Security, access, and operations for Teradata migrations
This article is part three of a seven-part series that provides guidance on how to migrate from Teradata to Azure Synapse Analytics. The focus of this article is best practices for security access operations.
Security considerations
This article discusses connection methods for existing legacy Teradata environments and how they can be migrated to Azure Synapse Analytics with minimal risk and user impact.
This article assumes that there's a requirement to migrate the existing methods of connection and user/role/permission structure as-is. If not, use the Azure portal to create and manage a new security regime.
For more information on the Azure Synapse security options, see Security whitepaper.
Connection and authentication
Teradata authorization options
Tip
Authentication in both Teradata and Azure Synapse can be "in database" or through external methods.
Teradata supports several mechanisms for connection and authorization. Valid mechanism values are:
TD1, which selects Teradata 1 as the authentication mechanism. Username and password are required.
TD2, which selects Teradata 2 as the authentication mechanism. Username and password are required.
TDNEGO, which selects one of the authentication mechanisms automatically based on the policy, without user involvement.
LDAP, which selects Lightweight Directory Access Protocol (LDAP) as the authentication mechanism. The application provides the username and password.
KRB5, which selects Kerberos (KRB5) on Windows clients working with Windows servers. To sign in using KRB5, the user needs to supply a domain, username, and password. The domain is specified by setting the username to
MyUserName@MyDomain.NTLM, which selects NTLM on Windows clients working with Windows servers. The application provides the username and password.
Kerberos (KRB5), Kerberos Compatibility (KRB5C), NT LAN Manager (NTLM), and NT LAN Manager Compatibility (NTLMC) are for Windows only.
Azure Synapse authorization options
Azure Synapse supports two basic options for connection and authorization:
SQL authentication: SQL authentication is via a database connection that includes a database identifier, user ID, and password plus other optional parameters. This is functionally equivalent to Teradata TD1, TD2 and default connections.
Microsoft Entra authentication: with Microsoft Entra authentication, you can centrally manage the identities of database users and other Microsoft services in one central location. Central ID management provides a single place to manage SQL Data Warehouse users and simplifies permission management. Microsoft Entra ID can also support connections to LDAP and Kerberos services—for example, Microsoft Entra ID can be used to connect to existing LDAP directories if these are to remain in place after migration of the database.
Users, roles, and permissions
Overview
Tip
High-level planning is essential for a successful migration project.
Both Teradata and Azure Synapse implement database access control via a combination of users, roles, and permissions. Both use standard SQL CREATE USER and CREATE ROLE statements to define users and roles, and GRANT and REVOKE statements to assign or remove permissions to those users and/or roles.
Tip
Automation of migration processes is recommended to reduce elapsed time and scope for errors.
Conceptually the two databases are similar, and it might be possible to automate the migration of existing user IDs, roles, and permissions to some degree. Migrate such data by extracting the existing legacy user and role information from the Teradata system catalog tables and generating matching equivalent CREATE USER and CREATE ROLE statements to be run in Azure Synapse to recreate the same user/role hierarchy.
After data extraction, use Teradata system catalog tables to generate equivalent GRANT statements to assign permissions (where an equivalent one exists). The following diagram shows how to use existing metadata to generate the necessary SQL.
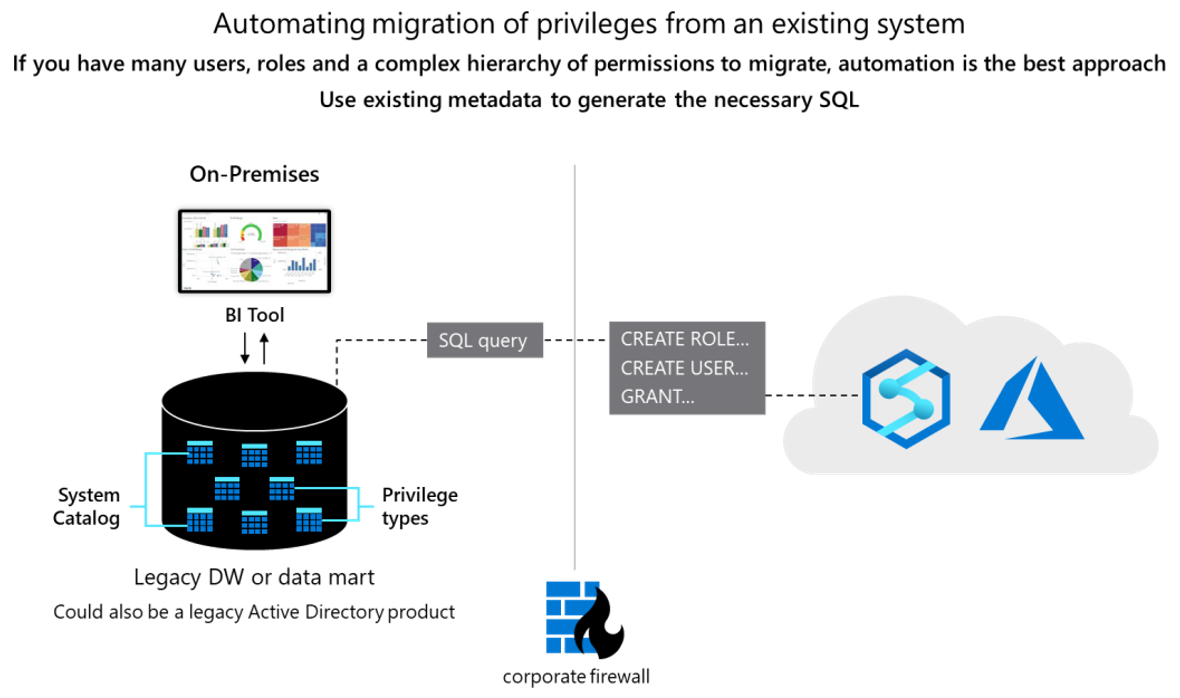
Users and roles
Tip
Migration of a data warehouse requires more than just tables, views, and SQL statements.
The information about current users and roles in a Teradata system is found in the system catalog tables DBC.USERS (or DBC.DATABASES) and DBC.ROLEMEMBERS. Query these tables (if the user has SELECT access to those tables) to obtain current lists of users and roles defined within the system. The following are examples of queries to do this for individual users:
/***SQL to find all users***/
SELECT
DatabaseName AS UserName
FROM DBC.Databases
WHERE dbkind = 'u';
/***SQL to find all roles***/
SELECT A.ROLENAME, A.GRANTEE, A.GRANTOR,
A.DefaultRole,
A.WithAdmin,
B.DATABASENAME,
B.TABLENAME,
B.COLUMNNAME,
B.GRANTORNAME,
B.AccessRight
FROM DBC.ROLEMEMBERS A
JOIN DBC.ALLROLERIGHTS B
ON A.ROLENAME = B.ROLENAME
GROUP BY 1,2,3,4,5,6,7
ORDER BY 2,1,6;
These examples modify SELECT statements to produce a result set, which is a series of CREATE USER and CREATE ROLE statements, by including the appropriate text as a literal within the SELECT statement.
There's no way to retrieve existing passwords, so you need to implement a scheme for allocating new initial passwords on Azure Synapse.
Permissions
Tip
There are equivalent Azure Synapse permissions for basic database operations such as DML and DDL.
In a Teradata system, the system tables DBC.ALLRIGHTS and DBC.ALLROLERIGHTS hold the access rights for users and roles. Query these tables (if the user has SELECT access to those tables) to obtain current lists of access rights defined within the system. The following are examples of queries for individual users:
/**SQL for AccessRights held by a USER***/
SELECT UserName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantAuthority, GrantorName, AllnessFlag, CreatorName, CreateTimeStamp
FROM DBC.ALLRIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE UserName='UserXYZ'
Order By 2,3,4,5;
/**SQL for AccessRights held by a ROLE***/
SELECT RoleName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantorName, CreateTimeStamp
FROM DBC.ALLROLERIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv
Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE RoleName='BI_DEVELOPER'
Order By 2,3,4,5;
Modify these example SELECT statements to produce a result set that's a series of GRANT statements by including the appropriate text as a literal within the SELECT statement.
Use the table AccessRightsAbbv to look up the full text of the access right, as the join key is an abbreviated 'type' field. See the following table for a list of Teradata access rights and their equivalent in Azure Synapse.
| Teradata permission name | Teradata type | Azure Synapse equivalent |
|---|---|---|
| ABORT SESSION | AS | KILL DATABASE CONNECTION |
| ALTER EXTERNAL PROCEDURE | AE | 4 |
| ALTER FUNCTION | AF | ALTER FUNCTION |
| ALTER PROCEDURE | AP | ALTER PROCEDURE |
| CHECKPOINT | CP | CHECKPOINT |
| CREATE AUTHORIZATION | CA | CREATE LOGIN |
| CREATE DATABASE | CD | CREATE DATABASE |
| CREATE EXTERNAL PROCEDURE | CE | 4 |
| CREATE FUNCTION | CF | CREATE FUNCTION |
| CREATE GLOP | GC | 3 |
| CREATE MACRO | CM | CREATE PROCEDURE 2 |
| CREATE OWNER PROCEDURE | OP | CREATE PROCEDURE |
| CREATE PROCEDURE | PC | CREATE PROCEDURE |
| CREATE PROFILE | CO | CREATE LOGIN 1 |
| CREATE ROLE | CR | CREATE ROLE |
| DROP DATABASE | DD | DROP DATABASE |
| DROP FUNCTION | DF | DROP FUNCTION |
| DROP GLOP | GD | 3 |
| DROP MACRO | DM | DROP PROCEDURE 2 |
| DROP PROCEDURE | PD | DELETE PROCEDURE |
| DROP PROFILE | DO | DROP LOGIN 1 |
| DROP ROLE | DR | DELETE ROLE |
| DROP TABLE | DT | DROP TABLE |
| DROP TRIGGER | DG | 3 |
| DROP USER | DU | DROP USER |
| DROP VIEW | DV | DROP VIEW |
| DUMP | DP | 4 |
| EXECUTE | E | EXECUTE |
| EXECUTE FUNCTION | EF | EXECUTE |
| EXECUTE PROCEDURE | PE | EXECUTE |
| GLOP MEMBER | GM | 3 |
| INDEX | IX | CREATE INDEX |
| INSERT | I | INSERT |
| MONRESOURCE | MR | 5 |
| MONSESSION | MS | 5 |
| OVERRIDE DUMP CONSTRAINT | OA | 4 |
| OVERRIDE RESTORE CONSTRAINT | OR | 4 |
| REFERENCES | RF | REFERENCES |
| REPLCONTROL | RO | 5 |
| RESTORE | RS | 4 |
| SELECT | R | SELECT |
| SETRESRATE | SR | 5 |
| SETSESSRATE | SS | 5 |
| SHOW | SH | 3 |
| UPDATE | U | UPDATE |
AccessRightsAbbv table notes:
Teradata
PROFILEis functionally equivalent toLOGINin Azure Synapse.The following table summarizes the differences between macros and stored procedures in Teradata. In Azure Synapse, procedures provide the functionality described in the table.
Macro Stored procedure Contains SQL Contains SQL May contain BTEQ dot commands Contains comprehensive SPL May receive parameter values passed to it May receive parameter values passed to it May retrieve one or more rows Must use a cursor to retrieve more than one row Stored in DBC PERM space Stored in DATABASE or USER PERM Returns rows to the client May return one or more values to client as parameters SHOW,GLOP, andTRIGGERhave no direct equivalent in Azure Synapse.These features are managed automatically by the system in Azure Synapse. See Operational considerations.
In Azure Synapse, these features are handled outside of the database.
For more information about access rights in Azure Synapse, see to Azure Synapse Analytics security permissions.
Operational considerations
Tip
Operational tasks are necessary to keep any data warehouse operating efficiently.
This section discusses how to implement typical Teradata operational tasks in Azure Synapse with minimal risk and impact to users.
As with all data warehouse products, once in production there are ongoing management tasks that are necessary to keep the system running efficiently and to provide data for monitoring and auditing. Resource utilization and capacity planning for future growth also falls into this category, as does backup/restore of data.
While conceptually the management and operations tasks for different data warehouses are similar, the individual implementations may differ. In general, modern cloud-based products such as Azure Synapse tend to incorporate a more automated and "system managed" approach (as opposed to a more "manual" approach in legacy data warehouses such as Teradata).
The following sections compare Teradata and Azure Synapse options for various operational tasks.
Housekeeping tasks
Tip
Housekeeping tasks keep a production warehouse operating efficiently and optimize use of resources such as storage.
In most legacy data warehouse environments, there's a requirement to perform regular "housekeeping" tasks such as reclaiming disk storage space that can be freed up by removing old versions of updated or deleted rows, or reorganizing data log files or index blocks for efficiency. Collecting statistics is also a potentially time-consuming task. Collecting statistics is required after a bulk data ingest to provide the query optimizer with up-to-date data to base generation of query execution plans.
Teradata recommends collecting statistics as follows:
Collect statistics on unpopulated tables to set up the interval histogram used in internal processing. This initial collection makes subsequent statistics collections faster. Make sure to recollect statistics after data is added.
Collect prototype phase statistics for newly populated tables.
Collect production phase statistics after a significant percentage of change to the table or partition (~10% of rows). For high volumes of nonunique values, such as dates or timestamps, it may be advantageous to recollect at 7%.
Collect production phase statistics after you've created users and applied real world query loads to the database (up to about three months of querying).
Collect statistics in the first few weeks after an upgrade or migration during periods of low CPU utilization.
Statistics collection can be managed manually using Automated Statistics Management open APIs or automatically using the Teradata Viewpoint Stats Manager portlet.
Tip
Automate and monitor housekeeping tasks in Azure.
Teradata Database contains many log tables in the Data Dictionary that accumulate data, either automatically or after certain features are enabled. Because log data grows over time, purge older information to avoid using up permanent space. There are options to automate the maintenance of these logs available. The Teradata dictionary tables that require maintenance are discussed next.
Dictionary tables to maintain
Reset accumulators and peak values using the DBC.AMPUsage view and the ClearPeakDisk macro provided with the software:
DBC.Acctg: resource usage by account/userDBC.DataBaseSpace: database and table space accounting
Teradata automatically maintains these tables, but good practices can reduce their size:
DBC.AccessRights: user rights on objectsDBC.RoleGrants: role rights on objectsDBC.Roles: defined rolesDBC.Accounts: account codes by user
Archive these logging tables (if desired) and purge information 60-90 days old. Retention depends on customer requirements:
DBC.SW_Event_Log: database console logDBC.ResUsage: resource monitoring tablesDBC.EventLog: session logon/logoff historyDBC.AccLogTbl: logged user/object eventsDBC.DBQL tables: logged user/SQL activity.NETSecPolicyLogTbl: logs dynamic security policy audit trails.NETSecPolicyLogRuleTbl: controls when and how dynamic security policy is logged
Purge these tables when the associated removable media is expired and overwritten:
DBC.RCEvent: archive/recovery eventsDBC.RCConfiguration: archive/recovery configDBC.RCMedia: VolSerial for archive/recovery
Azure Synapse has an option to automatically create statistics so that they can be used as needed. Perform defragmentation of indexes and data blocks manually, on a scheduled basis, or automatically. Leveraging native built-in Azure capabilities can reduce the effort required in a migration exercise.
Monitoring and auditing
Tip
Over time, several different tools have been implemented to allow monitoring and logging of Teradata systems.
Teradata provides several tools to monitor the operation including Teradata Viewpoint and Ecosystem Manager. For logging query history, the Database Query Log (DBQL) is a Teradata database feature that provides a series of predefined tables that can store historical records of queries and their duration, performance, and target activity based on user-defined rules.
Database administrators can use Teradata Viewpoint to determine system status, trends, and individual query status. By observing trends in system usage, system administrators are better able to plan project implementations, batch jobs, and maintenance to avoid peak periods of use. Business users can use Teradata Viewpoint to quickly access the status of reports and queries and drill down into details.
Tip
The Azure portal provides a UI to manage monitoring and auditing tasks for all Azure data and processes.
Similarly, Azure Synapse provides a rich monitoring experience within the Azure portal to provide insights into your data warehouse workload. The Azure portal is the recommended tool when monitoring your data warehouse as it provides configurable retention periods, alerts, recommendations, and customizable charts and dashboards for metrics and logs.
The portal also enables integration with other Azure monitoring services such as Operations Management Suite (OMS) and Azure Monitor (logs) to provide a holistic monitoring experience for not only the data warehouse but also the entire Azure analytics platform for an integrated monitoring experience.
Tip
Low-level and system-wide metrics are automatically logged in Azure Synapse.
Resource utilization statistics for Azure Synapse are automatically logged within the system. The metrics for each query include usage statistics for CPU, memory, cache, I/O, and temporary workspace, as well as connectivity information like failed connection attempts.
Azure Synapse provides a set of Dynamic Management Views (DMVs). These views are useful when actively troubleshooting and identifying performance bottlenecks with your workload.
For more information, see Azure Synapse operations and management options.
High Availability (HA) and Disaster Recovery (DR)
Teradata implements features such as FALLBACK, Archive Restore Copy utility (ARC), and Data Stream Architecture (DSA) to provide protection against data loss and high availability (HA) via replication and archive of data. Disaster Recovery (DR) options include Dual Active Solution, DR as a service, or a replacement system depending on the recovery time requirement.
Tip
Azure Synapse creates snapshots automatically to ensure fast recovery times.
Azure Synapse uses database snapshots to provide high availability of the warehouse. A data warehouse snapshot creates a restore point that can be used to recover or copy a data warehouse to a previous state. Since Azure Synapse is a distributed system, a data warehouse snapshot consists of many files that are in Azure Storage. Snapshots capture incremental changes from the data stored in your data warehouse.
Azure Synapse automatically takes snapshots throughout the day creating restore points that are available for seven days. This retention period can't be changed. Azure Synapse supports an eight-hour recovery point objective (RPO). A data warehouse can be restored in the primary region from any one of the snapshots taken in the past seven days.
Tip
Use user-defined snapshots to define a recovery point before key updates.
User-defined restore points are also supported, allowing manual triggering of snapshots to create restore points of a data warehouse before and after large modifications. This capability ensures that restore points are logically consistent, which provides additional data protection in case of any workload interruptions or user errors for a desired RPO of less than 8 hours.
Tip
Microsoft Azure provides automatic backups to a separate geographical location to enable DR.
As well as the snapshots described previously, Azure Synapse also performs as standard a geo-backup once per day to a paired data center. The RPO for a geo-restore is 24 hours. You can restore the geo-backup to a server in any other region where Azure Synapse is supported. A geo-backup ensures that a data warehouse can be restored in case the restore points in the primary region aren't available.
Workload management
Tip
In a production data warehouse, there are typically mixed workloads with different resource usage characteristics running concurrently.
A workload is a class of database requests with common traits whose access to the database can be managed with a set of rules. Workloads are useful for:
Setting different access priorities for different types of requests.
Monitoring resource usage patterns, performance tuning, and capacity planning.
Limiting the number of requests or sessions that can run at the same time.
In a Teradata system, workload management is the act of managing workload performance by monitoring system activity and acting when pre-defined limits are reached. Workload management uses rules, and each rule applies only to some database requests. However, the collection of all rules applies to all active work on the platform. Teradata Active System Management (TASM) performs full workload management in a Teradata Database.
In Azure Synapse, resource classes are pre-determined resource limits that govern compute resources and concurrency for query execution. Resource classes can help you manage your workload by setting limits on the number of queries that run concurrently and on the compute resources assigned to each query. There's a trade-off between memory and concurrency.
Azure Synapse automatically logs resource utilization statistics. Metrics include usage statistics for CPU, memory, cache, I/O, and temporary workspace for each query. Azure Synapse also logs connectivity information, such as failed connection attempts.
Tip
Low-level and system-wide metrics are automatically logged within Azure.
Azure Synapse supports these basic workload management concepts:
Workload classification: you can assign a request to a workload group to set importance levels.
Workload importance: you can influence the order in which a request gets access to resources. By default, queries are released from the queue on a first-in, first-out basis as resources become available. Workload importance allows higher priority queries to receive resources immediately regardless of the queue.
Workload isolation: you can reserve resources for a workload group, assign maximum and minimum usage for varying resources, limit the resources a group of requests can consume can, and set a timeout value to automatically kill runaway queries.
Running mixed workloads can pose resource challenges on busy systems. A successful workload management scheme effectively manages resources, ensures highly efficient resource utilization, and maximizes return on investment (ROI). The workload classification, workload importance, and workload isolation gives more control over how workload utilizes system resources.
The workload management guide describes the techniques to analyze the workload, manage and monitor workload importance](../../sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md), and the steps to convert a resource class to a workload group. Use the Azure portal and T-SQL queries on DMVs to monitor the workload to ensure that the applicable resources are efficiently utilized. Azure Synapse provides a set of Dynamic Management Views (DMVs) for monitoring all aspects of workload management. These views are useful when actively troubleshooting and identifying performance bottlenecks in your workload.
This information can also be used for capacity planning, determining the resources required for additional users or application workload. This also applies to planning scale up/scale downs of compute resources for cost-effective support of "peaky" workloads.
For more information on workload management in Azure Synapse, see Workload management with resource classes.
Scale compute resources
Tip
A major benefit of Azure is the ability to independently scale up and down compute resources on demand to handle peaky workloads cost-effectively.
The architecture of Azure Synapse separates storage and compute, allowing each to scale independently. As a result, compute resources can be scaled to meet performance demands independent of data storage. You can also pause and resume compute resources. A natural benefit of this architecture is that billing for compute and storage is separate. If a data warehouse isn't in use, you can save on compute costs by pausing compute.
Compute resources can be scaled up or scaled back by adjusting the data warehouse units setting for the data warehouse. Loading and query performance will increase linearly as you add more data warehouse units.
Adding more compute nodes adds more compute power and ability to leverage more parallel processing. As the number of compute nodes increases, the number of distributions per compute node decreases, providing more compute power and parallel processing for queries. Similarly, decreasing data warehouse units reduces the number of compute nodes, which reduces the compute resources for queries.
Next steps
To learn more about visualization and reporting, see the next article in this series: Visualization and reporting for Teradata migrations.
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om