Nasazení modelu do clusteru Azure Kubernetes Service s v1
Důležité
Tento článek vysvětluje, jak k nasazení modelu použít Azure Machine Učení CLI (v1) a Sadu Azure Machine Učení SDK pro Python (v1). Doporučený přístup pro v2 najdete v tématu Nasazení a určení skóre modelu strojového učení pomocí online koncového bodu.
Naučte se používat Azure Machine Učení k nasazení modelu jako webové služby ve službě Azure Kubernetes Service (AKS). AKS je vhodný pro vysoce škálovaná produkční nasazení. AKS použijte, pokud potřebujete jednu nebo více z následujících možností:
- Rychlá doba odezvy
- Automatické škálování nasazené služby
- Protokolování
- Shromažďování dat modelu
- Authentication
- Ukončení šifrování TLS
- Možnosti hardwarové akcelerace , jako jsou GPU a programovatelné hradlové pole (FPGA)
Při nasazování do AKS nasadíte do clusteru AKS, který je připojený k vašemu pracovnímu prostoru. Informace o připojení clusteru AKS k vašemu pracovnímu prostoru najdete v tématu Vytvoření a připojení clusteru Azure Kubernetes Service.
Důležité
Před nasazením do webové služby doporučujeme ladit místně. Další informace najdete v tématu Řešení potíží s místním nasazením modelu.
Můžete také odkazovat na nasazení do místního poznámkového bloku na GitHubu.
Poznámka:
Koncové body služby Azure Machine Učení (v2) poskytují vylepšené a jednodušší prostředí pro nasazení. Koncové body podporují scénáře odvození v reálném čase i dávkového odvozu. Koncové body poskytují jednotné rozhraní pro vyvolání a správu nasazení modelu napříč typy výpočetních prostředků. Podívejte se, co jsou koncové body azure machine Učení?
Požadavky
Pracovní prostor služby Azure Machine Learning. Další informace najdete v tématu Vytvoření pracovního prostoru Učení počítače Azure.
Model strojového učení zaregistrovaný ve vašem pracovním prostoru Pokud nemáte zaregistrovaný model, přečtěte si téma Nasazení modelů strojového učení do Azure.
Rozšíření Azure CLI (v1) pro službu Machine Učení, Azure Machine Učení Python SDK nebo rozšíření Azure Machine Učení Visual Studio Code.
Důležité
Některé příkazy Azure CLI v tomto článku používají
azure-cli-mlrozšíření Azure Machine Učení ( nebo v1). Podpora rozšíření v1 skončí 30. září 2025. Do tohoto data budete moct nainstalovat a používat rozšíření v1.Doporučujeme přejít na
mlrozšíření (nebo v2) před 30. zářím 2025. Další informace o rozšíření v2 najdete v tématu Rozšíření Azure ML CLI a Python SDK v2.Fragmenty kódu Pythonu v tomto článku předpokládají, že jsou nastavené následující proměnné:
ws– Nastavte si pracovní prostor.model- Nastavte si zaregistrovaný model.inference_config– Nastavte konfiguraci odvozování modelu.
Fragmenty kódu rozhraní příkazového řádku v tomto článku předpokládají, že jste už vytvořili inferenceconfig.json dokument. Další informace o vytvoření tohoto dokumentu najdete v tématu Nasazení modelů strojového učení do Azure.
Cluster AKS připojený k vašemu pracovnímu prostoru. Další informace najdete v tématu Vytvoření a připojení clusteru Azure Kubernetes Service.
- Pokud chcete nasadit modely do uzlů GPU nebo uzlů FPGA (nebo jakéhokoli konkrétního produktu), musíte vytvořit cluster s konkrétním produktem. Neexistuje žádná podpora pro vytvoření fondu sekundárních uzlů v existujícím clusteru a nasazení modelů ve fondu sekundárních uzlů.
Principy procesů nasazení
Slovo nasazení se používá v Kubernetes i v Učení Azure Machine. Nasazení má v těchto dvou kontextech různé významy. V Kubernetes je nasazení konkrétní entitou určenou deklarativním souborem YAML. Nasazení Kubernetes má definovaný životní cyklus a konkrétní vztahy s jinými entitami Kubernetes, jako PodsReplicaSetsjsou a . O Kubernetes se můžete dozvědět z dokumentace a videí na adrese Co je Kubernetes?
V azure Machine Učení se nasazení používá v obecnějším smyslu zpřístupnění a čištění prostředků projektu. Kroky, které Azure Machine Učení považuje za součást nasazení, jsou:
- Zazipování souborů ve složce projektu a ignorování souborů zadaných v souboru .amlignore nebo .gitignore
- Vertikální navýšení kapacity výpočetního clusteru (souvisí s Kubernetes)
- Sestavení nebo stažení souboru dockerfile do výpočetního uzlu (souvisí s Kubernetes)
- Systém vypočítá hodnotu hash:
- Základní image
- Vlastní kroky Dockeru (viz Nasazení modelu pomocí vlastní základní image Dockeru)
- Definice conda YAML (viz Vytvoření a použití softwarových prostředí v Azure Machine Učení)
- Systém použije tuto hodnotu hash jako klíč ve vyhledávání pracovního prostoru Azure Container Registry (ACR).
- Pokud se nenajde, vyhledá shodu v globální službě ACR.
- Pokud se nenajde, systém sestaví novou image uloženou v mezipaměti a odešle ji do pracovního prostoru ACR.
- Systém vypočítá hodnotu hash:
- Stažení souboru zkomprimovaného projektu do dočasného úložiště na výpočetním uzlu
- Rozbalení souboru projektu
- Výpočetní uzel, který se spouští
python <entry script> <arguments> - Ukládání protokolů, souborů modelu a dalších souborů zapsaných do souboru ./outputs do účtu úložiště přidruženého k pracovnímu prostoru
- Vertikální snížení kapacity výpočetních prostředků, včetně odebrání dočasného úložiště (souvisí s Kubernetes)
Směrovač služby Azure Machine Učení
Front-endová komponenta (azureml-fe), která směruje příchozí požadavky na odvozovací požadavky do nasazených služeb, se podle potřeby automaticky škáluje. Škálování azureml-fe je založené na účelu a velikosti clusteru AKS (počet uzlů). Účel clusteru a uzly se konfigurují při vytváření nebo připojování clusteru AKS. Pro každý cluster existuje jedna služba azureml-fe, která může běžet na několika podech.
Důležité
Pokud používáte cluster nakonfigurovaný jako dev-test, je samoobslužný škálování zakázaný. I u clusterů FastProd/DenseProd je samoobslužné škálování povolené jenom v případě, že telemetrie ukazuje, že je potřeba.
Poznámka:
Maximální datová část požadavku je 100 MB.
Azureml-fe škáluje kapacitu nahoru (svisle), aby používala více jader, a horizontálně (horizontálně) pro použití více podů. Při rozhodování o vertikálním navýšení kapacity se použije doba, kterou trvá směrování příchozích požadavků na odvozování. Pokud tato doba překročí prahovou hodnotu, provede se vertikální navýšení kapacity. Pokud doba směrování příchozích požadavků nadále překračuje prahovou hodnotu, dojde k horizontálnímu navýšení kapacity.
Při vertikálním snížení a snížení kapacity se používá využití procesoru. Pokud je dosažená prahová hodnota využití procesoru, front-end se nejprve škáluje dolů. Pokud využití procesoru klesne na prahovou hodnotu horizontálního snížení kapacity, provede se operace horizontálního snížení kapacity. Vertikální navýšení a navýšení kapacity probíhá pouze v případě, že je k dispozici dostatek prostředků clusteru.
Při vertikálním navýšení nebo snížení kapacity se pody azureml-fe restartují, aby se použily změny procesoru a paměti. Restartování neovlivní odvozování požadavků.
Vysvětlení požadavků na připojení pro cluster AKS pro odvozování
Když Azure Machine Učení vytvoří nebo připojí cluster AKS, nasadí se cluster AKS s jedním z následujících dvou síťových modelů:
- Sítě Kubenet: Síťové prostředky se obvykle vytvářejí a konfigurují při nasazení clusteru AKS.
- Sítě Azure Container Networking Interface (CNI): Cluster AKS je připojený k existujícímu prostředku a konfiguracím virtuální sítě.
Pro sítě Kubenet se síť vytvoří a správně nakonfiguruje pro službu Azure Machine Učení. V případě sítí CNI musíte porozumět požadavkům na připojení a zajistit překlad DNS a odchozí připojení pro odvozování AKS. K blokování síťového provozu můžete například použít bránu firewall.
Následující diagram znázorňuje požadavky na připojení pro odvozování AKS. Černé šipky představují skutečnou komunikaci a modré šipky představují názvy domén. Možná budete muset přidat položky pro tyto hostitele do brány firewall nebo do vlastního serveru DNS.
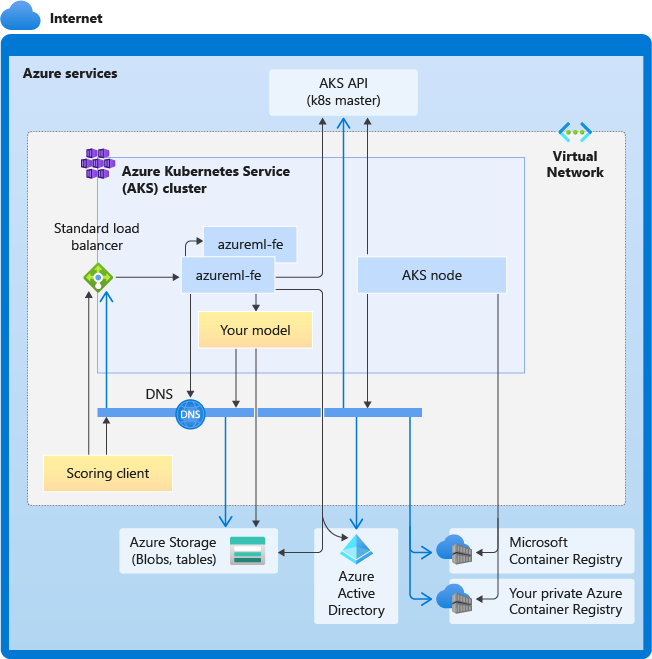
Obecné požadavky na připojení AKS najdete v tématu Omezení síťového provozu pomocí služby Azure Firewall v AKS.
Informace o přístupu ke službám Azure Machine Učení za bránou firewall najdete v tématu Konfigurace příchozího a odchozího síťového provozu.
Celkové požadavky na překlad DNS
Překlad DNS v rámci existující virtuální sítě je pod vaší kontrolou. Například brána firewall nebo vlastní server DNS. Následující hostitelé musí být dosažitelní:
| Název hostitele | Používá |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
Server rozhraní API AKS |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Vaše služba Azure Container Registry (ACR) |
<account>.table.core.windows.net |
Účet služby Azure Storage (Table Storage) |
<account>.blob.core.windows.net |
Účet služby Azure Storage (Blob Storage) |
api.azureml.ms |
Ověřování Microsoft Entra |
ingest-vienna<region>.kusto.windows.net |
Koncový bod Kusto pro aktualizaci telemetrie |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
Název domény koncového bodu, pokud jste automaticky vygenerovali pomocí služby Azure Machine Učení. Pokud jste použili vlastní název domény, tuto položku nepotřebujete. |
Připojení požadavky na spolehlivost v chronologickém pořadí
V procesu vytvoření nebo připojení AKS se do clusteru AKS nasadí směrovač Azure Machine Učení (azureml-fe). Aby bylo možné nasadit směrovač Azure Machine Učení, měl by být uzel AKS schopný:
- Překlad DNS pro server rozhraní API AKS
- Řešení DNS pro MCR za účelem stažení imagí Dockeru pro směrovač Azure Machine Učení
- Stažení imagí z MCR, kde se vyžaduje odchozí připojení
Hned po nasazení azureml-fe se pokusí spustit a to vyžaduje:
- Překlad DNS pro server rozhraní API AKS
- Dotazování serveru rozhraní API AKS za účelem zjištění jiných instancí samotného (jedná se o službu s více pody)
- Připojení k jiným instancím samotného
Jakmile se azureml-fe spustí, vyžaduje správné fungování následujícího připojení:
- Připojení do Služby Azure Storage ke stažení dynamické konfigurace
- Přeložte DNS pro ověřovací server Microsoft Entra api.azureml.ms a komunikujte s ním, když nasazená služba používá ověřování Microsoft Entra.
- Dotazování serveru rozhraní API AKS za účelem zjišťování nasazených modelů
- Komunikace s nasazenými identifikátory POD modelu
V době nasazení modelu by pro úspěšné nasazení modelu měl být uzel AKS schopný:
- Překlad DNS pro ACR zákazníka
- Stažení obrázků z ACR zákazníka
- Překlad DNS pro azure BLOB, kde je uložený model
- Stažení modelů z azure BLOB
Jakmile se model nasadí a služba spustí, azureml-fe ho automaticky zjistí pomocí rozhraní API AKS a je připraven k jeho směrování. Musí být schopný komunikovat s modelem POD.
Poznámka:
Pokud nasazený model vyžaduje připojení (například dotazování externí databáze nebo jiné služby REST nebo stažení objektu BLOB), mělo by být pro tyto služby povolené překlad DNS i odchozí komunikace.
Nasazení do AKS
Pokud chcete nasadit model do AKS, vytvořte konfiguraci nasazení, která popisuje potřebné výpočetní prostředky. Například počet jader a paměti. Potřebujete také konfiguraci odvozování, která popisuje prostředí potřebné k hostování modelu a webové služby. Další informace o vytvoření konfigurace odvozování najdete v tématu Postupy a umístění nasazení modelů.
Poznámka:
Počet nasazovaných modelů je omezený na 1 000 modelů na jedno nasazení (na kontejner).
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
Další informace o třídách, metodách a parametrech použitých v tomto příkladu najdete v následujících referenčních dokumentech:
Automatické škálování
PLATÍ PRO:Python SDK azureml v1
Komponenta, která zpracovává automatické škálování pro nasazení modelu Azure Machine Učení, je azureml-fe, což je směrovač inteligentních požadavků. Vzhledem k tomu, že všechny požadavky na odvozování procházejí, mají potřebná data k automatickému škálování nasazených modelů.
Důležité
Nepovolujte horizontální automatické škálování podů Kubernetes (HPA) pro nasazení modelů. Tím dojde k tomu, že dvě komponenty automatického škálování vzájemně soupeří. Azureml-fe je navržený tak, aby automaticky škáloval modely nasazené službou Azure Machine Učení, kde hpA musí odhadnout nebo odhadnout využití modelu z obecné metriky, jako je využití procesoru nebo vlastní konfigurace metrik.
Azureml-fe neškáluje počet uzlů v clusteru AKS, protože to může vést k neočekávanému zvýšení nákladů. Místo toho škáluje počet replik modelu v rámci fyzických hranic clusteru. Pokud potřebujete škálovat počet uzlů v clusteru, můžete cluster škálovat ručně nebo nakonfigurovat automatické škálování clusteru AKS.
Automatické škálování je možné řídit nastavením autoscale_target_utilizationa autoscale_min_replicasautoscale_max_replicas pro webovou službu AKS. Následující příklad ukazuje, jak povolit automatické škálování:
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
Rozhodnutí o vertikálním navýšení nebo snížení kapacity jsou založená na využití aktuálních replik kontejneru. Počet replik, které jsou zaneprázdněné (zpracování požadavku) vydělené celkovým počtem aktuálních replik, je aktuální využití. Pokud toto číslo překročí autoscale_target_utilization, vytvoří se více replik. Pokud je nižší, repliky se zmenší. Ve výchozím nastavení je cílové využití 70 %.
Rozhodnutí o přidání replik jsou dychtivá a rychlá (přibližně 1 sekunda). Rozhodnutí o odebrání replik jsou konzervativní (přibližně 1 minuta).
Požadované repliky můžete vypočítat pomocí následujícího kódu:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Další informace o nastavení autoscale_target_utilization, autoscale_max_replicasa autoscale_min_replicas, naleznete v AksWebservice modul reference.
Ověřování webové služby
Při nasazování do služby Azure Kubernetes Service je ve výchozím nastavení povolené ověřování na základě klíčů. Můžete také povolit ověřování na základě tokenů. Ověřování na základě tokenů vyžaduje, aby klienti používali účet Microsoft Entra k vyžádání ověřovacího tokenu, který se používá k odesílání požadavků na nasazenou službu.
Pokud chcete zakázat ověřování, nastavte auth_enabled=False parametr při vytváření konfigurace nasazení. Následující příklad zakáže ověřování pomocí sady SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
Informace o ověřování z klientské aplikace najdete v modelu Využití počítače Azure Učení nasazeného jako webová služba.
Ověřování pomocí klíčů
Pokud je povolené ověřování pomocí klíče, můžete metodu get_keys použít k načtení primárního a sekundárního ověřovacího klíče:
primary, secondary = service.get_keys()
print(primary)
Důležité
Pokud potřebujete klíč znovu vygenerovat, použijte service.regen_key.
Ověřování pomocí tokenů
Pokud chcete povolit ověřování tokenu token_auth_enabled=True , nastavte parametr při vytváření nebo aktualizaci nasazení. Následující příklad umožňuje ověřování tokenů pomocí sady SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
Pokud je povolené ověřování tokenů, můžete pomocí get_token metody načíst token JWT a čas vypršení platnosti tokenu:
token, refresh_by = service.get_token()
print(token)
Důležité
Po uplynutí doby tokenu refresh_by musíte požádat o nový token.
Microsoft důrazně doporučuje vytvořit pracovní prostor Azure Machine Učení ve stejné oblasti jako cluster AKS. K ověření pomocí tokenu webová služba zavolá oblast, ve které se vytvoří váš pracovní prostor Azure Machine Učení. Pokud oblast vašeho pracovního prostoru není dostupná, nemůžete načíst token pro webovou službu ani v případě, že je váš cluster v jiné oblasti než váš pracovní prostor. Výsledkem je, že ověřování na základě tokenů je nedostupné, dokud nebude oblast vašeho pracovního prostoru opět dostupná. Čím větší je vzdálenost mezi oblastí clusteru a oblastí vašeho pracovního prostoru, tím déle trvá načtení tokenu.
Pokud chcete načíst token, musíte použít sadu Azure Machine Učení SDK nebo příkaz az ml service get-access-token.
Kontrola ohrožení zabezpečení
Microsoft Defender for Cloud poskytuje jednotnou správu zabezpečení a pokročilou ochranu před hrozbami napříč hybridními cloudovými úlohami. Měli byste povolit, aby Microsoft Defender for Cloud kontrolovala vaše prostředky a dodržovala jeho doporučení. Další informace najdete v tématu Zabezpečení kontejnerů v programu Microsoft Defender pro kontejnery.
Související obsah
- Použití řízení přístupu na základě role v Azure pro autorizaci Kubernetes
- Zabezpečení prostředí pro odvozování služby Azure Machine Learning s využitím virtuálních sítí
- Použití vlastního kontejneru k nasazení modelu do online koncového bodu
- Řešení potíží s nasazením vzdáleného modelu
- Aktualizace nasazené webové služby
- Zabezpečení webové služby prostřednictvím služby Azure Machine Learning s využitím protokolu TLS
- Využívání modelu služby Azure Machine Learning nasazeného jako webová služba
- Monitorování a shromažďování dat z koncových bodů webové služby ML
- Shromažďování dat z modelů v produkčním prostředí