Odhad a správa kapacity vyhledávací služby
Ve službě Azure AI Search je kapacita založená na replikách a oddílech, které je možné škálovat na vaši úlohu. Repliky jsou kopie vyhledávacího webu. Oddíly jsou jednotky úložiště. Každá nová vyhledávací služba začíná jednou, ale repliky a oddíly můžete přidávat nebo odebírat nezávisle tak, aby vyhovovaly proměnlivým úlohám. Přidání kapacity zvyšuje náklady na provoz vyhledávací služby.
Fyzické charakteristiky replik a oddílů, jako je rychlost zpracování a vstupně-výstupní operace disku, se liší podle úrovně služby. Ve standardní vyhledávací službě jsou repliky a oddíly rychlejší a větší než repliky základní služby.
Změna kapacity není okamžitá. Provizi nebo vyřazení oddílů z provozu může trvat až hodinu, zejména u služeb s velkým množstvím dat.
Při škálování vyhledávací služby si můžete vybrat z následujících nástrojů a přístupů:
Koncepty: jednotky vyhledávání, repliky, oddíly, horizontální oddíly
Kapacita se vyjadřuje v jednotkáchvyhledávání, které je možné přidělit kombinací oddílů a replik pomocí základního mechanismu horizontálního dělení , který podporuje flexibilní konfigurace:
| Koncepce | Definice |
|---|---|
| Jednotka vyhledávání | Jeden přírůstek celkové dostupné kapacity (36 jednotek). Je to také fakturační jednotka Search Azure AI. Ke spuštění služby se vyžaduje minimálně jedna jednotka. |
| Replika | Instance vyhledávací služby, které se používají především k vyrovnávání zatížení operací dotazů. Každá replika hostuje jednu kopii indexu. Pokud přidělíte tři repliky, máte k dispozici tři kopie indexu pro žádosti o obsluhu dotazů. |
| Oddíl | Fyzické úložiště a vstupně-výstupní operace pro operace čtení a zápisu (například při opětovném sestavení nebo aktualizaci indexu) Každý oddíl má řez celkového indexu. Pokud přidělíte tři oddíly, index se rozdělí na třetí oddíly. |
| Střep | Blok indexu Azure AI Search rozdělí jednotlivé indexy na horizontální oddíly, aby se proces přidávání oddílů zrychlil (přesunutím horizontálních oddílů do nových jednotek vyhledávání). |
Následující diagram znázorňuje vztah mezi replikami, oddíly, horizontálními oddíly a jednotkami vyhledávání. Ukazuje příklad, jak se jeden index rozděluje do čtyř jednotek hledání ve službě se dvěma replikami a dvěma oddíly. Každý ze čtyř jednotek vyhledávání ukládá pouze polovinu horizontálních oddílů indexu. Vyhledávací jednotky v levém sloupci ukládají první polovinu horizontálních oddílů, které tvoří první oddíl, zatímco ty v pravém sloupci ukládají druhou polovinu horizontálních oddílů, které tvoří druhý oddíl. Vzhledem k tomu, že existují dvě repliky, existují dvě kopie každého horizontálního oddílu indexu. Jednotky vyhledávání v horním řádku ukládají jednu kopii, která tvoří první repliku, zatímco ty v dolním řádku ukládají další kopii, která tvoří druhou repliku.
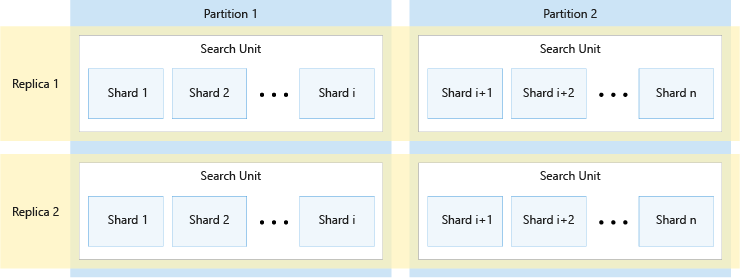
Výše uvedený diagram je pouze jedním příkladem. Je možné použít mnoho kombinací oddílů a replik, maximálně 36 celkového počtu jednotek vyhledávání.
Ve službě Azure AI Search je správa horizontálních oddílů podrobností implementace a nekonfigurovatelná, ale znalost horizontálního dělení indexu pomáhá pochopit občasné anomálie při řazení a chování automatického dokončování:
Anomálie řazení: Skóre hledání se nejprve počítají na úrovni horizontálních oddílů a pak se agregují do jedné sady výsledků. V závislosti na vlastnostech obsahu horizontálních oddílů můžou být shody z jednoho horizontálního oddílu seřazené výš než shody v druhém. Pokud si všimnete čítačů intuitivního řazení ve výsledcích hledání, je to s největší pravděpodobností způsobeno vlivem horizontálního dělení, zejména pokud jsou indexy malé. Těmto anomáliím řazení se můžete vyhnout tím, že se rozhodnete vypočítat skóre globálně v celém indexu, ale tím dojde k penalizaci výkonu.
Automatické dokončování anomálií: Automatické dokončování dotazů, ve kterých jsou shody provedeny na prvních několika znacích částečně zadaného termínu, přijměte přibližný parametr, který odpouští malé odchylky v pravopisu. U automatického dokončování je přibližné porovnávání omezené na termíny v rámci aktuálního horizontálního oddílu. Pokud například horizontální oddíl obsahuje "Microsoft" a zadá se částečný termín "mikro", bude vyhledávací modul v tomto horizontálním oddílu odpovídat hodnotě Microsoft, ale ne v jiných horizontálních oddílech, které obsahují zbývající části indexu.
Cíle odhadu
Plánování kapacity musí zahrnovat limity objektů (například maximální počet indexů povolených pro službu) a limity úložiště. Úroveň služby určuje limity objektů a úložiště. Podle toho, který limit je dosažen jako první, je efektivní limit.
Počty indexů a dalších objektů jsou obvykle diktovány obchodními a technickými požadavky. Můžete mít například více verzí stejného indexu pro aktivní vývoj, testování a produkci.
Požadavky na úložiště jsou určeny velikostí indexů, které očekáváte při sestavování. Neexistují žádné pevné heuristické ani generality, které pomáhají s odhady. Jediný způsob, jak určit velikost indexu, je jeden z nich. Jeho velikost bude založena na importovaných datech, analýze textu a konfiguraci indexu, například na tom, jestli povolíte návrhy, filtrování a řazení.
Pro fulltextové vyhledávání je primární datová struktura invertovanou strukturou indexu , která má jiné vlastnosti než zdrojová data. U invertovaného indexu se velikost a složitost určují obsahem, ne nutně množstvím dat, která do něj vytáčíte. Velký zdroj dat s vysokou redundancí může mít za následek menší index než menší datovou sadu, která obsahuje vysoce proměnlivý obsah. Proto je zřídka možné odvodit velikost indexu na základě velikosti původní datové sady.
Atributy v indexu, například povolení filtrů a řazení, ovlivňují požadavky na úložiště. Použití svrhovačů má také vliv na úložiště. Další informace naleznete v tématu Atributy a velikost indexu.
Poznámka:
I když odhad budoucích potřeb indexů a úložiště může vypadat jako odhad, stojí za to. Pokud je kapacita vrstvy příliš nízká, budete muset zřídit novou službu na vyšší úrovni a pak znovu načíst indexy. Neexistuje žádný místní upgrade služby z jedné vrstvy na jinou.
Odhad s úrovní Free
Jedním z přístupů k odhadu kapacity je začít s úrovní Free. Nezapomeňte, že bezplatná služba nabízí až tři indexy, 50 MB úložiště a 2 minuty času indexování. S těmito omezeními může být obtížné odhadnout projektovanou velikost indexu, ale toto jsou tyto kroky:
Připravte malou reprezentativní datovou sadu.
Vytvořte index a načtěte data. Pokud je možné datovou sadu hostovat ve zdroji dat Azure podporovaném indexery, můžete k vytvoření a načtení indexu použít průvodce importem dat na portálu . V opačném případě můžete pomocí rozhraní REST API vytvořit index a odeslat data. Model nabízených oznámení vyžaduje, aby data byla ve formě dokumentů JSON, kde pole v dokumentu odpovídají polím v indexu.
Shromážděte informace o indexu, například velikost. Funkce a atributy ovlivňují úložiště. Pokud například přidáte návrhy (dotazy typu hledání při psaní), zvýší se požadavky na úložiště.
Pomocí stejné datové sady můžete zkusit vytvořit více verzí indexu s různými atributy v jednotlivých polích, abyste zjistili, jak se požadavky na úložiště liší. Další informace najdete v tématu Důsledky úložiště v části Vytvoření základního indexu.
S hrubým odhadem můžete tuto částku zdvojnásobit na rozpočet pro dva indexy (vývoj a produkci) a pak odpovídajícím způsobem zvolit úroveň.
Odhad s fakturovatelnou úrovní
Vyhrazené prostředky můžou během vývoje pojmout větší vzorkování a dobu zpracování pro realističtější odhady množství, velikosti a objemů dotazů indexu. Někteří zákazníci přeskočí přímo s fakturovatelnou úrovní a pak znovu vyhodnotí, jak se vývojový projekt vyvíjí.
Zkontrolujte limity služeb na jednotlivých úrovních a zjistěte, jestli nižší úrovně můžou podporovat požadovaný počet indexů. Limity indexů na úrovních Basic, S1 a S2 jsou 15, 50 a 200. Úroveň Optimalizováno pro úložiště má limit 10 indexů, protože je navržená tak, aby podporovala nízký počet velmi velkých indexů.
Vytvoření služby na fakturovatelné úrovni:
- Pokud si nejste jistí, jestli si nejste jistí, jestli máte projektované zatížení, začněte nízkou úrovní úrovně Basic nebo S1.
- Pokud testování zahrnuje rozsáhlé indexování a načítání dotazů, začněte vysoko na úrovni S2 nebo dokonce S3.
- Pokud indexujete velké množství dat a zatížení dotazů je relativně nízké, začněte s optimalizací úložiště v L1 nebo L2, stejně jako u interní obchodní aplikace.
Vytvořte počáteční index , abyste zjistili, jak se zdrojová data překládají na index. Toto je jediný způsob, jak odhadnout velikost indexu.
Monitorujte úložiště, limity služeb, objem dotazů a latenci na portálu. Na portálu se zobrazují dotazy za sekundu, omezené dotazy a latence vyhledávání. Všechny tyto hodnoty vám můžou pomoct rozhodnout, jestli jste vybrali správnou úroveň.
Přidejte repliky pro vysokou dostupnost nebo zmírníte nízký výkon dotazů.
Neexistují žádné pokyny k tomu, kolik replik je potřeba k přizpůsobení zatížení dotazů. Výkon dotazů závisí na složitosti dotazu a konkurenčních úlohách. I když přidávání replik jasně vede k lepšímu výkonu, výsledek není striktně lineární: přidání tří replik nezaručuje trojitou propustnost. Pokyny k odhadu QPS pro vaše řešení najdete v tématu Analýza výkonua monitorování dotazů.
Poznámka:
Požadavky na úložiště se dají nafouknout, pokud zahrnete data, která se nikdy nebudou prohledávat. V ideálním případě dokumenty obsahují jenom data, která potřebujete pro vyhledávání. Binární data se nedají prohledávat a měly by se ukládat samostatně (třeba v tabulce Azure nebo v úložišti objektů blob). Do indexu by se pak mělo přidat pole, které bude obsahovat odkaz na adresu URL externích dat. Maximální velikost individuálního vyhledávacího dokumentu je 16 MB (nebo méně, pokud hromadně nahráváte více dokumentů v jednom požadavku). Další informace najdete v tématu Omezení služeb ve službě Azure AI Search.
Důležité informace o objemu dotazů
Dotazy za sekundu (QPS) jsou důležitou metrikou při ladění výkonu, ale pro plánování kapacity se stává důležitým aspektem pouze v případě, že na začátku očekáváte velký objem dotazů.
Úrovně Standard můžou poskytovat rovnováhu mezi replikami a oddíly. Dotaz můžete zvýšit přidáním replik pro vyrovnávání zatížení nebo přidáním oddílů pro paralelní zpracování. Po zřízení služby pak můžete ladit výkon.
Pokud od počátku očekáváte vysoce udržitelné svazky dotazů, měli byste zvážit vyšší úrovně Standard, které jsou podporovány výkonnějším hardwarem. Oddíly a repliky pak můžete převést do režimu offline nebo dokonce přepnout na službu nižší vrstvy, pokud k těmto svazkům dotazů nedojde. Další informace o výpočtu propustnosti dotazů najdete v tématu Monitorování dotazů.
Úrovně Optimalizované pro úložiště jsou užitečné pro velké datové úlohy, které podporují celkově dostupné úložiště indexů, pokud jsou požadavky na latenci dotazů méně důležité. Pro vyrovnávání zatížení a další oddíly pro paralelní zpracování byste stále měli používat další repliky. Po zřízení služby pak můžete ladit výkon.
Smlouvy o úrovni služeb
Funkce úrovně Free a Preview se nevztahují na smlouvy o úrovni služeb (SLA). U všech fakturovatelných úrovní se smlouvy SLA projeví při zřizování dostatečné redundance pro vaši službu. Pro smlouvy SLA pro dotazy (čtení) potřebujete dvě nebo více replik. Pro smlouvy SLA pro dotazy a indexování (čtení i zápis) potřebujete tři nebo více replik. Počet oddílů nemá vliv na smlouvy SLA.
Tipy pro plánování kapacity
Umožňuje metrikám vytvářet dotazy a shromažďovat data o vzorech využití (dotazy během pracovní doby, indexování mimo špičku). Tato data slouží k informování o rozhodnutích o zřizování služeb. I když to není praktické po hodinách nebo denním tempu, můžete dynamicky upravit oddíly a prostředky tak, aby vyhovovaly plánovaným změnám ve svazcích dotazů. Můžete také pojmout neplánované, ale trvalé změny, pokud jsou úrovně dostatečně dlouhé, aby bylo možné přijmout opatření.
Mějte na paměti, že jedinou nevýhodou zřizování je, že pokud jsou skutečné požadavky větší než vaše předpovědi, možná budete muset službu rozdělit. Abyste se vyhnuli přerušení služeb, vytvoříte novou službu na vyšší úrovni a spustíte ji vedle sebe, dokud všechny aplikace a požadavky nebudou cílit na nový koncový bod.
Kdy přidat kapacitu
Na začátku je služba přidělena minimální úroveň prostředků sestávající z jednoho oddílu a jedné repliky. Zvolená úroveň určuje velikost a rychlost oddílu a každá vrstva se optimalizuje kolem sady charakteristik, které odpovídají různým scénářům. Pokud zvolíte vyšší úroveň, možná budete potřebovat méně oddílů , než kdybyste přešli s S1. Jednou z otázek, na které budete muset odpovědět prostřednictvím samoobslužného testování, je to, jestli větší a dražší oddíl přináší lepší výkon než dva levnější oddíly ve službě zřízené na nižší úrovni.
Jedna služba musí mít dostatek prostředků pro zpracování všech úloh (indexování a dotazů). Žádná úloha se nespustí na pozadí. Indexování můžete naplánovat pro časy, kdy jsou požadavky dotazů přirozeně méně časté, ale služba jinak nebude upřednostňovat jeden úkol před druhým. Kromě toho určité množství redundance vyloučí výkon dotazů, když se služby nebo uzly aktualizují interně.
Mezi pokyny pro určení, jestli přidat kapacitu, patří:
- Splnění kritérií vysoké dostupnosti pro smlouvu o úrovni služeb
- Četnost chyb HTTP 503 se zvyšuje.
- Očekává se velké objemy dotazů.
Obecně platí, že vyhledávací aplikace obvykle potřebují více replik než oddíly, zejména pokud jsou operace služby zkreslené vůči úlohám dotazů. Každá replika je kopie indexu, která službě umožňuje vyrovnávat zatížení požadavků na více kopií. Azure AI Search spravuje veškeré vyrovnávání zatížení a replikaci indexu a počet replik přidělených vaší službě můžete kdykoli změnit. Ve standardní vyhledávací službě můžete přidělit až 12 replik a 3 repliky ve vyhledávací službě Basic. Přidělení repliky je možné provést buď z webu Azure Portal , nebo z některé z programových možností.
Aplikace vyhledávání, které vyžadují aktualizaci dat téměř v reálném čase, budou potřebovat proporcionálně více oddílů než repliky. Přidáním oddílů se rozdělí operace čtení a zápisu do většího počtu výpočetních prostředků. Poskytuje také více místa na disku pro ukládání dalších indexů a dokumentů.
Dotazování větších indexů trvá déle. Můžete například zjistit, že každé přírůstkové zvýšení oddílů vyžaduje menší, ale proporcionální zvýšení replik. Složitost dotazů a objemu dotazů se projeví v tom, jak rychle se mění provádění dotazů.
Poznámka:
Přidání dalších replik nebo oddílů zvyšuje náklady na provoz služby a může představovat mírné odchylky způsobu řazení výsledků. Nezapomeňte zkontrolovat cenovou kalkulačku, abyste pochopili důsledky fakturace při přidávání dalších uzlů. Následující graf vám může pomoct křížově odkazovat na počet jednotek hledání požadovaných pro konkrétní konfiguraci. Další informace o tom, jak další repliky ovlivňují zpracování dotazů, najdete v tématu Řazení výsledků.
Přidání nebo omezení replik a oddílů
Přihlaste se k webu Azure Portal a vyberte vyhledávací službu.
V části Nastavení otevřete stránku Škálování a upravte repliky a oddíly.
Následující snímek obrazovky ukazuje úroveň Basic Standard zřízenou s jednou replikou a oddílem. Vzorec v dolní části označuje, kolik jednotek hledání se používá (1). Pokud by jednotková cena byla 100 USD (nikoli reálná cena), měsíční náklady na provoz této služby by byly v průměru 100 USD.
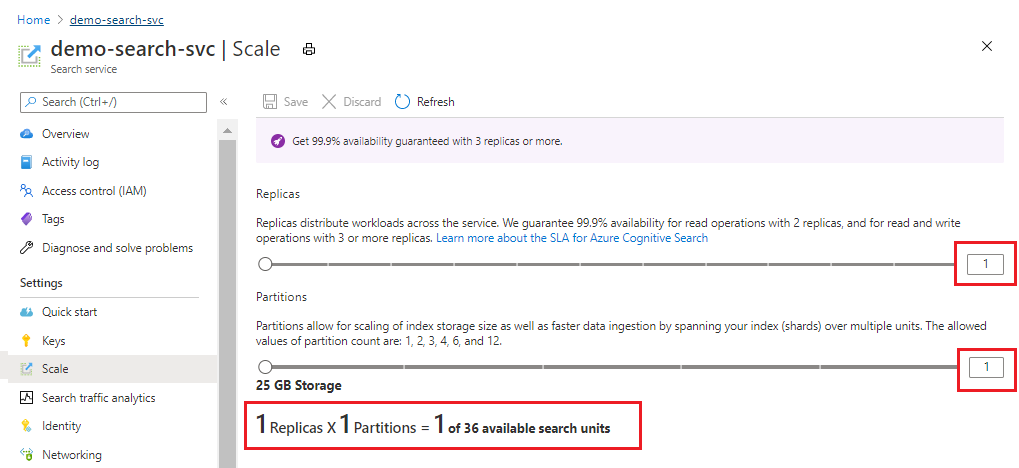
Pomocí posuvníku můžete zvýšit nebo snížit počet oddílů. Zvolte Uložit.
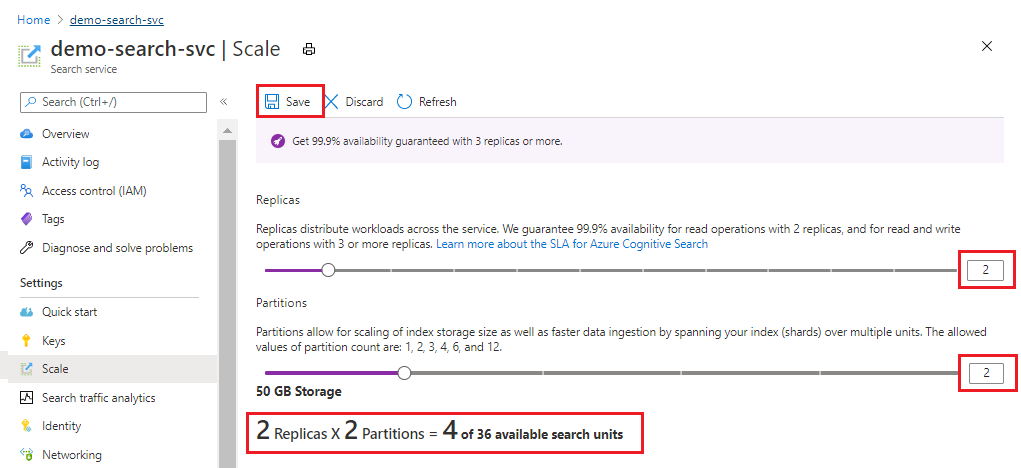
Tento příklad přidá druhou repliku a oddíl. Všimněte si počtu jednotek vyhledávání; je teď čtyři, protože fakturační vzorec je replikovaný oddíly (2 x 2). Zdvojnásobení kapacity více než zdvojnásobí náklady na provoz služby. Pokud by náklady na jednotku vyhledávání byly 100 USD, nová měsíční faktura by teď byla 400 USD.
Aktuální náklady na jednotku jednotlivých úrovní najdete na stránce Ceny.
Po uložení můžete zkontrolovat oznámení a potvrdit, že akce proběhla úspěšně.
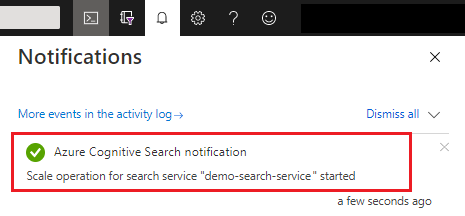
Dokončení změn kapacity může trvat 15 minut až několik hodin. Po spuštění procesu není možné zrušit žádné monitorování repliky a oddílů v reálném čase. Následující zpráva ale zůstane viditelná, i když jsou změny probíhající.

Poznámka:
Po zřízení služby se nedá upgradovat na vyšší úroveň. Na nové úrovni musíte vytvořit vyhledávací službu a znovu načíst indexy. Nápovědu ke zřizování služeb najdete v tématu Vytvoření Search Azure AI na portálu.
Jak se zpracovávají žádosti o škálování
Po přijetí žádosti o škálování vyhledávací služba:
- Zkontroluje, jestli je požadavek platný.
- Spustí zálohování dat a systémových informací.
- Zkontroluje, jestli je služba již ve stavu zřizování (aktuálně přidává nebo odstraňuje repliky nebo oddíly).
- Spustí zřizování.
Škálování služby může trvat až 15 minut nebo déle než hodinu v závislosti na velikosti služby a rozsahu požadavku. Zálohování může trvat několik minut v závislosti na množství dat a počtu oddílů a replik.
Výše uvedené kroky nejsou zcela po sobě jdoucí. Systém například spustí zřizování, když to může bezpečně provést, což může být v době, kdy se zálohování vyřazují.
Chyby při škálování
Chybová zpráva Operace aktualizace služby nejsou v tuto chvíli povoleny, protože zpracováváme předchozí požadavek, je způsobená opakováním žádosti o vertikální snížení nebo navýšení kapacity, když služba už zpracovává předchozí požadavek.
Vyřešte tuto chybu tak, že zkontrolujete stav služby a ověříte stav zřizování:
- K získání stavu služby použijte rozhraní REST API pro správu, Azure PowerShell nebo Azure CLI.
- Volání služby Get Service (REST) nebo ekvivalentní pro PowerShell nebo rozhraní příkazového řádku
- Zkontrolujte odpověď na "provisioningState": "provisioning" (zřizování).
Pokud je stav Zřizování, počkejte na dokončení požadavku. Než se pokusíte o další požadavek, stav by měl být Úspěšný nebo Neúspěšný. Pro zálohování neexistuje žádný stav. Zálohování je interní operace a není pravděpodobné, že by to bylo faktorem jakéhokoli přerušení cvičení škálování.
Pokud se zdá, že vyhledávací služba je ve stavu zřizování zastavená, zkontrolujte, jestli nejsou osamocené indexy nepoužitelné, s nulovými objemy dotazů a bez aktualizací indexu. Nepoužitelný index může blokovat změny kapacity služby. Hledejte zejména indexy, které jsou zašifrované pomocí klíče CMK, jejichž klíče už nejsou platné. Index byste měli odstranit nebo obnovit klíče, aby se index vrátil do režimu online a odblokuje se operace škálování.
Kombinace oddílů a replik
Ve vyhledávacích službách vytvořených před 3. dubnem 2024: Basic může mít přesně jeden oddíl a až tři repliky pro maximální limit tří jednotek SU. Jediný upravitelný prostředek je repliky.
Ve vyhledávacích službách vytvořených po 3. dubnu 2024 v podporovaných oblastech: Basic může mít až tři oddíly a tři repliky. Maximální limit SU je devět, aby podporoval úplný doplněk oddílů a replik.
Pro vyhledávací služby na libovolné fakturovatelné úrovni bez ohledu na datum vytvoření potřebujete minimálně dvě repliky pro zajištění vysoké dostupnosti dotazů.
Všechny vyhledávací služby optimalizované pro standard a úložiště mohou předpokládat následující kombinace replik a oddílů, které jsou pro tyto úrovně povolené limitem 36 SU.
| 1 oddíl | 2 oddíly | 3 oddíly | 4 oddíly | 6 oddílů | 12 oddílů | |
|---|---|---|---|---|---|---|
| 1 replika | 1 SU | 2 SU | 3 SU | 4 SU | 6 SU | 12 SU |
| 2 repliky | 2 SU | 4 SU | 6 SU | 8 SU | 12 SU | 24 SU |
| 3 repliky | 3 SU | 6 SU | 9 SU | 12 SU | 18 SU | 36 SU |
| 4 repliky | 4 SU | 8 SU | 12 SU | 16 SU | 24 SU | – |
| 5 replik | 5 SU | 10 SU | 15 SU | 20 SU | 30 SU | – |
| 6 replik | 6 SU | 12 SU | 18 SU | 24 SU | 36 SU | – |
| 12 replik | 12 SU | 24 SU | 36 SU | – | – | N/A |
SU, ceny a kapacita jsou podrobně vysvětlené na webu Azure. Další informace najdete v tématu Podrobnosti o cenách.
Poznámka:
Počet replik a oddílů se rovnoměrně dělí na 12 (konkrétně 1, 2, 3, 4, 6, 12). Azure AI Search předem rozdělí každý index na 12 horizontálních oddílů, aby se mohl rozdělit do stejných částí napříč všemi oddíly. Pokud má například vaše služba tři oddíly a vytvoříte index, každý oddíl bude obsahovat čtyři horizontální oddíly indexu. Způsob horizontálního dělení indexu ve službě Azure AI Search představuje podrobnosti implementace, které se můžou v budoucích verzích změnit. I když je číslo dnes 12, neměli byste očekávat, že by toto číslo v budoucnu vždy bylo 12.