Recept: Služby Azure AI – Detekce anomálií s více proměnnými
Tento recept ukazuje, jak můžete používat služby SynapseML a Azure AI v Apache Sparku k detekci anomálií s více proměnnými. Detekce vícevariátových anomálií umožňuje detekci anomálií mezi mnoha proměnnými nebo časovými řadami s ohledem na všechny vzájemné korelace a závislosti mezi různými proměnnými. V tomto scénáři použijeme SynapseML k trénování modelu pro detekci vícevariatických anomálií pomocí služeb Azure AI a pak použijeme k odvozování vícevariatických anomálií v datové sadě obsahující syntetická měření ze tří senzorů IoT.
Důležité
Od 20. září 2023 nebudete moct vytvářet nové Detektor anomálií prostředky. Služba Detektor anomálií se 1. října 2026 vyřadí z provozu.
Další informace o Detektor anomálií Azure AI najdete na této stránce dokumentace.
Požadavky
- Předplatné Azure – Vytvoření předplatného zdarma
- Připojte poznámkový blok k jezeru. Na levé straně vyberte Přidat a přidejte existující jezerní dům nebo vytvořte jezero.
Nastavení
Postupujte podle pokynů k vytvoření Anomaly Detector prostředku pomocí webu Azure Portal nebo případně můžete k vytvoření tohoto prostředku použít Také Azure CLI.
Po nastavení Anomaly Detectormůžete prozkoumat metody zpracování dat různých formulářů. Katalog služeb v rámci Azure AI nabízí několik možností: Vision, Speech, Language, Web Search, Decision, Translation a Document Intelligence.
Vytvoření prostředku Detektor anomálií
- Na webu Azure Portal vyberte Vytvořit ve skupině prostředků a potom zadejte Detektor anomálií. Vyberte prostředek Detektor anomálií.
- Pojmenujte prostředek a v ideálním případě použijte stejnou oblast jako zbytek vaší skupiny prostředků. Použijte výchozí možnosti pro zbytek a pak vyberte Zkontrolovat a vytvořit a pak Vytvořit.
- Jakmile se prostředek Detektor anomálií vytvoří, otevřete ho
Keys and Endpointsa vyberte panel v levém navigačním panelu. Zkopírujte klíč pro Detektor anomálií prostředek doANOMALY_API_KEYproměnné prostředí nebo hoanomalyKeyuložte do proměnné.
Vytvoření prostředku účtu úložiště
Pokud chcete uložit zprostředkující data, musíte vytvořit účet služby Azure Blob Storage. V rámci daného účtu úložiště vytvořte kontejner pro ukládání zprostředkujících dat. Poznamenejte si název kontejneru a zkopírujte připojovací řetězec do tohoto kontejneru. Později ji budete potřebovat k naplnění containerName proměnné a BLOB_CONNECTION_STRING proměnné prostředí.
Zadejte klíče služby.
Začněme nastavením proměnných prostředí pro naše klíče služby. Další buňka nastaví ANOMALY_API_KEY proměnné prostředí a BLOB_CONNECTION_STRING proměnné prostředí na základě hodnot uložených v naší službě Azure Key Vault. Pokud tento kurz spouštíte ve vlastním prostředí, před pokračováním se ujistěte, že jste tyto proměnné prostředí nastavili.
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Teď si můžete přečíst ANOMALY_API_KEY proměnné prostředí a BLOB_CONNECTION_STRING nastavit containerName je a location nastavit.
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Nejprve se připojíme k účtu úložiště, aby detektor anomálií mohl uložit přechodné výsledky tam:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Pojďme naimportovat všechny potřebné moduly.
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
Teď si pojďme ukázková data přečíst do datového rámce Sparku.
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Teď můžeme vytvořit estimator objekt, který se používá k trénování modelu. Určujeme počáteční a koncové časy trénovacích dat. Také určíme vstupní sloupce, které se mají použít, a název sloupce, který obsahuje časová razítka. Nakonec určíme počet datových bodů, které se mají použít v posuvném okně detekce anomálií, a my nastavíme připojovací řetězec na účet služby Azure Blob Storage.
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Teď, když jsme vytvořili estimatorsoubor , se přizpůsobíme datům:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Když jsme volali .show(5) v předchozí buňce, ukázalo nám prvních pět řádků v datovém rámci. Výsledky byly všechny null , protože nebyly uvnitř okna odvození.
Pokud chcete zobrazit výsledky jenom pro odvozená data, vyberte sloupce, které potřebujeme. Potom můžeme řádky v datovém rámci seřadit vzestupně a vyfiltrovat výsledek tak, aby se zobrazily jenom řádky v oblasti okna odvozování. V našem případě inferenceEndTime je stejný jako poslední řádek v datovém rámci, takže to můžete ignorovat.
Aby bylo možné výsledky vykreslit lépe, umožňuje převést datový rámec Sparku na datový rámec Pandas.
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
Naformátujte contributors sloupec, do kterého se uloží skóre příspěvku z každého senzoru, do detekovaných anomálií. Další buňka naformátuje tato data a rozdělí skóre příspěvku každého senzoru do vlastního sloupce.
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Výborně! Nyní máme skóre příspěvků snímačů 1, 2 a 3 v series_0, series_1a series_2 sloupce v uvedeném pořadí.
Spuštěním další buňky vykreslíte výsledky. Parametr minSeverity určuje minimální závažnost anomálií, které se mají vykreslit.
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
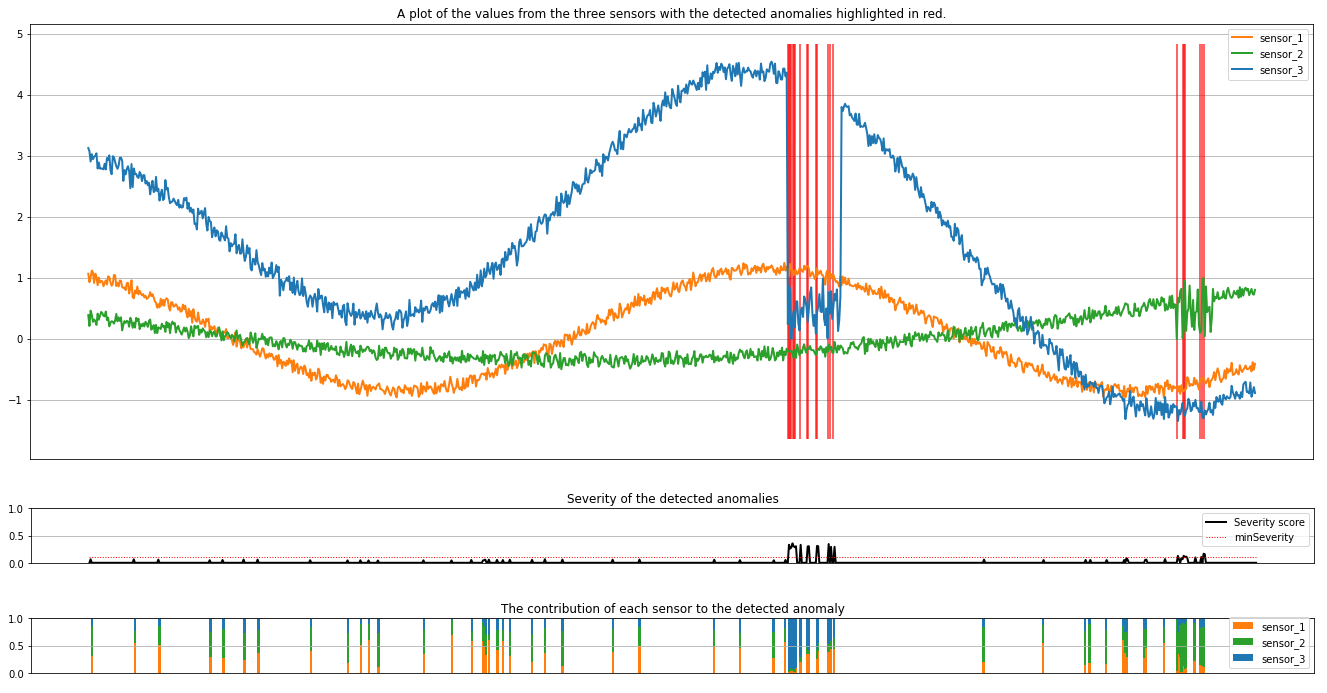
Grafy zobrazují nezpracovaná data ze senzorů (uvnitř okna odvozování) oranžovou, zelenou a modrou. Červené svislé čáry na prvním obrázku ukazují zjištěné anomálie, které mají závažnost větší nebo rovno minSeverity.
Druhý graf zobrazuje skóre závažnosti všech zjištěných anomálií s minSeverity prahovou hodnotou zobrazenou v tečkované červené čáře.
Nakonec poslední graf ukazuje příspěvek dat z každého senzoru ke zjištěným anomáliím. Pomáhá nám diagnostikovat a pochopit nejpravděpodobnější příčinu každé anomálie.
Související obsah
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro