Kurz Lakehouse: Vytváření sestav v Microsoft Fabric
V této části kurzu vytvoříte datový model Power BI a vytvoříte sestavu úplně od začátku.
Požadavky
Vytvoření sestavy
Power BI je nativně integrovaný do celého prostředí Infrastruktury. Tato nativní integrace přináší jedinečný režim, který se nazývá DirectLake, který přistupuje k datům z jezera, aby poskytoval nejvýkonnější prostředí pro dotazy a generování sestav. Režim DirectLake je zásadní schopnost nového motoru analyzovat velmi velké sémantické modely v Power BI. Technologie je založená na myšlence načítání souborů formátovaných parquet přímo z datového jezera, aniž byste museli dotazovat datový sklad nebo koncový bod lakehouse a nemuseli importovat nebo duplikovat data do sémantického modelu Power BI. DirectLake je rychlá cesta k načtení dat z datového jezera přímo do modulu Power BI připraveného k analýze.
V tradičním režimu DirectQuery modul Power BI přímo dotazuje data ze zdroje pro každé spuštění dotazu a výkon dotazu závisí na rychlosti načítání dat. DirectQuery eliminuje potřebu kopírování dat a zajišťuje, aby se všechny změny ve zdroji okamžitě projevily ve výsledcích dotazu. Na druhou stranu je výkon v režimu importu mnohem lepší, protože data jsou snadno dostupná v paměti, aniž by se museli dotazovat na data ze zdroje pro každé spuštění dotazu, ale modul Power BI musí data nejprve zkopírovat do paměti v době aktualizace dat. Všechny změny souvisejícího zdroje dat se vyberou během příští aktualizace dat (v naplánované i na vyžádání).
Režim DirectLake teď eliminuje tento požadavek na import načtením datových souborů přímo do paměti. Vzhledem k tomu, že neexistuje žádný explicitní proces importu, je možné při jejich výskytu vyzvednout všechny změny ve zdroji, a tím zkombinovat výhody DirectQuery a režimu importu a vyhnout se jejich nevýhodám. Režim DirectLake je proto ideální volbou pro analýzu velmi velkých sémantických modelů a sémantických modelů s častými aktualizacemi ve zdroji.
V rozevírací nabídce Lakehouse wwilakehouse vyberte koncový bod analýzy SQL z rozevírací nabídky Lakehouse v pravém horním rohu obrazovky.
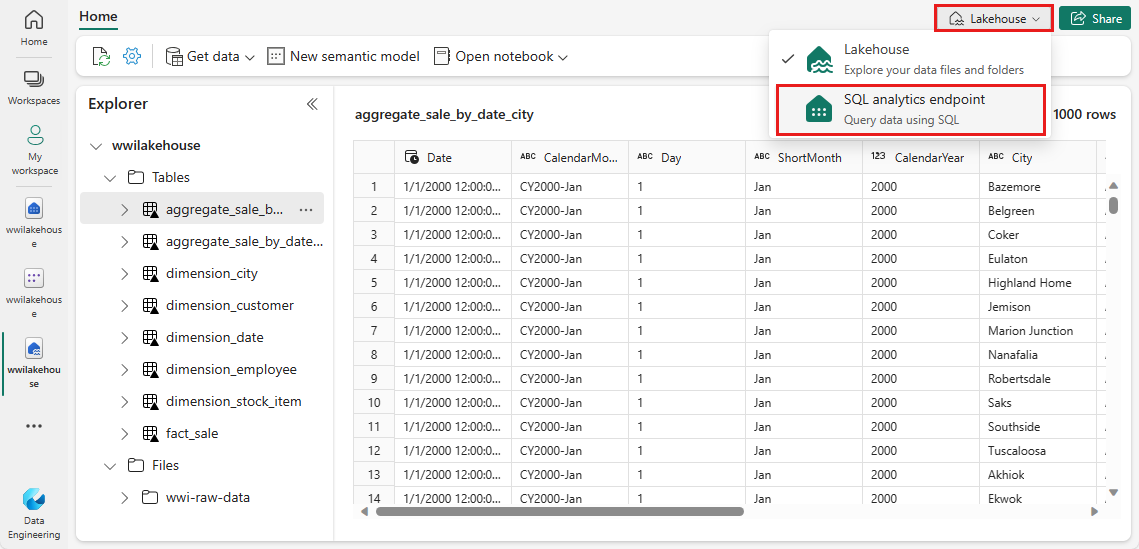
V podokně koncového bodu SQL byste měli být schopni zobrazit všechny tabulky, které jste vytvořili. Pokud je ještě nevidíte, vyberte nahoře ikonu Aktualizovat . Potom výběrem karty Model v dolní části otevřete výchozí sémantický model Power BI.
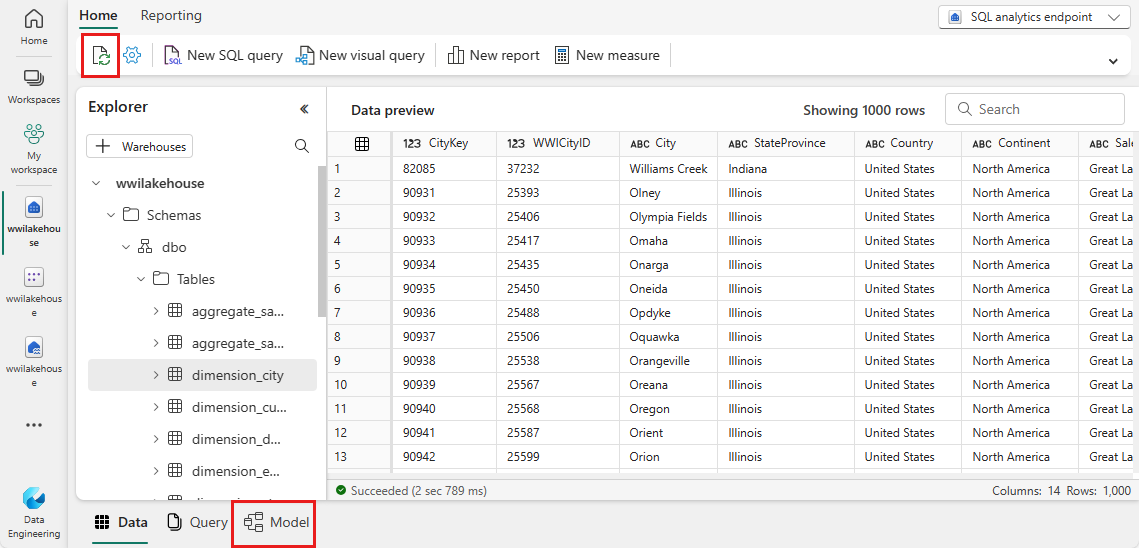
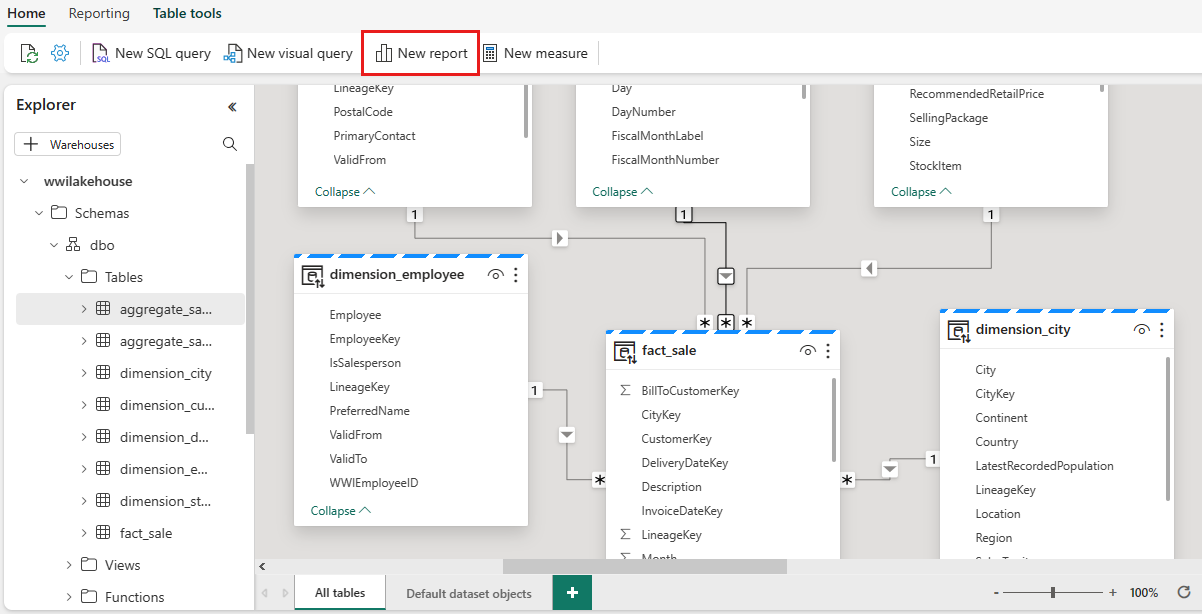
Pro tento datový model je potřeba definovat relaci mezi různými tabulkami, abyste mohli vytvářet sestavy a vizualizace na základě dat přicházejících mezi různými tabulkami. Z tabulky fact_sale přetáhněte pole CityKey do pole CityKey v tabulce dimension_city a vytvořte relaci. Zobrazí se dialogové okno Nová relace .
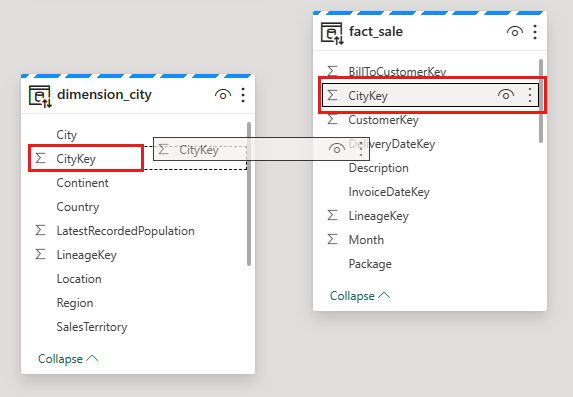
V dialogovém okně Nová relace :
Tabulka 1 se naplní fact_sale a sloupcem CityKey.
Tabulka 2 se naplní dimension_city a sloupcem CityKey.
Kardinalita: Mnoho k jednomu (*:1)
Směr křížového filtru: Jednoduché
Pole vedle možnosti Nastavit tuto relaci jako aktivní ponechte.
Zaškrtněte políčko vedle položky Předpokládat referenční integritu.
Vyberte OK.
Poznámka:
Při definovánírelacích pro tuto sestavu se ujistěte, že máte z tabulky fact_sale (tabulka 1 dimension_) mnoho k jedné relaci (tabulka 2) a ne naopak.
Dále přidejte tyto relace se stejným nastavením nové relace , jak je znázorněno výše, ale s následujícími tabulkami a sloupci:
- StockItemKey(fact_sale) – StockItemKey(dimension_stock_item)
- Salespersonkey(fact_sale) – EmployeeKey(dimension_employee)
- CustomerKey(fact_sale) – CustomerKey(dimension_customer)
- InvoiceDateKey(fact_sale) – Date(dimension_date)
Po přidání těchto relací je datový model připravený k vytváření sestav, jak je znázorněno na následujícím obrázku:
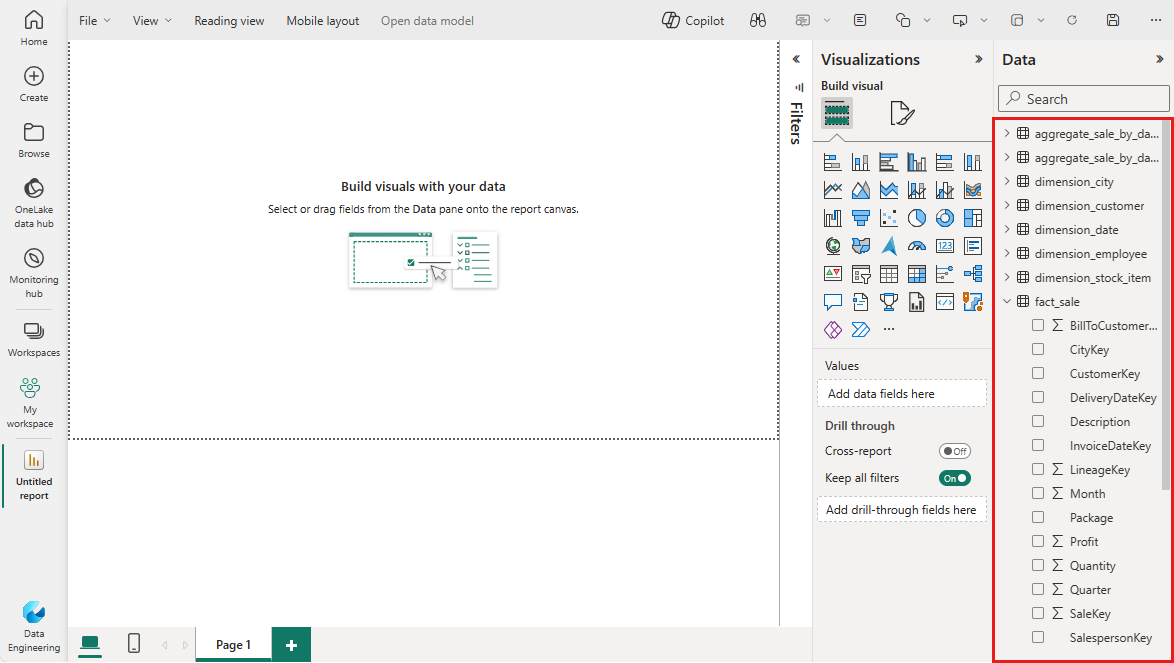
Výběrem možnosti Nová sestava začnete vytvářet sestavy nebo řídicí panely v Power BI. Na plátně sestav Power BI můžete vytvářet sestavy, které splňují vaše obchodní požadavky, přetažením požadovaných sloupců z podokna Data na plátno a použitím jedné nebo více dostupných vizualizací.
Přidejte název:
Na pásu karet vyberte Textové pole.
Typ v WW Importers Profit Reporting.
Zvýrazněte text a zvětšete velikost na 20 a umístěte ho do levého horního rohu stránky sestavy.
Přidání karty:
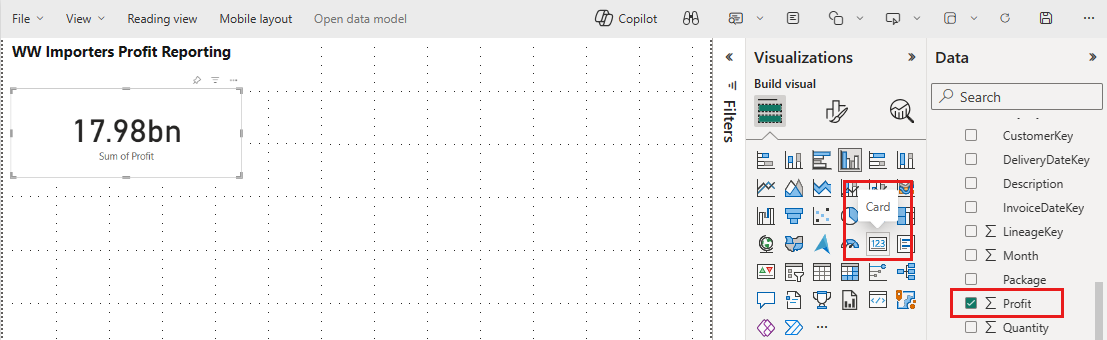
V podokně Data rozbalte fact_sale a zaškrtněte políčko vedle položky Zisk. Tento výběr vytvoří sloupcový graf a přidá pole na osu Y.
Když je graf vybraný, vyberte vizuál Karta v podokně vizualizace. Tento výběr převede vizuál na kartu.
Umístěte kartu pod název.
Přidání pruhového grafu:
V podokně Data rozbalte fact_sales a zaškrtněte políčko vedle položky Zisk. Tento výběr vytvoří sloupcový graf a přidá pole na osu Y.
V podokně Data rozbalte dimension_city a zaškrtněte políčko SalesTerritory. Tento výběr přidá pole na osu Y.
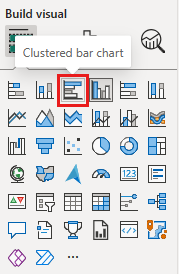
Když je pruhový graf vybraný, vyberte vizuál skupinového pruhového grafu v podokně vizualizace. Tento výběr převede sloupcový graf na pruhový graf.
Změňte velikost pruhového grafu tak, aby vyplnil oblast pod názvem a kartou.
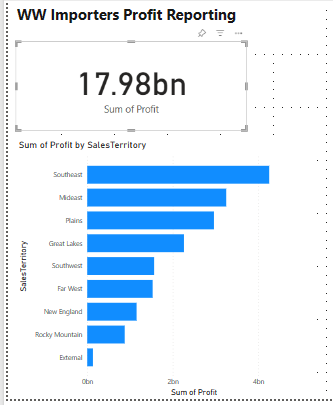
Klikněte na libovolné místo na prázdném plátně (nebo stiskněte klávesu Esc), takže pruhový graf už není vybraný.
Vytvoření vizuálu skládaného plošného grafu:
V podokně Vizualizace vyberte vizuál skládaného plošného grafu.
Změna umístění a změna velikosti skládaného plošného grafu napravo od vizuálů karet a pruhových grafů vytvořených v předchozích krocích
V podokně Data rozbalte fact_sales a zaškrtněte políčko vedle položky Zisk. Rozbalte dimension_date a zaškrtněte políčko vedle položky FiscalMonthNumber. Tento výběr vytvoří vyplněný spojnicový graf zobrazující zisk podle fiskálního měsíce.
V podokně Data rozbalte dimension_stock_item a přetáhněte Pole NákupPackage do pole Legenda. Tento výběr přidá řádek pro každou z nákupních balíčků.
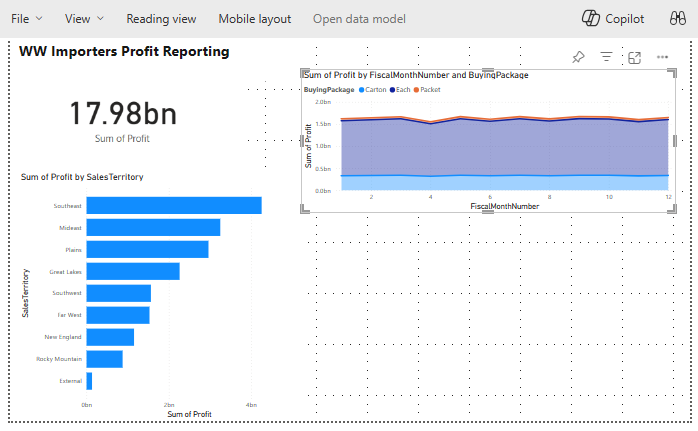
Klikněte na libovolné místo na prázdném plátně (nebo stiskněte klávesu Esc), takže skládaný plošný graf už není vybraný.
Vytvoření sloupcového grafu:
V podokně Vizualizace vyberte vizuál skládaného sloupcového grafu .
V podokně Data rozbalte fact_sales a zaškrtněte políčko vedle položky Zisk. Tento výběr přidá pole na osu Y.
V podokně Data rozbalte dimension_employee a zaškrtněte políčko vedle položky Zaměstnanec. Tento výběr přidá pole na osu X.
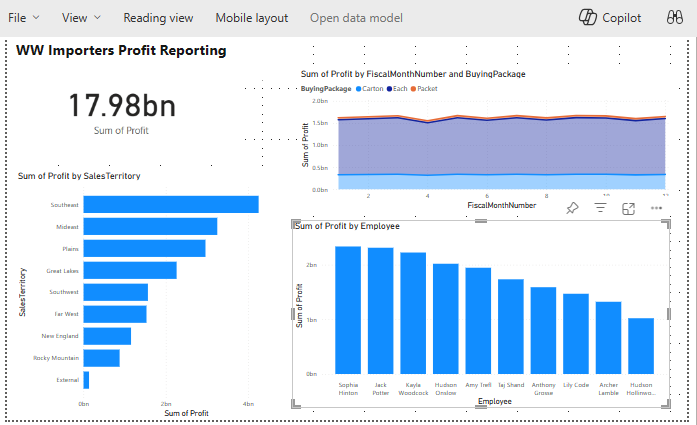
Klikněte na libovolné místo na prázdném plátně (nebo stiskněte klávesu Esc), takže graf už není vybraný.
Na pásu karet vyberte Uložit soubor>.
Jako sestavu zadejte název sestavy.
Zvolte Uložit.


Další krok
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro