Hent data fra Azure Storage
I denne artikel får du mere at vide om, hvordan du henter data fra Azure Storage (ADLS Gen2-objektbeholder, blobobjektbeholder eller individuelle blobs) til enten en ny eller eksisterende tabel.
Forudsætninger
- Et arbejdsområde med en Microsoft Fabric-aktiveret kapacitet
- En KQL-database med redigeringstilladelser
- En lagerkonto
Kilde
På det nederste bånd i din KQL-database skal du vælge Hent data.
I vinduet Hent data er fanen Kilde valgt.
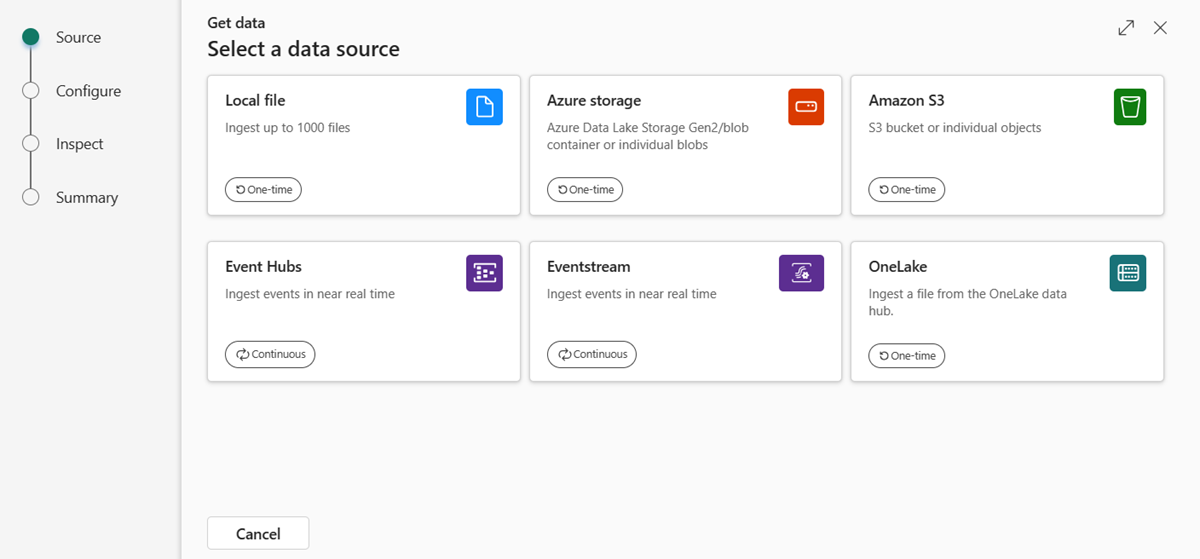
Vælg datakilden på den tilgængelige liste. I dette eksempel henter du data fra Azure Storage.

Konfigurer
Vælg en destinationstabel. Hvis du vil indføde data i en ny tabel, skal du vælge + Ny tabel og angive et tabelnavn.
Bemærk
Tabelnavne kan indeholde op til 1024 tegn, herunder mellemrum, alfanumeriske tegn, bindestreger og understregningstegn. Specialtegn understøttes ikke.
Hvis du vil tilføje datakilden, skal du indsætte dit lager forbindelsesstreng i URI-feltet og derefter vælge +. I følgende tabel vises de understøttede godkendelsesmetoder og de tilladelser, der er nødvendige for at indtage data fra Azure Storage.
Authentication method Individuel blob Blobobjektbeholder Azure Data Lake Storage Gen2 SAS-token (Shared Access) Læs og Skriv Læs og opliste Læs og opliste Adgangsnøgle til lagerkonto Bemærk
- Du kan enten tilføje op til 10 individuelle blobs eller indtage op til 5.000 blobs fra en enkelt objektbeholder. Du kan ikke indtage begge dele på samme tid.
- Hver blob kan maksimalt være 1 GB dekomprimeret.
Hvis du har indsat en forbindelsesstreng for en blobobjektbeholder eller en Azure Data Lake Storage Gen2, kan du tilføje følgende valgfrie filtre:
Indstilling Beskrivelse af felt Filfiltre (valgfrit) Folder path Filtrerer data til indfødning af filer med en bestemt mappesti. Filtypenavn Filtrerer kun data til indfødning af filer med et bestemt filtypenavn.
Vælg Næste

Inspicer
Fanen Undersøg åbnes med et eksempel på dataene.
Vælg Udfør for at fuldføre indtagelsesprocessen.

Eventuelt:
- Vælg Kommandofremviser for at få vist og kopiere de automatiske kommandoer, der genereres fra dine input.
- Brug rullelisten Skemadefinitionsfil til at ændre den fil, som skemaet udledes fra.
- Rediger det automatisk udledte dataformat ved at vælge det ønskede format på rullelisten. Du kan få flere oplysninger under Dataformater, der understøttes af analyse i realtid.
- Rediger kolonner.
- Udforsk avancerede indstillinger baseret på datatype.
Rediger kolonner
Bemærk
- I forbindelse med tabelformater (CSV, TSV, PSV) kan du ikke tilknytte en kolonne to gange. Hvis du vil knytte til en eksisterende kolonne, skal du først slette den nye kolonne.
- Du kan ikke ændre en eksisterende kolonnetype. Hvis du forsøger at knytte til en kolonne med et andet format, kan du ende med at have tomme kolonner.
De ændringer, du kan foretage i en tabel, afhænger af følgende parametre:
- Tabeltypen er ny eller eksisterende
- Tilknytningstypen er ny eller eksisterende
| Tabeltype | Tilknytningstype | Tilgængelige justeringer |
|---|---|---|
| Ny tabel | Ny tilknytning | Omdøb kolonne, skift datatype, skift datakilde, tilknytningstransformation, tilføj kolonne, slet kolonne |
| Eksisterende tabel | Ny tilknytning | Tilføj kolonne (hvor du derefter kan ændre datatype, omdøbe og opdatere) |
| Eksisterende tabel | Eksisterende tilknytning | ingen |

Tilknytning af transformationer
Nogle tilknytninger af dataformater (Parquet, JSON og Avro) understøtter enkle transformationer af indfødningstid. Hvis du vil anvende tilknytningstransformationer, skal du oprette eller opdatere en kolonne i vinduet Rediger kolonner .
Tilknytningstransformationer kan udføres på en kolonne af typen streng eller datetime, hvor kilden har datatypen int eller long. Understøttede tilknytningstransformationer er:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Avancerede indstillinger baseret på datatype
Tabel (CSV, TSV, PSV):
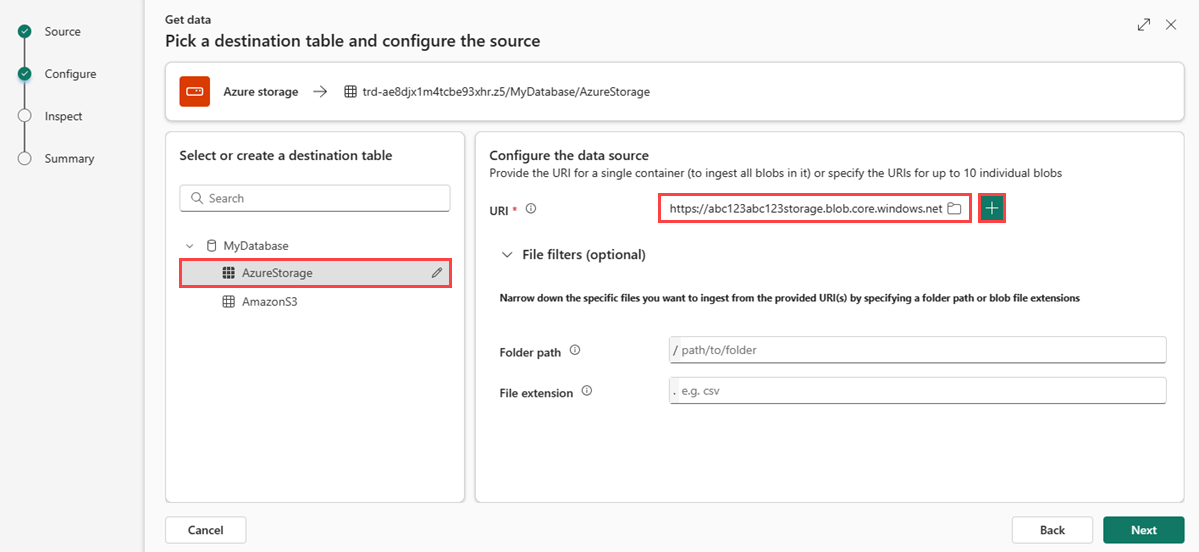
Hvis du bruger tabelformater i en eksisterende tabel, kan du vælge Avanceret>behold tabelskema. Tabeldata indeholder ikke nødvendigvis de kolonnenavne, der bruges til at knytte kildedata til de eksisterende kolonner. Når denne indstilling er markeret, udføres tilknytningen efter rækkefølge, og tabelskemaet forbliver det samme. Hvis denne indstilling ikke er markeret, oprettes der nye kolonner til indgående data, uanset datastruktur.
Hvis du vil bruge den første række som kolonnenavne, skal du vælge Avanceret>første række er kolonneoverskrift.
JSON:
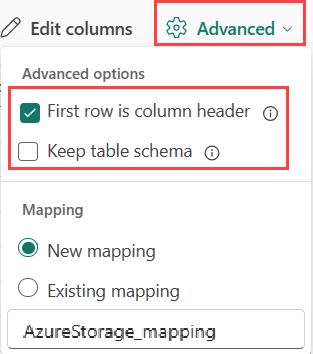
Hvis du vil bestemme kolonneopdelingen af JSON-data, skal du vælge Avancerede>indlejrede niveauer fra 1 til 100.
Hvis du vælger Avanceret>Spring JSON-linjer over med fejl, indtages dataene i JSON-format. Hvis du ikke markerer dette afkrydsningsfelt, indtages dataene i multijsonformat.
Resumé
I vinduet Dataforberedelse er alle tre trin markeret med grønne markeringer, når dataindtagelse er fuldført. Du kan vælge et kort, der skal forespørges om, slippe de data, der er indtaget, eller se et dashboard med oversigten over indtagelse.

Relateret indhold
- Hvis du vil administrere databasen, skal du se Administrer data
- Hvis du vil oprette, gemme og eksportere forespørgsler, skal du se Forespørgselsdata i et KQL-forespørgselssæt
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om