Události
Konference komunity Microsoftu 365
6. 5. 14 - 9. 5. 0
Dovednost pro éru umělé inteligence v konečné komunitě řízené Microsoft 365 událostí, 6. května-8 v Las Vegas.
Další informaceTento prohlížeč se už nepodporuje.
Upgradujte na Microsoft Edge, abyste mohli využívat nejnovější funkce, aktualizace zabezpečení a technickou podporu.
Jednoduchý model zpracování dokumentů nabízí flexibilní a předem vytrénované řešení pro extrakci informací ze základních strukturovaných dokumentů, včetně informací, jako jsou:
Páry klíč-hodnota – představte si, jako jsou popisky a odpovídající informace, například "Name: Adele Vance" (Jméno: Adele Vanceová).
Značky výběru – jedná se o zaškrtávací políčka nebo jiné značky, které označují volby nebo výběry v dokumentu.
Pojmenované entity – jedná se o konkrétní položky, jako jsou jména lidí, míst nebo organizací uvedených v textu dokumentu.
Čárové kódy – jedná se o strojově čitelná vyjádření dat, která se dají použít pro účely sledování nebo identifikace v dokumentu.
Na rozdíl od jiných předem připravených modelů s pevnými schématy dokáže tento model identifikovat klíče, které můžou ostatním chybět, a poskytuje cennou alternativu k vlastnímu označování a trénování modelů. Tento model také podporuje čárové kódy a rozpoznávání jazyka.
Jednoduché zpracování dokumentů funguje nejlépe s typy dokumentů, které obsahují strukturované informace, například:
Forms – často mají jasná pole a popisky, což usnadňuje extrakci párů klíč-hodnota.
Faktury – obvykle obsahují konzistentní rozložení s tabulkami a páry klíč-hodnota.
Účtenky – podobně jako faktury mají strukturovaná data, která se dají snadno extrahovat.
Kontrakty – obsahují dobře definované oddíly a klauzule, které je možné efektivně analyzovat.
Bankovní výpisy – zahrnují tabulky a strukturovaná data, která jsou ideální pro extrakci.
Tyto dokumenty těží z možností optického rozpoznávání znaků (OCR) a procesů hlubokého učení, které se používají k extrakci párů klíč-hodnota, výběrových značek, tabulek a pojmenovaných entit.
Poznámka
V současné době je tento model k dispozici pro typy souborů .pdf a obrázků a ve více než 100 jazycích. Další podporované typy souborů budou přidány v budoucích verzích.
Pokud chcete použít jednoduchý model zpracování dokumentů, postupujte takto:
Postupujte podle pokynů v tématu Vytvoření modelu v Syntexu a vytvořte jednoduchý model zpracování dokumentů. Pak pokračujte následujícími kroky a dokončete model.
Na stránce Modely v části Přidat soubor k analýze vyberte Přidat soubor.

Na stránce Soubory pro analýzu modelu vyberte Přidat a vyhledejte soubor, který chcete použít.
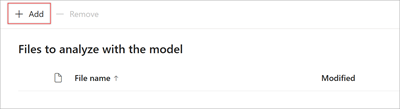
Na stránce Přidat soubor z knihovny trénovacích souborů vyberte soubor a pak vyberte Přidat.
Na stránce Soubory k analýze modelu vyberte Další.
Na stránce podrobností extraktoru uvidíte oblast dokumentu na pravé straně stránky a panel Extraktory na levé straně. Panel Extraktory zobrazuje seznam extraktorů, které byly v dokumentu identifikovány.

Pole entit, která jsou v oblasti dokumentu zvýrazněná zeleně, jsou položky, které model zjistil při analýze souboru. Když vyberete entitu, kterou chcete extrahovat, zvýrazněné pole se změní na modrou. Pokud se později rozhodnete entitu nezahrnovat, zvýrazněné pole se změní na šedé. Zvýraznění usnadňuje zobrazení aktuálního stavu extraktorů, které vyberete.
Tip
Pokud chcete pole entit přiblížit nebo oddálit, použijte kolečko myši nebo ovládací prvky lupy v dolní části oblasti dokumentu.
V závislosti na tom, co preferujete, můžete vybrat extraktor buď v oblasti dokumentu, nebo na panelu Extraktory .
Když vyberete extraktor, zobrazí se v oblasti dokumentu pole Vybrat extraktor? . V poli se zobrazí název klíče (název vygenerovaný pro extraktor), zjištěná hodnota (hodnota tohoto pole v dokumentu), typ sloupce a možnost vybrat entitu jako extraktor.

Název klíče se použije jako název sloupce, když se model použije na knihovnu SharePointu. Pokud chcete, můžete název klíče změnit tak, aby byl popisnější. Typ sloupce ukazuje, jak se informace zobrazují v knihovně. Typ sloupce můžete změnit tak, aby zobrazoval, jak se mají informace zobrazovat. Když se model použije na knihovnu, můžete pomocí formátování sloupců určit, jak má vypadat v dokumentu.
Pokračujte výběrem dalších extraktorů, které chcete použít. Můžete také přidat další soubory pro analýzu této konfigurace modelu.
Existují tři způsoby, jak můžete přejmenovat extraktor:
V oblasti dokumentu na stránce podrobností extraktoru vyberte pole entity. Do pole Vybrat extraktor? zadejte do pole Název klíče nový název extraktoru.
Na panelu Extraktory na stránce s podrobnostmi o extraktoru vyberte extraktor, který chcete přejmenovat, a pak vyberte Přejmenovat.
Na domovské stránce modelu v části Extraktory vyberte extraktor, který chcete přejmenovat, a pak vyberte Přejmenovat.
Pro tento model můžete určit zpracování rozsahu stránek pro soubor místo celého souboru. Na panelu Extraktory vyberte v části Rozsah stránek stránku, kterou chcete zpracovat. Ve výchozím nastavení je nastavení Rozsah stránek prázdné. Pokud není k dispozici žádný rozsah stránek, zpracuje se celý dokument. Další informace najdete v tématu Nastavení rozsahu stránek pro extrahování informací z konkrétních stránek.
U tohoto modelu můžete rozpoznat jazyk dokumentu a extrahovat ho do sloupce. Na panelu Extraktory v části Rozpoznávání jazyka přepněte rozpoznávání jazyka. Zobrazí kód ISO rozpoznaného jazyka.

Rozpoznávání jazyka můžete také zapnout nebo vypnout na panelu Nastavení modelu pro model.
Pokud chcete uložit změny a vrátit se na domovskou stránku modelu, vyberte na panelu Extraktorymožnost Uložit a ukončit.
Pokud jste připravení použít model pro knihovnu, vyberte v oblasti dokumentu Další. Na panelu Přidat do knihovny zvolte knihovnu, do které chcete model přidat, a pak vyberte Přidat.
Informace o typech souborů, jazycích, optickém rozpoznávání znaků a dalších aspektech tohoto předem vytvořeného modelu najdete v tématu Požadavky a omezení pro předem připravené zpracování dokumentů v SharePointu.
Události
Konference komunity Microsoftu 365
6. 5. 14 - 9. 5. 0
Dovednost pro éru umělé inteligence v konečné komunitě řízené Microsoft 365 událostí, 6. května-8 v Las Vegas.
Další informaceŠkolení
Modul
Process custom documents with AI Builder - Training
Explore the fundamentals of AI Builder's Document processing, its benefits to your organization, and its integration with Power Apps.
Certifikace
Certifikace Microsoft: Power Automate RPA Developer Associate - Certifications
Předveďte, jak vylepšit a automatizovat pracovní postupy pomocí vývojáře Microsoft Power Automate RPA.
Dokumentace
Naučte se používat předem vytvořený model kontraktů v Microsoft Syntex.
Naučte se používat předem připravený model faktur v Microsoft Syntex.
Nastavení a správa předem připraveného zpracování dokumentů pro SharePoint - Microsoft Syntex
Zjistěte, jak nastavit a spravovat předem připravené zpracování dokumentů v SharePointu.