Design and performance for Oracle migrations
This article is part one of a seven-part series that provides guidance on how to migrate from Oracle to Azure Synapse Analytics. The focus of this article is best practices for design and performance.
Overview
Due to the cost and complexity of maintaining and upgrading legacy on-premises Oracle environments, many existing Oracle users want to take advantage of the innovations provided by modern cloud environments. Infrastructure-as-a-service (IaaS) and platform-as-a-service (PaaS) cloud environments let you delegate tasks like infrastructure maintenance and platform development to the cloud provider.
Tip
More than just a database—the Azure environment includes a comprehensive set of capabilities and tools.
Although Oracle and Azure Synapse Analytics are both SQL databases that use massively parallel processing (MPP) techniques to achieve high query performance on exceptionally large data volumes, there are some basic differences in approach:
Legacy Oracle systems are often installed on-premises and use relatively expensive hardware, while Azure Synapse is cloud-based and uses Azure storage and compute resources.
Upgrading an Oracle configuration is a major task involving extra physical hardware and potentially lengthy database reconfiguration, or dump and reload. Because storage and compute resources are separate in the Azure environment and have elastic scaling capability, those resources can be scaled upwards or downwards independently.
You can pause or resize Azure Synapse as needed to reduce resource utilization and cost.
Microsoft Azure is a globally available, highly secure, scalable cloud environment that includes Azure Synapse and an ecosystem of supporting tools and capabilities. The next diagram summarizes the Azure Synapse ecosystem.
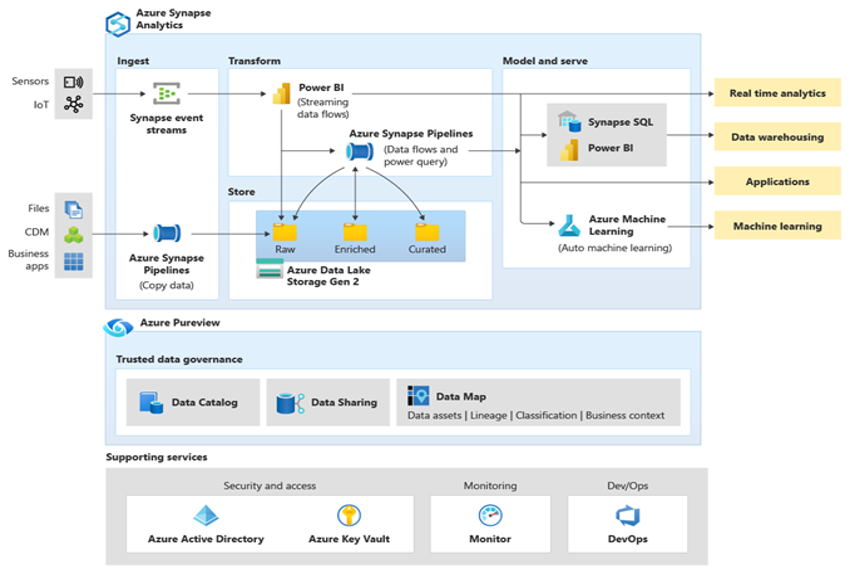
Azure Synapse provides best-of-breed relational database performance by using techniques such as MPP and automatic in-memory caching. You can see the results of these techniques in independent benchmarks such as the one run recently by GigaOm, which compares Azure Synapse to other popular cloud data warehouse offerings. Customers who migrate to the Azure Synapse environment see many benefits, including:
Improved performance and price/performance.
Increased agility and shorter time to value.
Faster server deployment and application development.
Elastic scalability—only pay for actual usage.
Improved security/compliance.
Reduced storage and disaster recovery costs.
Lower overall TCO, better cost control, and streamlined operational expenditure (OPEX).
To maximize these benefits, migrate new or existing data and applications to the Azure Synapse platform. In many organizations, migration includes moving an existing data warehouse from a legacy on-premises platform, such as Oracle, to Azure Synapse. At a high level, the migration process includes these steps:
Preparation 🡆
Define scope—what is to be migrated.
Build inventory of data and processes for migration.
Define data model changes (if any).
Define source data extract mechanism.
Identify the appropriate Azure and third-party tools and features to be used.
Train staff early on the new platform.
Set up the Azure target platform.
Migration 🡆
Start small and simple.
Automate wherever possible.
Leverage Azure built-in tools and features to reduce migration effort.
Migrate metadata for tables and views.
Migrate historical data to be maintained.
Migrate or refactor stored procedures and business processes.
Migrate or refactor ETL/ELT incremental load processes.
Post migration
Monitor and document all stages of the process.
Use the experience gained to build a template for future migrations.
Re-engineer the data model if required (using new platform performance and scalability).
Test applications and query tools.
Benchmark and optimize query performance.
This article provides general information and guidelines for performance optimization when migrating a data warehouse from an existing Oracle environment to Azure Synapse. The goal of performance optimization is to achieve the same or better data warehouse performance in Azure Synapse after the migration.
Design considerations
Migration scope
When you're preparing to migrate from an Oracle environment, consider the following migration choices.
Choose the workload for the initial migration
Typically, legacy Oracle environments have evolved over time to encompass multiple subject areas and mixed workloads. When you're deciding where to start on a migration project, choose an area where you'll be able to:
Prove the viability of migrating to Azure Synapse by quickly delivering the benefits of the new environment.
Allow your in-house technical staff to gain relevant experience with the processes and tools that they'll use when they migrate other areas.
Create a template for further migrations that's specific to the source Oracle environment and the current tools and processes that are already in place.
A good candidate for an initial migration from an Oracle environment supports the preceding items, and:
Implements a BI/Analytics workload rather than an online transaction processing (OLTP) workload.
Has a data model, such as a star or snowflake schema, that can be migrated with minimal modification.
Tip
Create an inventory of objects that need to be migrated, and document the migration process.
The volume of migrated data in an initial migration should be large enough to demonstrate the capabilities and benefits of the Azure Synapse environment but not too large to quickly demonstrate value. A size in the 1-10 terabyte range is typical.
An initial approach to a migration project is to minimize the risk, effort, and time needed so that you quickly see the benefits of the Azure cloud environment. The following approaches limit the scope of the initial migration to just the data marts and doesn't address broader migration aspects, such as ETL migration and historical data migration. However, you can address those aspects in later phases of the project once the migrated data mart layer is backfilled with data and the required build processes.
Lift and shift migration vs. Phased approach
In general, there are two types of migration regardless of the purpose and scope of the planned migration: lift and shift as-is and a phased approach that incorporates changes.
Lift and shift
In a lift and shift migration, an existing data model, like a star schema, is migrated unchanged to the new Azure Synapse platform. This approach minimizes risk and migration time by reducing the work needed to realize the benefits of moving to the Azure cloud environment. Lift and shift migration is a good fit for these scenarios:
- You have an existing Oracle environment with a single data mart to migrate, or
- You have an existing Oracle environment with data that's already in a well-designed star or snowflake schema, or
- You're under time and cost pressures to move to a modern cloud environment.
Tip
Lift and shift is a good starting point, even if subsequent phases implement changes to the data model.
Phased approach that incorporates changes
If a legacy data warehouse has evolved over a long period of time, you might need to re-engineer it to maintain the required performance levels. You might also have to re-engineer to support new data like Internet of Things (IoT) streams. As part of the re-engineering process, migrate to Azure Synapse to get the benefits of a scalable cloud environment. Migration can include a change in the underlying data model, such as a move from an Inmon model to a data vault.
Microsoft recommends moving your existing data model as-is to Azure and using the performance and flexibility of the Azure environment to apply the re-engineering changes. That way, you can use Azure's capabilities to make the changes without impacting the existing source system.
Use Microsoft facilities to implement a metadata-driven migration
You can automate and orchestrate the migration process by using the capabilities of the Azure environment. This approach minimizes the performance hit on the existing Oracle environment, which may already be running close to capacity.
The SQL Server Migration Assistant (SSMA) for Oracle can automate many parts of the migration process, including in some cases functions and procedural code. SSMA supports Azure Synapse as a target environment.

SSMA for Oracle can help you migrate an Oracle data warehouse or data mart to Azure Synapse. SSMA is designed to automate the process of migrating tables, views, and data from an existing Oracle environment.
Azure Data Factory is a cloud-based data integration service that supports creating data-driven workflows in the cloud that orchestrate and automate data movement and data transformation. You can use Data Factory to create and schedule data-driven workflows (pipelines) that ingest data from disparate data stores. Data Factory can process and transform data by using compute services such as Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics, and Azure Machine Learning.
Data Factory can be used to migrate data at source to Azure SQL target. This offline data movement helps to reduce migration downtime significantly.
Azure Database Migration Services can help you plan and perform a migration from environments like Oracle.
When you're planning to use Azure facilities to manage the migration process, create metadata that lists all the data tables to be migrated and their location.
Design differences between Oracle and Azure Synapse
As mentioned earlier, there are some basic differences in approach between Oracle and Azure Synapse Analytics databases. SSMA for Oracle not only helps bridge these gaps but also automates the migration. Although SSMA isn't the most efficient approach for very high volumes of data, it's useful for smaller tables.
Multiple databases vs. single database and schemas
The Oracle environment often contains multiple separate databases. For instance, there could be separate databases for: data ingestion and staging tables, core warehouse tables, and data marts—sometimes referred to as the semantic layer. Processing in ETL or ELT pipelines can implement cross-database joins and move data between the separate databases.
In contrast, the Azure Synapse environment contains a single database and uses schemas to separate tables into logically separate groups. We recommend that you use a series of schemas within the target Azure Synapse database to mimic the separate databases migrated from the Oracle environment. If the Oracle environment already uses schemas, you may need to use a new naming convention when you move the existing Oracle tables and views to the new environment. For example, you could concatenate the existing Oracle schema and table names into the new Azure Synapse table name, and use schema names in the new environment to maintain the original separate database names. Although you can use SQL views on top of the underlying tables to maintain the logical structures, there are potential downsides to that approach:
Views in Azure Synapse are read-only, so any updates to the data must take place on the underlying base tables.
There may already be one or more layers of views in existence and adding an extra layer of views could affect performance.
Tip
Combine multiple databases into a single database within Azure Synapse and use schema names to logically separate the tables.
Table considerations
When you migrate tables between different environments, typically only the raw data and the metadata that describes it physically migrate. Other database elements from the source system, such as indexes, usually aren't migrated because they might be unnecessary or implemented differently in the new environment.
Performance optimizations in the source environment, such as indexes, indicate where you might add performance optimization in the new environment. For example, if queries in the source Oracle environment frequently use bit-mapped indexes, that suggests that a non-clustered index should be created within Azure Synapse. Other native performance optimization techniques like table replication may be more applicable than straight like-for-like index creation. SSMA for Oracle can be used to provide migration recommendations for table distribution and indexing.
Tip
Existing indexes indicate candidates for indexing in the migrated warehouse.
Unsupported Oracle database object types
Oracle-specific features can often be replaced by Azure Synapse features. However, some Oracle database objects aren't directly supported in Azure Synapse. The following list of unsupported Oracle database objects describes how you can achieve an equivalent functionality in Azure Synapse.
Various indexing options: in Oracle, several indexing options, such as bit-mapped indexes, function-based indexes, and domain indexes, have no direct equivalent in Azure Synapse.
You can find out which columns are indexed and the index type by:
Querying system catalog tables and views, such as
ALL_INDEXES,DBA_INDEXES,USER_INDEXES, andDBA_IND_COL. You can use the built-in queries in Oracle SQL Developer, as shown in the following screenshot.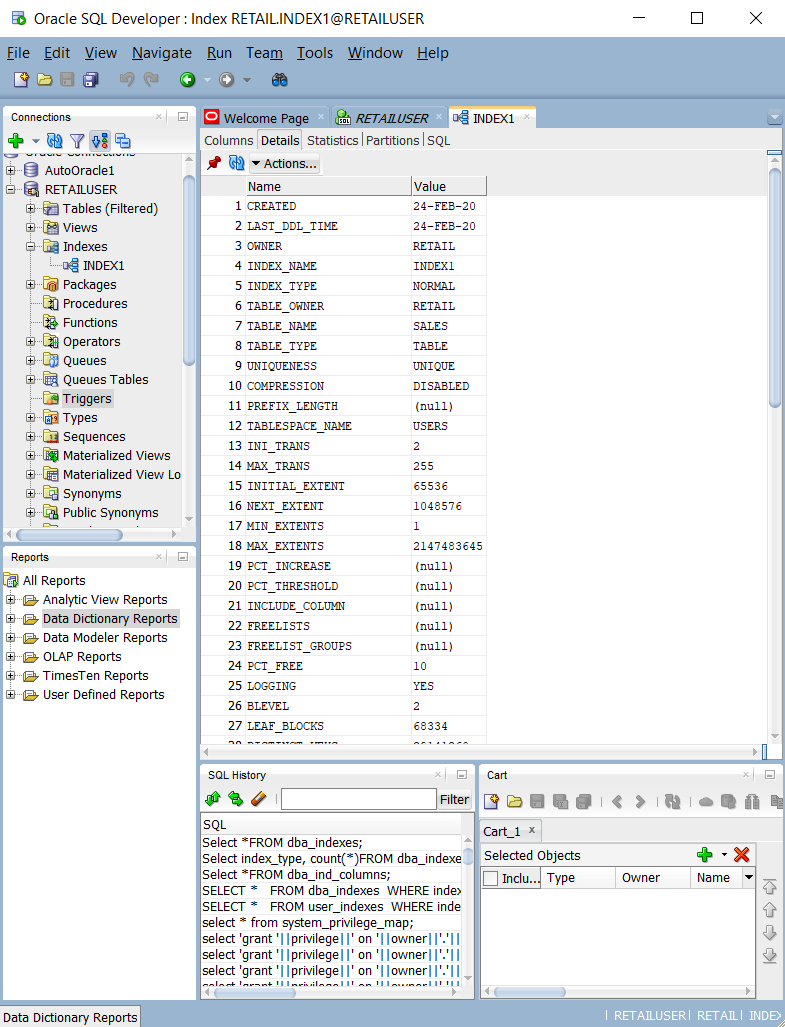
Or, run the following query to find all indexes of a given type:
SELECT * FROM dba_indexes WHERE index_type LIKE 'FUNCTION-BASED%';Querying the
dba_index_usageorv$object_usageviews when monitoring is enabled. You can query those views in Oracle SQL Developer, as shown in the following screenshot.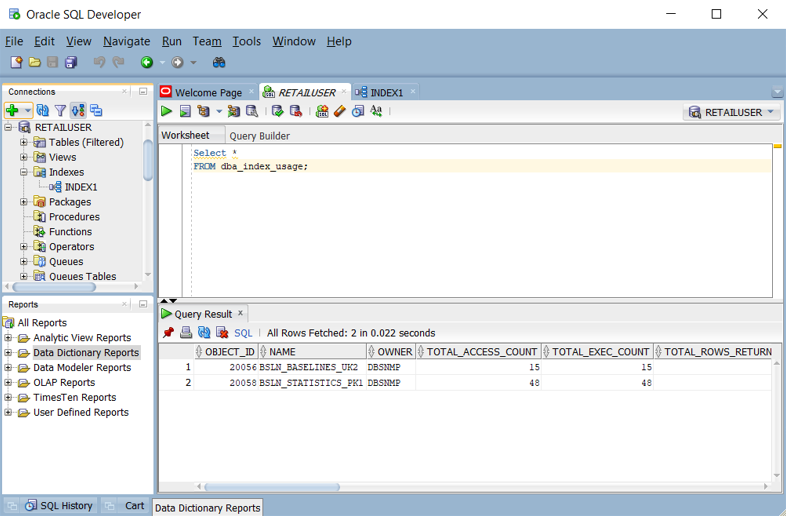
Function-based indexes, where the index contains the result of a function on the underlying data columns, have no direct equivalent in Azure Synapse. We recommend that you first migrate the data, then in Azure Synapse run the Oracle queries that use function-based indexes to gauge performance. If the performance of those queries in Azure Synapse isn't acceptable, consider creating a column that contains the pre-calculated value and then index that column.
When you configure the Azure Synapse environment, it makes sense to only implement in-use indexes. Azure Synapse currently supports the index types shown here:
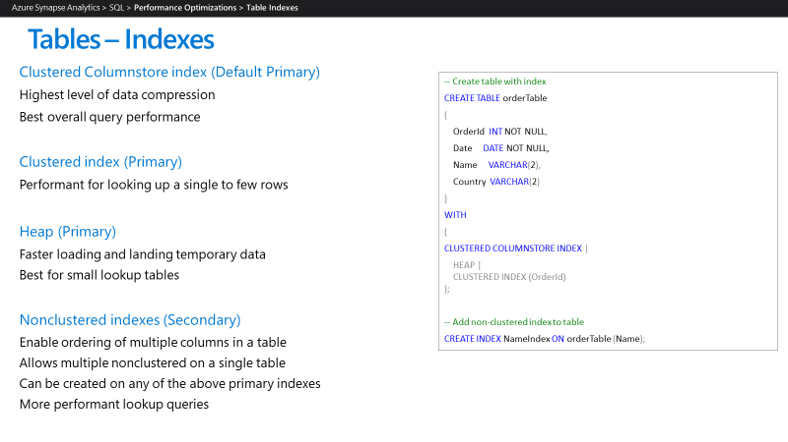
Azure Synapse features, such as parallel query processing and in-memory caching of data and results, make it likely that fewer indexes are required for data warehouse applications to achieve performance goals. We recommend that you use the following index types in Azure Synapse:
Clustered columnstore indexes: when no index options are specified for a table, Azure Synapse by default creates a clustered columnstore index. Clustered columnstore tables offer the highest level of data compression, best overall query performance, and generally outperform clustered index or heap tables. A clustered columnstore index is usually the best choice for large tables. When you create a table, choose clustered columnstore if you're unsure how to index your table. However, there are some scenarios where clustered columnstore indexes aren't the best option:
- Tables with pre-sort data on a sort key(s) could benefit from the segment elimination enabled by ordered clustered columnstore indexes.
- Tables with varchar(max), nvarchar(max), or varbinary(max) data types, because a clustered columnstore index doesn't support those data types. Instead, consider using a heap or clustered index.
- Tables with transient data, because columnstore tables might be less efficient than heap or temporary tables.
- Small tables with less than 100 million rows. Instead, consider using heap tables.
Ordered clustered columnstore indexes: By enabling efficient segment elimination, ordered clustered columnstore indexes in Azure Synapse dedicated SQL pools provide much faster performance by skipping large amounts of ordered data that don't match the query predicate. Loading data into an ordered CCI table can take longer than a non-ordered CCI table because of the data sorting operation, however queries can run faster afterwards with ordered CCI. For more information on ordered clustered columnstore indexes, see Performance tuning with ordered clustered columnstore index.
Clustered and nonclustered indexes: clustered indexes can outperform clustered columnstore indexes when a single row needs to be quickly retrieved. For queries where a single row lookup, or just a few row lookups, must perform at extreme speed, consider using a cluster index or nonclustered secondary index. The disadvantage of using a clustered index is that only queries with a highly selective filter on the clustered index column will benefit. To improve filtering on other columns, you can add a nonclustered index to the other columns. However, each index that you add to a table uses more space and increases the processing time to load.
Heap tables: when you're temporarily landing data on Azure Synapse, you might find that using a heap table makes the overall process faster. This is because loading data to heap tables is faster than loading data to index tables, and in some cases subsequent reads can be done from cache. If you're loading data only to stage it before running more transformations, it's much faster to load it to a heap table than a clustered columnstore table. Also, loading data to a temporary table is faster than loading a table to permanent storage. For small lookup tables with less than 100 million rows, heap tables are usually the right choice. Cluster columnstore tables begin to achieve optimal compression when they contain more than 100 million rows.
Clustered tables: Oracle tables can be organized so that table rows that are frequently accessed together (based on a common value) are physically stored together to reduce disk I/O when data is retrieved. Oracle also provides a hash-cluster option for individual tables, which applies a hash value to the cluster key and physically stores rows with the same hash value together. To list clusters within an Oracle database, use the
SELECT * FROM DBA_CLUSTERS;query. To determine whether a table is within a cluster, use theSELECT * FROM TAB;query, which shows the table name and cluster ID for each table.In Azure Synapse, you can achieve similar results by using materialized and/or replicated tables, because those table types minimize the I/O required at query run time.
Materialized views: Oracle supports materialized views and recommends using one or more for large tables with many columns where only a few columns are regularly used in queries. Materialized views are automatically refreshed by the system when data in the base table is updated.
In 2019, Microsoft announced that Azure Synapse will support materialized views with the same functionality as in Oracle. Materialized views are now a preview feature in Azure Synapse.
In-database triggers: in Oracle, a trigger can be configured to automatically run when a triggering event occurs. Triggering events can be:
A data manipulation language (DML) statement, such as
INSERT,UPDATE, orDELETE, runs on a table. If you defined a trigger that fires before anINSERTstatement on a customer table, the trigger will fire once before a new row is inserted into the customer table.A DDL statement, such as
CREATEorALTER, runs. This trigger is often used for auditing purposes to record schema changes.A system event, such as startup or shutdown of the Oracle database.
A user event, such as sign-in or signout.
You can get a list of the triggers defined in an Oracle database by querying the
ALL_TRIGGERS,DBA_TRIGGERS, orUSER_TRIGGERSviews. The following screenshot shows aDBA_TRIGGERSquery in Oracle SQL Developer.
Azure Synapse doesn't support Oracle database triggers. However, you can add equivalent functionality by using Data Factory, although doing so will require you to refactor the processes that use triggers.
Synonyms: Oracle supports defining synonyms as alternative names for several database object types. Those object types include: tables, views, sequences, procedures, stored functions, packages, materialized views, Java class schema objects, user-defined objects, or another synonym.
Azure Synapse doesn't currently support defining synonyms, although if a synonym in Oracle refers to a table or view, then you can define a view in Azure Synapse to match the alternative name. If a synonym in Oracle refers to a function or stored procedure, then in Azure Synapse you can create another function or stored procedure, with a name to match the synonym, that calls the target.
User-defined types: Oracle supports user-defined objects that can contain a series of individual fields, each with their own definition and default values. Those objects can be referenced within a table definition in the same way as built-in data types like
NUMBERorVARCHAR. You can get a list of user-defined types within an Oracle database by querying theALL_TYPES,DBA_TYPES, orUSER_TYPESviews.Azure Synapse doesn't currently support user-defined types. If the data you need to migrate includes user-defined data types, either "flatten" them into a conventional table definition, or if they're arrays of data, normalize them in a separate table.




Oracle data type mapping
Most Oracle data types have a direct equivalent in Azure Synapse. The following table shows the recommended approach for mapping Oracle data types to Azure Synapse.
| Oracle Data Type | Azure Synapse Data Type |
|---|---|
| BFILE | Not supported. Map to VARBINARY (MAX). |
| BINARY_FLOAT | Not supported. Map to FLOAT. |
| BINARY_DOUBLE | Not supported. Map to DOUBLE. |
| BLOB | Not directly supported. Replace with VARBINARY(MAX). |
| CHAR | CHAR |
| CLOB | Not directly supported. Replace with VARCHAR(MAX). |
| DATE | DATE in Oracle can also contain time information. Depending on usage map to DATE or TIMESTAMP. |
| DECIMAL | DECIMAL |
| DOUBLE | PRECISION DOUBLE |
| FLOAT | FLOAT |
| INTEGER | INT |
| INTERVAL YEAR TO MONTH | INTERVAL data types aren't supported. Use date comparison functions, such as DATEDIFF or DATEADD, for date calculations. |
| INTERVAL DAY TO SECOND | INTERVAL data types aren't supported. Use date comparison functions, such as DATEDIFF or DATEADD, for date calculations. |
| LONG | Not supported. Map to VARCHAR(MAX). |
| LONG RAW | Not supported. Map to VARBINARY(MAX). |
| NCHAR | NCHAR |
| NVARCHAR2 | NVARCHAR |
| NUMBER | FLOAT |
| NCLOB | Not directly supported. Replace with NVARCHAR(MAX). |
| NUMERIC | NUMERIC |
| ORD media data types | Not supported |
| RAW | Not supported. Map to VARBINARY. |
| REAL | REAL |
| ROWID | Not supported. Map to GUID, which is similar. |
| SDO Geospatial data types | Not supported |
| SMALLINT | SMALLINT |
| TIMESTAMP | DATETIME2 or the CURRENT_TIMESTAMP() function |
| TIMESTAMP WITH LOCAL TIME ZONE | Not supported. Map to DATETIMEOFFSET. |
| TIMESTAMP WITH TIME ZONE | Not supported because TIME is stored using wall-clock time without a time zone offset. |
| URIType | Not supported. Store in a VARCHAR. |
| UROWID | Not supported. Map to GUID, which is similar. |
| VARCHAR | VARCHAR |
| VARCHAR2 | VARCHAR |
| XMLType | Not supported. Store XML data in a VARCHAR. |
Oracle also supports defining user-defined objects that can contain a series of individual fields, each with their own definition and default values. Those objects can then be referenced within a table definition in the same way as built-in data types like NUMBER or VARCHAR. Azure Synapse doesn't currently support user-defined types. If the data you need to migrate includes user-defined data types, either "flatten" them into a conventional table definition, or if they're arrays of data, normalize them in a separate table.
Tip
Assess the number and type of unsupported data types during the migration preparation phase.
Third-party vendors offer tools and services to automate migration, including the mapping of data types. If a third-party ETL tool is already in use in the Oracle environment, use that tool to implement any required data transformations.
SQL DML syntax differences
SQL DML syntax differences exist between Oracle SQL and Azure Synapse T-SQL. Those differences are discussed in detail in Minimize SQL issues for Oracle migrations. In some cases, you can automate DML migration by using Microsoft tools like SSMA for Oracle and Azure Database Migration Services, or third-party migration products and services.
Functions, stored procedures, and sequences
When migrating a data warehouse from a mature environment like Oracle, you probably need to migrate elements other than simple tables and views. Check whether tools within the Azure environment can replace the functionality of functions, stored procedures, and sequences because it's usually more efficient to use built-in Azure tools than to recode them for Azure Synapse.
As part of your preparation phase, create an inventory of objects that need to be migrated, define a method for handling them, and allocate appropriate resources in your migration plan.
Microsoft tools like SSMA for Oracle and Azure Database Migration Services, or third-party migration products and services, can automate the migration of functions, stored procedures, and sequences.
The following sections further discuss the migration of functions, stored procedures, and sequences.
Functions
As with most database products, Oracle supports system and user-defined functions within a SQL implementation. When you migrate a legacy database platform to Azure Synapse, common system functions can usually be migrated without change. Some system functions might have a slightly different syntax, but any required changes can be automated. You can get a list of functions within an Oracle database by querying the ALL_OBJECTS view with the appropriate WHERE clause. You can use Oracle SQL Developer to get a list of functions, as shown in the following screenshot.

For Oracle system functions or arbitrary user-defined functions that have no equivalent in Azure Synapse, recode those functions using a target environment language. Oracle user-defined functions are coded in PL/SQL, Java, or C. Azure Synapse uses the Transact-SQL language to implement user-defined functions.
Stored procedures
Most modern database products support storing procedures within the database. Oracle provides the PL/SQL language for this purpose. A stored procedure typically contains both SQL statements and procedural logic, and returns data or a status. You can get a list of stored procedures within an Oracle database by querying the ALL_OBJECTS view with the appropriate WHERE clause. You can use Oracle SQL Developer to get a list of stored procedures, as shown in the next screenshot.

Azure Synapse supports stored procedures using T-SQL, so you'll need to recode any migrated stored procedures in that language.
Sequences
In Oracle, a sequence is a named database object, created using CREATE SEQUENCE. A sequence provides unique numeric values via the CURRVAL and NEXTVAL methods. You can use the generated unique numbers as surrogate key values for primary keys.
Azure Synapse doesn't implement CREATE SEQUENCE, but you can implement sequences using IDENTITY columns or SQL code that generates the next sequence number in a series.
Extracting metadata and data from an Oracle environment
Data Definition Language generation
The ANSI SQL standard defines the basic syntax for Data Definition Language (DDL) commands. Some DDL commands, such as CREATE TABLE and CREATE VIEW, are common to both Oracle and Azure Synapse but also provide implementation-specific features such as indexing, table distribution, and partitioning options.
You can edit existing Oracle CREATE TABLE and CREATE VIEW scripts to achieve equivalent definitions in Azure Synapse. To do so, you might need to use modified data types and remove or modify Oracle-specific clauses such as TABLESPACE.
Within the Oracle environment, system catalog tables specify the current table and view definition. Unlike user-maintained documentation, system catalog information is always complete and in sync with current table definitions. You can access system catalog information using utilities such as Oracle SQL Developer. Oracle SQL Developer can generate CREATE TABLE DDL statements that you can edit to create equivalent tables in Azure Synapse.
Or, you can use SSMA for Oracle to migrate tables from an existing Oracle environment to Azure Synapse. SSMA for Oracle will apply the appropriate data type mappings and recommended table and distribution types, as shown in the following screenshot.

You can also use third-party migration and ETL tools that process system catalog information to achieve similar results.
Data extraction from Oracle
You can extract raw table data from Oracle tables to flat delimited files, such as CSV files, using standard Oracle utilities like Oracle SQL Developer, SQL*Plus, and SCLcl. Then, you can compress the flat delimited files using gzip, and upload the compressed files to Azure Blob Storage using AzCopy or Azure data transport tools like Azure Data Box.
Extract table data as efficiently as possible—especially when migrating large fact tables. For Oracle tables, use parallelism to maximize extraction throughput. You can achieve parallelism by running multiple processes that individually extract discrete segments of data, or by using tools capable of automating parallel extraction through partitioning.
Tip
Use parallelism for the most efficient data extraction.
If sufficient network bandwidth is available, you can extract data from an on-premises Oracle system directly into Azure Synapse tables or Azure Blob Data Storage. To do so, use Data Factory processes, Azure Database Migration Service, or third-party data migration or ETL products.
Extracted data files should contain delimited text in CSV, Optimized Row Columnar (ORC), or Parquet format.
For more information on migrating data and ETL from an Oracle environment, see Data migration, ETL, and load for Oracle migrations.
Performance recommendations for Oracle migrations
The goal of performance optimization is same or better data warehouse performance after migration to Azure Synapse.
Similarities in performance tuning approach concepts
Many performance tuning concepts for Oracle databases hold true for Azure Synapse databases. For example:
Use data distribution to collocate data-to-be-joined onto the same processing node.
Use the smallest data type for a given column to save storage space and accelerate query processing.
Ensure that columns to be joined have the same data type in order to optimize join processing and reduce the need for data transforms.
To help the optimizer produce the best execution plan, ensure statistics are up to date.
Monitor performance using built-in database capabilities to ensure that resources are being used efficiently.
Tip
Prioritize familiarity with Azure Synapse tuning options at the start of a migration.
Differences in performance tuning approach
This section highlights low-level performance tuning implementation differences between Oracle and Azure Synapse.
Data distribution options
For performance, Azure Synapse was designed with multi-node architecture and uses parallel processing. To optimize table performance in Azure Synapse, you can define a data distribution option in CREATE TABLE statements using the DISTRIBUTION statement. For example, you can specify a hash-distributed table, which distributes table rows across compute nodes by using a deterministic hash function. Many Oracle implementations, especially older on-premises systems, don't support this feature.
Unlike Oracle, Azure Synapse supports local joins between a small table and a large table through small table replication. For instance, consider a small dimension table and a large fact table within a star schema model. Azure Synapse can replicate the smaller dimension table across all nodes to ensure that the value of any join key for the large table has a matching, locally available dimension row. The overhead of dimension table replication is relatively low for a small dimension table. For large dimension tables, a hash distribution approach is more appropriate. For more information on data distribution options, see Design guidance for using replicated tables and Guidance for designing distributed tables.
Tip
Hash distribution improves query performance on large fact tables. Round-robin distribution is useful for improving loading speed.
Hash distribution can be applied on multiple columns for a more even distribution of the base table. Multi-column distribution will allow you to choose up to eight columns for distribution. This not only reduces the data skew over time but also improves query performance.
Note
Multi-column distribution is currently in preview for Azure Synapse Analytics. You can use multi-column distribution with CREATE MATERIALIZED VIEW, CREATE TABLE, and CREATE TABLE AS SELECT.
Distribution Advisor
In Azure Synapse SQL, the way each table is distributed can be customized. The table distribution strategy affects query performance substantially.
The distribution advisor is a new feature in Synapse SQL that analyzes queries and recommends the best distribution strategies for tables to improve query performance. Queries to be considered by the advisor can be provided by you or pulled from your historic queries available in DMV.
For details and examples on how to use the distribution advisor, visit Distribution Advisor in Azure Synapse SQL.
Data indexing
Azure Synapse supports several user-definable indexing options that have a different operation and usage compared to system-managed zone maps in Oracle. For more information about the different indexing options in Azure Synapse, see Indexes on dedicated SQL pool tables.
Index definitions within a source Oracle environment provide a useful indication of data usage and the candidate columns for indexing in the Azure Synapse environment. Typically, you won't need to migrate every index from a legacy Oracle environment because Azure Synapse doesn't over-rely on indexes and implements the following features to achieve outstanding performance:
Parallel query processing.
In-memory data and result set caching.
Data distribution, such as replication of small dimension tables, to reduce I/O.
Data partitioning
In an enterprise data warehouse, fact tables can contain billions of rows. Partitioning optimizes the maintenance and querying of these tables by splitting them into separate parts to reduce the amount of data processed. In Azure Synapse, the CREATE TABLE statement defines the partitioning specification for a table.
You can only use one field per table for partitioning. That field is frequently a date field because many queries are filtered by date or a date range. It's possible to change the partitioning of a table after initial load by using the CREATE TABLE AS (CTAS) statement to recreate the table with a new distribution. For a detailed discussion of partitioning in Azure Synapse, see Partitioning tables in dedicated SQL pool.
PolyBase or COPY INTO for data loading
PolyBase supports efficient loading of large amounts of data to a data warehouse by using parallel loading streams. For more information, see PolyBase data loading strategy.
COPY INTO also supports high-throughput data ingestion, and:
- Data retrieval from all files within a folder and subfolders.
- Data retrieval from multiple locations in the same storage account. You can specify multiple locations by using comma separated paths.
- Azure Data Lake Storage (ADLS) and Azure Blob Storage.
- CSV, PARQUET, and ORC file formats.
Tip
The recommended method for data loading is to use COPY INTO along with PARQUET file format.
Workload management
Running mixed workloads can pose resource challenges on busy systems. A successful workload management scheme effectively manages resources, ensures highly efficient resource utilization, and maximizes return on investment (ROI). Workload classification, workload importance, and workload isolation give more control over how workload utilizes system resources.
The workload management guide describes the techniques to analyze the workload, manage and monitor workload importance, and the steps to convert a resource class to a workload group. Use the Azure portal and T-SQL queries on DMVs to monitor the workload to ensure that the applicable resources are efficiently utilized.
Next steps
To learn about ETL and load for Oracle migration, see the next article in this series: Data migration, ETL, and load for Oracle migrations.
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om