Processen for udrulningspipelines
Udrulningsprocessen giver dig mulighed for at klone indhold fra én fase i udrulningspipelinen til en anden, typisk fra udvikling til test og fra test til produktion.
Under udrulningen kopierer Microsoft Fabric indholdet fra den aktuelle fase til målfasen. Forbindelserne mellem de kopierede elementer bevares under kopieringsprocessen. Fabric anvender også de konfigurerede udrulningsregler på det opdaterede indhold i destinationsfasen. Det kan tage et stykke tid at installere indhold, afhængigt af antallet af elementer, der installeres. I denne periode kan du navigere til andre sider på portalen, men du kan ikke bruge indholdet i destinationsfasen.
Du kan også installere indhold programmatisk ved hjælp af REST API'erne til udrulningspipelines. Du kan få mere at vide om denne proces i Automatiser din udrulningspipeline ved hjælp af API'er og DevOps.
Udrul indhold til en tom fase
Når du udruller indhold til en tom fase, oprettes der et nyt arbejdsområde på en kapacitet for den fase, du udruller til. Alle metadata i rapporter, dashboards og semantiske modeller i det oprindelige arbejdsområde kopieres til det nye arbejdsområde i den fase, du udruller til.
Der er flere måder at udrulle indhold fra én fase til en anden på. Du kan udrulle alt indholdet, eller du kan vælge, hvilke elementer der skal installeres.
Du kan også udrulle indhold bagud fra en senere fase i udrulningspipelinen til en tidligere fase.
Når installationen er fuldført, skal du opdatere de semantiske modeller, så du kan bruge det nyligt kopierede indhold. Den semantiske modelopdatering er påkrævet, fordi data ikke kopieres fra én fase til en anden. Hvis du vil vide, hvilke elementegenskaber der kopieres under udrulningsprocessen, og hvilke elementegenskaber der ikke kopieres, skal du gennemse de elementegenskaber, der kopieres under udrulningsafsnittet .
Opret et arbejdsområde
Første gang du installerer indhold, kontrollerer udrulningspipelines, om du har tilladelser.
Hvis du har tilladelser, kopieres indholdet af arbejdsområdet til den fase, du udruller til, og der oprettes et nyt arbejdsområde for den pågældende fase i kapaciteten.
Hvis du ikke har tilladelser, oprettes arbejdsområdet, men indholdet kopieres ikke. Du kan bede en kapacitetsadministrator om at føje dit arbejdsområde til en kapacitet eller bede om tildelingstilladelser til kapaciteten. Når arbejdsområdet senere er tildelt til en kapacitet, kan du udrulle indhold til dette arbejdsområde.
Hvis du bruger Premium pr. bruger, knyttes dit arbejdsområde automatisk til din Premium pr. bruger. I sådanne tilfælde kræves der ikke tilladelser. Men hvis du opretter et arbejdsområde med en Premium pr. bruger, er det kun andre brugere af Premium pr. bruger, der kan få adgang til det. Desuden er det kun brugere af Premium pr. bruger, der kan forbruge indhold, der er oprettet i sådanne arbejdsområder.
Udrulningsbrugeren bliver automatisk ejer af de klonede semantiske modeller og den eneste administrator af det nye arbejdsområde.
Udrul indhold til et eksisterende arbejdsområde
Udrulning af indhold fra en arbejdsproduktionspipeline til en fase, der har et eksisterende arbejdsområde, omfatter følgende trin:
Udrulning af nyt indhold som en tilføjelse til det indhold, der allerede findes.
Installerer opdateret indhold for at erstatte noget af det indhold, der allerede findes.
Installationsproces
Når indhold fra den aktuelle fase kopieres til destinationsfasen, identificerer Fabric eksisterende indhold i destinationsfasen og overskriver det. Udrulningspipelines bruger forbindelsen mellem det overordnede element og dets kloner til at identificere, hvilket indholdselement der skal overskrives. Denne forbindelse bevares, når der oprettes nyt indhold. Overskrivningshandlingen overskriver kun indholdet af elementet. Elementets id, URL-adresse og tilladelser forbliver uændrede.
I destinationsfasen forbliver elementegenskaber, der ikke kopieres, som de var før udrulningen. Nyt indhold og nye elementer kopieres fra den aktuelle fase til destinationsfasen.
Autobinding
Når elementer er forbundet i Fabric, afhænger det ene af elementerne af det andet. En rapport afhænger f.eks. altid af den semantiske model, den er forbundet til. En semantisk model kan afhænge af en anden semantisk model og kan også forbindes til flere rapporter, der er afhængige af den. Hvis der er en forbindelse mellem to elementer, forsøger udrulningspipelines altid at vedligeholde denne forbindelse.
Under udrulningen kontrollerer udrulningspipelines, om der er afhængigheder. Installationen lykkes eller mislykkes, afhængigt af placeringen af det element, der leverer de data, som det udrullede element afhænger af.
Der findes et sammenkædet element i destinationsfasen – Udrulningspipelines opretter automatisk forbindelse (autobinder) det udrullede element til det element, det afhænger af i den udrullede fase. Hvis du f.eks. udruller en sideinddelt rapport fra udvikling til test, og den er forbundet til en semantisk model, der tidligere er udrullet til testfasen, opretter den automatisk forbindelse til den semantiske model.
Det sammenkædede element findes ikke i destinationsfasen . Udrulningspipelines mislykkes en udrulning, hvis et element er afhængig af et andet element, og det element, der angiver, at dataene ikke er installeret og ikke er placeret i destinationsfasen. Hvis du f.eks. udruller en rapport fra udvikling til test, og testfasen ikke indeholder den semantiske model, mislykkes installationen. Hvis du vil undgå mislykkede installationer, fordi afhængige elementer ikke installeres, skal du bruge knappen Vælg relateret . Vælg relateret vælger automatisk alle de relaterede elementer, der leverer afhængigheder til de elementer, du er ved at udrulle.
Autobinding fungerer kun sammen med elementer, der understøttes af udrulningspipelines og er placeret i Fabric. Hvis du vil have vist afhængighederne for et element, skal du vælge Vis afstamning i menuen Flere indstillinger for elementet.
Autobinding på tværs af pipelines
Udrulningspipelines binder automatisk elementer, der er forbundet på tværs af pipelines, hvis de er i samme pipelinefase. Når du installerer sådanne elementer, forsøger udrulningspipelines at oprette en ny forbindelse mellem det udrullede element og det element, det er forbundet til i den anden pipeline. Hvis du f.eks. har en rapport i testfasen af pipeline A, der er forbundet til en semantisk model i testfasen af pipeline B, genkender udrulningspipelines denne forbindelse.
Her er et eksempel med illustrationer, der kan hjælpe med at demonstrere, hvordan autobinding på tværs af pipelines fungerer:
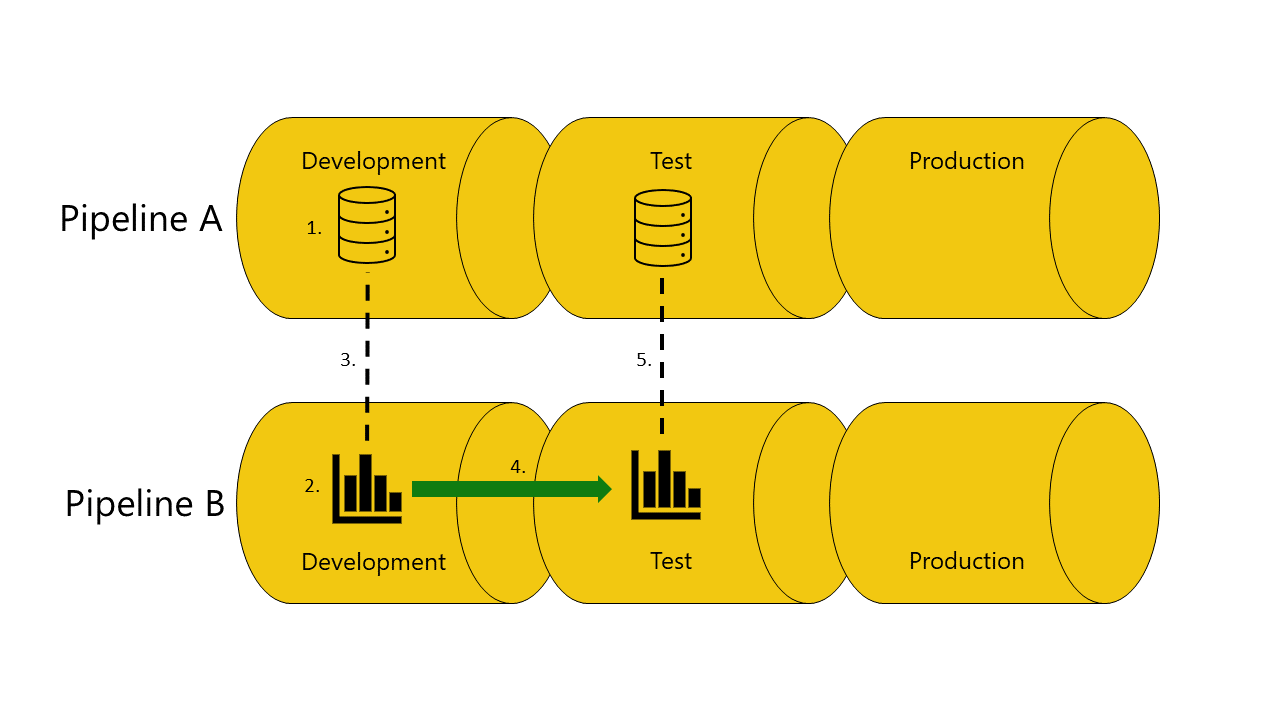
Du har en semantisk model i udviklingsfasen af pipeline A.
Du har også en rapport i udviklingsfasen af pipeline B.
Din rapport i pipeline B er forbundet med din semantiske model i pipeline A. Din rapport afhænger af denne semantiske model.
Du udruller rapporten i pipeline B fra udviklingsfasen til testfasen.
Installationen lykkes eller mislykkes, afhængigt af om du har en kopi af den semantiske model, som den afhænger af i testfasen af pipeline A:
Hvis du har en kopi af den semantiske model, afhænger rapporten af i testfasen af pipeline A:
Udrulningen lykkes, og udrulningspipelines forbinder (automatisk) rapporten i testfasen af pipeline B til den semantiske model i testfasen af pipeline A.
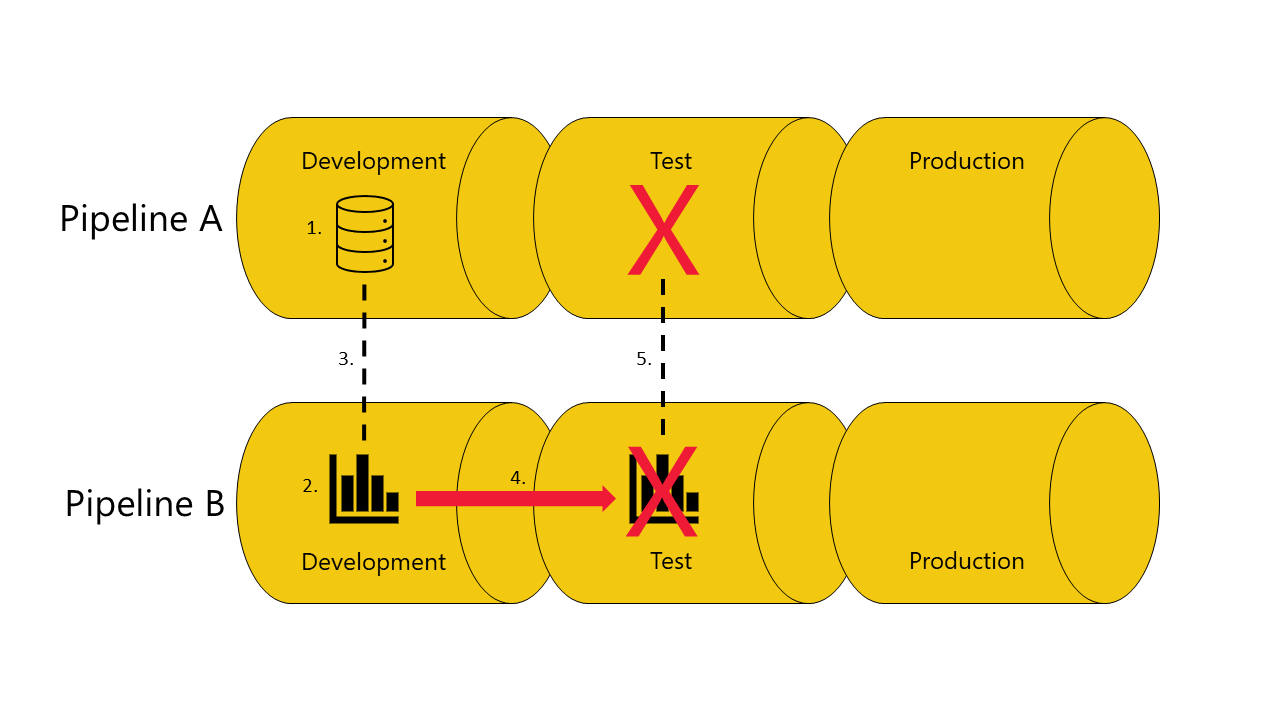
Hvis du ikke har en kopi af den semantiske model, afhænger rapporten af i testfasen af pipeline A:
Installationen mislykkes, fordi udrulningspipelines ikke kan oprette forbindelse (autobinder) rapporten i testfasen i pipeline B til den semantiske model, som den afhænger af i testfasen af pipeline A.
Undgå at bruge autobinding
I nogle tilfælde vil du muligvis ikke bruge autobinding. Hvis du f.eks. har én pipeline til udvikling af semantiske organisationsmodeller og en anden til oprettelse af rapporter. I dette tilfælde ønsker du måske, at alle rapporter altid skal være forbundet til semantiske modeller i produktionsfasen for den pipeline, de tilhører. Det kan du gøre ved at undgå at bruge funktionen til automatisk binding.
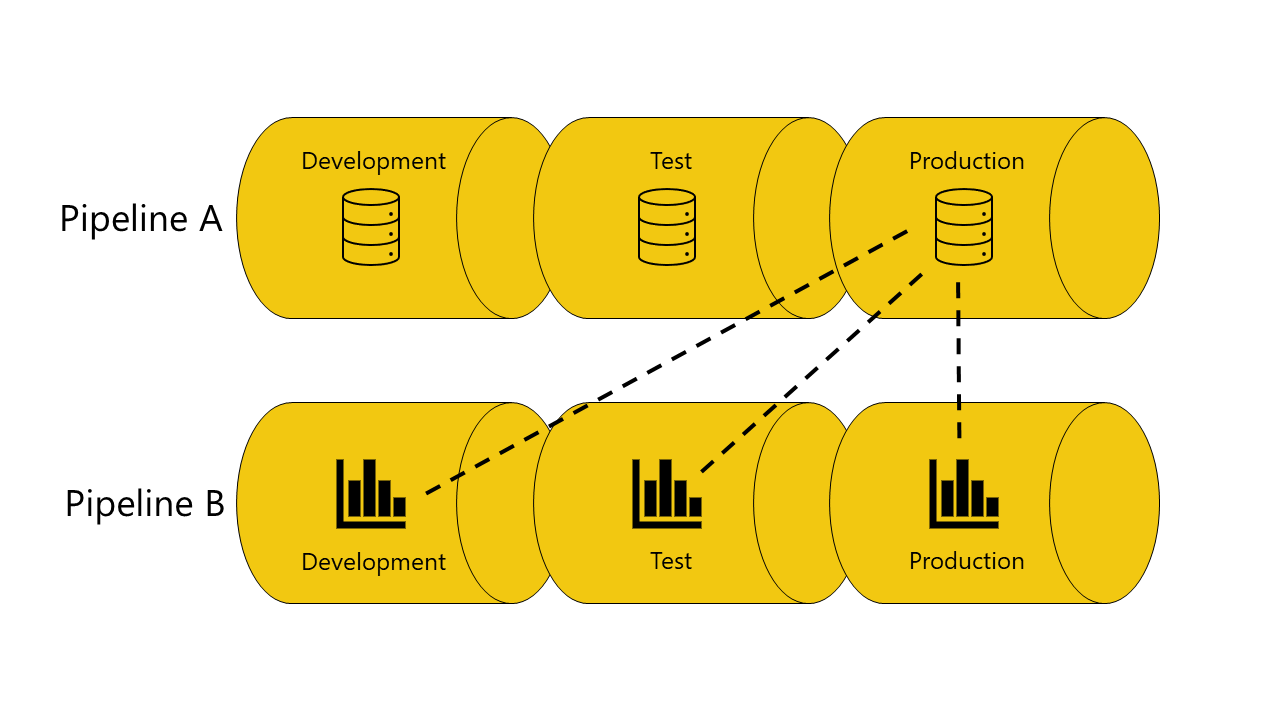
Der er tre metoder, du kan bruge til at undgå at bruge autobinding:
Forbind ikke elementet til de tilsvarende faser. Når elementerne ikke er forbundet i samme fase, bevarer udrulningspipelines den oprindelige forbindelse. Hvis du f.eks. har en rapport i udviklingsfasen af pipeline B, der er forbundet til en semantisk model i produktionsfasen af pipeline A. Når du udruller rapporten til testfasen af pipeline B, forbliver den forbundet med den semantiske model i produktionsfasen i pipeline A.
Definer en parameterregel. Denne indstilling er ikke tilgængelig for rapporter. Du kan kun bruge den med semantiske modeller og dataflow.
Forbind dine rapporter, dashboards og felter til en semantisk proxymodel eller et dataflow, der ikke er forbundet til en pipeline.
Autobinding og parametre
Parametre kan bruges til at styre forbindelserne mellem semantiske modeller eller dataflow og de elementer, de afhænger af. Når en parameter styrer forbindelsen, udføres automatisk binding efter udrulning ikke, selvom forbindelsen indeholder en parameter, der gælder for id'et for den semantiske model eller dataflowet eller arbejdsområde-id'et. I sådanne tilfælde skal du binde elementerne igen efter udrulningen ved at ændre parameterværdien eller ved hjælp af parameterregler.
Bemærk
Hvis du bruger parameterregler til at genbinde elementer, skal parametrene være af typen Text.
Opdaterer data
Data i destinationselementet, f.eks. en semantisk model eller dataflow, bevares, når det er muligt. Hvis der ikke er nogen ændringer af et element, der indeholder dataene, bevares dataene, som de var før udrulningen.
Når du i mange tilfælde har en lille ændring, f.eks. tilføjelse eller fjernelse af en tabel, bevarer Fabric de oprindelige data. Ved afbrydelse af skemaændringer eller ændringer i datakildeforbindelsen kræves der en fuld opdatering.
Krav til udrulning til en fase med et eksisterende arbejdsområde
Alle licenserede brugere , der er medlem af både destinations- og kildeinstallationsarbejdsområder, kan udrulle indhold, der er placeret på en kapacitet , til en fase med et eksisterende arbejdsområde. Du kan få flere oplysninger i afsnittet om tilladelser .
Mapper i udrulningspipelines (prøveversion)
Mapper i et arbejdsområde gør det muligt for brugerne effektivt at organisere og administrere arbejdsområdeelementer på en velkendt måde. Når du installerer indhold, der indeholder mapper, til en anden fase, anvendes mappehierarkiet for de anvendte elementer automatisk.
Mapperepræsentation
Da en udrulning kun er af elementer, vises indhold i arbejdsområdet i Udrulningspipelines som en flad liste over elementer. Et elements fulde sti vises, når du holder markøren over dets navn på listen. I udrulningspipelines betragtes mapper som en del af et elements navn (et elementnavn indeholder den fulde sti). Når et element udrulles, efter at stien er ændret (f.eks. flyttet fra mappe A til mappe B), anvender udrulningspipelines denne ændring på det parrede element under installationen – det parrede element flyttes også til mappe B. Hvis mappe B ikke findes i den fase, vi udruller til, oprettes den først i arbejdsområdet. Mapper kan kun ses og administreres på arbejdsområdesiden.
Identificer elementer, der er flyttet til forskellige mapper
Da mapper betragtes som en del af elementets navn, flyttes elementer til en anden mappe i arbejdsområdet, og de identificeres på siden Udrulningspipelines som Anderledes i sammenligningstilstand . Medmindre der også er en skemaændring, er indstillingen ud for etiketten til at åbne et vindue til ændringsgennemsyn , der præsenterer skemaændringerne, deaktiveret. Når du holder markøren over den, vises en note, hvor der står, at ændringen er en ændring af indstillinger (f.eks . omdøbning). Det skyldes, at ændringen endnu ikke er udrullet sammenlignet med de parrede elementer i kildefasen.
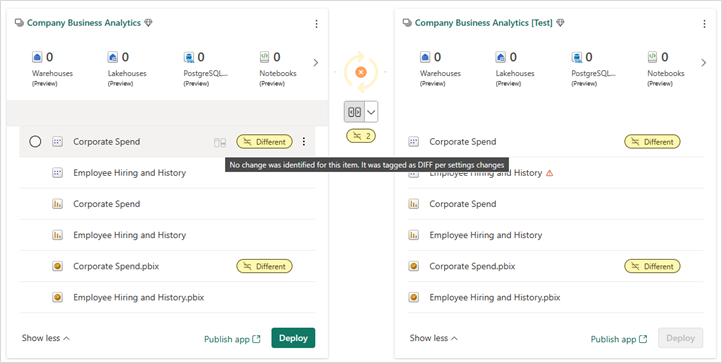
Individuelle mapper kan ikke installeres manuelt i udrulningspipelines. Udrulningen af dem udløses automatisk, når mindst ét af deres elementer installeres.
Mappehierarkiet for parrede elementer opdateres kun under installationen. Under tildelingen opdateres hierarkiet af parrede elementer ikke endnu efter parringsprocessen.
Da en mappe kun installeres, hvis et af dens elementer er installeret, kan der ikke installeres en tom mappe.
Hvis du udruller ét element ud af flere i en mappe, opdateres strukturen af de elementer, der ikke er installeret i destinationsfasen, også selvom selve elementerne ikke installeres.
Understøttede elementer
Når du udruller indhold fra én pipelinefase til en anden, kan det kopierede indhold indeholde følgende elementer:
- Datapipelines
- Dataflow gen1
- Datamarts
- Lakehouse
- Notebooks
- Sideinddelte rapporter
- Rapporter (baseret på understøttede semantiske modeller)
- Semantiske modeller (undtagen semantiske Direct Lake-modeller)
- Lagersteder
Elementegenskaber, der kopieres under udrulningen
Under udrulningen kopieres følgende elementegenskaber, og elementegenskaberne overskrives i destinationsfasen:
Datakilder (installationsregler understøttes)
Parametre (installationsregler understøttes)
Rapportvisualiseringer
Rapportsider
Dashboardfelter
Modelmetadata
Elementrelationer
Følsomhedsmærkater kopieres kun , når en af følgende betingelser er opfyldt. Hvis disse betingelser ikke er opfyldt, kopieres følsomhedsmærkater ikke under udrulningen.
Der udrulles et nyt element, eller et eksisterende element installeres i en tom fase.
Bemærk
Hvis standardmærkater er aktiveret for lejeren, og standardnavnet er gyldigt, hvis det element, der installeres, er en semantisk model eller et dataflow, kopieres mærkaten kun fra kildeelementet, hvis etiketten er beskyttet. Hvis etiketten ikke er beskyttet, anvendes standardnavnet på den nyoprettede semantiske målmodel eller dataflow.
Kildeelementet har et navn med beskyttelse, og det gør destinationselementet ikke. I sådanne tilfælde vises et pop op-vindue, der beder om samtykke til at tilsidesætte målfølsomhedsmærkaten.
Elementegenskaber, der ikke kopieres
Følgende elementegenskaber kopieres ikke under installationen:
Data – Data kopieres ikke. Det er kun metadata, der kopieres
URL-adresse
Id
Tilladelser – for et arbejdsområde eller et bestemt element
Indstillinger for arbejdsområde – hver fase har sit eget arbejdsområde
Appindhold og -indstillinger – Hvis du vil opdatere dine apps, skal du se Opdater indhold til Power BI-apps
Følgende semantiske modelegenskaber kopieres heller ikke under installationen:
Rolletildeling
Opdater tidsplan
Legitimationsoplysninger for datakilde
Indstillinger for cachelagring af forespørgsler (kan nedarves fra kapaciteten)
Indstillinger for godkendelse
Understøttede semantiske modelfunktioner
Udrulningspipelines understøtter mange semantiske modelfunktioner. I dette afsnit vises to semantiske modelfunktioner, der kan forbedre din oplevelse af udrulningspipelines:
Trinvis opdatering
Udrulningspipelines understøtter trinvis opdatering, som er en funktion, der giver mulighed for hurtigere og mere pålidelige opdateringer af store semantiske modeller med lavere forbrug.
Med udrulningspipelines kan du foretage opdateringer af en semantisk model med trinvis opdatering, samtidig med at du bevarer både data og partitioner. Når du installerer den semantiske model, kopieres politikken sammen.
For at forstå, hvordan trinvis opdatering fungerer med dataflow, kan du se , hvorfor jeg kan se to datakilder, der er forbundet til mit dataflow, efter at jeg har brugt dataflowregler?
Aktivering af trinvis opdatering i en pipeline
Hvis du vil aktivere trinvis opdatering, skal du konfigurere den i Power BI Desktop og derefter publicere din semantiske model. Når du har publiceret, er politikken for trinvis opdatering den samme på tværs af pipelinen og kan kun oprettes i Power BI Desktop.
Når din pipeline er konfigureret med trinvis opdatering, anbefaler vi, at du bruger følgende flow:
Foretag ændringer af din .pbix-fil i Power BI Desktop. Hvis du vil undgå lange ventetider, kan du foretage ændringer ved hjælp af et eksempel på dine data.
Upload din .pbix-fil til den første fase (normalt udvikling).
Udrul dit indhold til næste fase. Efter udrulningen gælder de ændringer, du har foretaget, for hele den semantiske model, du bruger.
Gennemse de ændringer, du har foretaget i hver fase, og når du har bekræftet dem, skal du udrulle til næste fase, indtil du kommer til den endelige fase.
Eksempler på anvendelse
Følgende er et par eksempler på, hvordan du kan integrere trinvis opdatering med udrulningspipelines.
Opret en ny pipeline , og opret forbindelse til et arbejdsområde med en semantisk model, hvor trinvis opdatering er aktiveret.
Aktivér trinvis opdatering i en semantisk model, der allerede findes i et udviklingsarbejdsområde .
Opret en pipeline fra et produktionsarbejdsområde, der har en semantisk model, der bruger trinvis opdatering. Tildel f.eks. arbejdsområdet til en ny pipelines produktionsfase , og brug bagududrulning til at udrulle til testfasen og derefter til udviklingsfasen .
Publicer en semantisk model, der bruger trinvis opdatering til et arbejdsområde, der er en del af en eksisterende pipeline.
Begrænsninger for trinvis opdatering
I forbindelse med trinvis opdatering understøtter udrulningspipelines kun semantiske modeller, der bruger forbedrede metadata for semantiske modeller. Alle semantiske modeller, der er oprettet eller ændret med Power BI Desktop, implementerer automatisk forbedrede metadata for semantiske modeller.
Når du genudgiver en semantisk model til en aktiv pipeline med trinvis opdatering aktiveret, medfører følgende ændringer udrulningsfejl på grund af datatab:
Genudgiv en semantisk model, der ikke bruger trinvis opdatering, til at erstatte en semantisk model, hvor trinvis opdatering er aktiveret.
Omdøbning af en tabel, hvor trinvis opdatering er aktiveret.
Omdøbning af ikke-beregnede kolonner i en tabel med trinvis opdatering aktiveret.
Andre ændringer, f.eks. tilføjelse af en kolonne, fjernelse af en kolonne og omdøbning af en beregnet kolonne, er tilladt. Men hvis ændringerne påvirker visningen, skal du opdatere, før ændringen er synlig.
Sammensatte modeller
Ved hjælp af sammensatte modeller kan du konfigurere en rapport med flere dataforbindelser.
Du kan bruge funktionaliteten for sammensatte modeller til at forbinde en fabric-semantisk model med en ekstern semantisk model, f.eks. Azure Analysis Services. Du kan finde flere oplysninger under Brug af DirectQuery til fabric-semantiske modeller og Azure Analysis Services.
I en udrulningspipeline kan du bruge sammensatte modeller til at forbinde en semantisk model med en anden semantisk Fabric-model uden for pipelinen.
Automatiske sammenlægninger
Automatiske sammenlægninger er bygget oven på brugerdefinerede sammenlægninger og bruger maskinel indlæring til løbende at optimere semantiske DirectQuery-modeller for at opnå maksimal ydeevne af rapportforespørgsler.
Hver semantisk model bevarer sine automatiske sammenlægninger efter udrulningen. Udrulningspipelines ændrer ikke en semantisk models automatiske aggregering. Det betyder, at hvis du udruller en semantisk model med en automatisk aggregering, forbliver den automatiske aggregering i destinationsfasen, som den er, og den overskrives ikke af den automatiske aggregering, der er installeret fra kildefasen.
Hvis du vil aktivere automatiske sammenlægninger, skal du følge vejledningen i konfigurer den automatiske sammenlægning.
Hybride tabeller
Hybridtabeller er tabeller med trinvis opdatering , der kan have både import- og direkte forespørgselspartitioner. Under en ren installation kopieres både opdateringspolitikken og hybridtabelpartitionerne. Når du udruller til en pipelinefase, der allerede har hybridtabelpartitioner, er det kun opdateringspolitikken, der kopieres. Opdater tabellen for at opdatere partitionerne.
Opdater indhold til Power BI-apps
Power BI-apps er den anbefalede måde at distribuere indhold til gratis Fabric-forbrugere på. Du kan opdatere indholdet af dine Power BI-apps ved hjælp af en udrulningspipeline, hvilket giver dig mere kontrol og fleksibilitet, når det kommer til din apps livscyklus.
Opret en app for hver udrulningspipelinefase, så du kan teste hver opdatering fra slutbrugerens synspunkt. Brug knappen Publicer eller vis på arbejdsområdekortet til at publicere eller få vist appen i en bestemt pipelinefase.

I produktionsfasen åbner den primære handlingsknap i nederste højre hjørne opdateringsappsiden i Fabric, så alle indholdsopdateringer bliver tilgængelige for appbrugere.

Vigtigt
Installationsprocessen omfatter ikke opdatering af appindholdet eller -indstillingerne. Hvis du vil anvende ændringer på indhold eller indstillinger, skal du manuelt opdatere appen i den påkrævede pipelinefase.
Tilladelser
Der kræves tilladelser til pipelinen og til de arbejdsområder, der er tildelt til den. Pipelinetilladelser og arbejdsområdetilladelser tildeles og administreres separat.
Pipelines har kun én tilladelse, Administration, som kræves til deling, redigering og sletning af en pipeline.
Arbejdsområder har forskellige tilladelser, også kaldet roller. Arbejdsområderoller bestemmer adgangsniveauet til et arbejdsområde i en pipeline.
Udrulningspipelines understøtter ikke Microsoft 365-grupper som pipelineadministratorer.
Hvis du vil udrulle fra én fase til en anden i pipelinen, skal du være pipelineadministrator og enten medlem eller administrator af de arbejdsområder, der er tildelt de involverede faser. En pipelineadministrator, der ikke er tildelt en arbejdsområderolle, kan f.eks. få vist pipelinen og dele den med andre. Denne bruger kan dog ikke få vist indholdet af arbejdsområdet i pipelinen eller i tjenesten og kan ikke udføre udrulninger.
Tabellen Tilladelser
I dette afsnit beskrives tilladelserne til udrulningspipelinen. De tilladelser, der er angivet i dette afsnit, kan have forskellige programmer i andre Fabric-funktioner.
Den laveste tilladelse til udrulningspipeline er pipelineadministrator, og den er påkrævet til alle udrulningspipelinehandlinger.
| User | Pipelinetilladelser | Kommentarer |
|---|---|---|
| Pipelineadministrator |
|
Pipelineadgang giver ikke tilladelser til at få vist eller udføre handlinger på indholdet i arbejdsområdet. |
| Arbejdsområdefremviser (og pipelineadministrator) |
|
Medlemmer af arbejdsområdet har tildelt rollen Læser uden oprettelsestilladelser , kan ikke få adgang til den semantiske model eller redigere indhold i arbejdsområdet. |
| Bidragyder til arbejdsområde (og pipelineadministrator) |
|
|
| Medlem af arbejdsområdet (og pipelineadministrator) |
|
Hvis blokken genudgiver og deaktiverer indstillingen for opdatering af pakker, der er placeret i sikkerhedsafsnittet for semantiske lejere, er aktiveret, er det kun semantiske modelejere, der kan opdatere semantiske modeller. |
| Administrator af arbejdsområde (og pipelineadministrator) |
|
Tildelte tilladelser
Når du udruller Power BI-elementer, kan ejerskabet af det udrullede element blive ændret. Gennemse følgende tabel for at forstå, hvem der kan udrulle hvert element, og hvordan udrulningen påvirker elementets ejerskab.
| Stofelement | Påkrævet tilladelse til at installere et eksisterende element | Elementejerskab efter førstegangsudrulning | Elementejerskab efter udrulning til en fase med elementet |
|---|---|---|---|
| Semantisk model | Medlem af arbejdsområdet | Den bruger, der har foretaget udrulningen, bliver ejer | Uændret |
| Dataflow | Ejer af dataflow | Den bruger, der har foretaget udrulningen, bliver ejer | Uændret |
| Datamart | Datamart-ejer | Den bruger, der har foretaget udrulningen, bliver ejer | Uændret |
| Sideinddelt rapport | Medlem af arbejdsområdet | Den bruger, der har foretaget udrulningen, bliver ejer | Den bruger, der har foretaget udrulningen, bliver ejer |
Påkrævede tilladelser til populære handlinger
I følgende tabel vises de nødvendige tilladelser til populære handlinger i udrulningspipelinen. Medmindre andet er angivet, skal du have alle de angivne tilladelser for hver handling.
| Handling | Påkrævede tilladelser |
|---|---|
| Få vist listen over pipelines i din organisation | Der kræves ingen licens (gratis bruger) |
| Oprette en pipeline | En bruger med en af følgende licenser:
|
| Slet en pipeline | Pipelineadministrator |
| Tilføj eller fjern en pipelinebruger | Pipelineadministrator |
| Tildel et arbejdsområde til en fase |
|
| Fjern tildeling af et arbejdsområde til en fase | En af følgende:
|
| Udrul til en tom fase |
|
| Udrul elementer til næste fase |
|
| Få vist eller angiv en regel |
|
| Administrer pipelineindstillinger | Pipelineadministrator |
| Få vist en pipelinefase |
|
| Få vist listen over elementer i en fase | Pipelineadministrator |
| Sammenlign to faser |
|
| Få vist installationshistorik | Pipelineadministrator |
Overvejelser og begrænsninger
I dette afsnit vises de fleste af begrænsningerne i udrulningspipelines.
- Arbejdsområdet skal være placeret på en Fabric-kapacitet.
- Det maksimale antal elementer, der kan installeres i en enkelt installation, er 300.
- Download af en .pbix-fil efter installation understøttes ikke.
- Microsoft 365-grupper understøttes ikke som pipelineadministratorer.
- Når du udruller et Power BI-element for første gang, mislykkes installationen, hvis et andet element i destinationsfasen er af samme type (f.eks. hvis begge filer er rapporter) og har det samme navn.
- Du kan se en liste over begrænsninger for arbejdsområder under begrænsninger for tildeling af arbejdsområder.
- Du kan se en liste over understøttede elementer under Understøttede elementer. Alle elementer, der ikke findes på listen, understøttes ikke.
- Udrulningen mislykkes, hvis nogle af elementerne har cirkulære eller selvafhængigheder (f.eks. refererer element A til element B og element B til element A).
- Det er kun Power BI-elementer, der kan installeres i et arbejdsområde i et andet kapacitetsområde. Andre Fabric-elementer kan ikke udrulles til et arbejdsområde i et andet kapacitetsområde.
Begrænsninger for semantisk model
Datasæt, der bruger dataforbindelse i realtid, kan ikke installeres.
En semantisk model med DirectQuery- eller Sammensat forbindelsestilstand, der bruger variationstabeller eller tabeller med automatisk dato/klokkeslæt , understøttes ikke. Du kan finde flere oplysninger under Hvad kan jeg gøre, hvis jeg har et datasæt med DirectQuery eller sammensat forbindelsestilstand, der bruger variations- eller kalendertabeller?.
Hvis den semantiske destinationsmodel bruger en direkte forbindelse under installationen, skal den semantiske kildemodel også bruge denne forbindelsestilstand.
Efter udrulningen understøttes download af en semantisk model (fra den fase, den blev udrullet til) ikke.
Du kan se en liste over begrænsninger for udrulningsregler under Begrænsninger for installationsregler.
Installation understøttes ikke på en semantisk model, der bruger oprindelig forespørgsel og DirectQuery sammen, og automatisk binding er aktiveret på DirectQuery-datakilden.
Begrænsninger for dataflow
Når du udruller et dataflow til en tom fase, opretter udrulningspipelines et nyt arbejdsområde og indstiller dataflowlageret til et Fabric-bloblager. Blob Storage bruges, selvom kildearbejdsområdet er konfigureret til at bruge Azure Data Lake Storage Gen2 (ADLS Gen2).
Tjenesteprincipalen understøttes ikke for dataflow.
Udrulning af CDM (Common Data Model) understøttes ikke.
Du kan se begrænsninger for regler for udrulningspipeline, der påvirker dataflow, under Begrænsninger for installationsregler.
Hvis et dataflow opdateres under installationen, mislykkes installationen.
Hvis du sammenligner faser under en opdatering af dataflowet, er resultaterne uforudsigelige.
Datamart-begrænsninger
Du kan ikke udrulle en datamart med følsomhedsmærkater.
Du skal være datamartejer for at udrulle en datamart.
Relateret indhold
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om