Kurz jazyka C#: Použití sad dovedností ke generování prohledávatelného obsahu ve službě Azure AI Search
V tomto kurzu se dozvíte, jak pomocí sady Azure SDK pro .NET vytvořit kanál rozšiřování AI pro extrakci a transformace obsahu během indexování.
Sady dovedností přidávají zpracování umělé inteligence do nezpracovaného obsahu, což zpřístupňuje tento obsah jednotnějším a prohledávatelnějším. Jakmile víte, jak sady dovedností fungují, můžete podporovat širokou škálu transformací: od analýzy obrázků až po zpracování přirozeného jazyka až po přizpůsobené zpracování, které poskytujete externě.
Tento kurz vám pomůže naučit se:
- Definujte objekty v kanálu rozšiřování.
- Vytvořte sadu dovedností. Vyvolání OCR, rozpoznávání jazyka, rozpoznávání entit a extrakce klíčových frází
- Spusťte kanál. Vytvoření a načtení indexu vyhledávání
- Zkontrolujte výsledky pomocí fulltextového vyhledávání.
Pokud nemáte předplatné Azure, otevřete si před zahájením bezplatný účet .
Přehled
Tento kurz používá jazyk C# a klientskou knihovnu Azure.Search.Documents k vytvoření zdroje dat, indexu, indexeru a sady dovedností.
Indexer řídí každý krok v kanálu, počínaje extrakcí obsahu ukázkových dat (nestrukturovaného textu a obrázků) v kontejneru objektů blob ve službě Azure Storage.
Jakmile se obsah extrahuje, sada dovedností provede předdefinované dovednosti od Microsoftu a vyhledá a extrahuje informace. Mezi tyto dovednosti patří optické rozpoznávání znaků (OCR) na obrázcích, rozpoznávání jazyka u textu, extrakce klíčových frází a rozpoznávání entit (organizace). Nové informace vytvořené sadou dovedností se posílají do polí v indexu. Po naplnění indexu můžete použít pole v dotazech, omezujících vlastností a filtrech.
Požadavky
Poznámka:
Pro účely tohoto kurzu můžete použít bezplatnou vyhledávací službu. Úroveň Free vás omezuje na tři indexy, tři indexery a tři zdroje dat. V tomto kurzu se vytváří od každého jeden. Než začnete, ujistěte se, že máte ve službě místo pro přijetí nových prostředků.
Stažení souborů
Stáhněte si soubor ZIP ukázkového úložiště dat a extrahujte obsah. Zjistěte jak.
Nahrání ukázkových dat do Azure Storage
Ve službě Azure Storage vytvořte nový kontejner a pojmenujte ho jako ukázku vyhledávání.
Získejte připojovací řetězec úložiště, abyste mohli formulovat připojení ve službě Azure AI Search.
Na levé straně vyberte Přístupové klávesy.
Zkopírujte připojovací řetězec pro klíč jeden nebo dva. Připojovací řetězec se podobá následujícímu příkladu:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Služby Azure AI
Integrované rozšiřování AI je podporováno službami Azure AI, včetně služeb language a Azure AI Vision pro zpracování přirozeného jazyka a obrázků. U malých úloh, jako je tento kurz, můžete použít bezplatné přidělení 20 transakcí na indexer. U větších úloh připojte prostředek azure AI Services pro více oblastí ke sadě dovedností s cenami průběžných plateb.
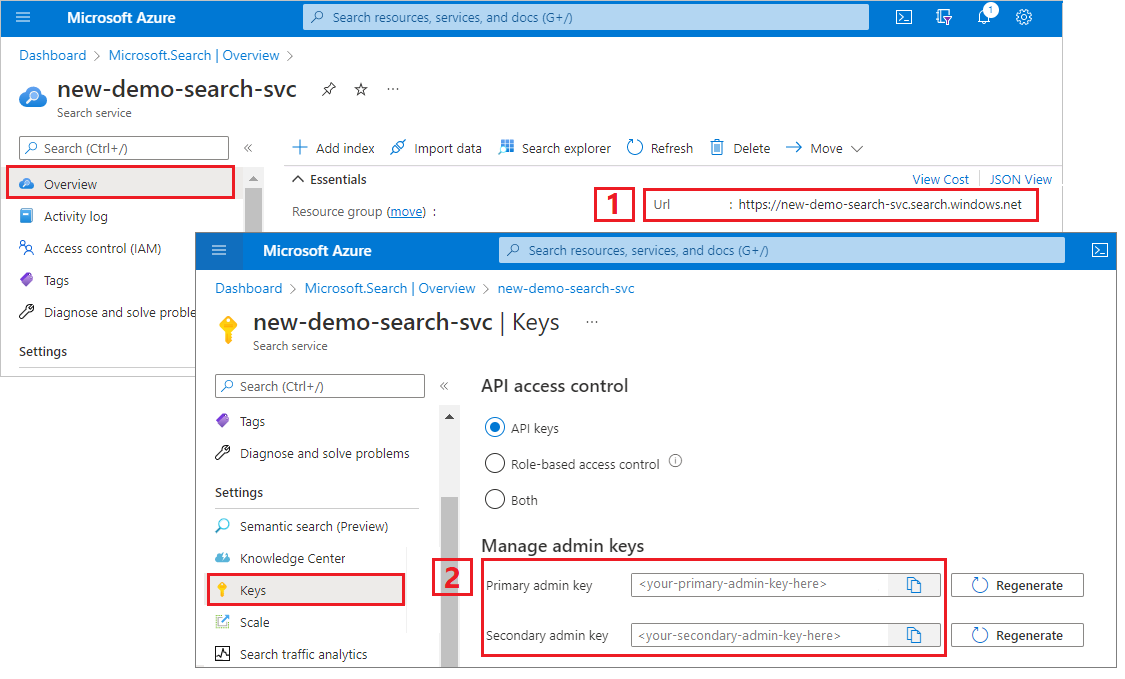
Zkopírování adresy URL vyhledávací služby a klíče rozhraní API
Pro účely tohoto kurzu vyžadují připojení ke službě Azure AI Search koncový bod a klíč rozhraní API. Tyto hodnoty můžete získat z webu Azure Portal.
Přihlaste se k webu Azure Portal, přejděte na stránku Přehled vyhledávací služby a zkopírujte adresu URL. Příkladem koncového bodu může být
https://mydemo.search.windows.net.V části Nastavení> Klíče zkopírujte klíč správce. Správa klíče slouží k přidávání, úpravám a odstraňování objektů. Existují dva zaměnitelné klíče správce. Zkopírujte jeden z nich.
Nastavení prostředí
Začněte otevřením sady Visual Studio a vytvořením nového projektu konzolové aplikace, který se dá spustit v .NET Core.
Instalace Azure.Search.Documents
Sada .NET SDK služby Azure AI Search se skládá z klientské knihovny, která umožňuje spravovat indexy, zdroje dat, indexery a sady dovedností a také nahrávat a spravovat dokumenty a spouštět dotazy, a to vše bez nutnosti zabývat se podrobnostmi HTTP a JSON. Tato klientská knihovna se distribuuje jako balíček NuGet.
Pro tento projekt nainstalujte verzi 11 nebo novější Azure.Search.Documents a nejnovější verzi Microsoft.Extensions.Configuration.
V sadě Visual Studio vyberte Nástroje>NuGet Správce balíčků> Nabídky NuGet pro řešení...
Vyhledejte Azure.Search.Document.
Vyberte nejnovější verzi a pak vyberte Nainstalovat.
Opakujte předchozí kroky a nainstalujte Microsoft.Extensions.Configuration a Microsoft.Extensions.Configuration.Json.
Přidání informací o připojení služby
Klikněte pravým tlačítkem na projekt v Průzkumník řešení a vyberte Přidat>novou položku... .
Pojmenujte soubor
appsettings.jsona vyberte Přidat.Tento soubor zahrňte do výstupního adresáře.
- Klikněte pravým tlačítkem myši a
appsettings.jsonvyberte Vlastnosti. - Pokud je novější, změňte hodnotu kopírovat do výstupního adresáře.
- Klikněte pravým tlačítkem myši a
Zkopírujte následující JSON do nového souboru JSON.
{ "SearchServiceUri": "<YourSearchServiceUri>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "SearchServiceQueryApiKey": "<YourSearchServiceQueryApiKey>", "AzureAIServicesKey": "<YourMultiRegionAzureAIServicesKey>", "AzureBlobConnectionString": "<YourAzureBlobConnectionString>" }
Přidejte informace o vyhledávací službě a účtu úložiště objektů blob. Vzpomeňte si, že tyto informace můžete získat z kroků zřizování služeb uvedených v předchozí části.
Do pole SearchServiceUri zadejte úplnou adresu URL.
Přidání oborů názvů
Do Program.cspole přidejte následující obory názvů.
using Azure;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Microsoft.Extensions.Configuration;
using System;
using System.Collections.Generic;
using System.Linq;
namespace EnrichwithAI
Vytvoření klienta
Vytvořte instanci a SearchIndexClient pod Mainpoložkou SearchIndexerClient .
public static void Main(string[] args)
{
// Create service client
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceUri = configuration["SearchServiceUri"];
string adminApiKey = configuration["SearchServiceAdminApiKey"];
string azureAiServicesKey = configuration["AzureAIServicesKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
SearchIndexerClient indexerClient = new SearchIndexerClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
}
Poznámka:
Klienti se připojují k vaší vyhledávací službě. Pokud chcete zabránit otevírání příliš velkého počtu připojení, měli byste se v případě potřeby pokusit sdílet jednu instanci ve vaší aplikaci. Metody jsou bezpečné pro přístup z více vláken, aby bylo možné takové sdílení povolit.
Přidání funkce pro ukončení programu během selhání
Tento kurz vám pomůže porozumět jednotlivým krokům kanálu indexování. Pokud dojde k kritickému problému, který brání programu ve vytváření zdroje dat, sady dovedností, indexu nebo indexeru, program vypíše chybovou zprávu a ukončí, aby problém mohl být srozumitelný a vyřešený.
Přidejte ExitProgram ke Main zpracování scénářů, které vyžadují ukončení programu.
private static void ExitProgram(string message)
{
Console.WriteLine("{0}", message);
Console.WriteLine("Press any key to exit the program...");
Console.ReadKey();
Environment.Exit(0);
}
Vytvoření kanálu
Ve službě Azure AI Search probíhá zpracování AI během indexování (nebo příjmu dat). Tato část návodu vytvoří čtyři objekty: zdroj dat, definice indexu, sada dovedností, indexer.
Krok 1: Vytvoření zdroje dat
SearchIndexerClientDataSourceName má vlastnost, kterou můžete nastavit na SearchIndexerDataSourceConnection objekt. Tento objekt poskytuje všechny metody, které potřebujete k vytvoření, výpisu, aktualizaci nebo odstranění zdrojů dat Azure AI Search.
Vytvořte novou SearchIndexerDataSourceConnection instanci voláním indexerClient.CreateOrUpdateDataSourceConnection(dataSource). Následující kód vytvoří zdroj dat typu AzureBlob.
private static SearchIndexerDataSourceConnection CreateOrUpdateDataSource(SearchIndexerClient indexerClient, IConfigurationRoot configuration)
{
SearchIndexerDataSourceConnection dataSource = new SearchIndexerDataSourceConnection(
name: "demodata",
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["AzureBlobConnectionString"],
container: new SearchIndexerDataContainer("cog-search-demo"))
{
Description = "Demo files to demonstrate Azure AI Search capabilities."
};
// The data source does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
}
catch (Exception ex)
{
Console.WriteLine("Failed to create or update the data source\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a data source");
}
return dataSource;
}
Pro úspěšný požadavek vrátí metoda vytvořený zdroj dat. Pokud dojde k problému s požadavkem, například neplatným parametrem, vyvolá metoda výjimku.
Teď přidejte řádek Main pro volání CreateOrUpdateDataSource funkce, kterou jste právě přidali.
// Create or Update the data source
Console.WriteLine("Creating or updating the data source...");
SearchIndexerDataSourceConnection dataSource = CreateOrUpdateDataSource(indexerClient, configuration);
Sestavte a spusťte řešení. Vzhledem k tomu, že se jedná o váš první požadavek, zkontrolujte web Azure Portal a ověřte, že se zdroj dat vytvořil ve službě Azure AI Search. Na stránce přehledu vyhledávací služby ověřte, že seznam Zdrojů dat obsahuje novou položku. Možná bude nutné několik minut počkat, než se stránka portálu aktualizuje.

Krok 2: Vytvoření sady dovedností
V této části definujete sadu kroků rozšiřování, které chcete použít pro vaše data. Každý krok rozšiřování se nazývá dovednost a sada kroků rozšiřování, sada dovedností. Tento kurz používá integrované dovednosti pro sadu dovedností:
Optické rozpoznávání znaků pro rozpoznávání tištěného a rukou psaného textu v souborech obrázků.
Sloučení textu ke sloučení textu z kolekce polí do jednoho "sloučeného obsahu" pole.
Rozpoznávání jazyka, které identifikuje jazyk obsahu
Rozpoznávání entit pro extrahování názvů organizací z obsahu v kontejneru objektů blob
Text Split to break large content into smaller chunks before call the key phrase extraction skill and the entity recognition skill. Extrakce klíčových frází a rozpoznávání entit přijímají vstupy o 50 000 znaménky nebo méně. Některé ze zdrojových souborů je nutné rozdělit, aby se do tohoto limitu vešly.
Extrakce klíčových frází, která získává hlavní klíčové fráze
Během počátečního zpracování azure AI Search prolomí každý dokument a extrahuje obsah z různých formátů souborů. Text pocházející ze zdrojového souboru se umístí do vygenerovaného content pole, jedno pro každý dokument. Proto nastavte vstup tak, aby "/document/content" používal tento text. Obsah obrázku se umístí do vygenerovaného normalized_images pole určeného v sadě dovedností jako /document/normalized_images/*.
Výstupy se dají namapovat na index, použít jako vstup do podřízené dovednosti, nebo využít oběma způsoby tak, jak se to dělá s kódem jazyka. V indexu je kód jazyka užitečný při filtrování. Jako vstup se kód jazyka používá v dovednostech analýzy textu, čímž se jazykovým pravidlům poskytne informace o dělení slov.
Další informace o základních principech sady dovedností najdete v článku o definování sady dovedností.
Dovednost OCR
Extrahuje OcrSkill text z obrázků. Tato dovednost předpokládá, že existuje pole normalized_images. Chcete-li toto pole vygenerovat, později v kurzu jsme nastavili "imageAction" konfiguraci v definici indexeru na "generateNormalizedImages".
private static OcrSkill CreateOcrSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("image")
{
Source = "/document/normalized_images/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("text")
{
TargetName = "text"
});
OcrSkill ocrSkill = new OcrSkill(inputMappings, outputMappings)
{
Description = "Extract text (plain and structured) from image",
Context = "/document/normalized_images/*",
DefaultLanguageCode = OcrSkillLanguage.En,
ShouldDetectOrientation = true
};
return ocrSkill;
}
Sloučit dovednosti
V této části vytvoříte MergeSkill pole obsahu dokumentu s textem, který byl vytvořen dovedností OCR.
private static MergeSkill CreateMergeSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/content"
});
inputMappings.Add(new InputFieldMappingEntry("itemsToInsert")
{
Source = "/document/normalized_images/*/text"
});
inputMappings.Add(new InputFieldMappingEntry("offsets")
{
Source = "/document/normalized_images/*/contentOffset"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("mergedText")
{
TargetName = "merged_text"
});
MergeSkill mergeSkill = new MergeSkill(inputMappings, outputMappings)
{
Description = "Create merged_text which includes all the textual representation of each image inserted at the right location in the content field.",
Context = "/document",
InsertPreTag = " ",
InsertPostTag = " "
};
return mergeSkill;
}
Dovednost rozpoznávání jazyka
Rozpozná LanguageDetectionSkill jazyk vstupního textu a hlásí jeden kód jazyka pro každý dokument odeslaný na žádost. Výstup dovednosti rozpoznávání jazyka používáme jako součást vstupu dovednosti Rozdělení textu.
private static LanguageDetectionSkill CreateLanguageDetectionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("languageCode")
{
TargetName = "languageCode"
});
LanguageDetectionSkill languageDetectionSkill = new LanguageDetectionSkill(inputMappings, outputMappings)
{
Description = "Detect the language used in the document",
Context = "/document"
};
return languageDetectionSkill;
}
Dovednost rozdělení textu
SplitSkill Následující text rozdělí podle stránek a omezí délku stránky na 4 000 znaků měřených podle String.Length. Algoritmus se pokusí rozdělit text na bloky, které mají největší maximumPageLength velikost. V tomto případě algoritmus nejlépe rozdělí větu na hranici věty, takže velikost bloku dat může být o něco menší než maximumPageLength.
private static SplitSkill CreateSplitSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("textItems")
{
TargetName = "pages",
});
SplitSkill splitSkill = new SplitSkill(inputMappings, outputMappings)
{
Description = "Split content into pages",
Context = "/document",
TextSplitMode = TextSplitMode.Pages,
MaximumPageLength = 4000,
DefaultLanguageCode = SplitSkillLanguage.En
};
return splitSkill;
}
Dovednost rozpoznávání entit
Tato EntityRecognitionSkill instance je nastavena na rozpoznávání typu organizationkategorie . Lze EntityRecognitionSkill také rozpoznat typy person kategorií a location.
Všimněte si, že pole "context" je nastaveno na "/document/pages/*" hvězdičku, což znamená, že krok rozšiřování se volá pro každou stránku pod "/document/pages".
private static EntityRecognitionSkill CreateEntityRecognitionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("organizations")
{
TargetName = "organizations"
});
EntityRecognitionSkill entityRecognitionSkill = new EntityRecognitionSkill(inputMappings, outputMappings)
{
Description = "Recognize organizations",
Context = "/document/pages/*",
DefaultLanguageCode = EntityRecognitionSkillLanguage.En
};
entityRecognitionSkill.Categories.Add(EntityCategory.Organization);
return entityRecognitionSkill;
}
Dovednost extrakce klíčových frází
Podobně jako instance EntityRecognitionSkill , která byla právě vytvořena, KeyPhraseExtractionSkill se volá pro každou stránku dokumentu.
private static KeyPhraseExtractionSkill CreateKeyPhraseExtractionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("keyPhrases")
{
TargetName = "keyPhrases"
});
KeyPhraseExtractionSkill keyPhraseExtractionSkill = new KeyPhraseExtractionSkill(inputMappings, outputMappings)
{
Description = "Extract the key phrases",
Context = "/document/pages/*",
DefaultLanguageCode = KeyPhraseExtractionSkillLanguage.En
};
return keyPhraseExtractionSkill;
}
Vytvoření a vytvoření sady dovedností
SearchIndexerSkillset Vytvářejte dovednosti, které jste vytvořili.
private static SearchIndexerSkillset CreateOrUpdateDemoSkillSet(SearchIndexerClient indexerClient, IList<SearchIndexerSkill> skills,string azureAiServicesKey)
{
SearchIndexerSkillset skillset = new SearchIndexerSkillset("demoskillset", skills)
{
// Azure AI services was formerly known as Cognitive Services.
// The APIs still use the old name, so we need to create a CognitiveServicesAccountKey object.
Description = "Demo skillset",
CognitiveServicesAccount = new CognitiveServicesAccountKey(azureAiServicesKey)
};
// Create the skillset in your search service.
// The skillset does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateSkillset(skillset);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the skillset\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a skillset");
}
return skillset;
}
Přidejte následující řádky do Main.
// Create the skills
Console.WriteLine("Creating the skills...");
OcrSkill ocrSkill = CreateOcrSkill();
MergeSkill mergeSkill = CreateMergeSkill();
EntityRecognitionSkill entityRecognitionSkill = CreateEntityRecognitionSkill();
LanguageDetectionSkill languageDetectionSkill = CreateLanguageDetectionSkill();
SplitSkill splitSkill = CreateSplitSkill();
KeyPhraseExtractionSkill keyPhraseExtractionSkill = CreateKeyPhraseExtractionSkill();
// Create the skillset
Console.WriteLine("Creating or updating the skillset...");
List<SearchIndexerSkill> skills = new List<SearchIndexerSkill>();
skills.Add(ocrSkill);
skills.Add(mergeSkill);
skills.Add(languageDetectionSkill);
skills.Add(splitSkill);
skills.Add(entityRecognitionSkill);
skills.Add(keyPhraseExtractionSkill);
SearchIndexerSkillset skillset = CreateOrUpdateDemoSkillSet(indexerClient, skills, azureAiServicesKey);
Krok 3: Vytvoření indexu
V tomto oddílu definujete schéma indexu, a to tak, že zadáte, která pole se mají zahrnout do prohledávatelného indexu, a pro jednotlivá pole poskytnete atributy vyhledávání. Pole mají typ a můžou přijímat argumenty, které určují, jak se pole používá (prohledávatelné, seřaditelné apod.). Názvy polí v indexu se nevyžadují, aby se shodovaly s názvy polí ve zdroji. V pozdějším kroku přidáte v indexeru mapování polí, pomocí kterých propojíte zdrojová a cílová pole. Pro tento krok definujte index pomocí konvencí pojmenování relevantních pro vaši vyhledávací aplikaci.
V tomto cvičení použijeme následující pole a jejich typy:
| Názvy polí | Typy polí |
|---|---|
id |
Edm.String |
content |
Edm.String |
languageCode |
Edm.String |
keyPhrases |
List<Edm.String> |
organizations |
List<Edm.String> |
Create DemoIndex – třída
Pole pro tento index jsou definována pomocí třídy modelu. Každá vlastnost třídy modelu má atributy, které určují chování související s vyhledáváním odpovídajícího pole indexu.
Třídu modelu přidáme do nového souboru C#. Pravým tlačítkem myši vyberte projekt a vyberte Přidat>novou položku..., vyberte "Třída" a pojmenujte soubor DemoIndex.csa pak vyberte Přidat.
Ujistěte se, že chcete používat typy z oborů Azure.Search.Documents.Indexes názvů a System.Text.Json.Serialization oborů názvů.
Do stejného oboru názvů, do DemoIndex.cs kterého vytvoříte index, přidejte následující definici třídy modelu a vložte ji do stejného oboru názvů.
using Azure.Search.Documents.Indexes;
using System.Text.Json.Serialization;
namespace EnrichwithAI
{
// The SerializePropertyNamesAsCamelCase is currently unsupported as of this writing.
// Replace it with JsonPropertyName
public class DemoIndex
{
[SearchableField(IsSortable = true, IsKey = true)]
[JsonPropertyName("id")]
public string Id { get; set; }
[SearchableField]
[JsonPropertyName("content")]
public string Content { get; set; }
[SearchableField]
[JsonPropertyName("languageCode")]
public string LanguageCode { get; set; }
[SearchableField]
[JsonPropertyName("keyPhrases")]
public string[] KeyPhrases { get; set; }
[SearchableField]
[JsonPropertyName("organizations")]
public string[] Organizations { get; set; }
}
}
Teď, když jste definovali třídu modelu, můžete snadno Program.cs vytvořit definici indexu. Název tohoto indexu bude demoindex. Pokud už index s tímto názvem existuje, odstraní se.
private static SearchIndex CreateDemoIndex(SearchIndexClient indexClient)
{
FieldBuilder builder = new FieldBuilder();
var index = new SearchIndex("demoindex")
{
Fields = builder.Build(typeof(DemoIndex))
};
try
{
indexClient.GetIndex(index.Name);
indexClient.DeleteIndex(index.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified index not exist, 404 will be thrown.
}
try
{
indexClient.CreateIndex(index);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the index\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without an index");
}
return index;
}
Během testování můžete zjistit, že se pokoušíte vytvořit index více než jednou. Z tohoto důvodu zkontrolujte, jestli index, který se chystáte vytvořit, již existuje, než se ho pokusíte vytvořit.
Přidejte následující řádky do Main.
// Create the index
Console.WriteLine("Creating the index...");
SearchIndex demoIndex = CreateDemoIndex(indexClient);
Přidejte následující příkaz using k vyřešení nejednoznačného odkazu.
using Index = Azure.Search.Documents.Indexes.Models;
Další informace o konceptech indexu najdete v tématu Vytvoření indexu (REST API).
Krok 4: Vytvoření a spuštění indexeru
Do této chvíle jste vytvořili zdroj dat, sadu dovedností a index. Tyto tři komponenty se stanou součástí indexeru, který jednotlivé části sestaví do jediné operace s více fázemi. Pokud je chcete sloučit do indexeru, musíte nadefinovat mapování polí.
Mapování zdrojových polí ze zdroje dat na cílová pole v indexu se zpracovávají před sadou dovedností. Pokud jsou názvy polí a typy na obou koncích stejné, nevyžaduje se žádné mapování.
Výstupní aplikaceFieldMapping se zpracovávají po sadě dovedností odkazující na sourceFieldNames, které neexistují, dokud je nezlomení dokumentu nebo rozšiřování vytvoří. TargetFieldName je pole v indexu.
Kromě připojení vstupů k výstupům můžete také použít mapování polí pro zploštěné datové struktury. Další informace naleznete v tématu Jak mapovat rozšířená pole na prohledávatelný index.
private static SearchIndexer CreateDemoIndexer(SearchIndexerClient indexerClient, SearchIndexerDataSourceConnection dataSource, SearchIndexerSkillset skillSet, SearchIndex index)
{
IndexingParameters indexingParameters = new IndexingParameters()
{
MaxFailedItems = -1,
MaxFailedItemsPerBatch = -1,
};
indexingParameters.Configuration.Add("dataToExtract", "contentAndMetadata");
indexingParameters.Configuration.Add("imageAction", "generateNormalizedImages");
SearchIndexer indexer = new SearchIndexer("demoindexer", dataSource.Name, index.Name)
{
Description = "Demo Indexer",
SkillsetName = skillSet.Name,
Parameters = indexingParameters
};
FieldMappingFunction mappingFunction = new FieldMappingFunction("base64Encode");
mappingFunction.Parameters.Add("useHttpServerUtilityUrlTokenEncode", true);
indexer.FieldMappings.Add(new FieldMapping("metadata_storage_path")
{
TargetFieldName = "id",
MappingFunction = mappingFunction
});
indexer.FieldMappings.Add(new FieldMapping("content")
{
TargetFieldName = "content"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/organizations/*")
{
TargetFieldName = "organizations"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/keyPhrases/*")
{
TargetFieldName = "keyPhrases"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/languageCode")
{
TargetFieldName = "languageCode"
});
try
{
indexerClient.GetIndexer(indexer.Name);
indexerClient.DeleteIndexer(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified indexer not exist, 404 will be thrown.
}
try
{
indexerClient.CreateIndexer(indexer);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the indexer\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without creating an indexer");
}
return indexer;
}
Přidejte následující řádky do Main.
// Create the indexer, map fields, and execute transformations
Console.WriteLine("Creating the indexer and executing the pipeline...");
SearchIndexer demoIndexer = CreateDemoIndexer(indexerClient, dataSource, skillset, demoIndex);
Očekáváme, že dokončení zpracování indexeru nějakou dobu trvá. I když je sada dat malá, analytické dovednosti jsou výpočetně náročné. Některé dovednosti, třeba analýza obrazu, trvají dlouho.
Tip
Vytvoření indexeru vyvolá kanál. Pokud dojde k nějakému problému při komunikaci s daty, při mapování vstupů a výstupů nebo s pořadím operací, zobrazí se v této fázi.
Prozkoumání vytváření indexeru
Kód se nastaví "maxFailedItems" na -1, který dává modulu indexování pokyn, aby při importu dat ignoroval chyby. To je užitečné, protože v ukázkovém zdroji dat je velmi málo dokumentů. Pro větší zdroje dat by tato hodnota byla větší než 0.
Všimněte si také, že "dataToExtract" je nastavena na "contentAndMetadata". Tento příkaz dává indexeru pokyn, aby automaticky extrahoval obsah z různých formátů souborů, stejně jako metadata, která s jednotlivými soubory souvisí.
Když se extrahuje obsah, můžete nastavit imageAction, aby se z obrázků nalezených ve zdroji dat extrahoval text. Sada "imageAction" na "generateNormalizedImages" konfiguraci v kombinaci s dovedností OCR a dovedností při slučování textu říká indexeru, aby extrahoval text z obrázků (například slovo "stop" z znaménka zastavení provozu) a vložil ho jako součást pole obsahu. Toto chování platí jak pro obrázky vložené do dokumentů (třeba obrázek v souboru PDF), tak pro obrázky nalezené ve zdroji dat, např. soubor JPG.
Monitorování indexování
Až se indexer nadefinuje, automaticky se spustí, až se odešle požadavek. V závislosti na tom, které dovednosti jste definovali, může indexování trvat déle, než očekáváte. Pokud chcete zjistit, jestli je indexer stále spuštěný, použijte metodu GetStatus .
private static void CheckIndexerOverallStatus(SearchIndexerClient indexerClient, SearchIndexer indexer)
{
try
{
var demoIndexerExecutionInfo = indexerClient.GetIndexerStatus(indexer.Name);
switch (demoIndexerExecutionInfo.Value.Status)
{
case IndexerStatus.Error:
ExitProgram("Indexer has error status. Check the Azure Portal to further understand the error.");
break;
case IndexerStatus.Running:
Console.WriteLine("Indexer is running");
break;
case IndexerStatus.Unknown:
Console.WriteLine("Indexer status is unknown");
break;
default:
Console.WriteLine("No indexer information");
break;
}
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to get indexer overall status\n Exception message: {0}\n", ex.Message);
}
}
demoIndexerExecutionInfo představuje aktuální stav a historii spuštění indexeru.
Upozornění jsou běžná u některých kombinací zdrojových souborů a dovedností a ne vždy značí problém. V tomto kurzu jsou upozornění neškodná (např. v souboru JPEG nejsou žádné textové vstupy).
Přidejte následující řádky do Main.
// Check indexer overall status
Console.WriteLine("Check the indexer overall status...");
CheckIndexerOverallStatus(indexerClient, demoIndexer);
Hledání
V konzolových aplikacích Azure AI Search obvykle přidáváme 2sekundové zpoždění před spuštěním dotazů, které vrací výsledky, ale protože dokončení rozšiřování trvá několik minut, zavřeme konzolovou aplikaci a místo toho použijeme jiný přístup.
Nejjednodušší možností je Průzkumník služby Search na portálu. Nejprve můžete spustit prázdný dotaz, který vrátí všechny dokumenty, nebo cílenější hledání, které vrací nový obsah pole vytvořený kanálem.
Na webu Azure Portal na stránce Přehled vyhledávání vyberte Indexy.
Najděte
demoindexv seznamu. Mělo by mít 14 dokumentů. Pokud je počet dokumentů nulový, indexer je stále spuštěný nebo se stránka ještě neaktualizovala.Vyberte možnost
demoindex. Průzkumník služby Search je první karta.Obsah je možné prohledávat hned po načtení prvního dokumentu. Pokud chcete ověřit, jestli obsah existuje, spusťte nespecifikovaný dotaz kliknutím na Tlačítko Hledat. Tento dotaz vrátí všechny aktuálně indexované dokumenty a poskytne vám představu o tom, co index obsahuje.
V dalším kroku vložte následující řetězec, abyste lépe spravitelně řídili výsledky:
search=*&$select=id, languageCode, organizations
Resetování a opětovné spuštění
V počátečních experimentálních fázích vývoje je nejproktičtějším přístupem k iteraci návrhu odstranit objekty z Azure AI Search a umožnit kódu jejich opětovné sestavení. Názvy prostředků jsou jedinečné. Když se objekt odstraní, je možné ho znovu vytvořit se stejným názvem.
Vzorový kód pro tento kurz zkontroluje existující objekty a odstraní je, abyste mohli znovu spustit kód. Pomocí portálu můžete také odstranit indexy, indexery, zdroje dat a sady dovedností.
Shrnutí
V tomto kurzu jsme si ukázali základní kroky pro vytvoření rozšířeného kanálu indexování prostřednictvím vytváření součástí součástí: zdroje dat, sady dovedností, indexu a indexeru.
Předdefinované dovednosti byly zavedeny spolu s definicí sady dovedností a mechanikou zřetězování dovedností prostřednictvím vstupů a výstupů. Také jste se dozvěděli, že outputFieldMappings v definici indexeru se vyžaduje směrování obohacených hodnot z kanálu do prohledávatelného indexu v Search Azure AI.
Nakonec jste se dozvěděli, jak testovat výsledky a resetovat systém pro další iterace. Zjistili jste, že zasílání dotazů na index vrací výstup vytvořený kanálem rozšířeného indexování. K tomu všemu jste se naučili, jak zkontrolovat stav indexeru a které objekty se mají před opětovným spuštěním kanálu odstranit.
Vyčištění prostředků
Když pracujete ve vlastním předplatném, je na konci projektu vhodné odebrat prostředky, které už nepotřebujete. Prostředky, které necháte spuštěné, vás stojí peníze. Prostředky můžete odstraňovat jednotlivě nebo můžete odstranit skupinu prostředků, a odstranit tak celou sadu prostředků najednou.
Prostředky můžete najít a spravovat na portálu pomocí odkazu Všechny prostředky nebo skupiny prostředků v levém navigačním podokně.
Další kroky
Teď, když jste obeznámeni se všemi objekty v kanálu rozšiřování AI, se podrobněji podíváme na definice sady dovedností a individuální dovednosti.