Kurz: Trénování prvního modelu strojového učení (SDK v1, část 2 ze 3)
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
V tomto kurzu se dozvíte, jak vytrénovat model strojového učení ve službě Azure Machine Learning. Tento kurz je druhou částí dvoudílné série kurzů.
V části 1: Spuštění "Hello world!" série jste se naučili, jak pomocí řídicího skriptu spustit úlohu v cloudu.
V tomto kurzu provedete další krok odesláním skriptu, který trénuje model strojového učení. Tento příklad vám pomůže pochopit, jak Azure Machine Learning usnadňuje konzistentní chování mezi místním laděním a vzdálenými spuštěními.
V tomto kurzu se naučíte:
- Vytvořte trénovací skript.
- Pomocí Conda definujte prostředí Azure Machine Learning.
- Vytvořte řídicí skript.
- Principy tříd služby Azure Machine Learning (
Environment,Run,Metrics). - Odešlete a spusťte trénovací skript.
- Zobrazte výstup kódu v cloudu.
- Protokolovat metriky do služby Azure Machine Learning
- Zobrazte metriky v cloudu.
Požadavky
- Dokončení 1. části série.
Vytváření trénovacích skriptů
Nejprve definujete architekturu neurální sítě v souboru model.py . Veškerý trénovací kód přejde do src podadresáře, včetně model.py.
Trénovací kód pochází z tohoto úvodního příkladu z PyTorchu. Koncepty služby Azure Machine Learning platí pro jakýkoli kód strojového učení, nejen pro PyTorch.
V podsložce src vytvořte soubor model.py. Zkopírujte tento kód do souboru:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xNa panelu nástrojů vyberte Uložit a soubor uložte. Pokud chcete, zavřete kartu.
Dále definujte trénovací skript také v podsložce src . Tento skript stáhne datovou sadu CIFAR10 pomocí rozhraní API PyTorch
torchvision.dataset, nastaví síť definovanou v model.py a vytrénuje ji pro dvě epochy pomocí standardního SGD a ztráty křížové entropie.Vytvořte train.py skript v podsložce src:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")Teď máte následující strukturu složek:
Místní testování
Výběrem možnosti Uložit a spustit skript v terminálu spusťte skript train.py přímo na výpočetní instanci.
Po dokončení skriptu vyberte Aktualizovat nad složkami souborů. Zobrazí se nová datová složka s názvem get-started/data Expand this folder to view the downloaded data.
Vytvoření prostředí Pythonu
Azure Machine Learning poskytuje koncept prostředí , které představuje reprodukovatelné a verze prostředí Pythonu pro spouštění experimentů. Vytvoření prostředí z místního prostředí Conda nebo pip je snadné.
Nejprve vytvoříte soubor se závislostmi balíčku.
Ve složce get-started vytvořte nový soubor s názvem
pytorch-env.yml:name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvisionNa panelu nástrojů vyberte Uložit a soubor uložte. Pokud chcete, zavřete kartu.
Vytvoření řídicího skriptu
Rozdíl mezi následujícím řídicím skriptem a skriptem, který jste použili k odeslání příkazu "Hello world!", je, že k nastavení prostředí přidáte několik dalších řádků.
Ve složce get-started vytvořte nový soubor Pythonu s názvem run-pytorch.py:
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Tip
Pokud jste při vytváření výpočetního clusteru použili jiný název, nezapomeňte název upravit i v kódu compute_target='cpu-cluster' .
Vysvětlení změn kódu
env = ...
Odkazuje na soubor závislostí, který jste vytvořili výše.
config.run_config.environment = env
Přidá prostředí do ScriptRunConfig.
Odeslání spuštění do služby Azure Machine Learning
Výběrem příkazu Uložit a spustit skript v terminálu spusťte run-pytorch.py skript.
V okně terminálu se zobrazí odkaz, který se otevře. Výběrem odkazu zobrazíte úlohu.
Poznámka:
Při načítání azureml_run_type_providers... se může zobrazit některá upozornění, která začínají chybou. Tato upozornění můžete ignorovat. K zobrazení výstupu použijte odkaz v dolní části těchto upozornění.
Zobrazení výstupu
- Na stránce, která se otevře, se zobrazí stav úlohy. Při prvním spuštění tohoto skriptu azure Machine Learning vytvoří novou image Dockeru z prostředí PyTorch. Dokončení celé úlohy může trvat přibližně 10 minut. Tato image bude znovu použita v budoucích úlohách, aby byla mnohem rychlejší.
- V studio Azure Machine Learning můžete zobrazit protokoly sestavení Dockeru. zobrazení protokolů sestavení:
- Vyberte kartu Výstupy a protokoly.
- Vyberte složku azureml-logs .
- Vyberte 20_image_build_log.txt.
- Jakmile je stav úlohy Dokončeno, vyberte Výstup + protokoly.
- Vyberte user_logs a pak std_log.txt zobrazte výstup úlohy.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
Pokud se zobrazí chybaYour total snapshot size exceeds the limit, datová složka se nachází v hodnotě source_directory použité v ScriptRunConfig.
Vyberte ... na konci složky a pak vyberte Přesunout a přesuňte data do složky Get-started.
Metriky trénování protokolů
Teď, když máte trénování modelu ve službě Azure Machine Learning, začněte sledovat některé metriky výkonu.
Aktuální trénovací skript vytiskne metriky do terminálu. Azure Machine Learning poskytuje mechanismus protokolování metrik s dalšími funkcemi. Přidáním několika řádků kódu získáte možnost vizualizovat metriky v sadě Studio a porovnat metriky mezi několika úlohami.
Úprava train.py tak, aby zahrnovala protokolování
Upravte skript train.py tak, aby obsahoval dva další řádky kódu:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Uložte tento soubor a pak kartu zavřete, pokud chcete.
Vysvětlení dalších dvou řádků kódu
V train.py přistupujete k objektu spuštění přímo z trénovacího skriptu pomocí Run.get_context() metody a použijete ho k protokolování metrik:
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
Metriky ve službě Azure Machine Learning jsou:
- Uspořádané podle experimentu a spuštění, takže je snadné sledovat a porovnávat metriky.
- Vybaveno uživatelským rozhraním, abyste mohli vizualizovat výkon trénování v studiu.
- Navržené pro škálování, takže tyto výhody zachováte i při spouštění stovek experimentů.
Aktualizace souboru prostředí Conda
Skript train.py právě vzal novou závislost na azureml.core. Aktualizace pytorch-env.yml tak, aby odrážela tuto změnu:
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
Před odesláním spuštění nezapomeňte tento soubor uložit.
Odeslání spuštění do služby Azure Machine Learning
Vyberte kartu pro run-pytorch.py skript a pak v terminálu vyberte Uložit a spustit skript, aby se skript run-pytorch.py znovu spustil. Nejprve uložte provedené změny pytorch-env.yml .
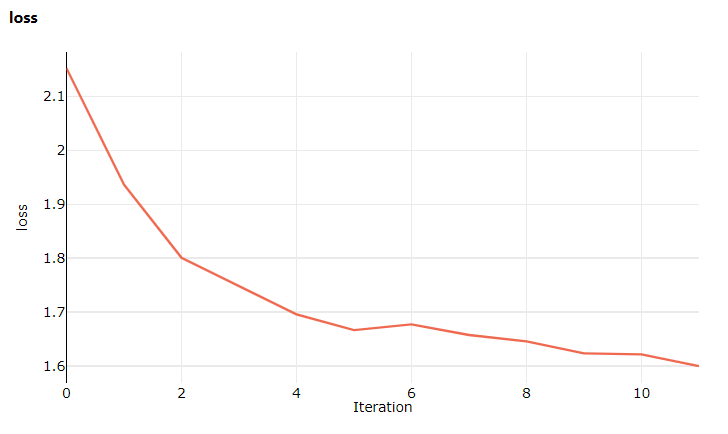
Tentokrát, když navštívíte studio, přejděte na kartu Metriky , kde teď můžete vidět živé aktualizace o ztrátě trénování modelu. Než začne trénování, může to trvat 1 až 2 minuty.
Vyčištění prostředků
Pokud chcete pokračovat v dalším kurzu nebo začít s vlastními trénovacími úlohami, přeskočte na Související zdroje.
Zastavení výpočetní instance
Pokud ji teď nebudete používat, zastavte výpočetní instanci:
- V sadě Studio na levé straně vyberte Compute.
- Na horních kartách vyberte Výpočetní instance.
- V seznamu vyberte výpočetní instanci.
- Na horním panelu nástrojů vyberte Zastavit.
Odstranění všech prostředků
Důležité
Prostředky, které jste vytvořili, se dají použít jako předpoklady pro další kurzy a články s postupy pro Azure Machine Learning.
Pokud nemáte v úmyslu používat žádné prostředky, které jste vytvořili, odstraňte je, abyste za ně neúčtovaly žádné poplatky:
Úplně nalevo na webu Azure Portal vyberte Skupiny prostředků.
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Vyberte Odstranit skupinu prostředků.
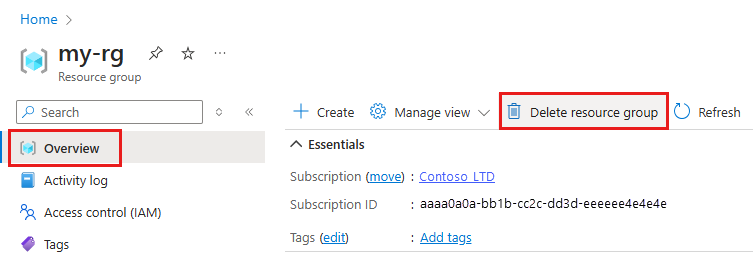
Zadejte název skupiny prostředků. Poté vyberte Odstranit.
Můžete také zachovat skupinu prostředků, ale odstranit jeden pracovní prostor. Zobrazte vlastnosti pracovního prostoru a vyberte Odstranit.
Související prostředky
V této relaci jste upgradovali ze základního skriptu "Hello world!" na realističtější trénovací skript, který ke spuštění vyžadoval konkrétní prostředí Pythonu. Viděli jste, jak používat kurátorovaná prostředí Azure Machine Learning. Nakonec jste viděli, jak v několika řádcích kódu můžete protokolovat metriky do služby Azure Machine Learning.
Existují další způsoby, jak vytvořit prostředí Azure Machine Learning, včetně z souboru pip requirements.txt nebo z existujícího místního prostředí Conda.