Cvičení – vizualizace modelu strojového učení
Jednou z výhod použití klasifikátoru rozhodovacího stromu je vizualizace, kterou můžete použít k lepšímu pochopení způsobu rozhodování modelu. Pomocí graphviz a pydotplus můžete rychle zjistit, jak se rozhodnutí udělalo. V budoucích iteracích uvidíte, jak se rozhodnutí změnila.
Vytvoření vizuálního stromu
Pokud chcete vytvořit vizuální znázornění modelu, vytvoříte funkci, která přijímá jako parametry:
- Data:
tree– model strojového učení - Sloupce:
feature_names– seznam sloupců ve vstupních datech - Výstup:
class_names– seznam možností klasifikace (v tomto případě ano nebo ne) - Název souboru:
png_file_to_save– název souboru, do kterého chcete vizualizaci uložit
Zavoláte funkci export_graphviz() nástroje scikit-learn a potom vrátíte obrazové znázornění grafu, který vám scikit-learn poskytne.
# Let's import a library for visualizing our decision tree.
from sklearn.tree import export_graphviz
def tree_graph_to_png(tree, feature_names,class_names, png_file_to_save):
tree_str = export_graphviz(tree, feature_names=feature_names, class_names=class_names,
filled=True, out_file=None)
graph = pydotplus.graph_from_dot_data(tree_str)
return Image(graph.create_png())
Volání této funkce je poměrně jasné:
- Data:
tree_model– model, který jste trénovali a testovali dříve - Sloupce:
X.columns.values– seznam sloupců ve vstupu - Výstup: [
yes,no] – dva možné výsledky - Název souboru:
decision_tree.png– název souboru, do kterého chcete obrázek uložit
# This function takes a machine learning model and visualizes it.
tree_graph_to_png(tree=tree_model, feature_names=X.columns.values,class_names=['No Launch','Launch'], png_file_to_save='decision-tree.png')
Tato funkce vytvoří následující obrázek.
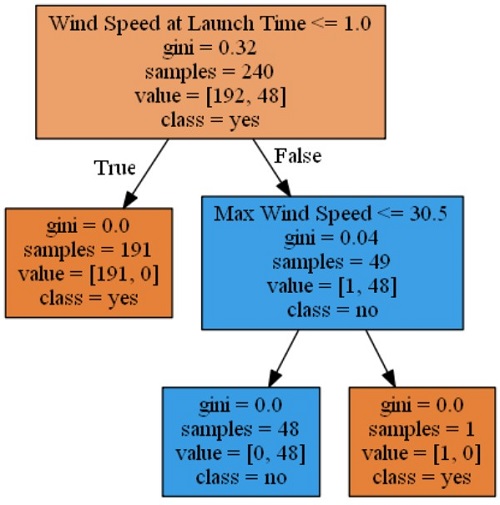
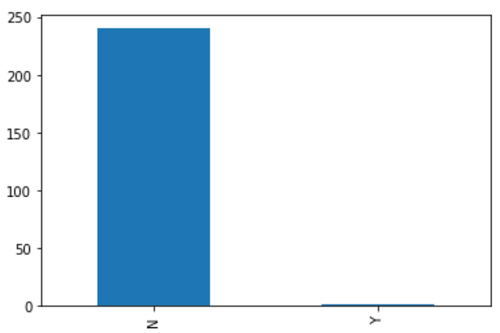
Když se podíváme na datovou sadu, máme celkově 240 vzorků:
- 192 nejsou žádné starty
- 48 jsou starty
Tento výsledek je způsoben naší strategií čištění dat, kdy jsme předpokládali, že všechny dny, které nejsou označené jako nespustí, nejsou dny spuštění.
Pomocí nových popisků můžeme říci: "Pokud rychlost větru byla menší než 1,0, pak 191 z 240 vzorků odhadla, že v daný den nebylo možné spustit." Tento výsledek může vypadat jako lichý, ale na základě dat je správný. Tady jsou důkazy: Vykreslili jsme start a distribuci bez startu pro dny, kdy rychlost větru při startu <= 1 před vyřazením sloupce dříve v tomto poznámkovém bloku. Ukazuje, že pro téměř všechny časy, kdy nespustíme:
Pochopení vizualizace
Tento jednoduchý strom vám ukáže, že nejdůležitější funkce dat byla Wind Speed at Launch Time. Pokud byla rychlost větru menší než 1,0, pak u 191 vzorků z 240 bylo správně uhodnuto, že ke startu nedojde. Zjistili jsme, že 191 z těchto vzorků potřebovalo ke správnému uhodnutí výsledku jenom to, aby hodnota Wind Speed at Launch Time byla menší než 1,0, zatímco nad 1,0 bylo potřeba více informací.
Tento přehled není dobrý. Dříve jsme nastavili všechny hodnoty, které byly prázdné, na 0. Víme také, že mnoho hodnot, které se vztahovaly k době startu, bylo 0, protože 60 % našich dat nesouviselo se skutečným startem nebo pokusem o start.
Když se dále podíváte na stromovou strukturu, uvidíte, že Max Wind Speed je druhá nejdůležitější funkce těchto dat. Zde vidíte, že ze zbývajících 49 dnů, kdy maximální rychlost větru byla menší než 30,5, 48 dnů přinesl správný výstup startu a jeden přinesl výstup bez startu.
Tato data by mohla být zajímavější s nějakou skutečnou situací. Byl zjištěn pouze jeden den, kdy byl start naplánovaný a hodnota Max Wind Speed byla větší než 30,5, což bylo 27. května 2020. Start rakety Space X Dragon byl tehdy odložen na 30. května 2020. Tady je důkaz:
launch_data[(launch_data['Wind Speed at Launch Time'] > 1) & (launch_data['Max Wind Speed'] > 30.5)]

Vylepšení výsledků
V této vizualizaci jste viděli, že některé funkce se staly důležitými. Ale tento důraz vycházel z nesprávných informací.
Jedním z vylepšení, které je možné udělat, je určit vztah mezi Max Wind Speed a Wind Speed at Launch Time pro řádky, které tyto informace obsahují. Místo toho, abyste parametr Wind Speed at Launch Time nastavili na 0 pro dny, kdy není start, můžete ho nastavit na odhad toho, co by byl při běžné době startu. Tato změna by mohla data lépe znázornit.
Napadají vás další způsoby, jak data vylepšit?