přehled příjmu dat Azure Synapse Data Explorer (Preview)
Příjem dat je proces, který se používá k načtení datových záznamů z jednoho nebo více zdrojů za účelem importu dat do tabulky ve fondu Azure Synapse Data Explorer. Po ingestování budou data k dispozici pro dotaz.
Služba Azure Synapse Data Explorer pro správu dat, která je zodpovědná za příjem dat, implementuje následující proces:
- Načítá data v dávkách nebo streamování z externího zdroje a čte požadavky z čekající fronty Azure.
- Dávkové toky dat do stejné databáze a tabulky jsou optimalizované pro propustnost příjmu dat.
- Počáteční data se ověří a v případě potřeby se převede formát.
- Další manipulace s daty, včetně párování schématu, uspořádání, indexování, kódování a komprese dat
- Data se v úložišti uchovávají v souladu s nastavenými zásadami uchovávání informací.
- Ingestovaná data se potvrdí do modulu, kde jsou k dispozici pro dotazy.
Podporované formáty dat, vlastnosti a oprávnění
Vlastnosti příjmu dat: Vlastnosti, které ovlivňují způsob příjmu dat (například označování, mapování, čas vytvoření).
Oprávnění: K ingestování dat vyžaduje proces oprávnění na úrovni ingestoru databáze. Jiné akce, jako je dotaz, můžou vyžadovat oprávnění správce databáze, uživatele databáze nebo správce tabulky.
Dávkování vs. příjem dat streamování
Dávkový příjem dat provádí dávkování a je optimalizovaný pro vysokou propustnost příjmu dat. Tato metoda je upřednostňovaným a nejvýkonnějším typem příjmu dat. Data jsou dávková podle vlastností příjmu dat. Malé dávky dat se slučují a optimalizují pro rychlé výsledky dotazů. Zásady dávkování příjmu dat je možné nastavit pro databáze nebo tabulky. Ve výchozím nastavení je maximální hodnota dávkování 5 minut, 1 000 položek nebo celková velikost 1 GB. Limit velikosti dat pro příkaz dávkového příjmu dat je 4 GB.
Ingestování streamování je průběžný příjem dat ze streamovaného zdroje. Příjem dat streamování umožňuje latenci téměř v reálném čase u malých sad dat na tabulku. Data se nejprve ingestují do úložiště řádků a pak se přesunou do rozsahů úložiště sloupců.
Metody a nástroje pro příjem dat
Azure Synapse Data Explorer podporuje několik metod příjmu dat, z nichž každá má vlastní cílové scénáře. Mezi tyto metody patří nástroje pro příjem dat, konektory a moduly plug-in pro různé služby, spravované kanály, programový příjem dat pomocí sad SDK a přímý přístup k příjmu dat.
Příjem dat pomocí spravovaných kanálů
Pro organizace, které chtějí mít správu (omezování, opakování, monitorování, upozornění a další) prováděnou externí službou, je pravděpodobně nejvhodnějším řešením použití konektoru. Příjem dat ve frontě je vhodný pro velké objemy dat. Azure Synapse Data Explorer podporuje následující služby Azure Pipelines:
- Centrum událostí: Kanál, který přenáší události ze služeb do Azure Synapse Data Explorer. Další informace najdete v tématu Příjem dat z centra událostí do Azure Synapse Data Explorer.
- Kanály Synapse: Plně spravovaná služba integrace dat pro analytické úlohy v kanálech Synapse se připojuje k více než 90 podporovaným zdrojům, aby poskytovala efektivní a odolný přenos dat. Kanály Synapse připraví, transformují a obohacují data a poskytují tak přehledy, které je možné monitorovat různými způsoby. Tuto službu je možné použít jako jednorázové řešení, na pravidelné časové ose nebo aktivovat konkrétními událostmi.
Programový příjem dat pomocí sad SDK
Azure Synapse Data Explorer poskytuje sady SDK, které se dají použít pro dotazy a příjem dat. Programový příjem dat je optimalizovaný pro snížení nákladů na příjem dat tím, že minimalizuje transakce úložiště během procesu příjmu dat a jeho sledování.
Než začnete, pomocí následujícího postupu získejte koncové body Data Explorer fondu pro konfiguraci programového příjmu dat.
V Synapse Studio v levém podokně vyberte Spravovat>Data Explorer fondy.
Vyberte fond Data Explorer, který chcete použít k zobrazení jeho podrobností.
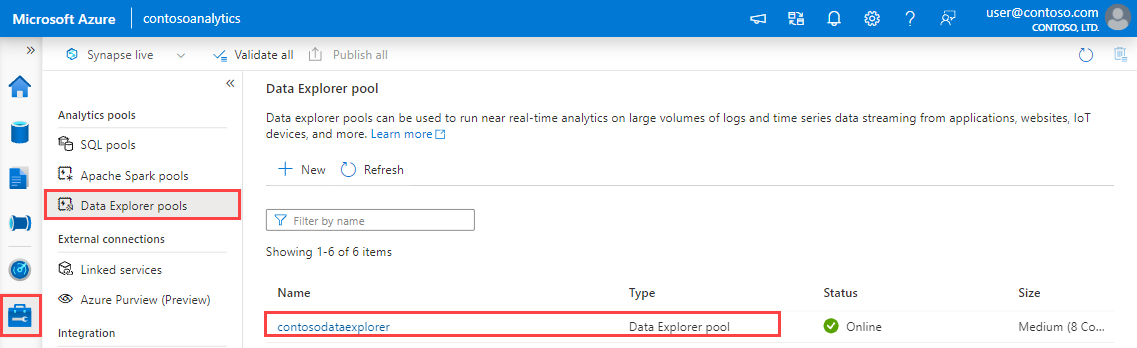
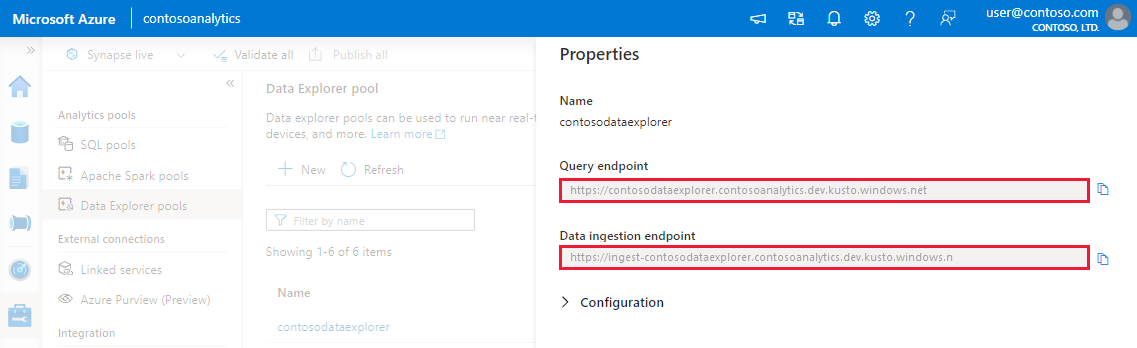
Poznamenejte si koncové body dotazů a příjmu dat. Při konfiguraci připojení k fondu Data Explorer použijte koncový bod dotazu jako cluster. Při konfiguraci sad SDK pro příjem dat použijte koncový bod pro příjem dat.
Dostupné sady SDK a opensourcové projekty
nástroje
- Příjem dat jedním kliknutím: Umožňuje rychle ingestovat data vytvořením a úpravou tabulek ze široké škály zdrojových typů. Příjem dat jedním kliknutím automaticky navrhuje tabulky a struktury mapování na základě zdroje dat v Azure Synapse Data Explorer. Příjem dat jedním kliknutím můžete použít k jednorázovému příjmu dat nebo k definování průběžného příjmu dat prostřednictvím služby Event Grid v kontejneru, do kterého se data ingestovala.
dotazovací jazyk Kusto ovládacích příkazů ingestování
Existuje několik metod, pomocí kterých lze data ingestovat přímo do modulu příkazy dotazovací jazyk Kusto (KQL). Vzhledem k tomu, že tato metoda obchází Správa dat služby, je vhodná pouze pro zkoumání a vytváření prototypů. Tuto metodu nepoužívejte v produkčních nebo velkoobjemových scénářích.
Vložený příjem dat: Řídicí příkaz .ingest inline se odešle do modulu, přičemž data, která se mají ingestovat, jsou součástí samotného textu příkazu. Tato metoda je určena pro improvizované účely testování.
Příjem z dotazu: Řídicí příkaz set, .append, .set-or-append nebo .set-or-replace se odešle do modulu s daty zadanými nepřímo jako výsledky dotazu nebo příkazu.
Ingestování z úložiště (pull): Řídicí příkaz .ingest do se odešle do modulu s daty uloženými v externím úložišti (například Azure Blob Storage) přístupným modulem a odkazem na příkaz.
Příklad použití řídicích příkazů ingestování najdete v tématu Analýza pomocí Data Explorer.
Proces příjmu dat
Jakmile zvolíte nejvhodnější metodu příjmu dat pro vaše potřeby, proveďte následující kroky:
Nastavení zásad uchovávání informací
Data ingestovaná do tabulky v Azure Synapse Data Explorer podléhají efektivním zásadám uchovávání informací v tabulce. Pokud nejsou pro tabulku nastavené explicitně, platné zásady uchovávání informací se odvozují ze zásad uchovávání informací databáze. Horké uchovávání je funkce velikosti clusteru a zásad uchovávání informací. Ingestování více dat, než máte k dispozici, způsobí, že první data v datech zůstanou za studena.
Ujistěte se, že zásady uchovávání informací databáze odpovídají vašim potřebám. Pokud ne, explicitně je přepište na úrovni tabulky. Další informace najdete v tématu Zásady uchovávání informací.
Vytvoření tabulky
Aby bylo možné ingestovat data, je potřeba předem vytvořit tabulku. Použijte jednu z následujících možností:
Vytvořte tabulku pomocí příkazu. Příklad použití příkazu vytvořit tabulku najdete v tématu Analýza pomocí Data Explorer.
Vytvořte tabulku pomocí příjmu dat jedním kliknutím.
Poznámka
Pokud je záznam neúplný nebo pole nelze analyzovat jako požadovaný datový typ, odpovídající sloupce tabulky se naplní hodnotami null.
Vytvoření mapování schématu
Mapování schématu pomáhá svázat zdrojová datová pole se sloupci cílové tabulky. Mapování umožňuje převést data z různých zdrojů do stejné tabulky na základě definovaných atributů. Podporují se různé typy mapování, a to jak řádkově orientované (CSV, JSON a AVRO), tak sloupcově orientované (Parquet). Ve většině metod lze mapování také předem vytvořit v tabulce a odkazovat na něj z parametru příkazu ingestování.
Nastavení zásad aktualizace (volitelné)
Některá mapování formátu dat (Parquet, JSON a Avro) podporují jednoduché a užitečné transformace v čase ingestování. Pokud scénář vyžaduje složitější zpracování v době příjmu, použijte zásady aktualizace, které umožňují zjednodušené zpracování pomocí příkazů dotazovací jazyk Kusto. Zásady aktualizace automaticky spouští extrakce a transformace pro ingestované data v původní tabulce a ingestují výsledná data do jedné nebo více cílových tabulek. Nastavte zásady aktualizací.