostředí. V opačném případě automatizované strojové učení poskytuje tyto prostředky ve výchozím nastavení. Další informace o hodnoticích skriptech Důležité
Názvy souborů musí být kratší než 32 znaků a musí začínat a končit alfanumerickými znaky. Jinak můžou obsahovat pomlčky, podtržítka, tečky a alfanumerické znaky. Mezery nejsou povolené.
Nabídka Upřesnit nabízí výchozí funkce nasazení, jako jsou nastavení shromažďování dat nebo využití prostředků. Pokud chcete tato výchozí nastavení přepsat, můžete to udělat v této nabídce.
Vyberte Nasadit. Dokončení nasazení může trvat přibližně 20 minut. Po zahájení nasazení se zobrazí karta Shrnutí modelu. Průběh nasazení můžete sledovat v části Stav nasazení.
Teď máte funkční webovou službu pro generování předpovědí. Předpovědi můžete otestovat dotazováním služby s využitím integrované podpory služby Azure Machine Learning v Power BI.