Integrace OneLake s Azure Synapse Analytics
Azure Synapse je neomezená analytická služba, která spojuje podnikové datové sklady a analýzu velkého objemu dat. V tomto kurzu se dozvíte, jak se připojit k OneLake pomocí Azure Synapse Analytics.
Zápis dat ze Synapse pomocí Apache Sparku
Pomocí těchto kroků můžete pomocí Apache Sparku zapisovat ukázková data do OneLake z Azure Synapse Analytics.
Otevřete pracovní prostor Synapse a vytvořte fond Apache Sparku s upřednostňovanými parametry.
Vytvořte nový poznámkový blok Apache Sparku.
Otevřete poznámkový blok, nastavte jazyk na PySpark (Python) a připojte ho k nově vytvořenému fondu Sparku.
Na samostatné kartě přejděte do microsoft Fabric lakehouse a najděte složku Tabulky nejvyšší úrovně.
Klikněte pravým tlačítkem myši na složku Tabulky a vyberte Vlastnosti.
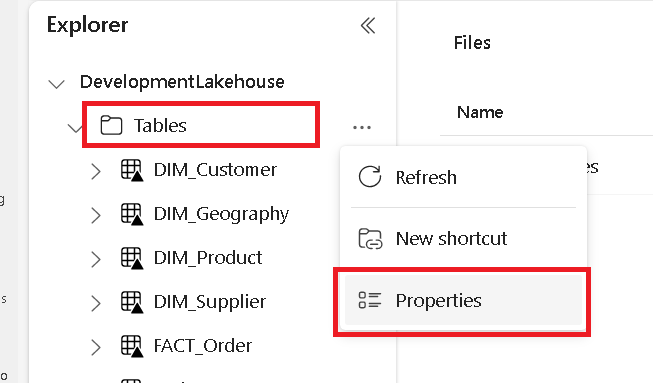
Zkopírujte cestu ABFS z podokna vlastností.
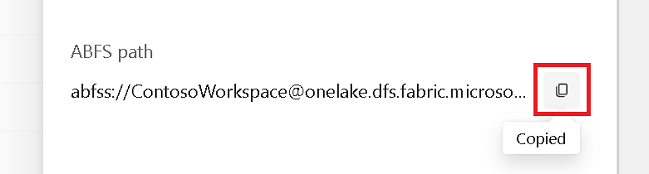
Zpátky v poznámkovém bloku Azure Synapse v první nové buňce kódu zadejte cestu k jezeru. Toto jezero je místo, kde se vaše data zapisuje později. Spusťte buňku.
# Replace the path below with the ABFS path to your lakehouse Tables folder. oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'V nové buňce kódu načtěte data z otevřené datové sady Azure do datového rámce. Tato datová sada je ta, kterou načtete do jezera. Spusťte buňku.
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet') display(yellowTaxiDf.limit(10))V nové buňce kódu, filtrování, transformaci nebo přípravě dat. V tomto scénáři můžete datovou sadu zkrátit a zrychlit načítání, spojovat se s jinými datovými sadami nebo filtrovat podle konkrétních výsledků. Spusťte buňku.
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1) display(filteredTaxiDf.limit(10))V nové buňce kódu pomocí cesty OneLake napište filtrovaný datový rámec do nové tabulky Delta-Parquet ve vašem fabric lakehouse. Spusťte buňku.
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')Nakonec v nové buňce kódu otestujte, že vaše data byla úspěšně zapsána čtením nově načteného souboru z OneLake. Spusťte buňku.
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/') display(lakehouseRead.limit(10))
Blahopřejeme. Teď můžete číst a zapisovat data ve OneLake pomocí Apache Sparku ve službě Azure Synapse Analytics.
Čtení dat ze služby Synapse pomocí SQL
Při čtení dat z OneLake z Azure Synapse Analytics použijte bezserverové SQL.
Otevřete Objekt Fabric Lakehouse a identifikujte tabulku, kterou chcete dotazovat ze služby Synapse.
Klikněte pravým tlačítkem myši na tabulku a vyberte Vlastnosti.
Zkopírujte cestu ABFS pro tabulku.
Otevřete pracovní prostor Synapse v nástroji Synapse Studio.
Vytvořte nový skript SQL.
V editoru dotazů SQL zadejte následující dotaz a nahraďte
ABFS_PATH_HEREcestu, kterou jste zkopírovali dříve.SELECT TOP 10 * FROM OPENROWSET( BULK 'ABFS_PATH_HERE', FORMAT = 'delta') as rows;Spuštěním dotazu zobrazte prvních 10 řádků tabulky.
Blahopřejeme. Teď můžete číst data z OneLake pomocí bezserverového SQL ve službě Azure Synapse Analytics.
Související obsah
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro