Viele Dienste verwenden ein Drosselungsmuster, um die von ihnen genutzten Ressourcen zu steuern, und begrenzen so die Rate, mit der andere Anwendungen oder Dienste auf sie zugreifen können. Die Verwendung eines Ratenbegrenzungsmusters ermöglicht die Vermeidung oder Minimierung von Drosselungsfehlern im Zusammenhang mit diesen Drosselungsgrenzwerten sowie eine genauere Vorhersage des Durchsatzes.
Ein Ratenbegrenzungsmuster eignet sich zwar für viele Szenarien, besonders hilfreich ist es jedoch bei umfangreichen repetitiven automatisierten Aufgaben wie etwa der Batchverarbeitung.
Kontext und Problem
Wenn eine große Anzahl von Vorgängen mit einem gedrosselten Dienst ausgeführt wird, kann dies zu mehr Datenverkehr und Durchsatz führen, da abgelehnte Anforderungen nachverfolgt und die entsprechenden Vorgänge anschließend wiederholt werden müssen. Bei zunehmender Vorgangsanzahl kann ein Drosselungslimit mehrere Durchgänge mit erneut gesendeten Daten erforderlich machen, was größere Leistungsbeeinträchtigungen zur Folge hat.
Hierzu ein Beispiel für die Erfassung von Daten in Azure Cosmos DB mit einem naiven Prozess vom Typ „Wiederholung bei Fehler“:
- Von Ihrer Anwendung müssen 10.000 Datensätze in Azure Cosmos DB erfasst werden. Die Erfassung eines einzelnen Datensatzes kostet zehn Anforderungseinheiten (Request Units, RUs), sodass für die Aufgabe insgesamt 100.000 RUs erforderlich sind.
- Für Ihre Azure Cosmos DB-Instanz wurde eine Kapazität von 20.000 RUs bereitgestellt.
- Sie senden alle 10.000 Datensätze an Azure Cosmos DB. 2.000 Datensätze werden erfolgreich geschrieben, und 8.000 Datensätze werden abgelehnt.
- Sie senden die übrigen 8.000 Datensätze an Azure Cosmos DB. 2.000 Datensätze werden erfolgreich geschrieben, und 6.000 Datensätze werden abgelehnt.
- Sie senden die übrigen 6.000 Datensätze an Azure Cosmos DB. 2.000 Datensätze werden erfolgreich geschrieben, und 4.000 Datensätze werden abgelehnt.
- Sie senden die übrigen 4.000 Datensätze an Azure Cosmos DB. 2.000 Datensätze werden erfolgreich geschrieben, und 2.000 Datensätze werden abgelehnt.
- Sie senden die restlichen 2.000 Datensätze an Azure Cosmos DB. Alle Datensätze werden erfolgreich geschrieben.
Der Erfassungsauftrag wurde zwar erfolgreich abgeschlossen, hierzu mussten jedoch 30.000 Datensätze an Azure Cosmos DB gesendet werden, obwohl das gesamte Dataset nur 10.000 Datensätze umfasste.
Im obigen Beispiel müssen noch weitere Faktoren berücksichtigt werden:
- Die Protokollierung einer hohen Anzahl von Fehlern und die Verarbeitung der resultierenden Protokolldaten können ebenfalls zu einem Mehraufwand führen. Bei diesem naiven Ansatz wurden 20.000 Fehler behandelt, und die Protokollierung dieser Fehler ist unter Umständen mit Kosten für Verarbeitung, Arbeitsspeicher oder Speicherressourcen verbunden.
- Da die Drosselungsgrenzwerte des Erfassungsdiensts nicht bekannt sind, ist es bei diesem naiven Ansatz nicht möglich, die Dauer der Datenverarbeitung abzuschätzen. Die Ratenbegrenzung ermöglicht Ihnen die Berechnung der für die Erfassung benötigten Zeit.
Lösung
Die Ratenbegrenzung kann Ihren Datenverkehr verringern und potenziell den Durchsatz verbessern. Hierzu wird die Anzahl von Datensätzen reduziert, die über einen bestimmten Zeitraum an einen Dienst gesendet werden.
Ein Dienst kann im Laufe der Zeit basierend auf verschiedenen Metriken gedrosselt werden. Hierzu zählen etwa folgende:
- Die Anzahl von Vorgängen (beispielsweise 20 Anforderungen pro Sekunde)
- Die Datenmenge (beispielsweise 2 GiB pro Minute)
- Die relativen Kosten von Vorgängen (beispielsweise 20.000 RUs pro Sekunde)
Unabhängig von der Metrik, die für die Drosselung verwendet wird, umfasst Ihre Implementierung der Ratenbegrenzung die Steuerung der Anzahl und/oder Größe der Vorgänge, die über einen bestimmten Zeitraum an den Dienst gesendet werden, um die Nutzung des Diensts zu optimieren, ohne dessen Drosselungskapazität zu überschreiten.
In Szenarien, in denen Ihre APIs Anforderungen schneller verarbeiten können als dies mit gedrosselten Erfassungsdiensten möglich ist, müssen Sie steuern, wie schnell Sie den Dienst verwenden können. Es ist jedoch riskant, die Drosselung nur als Datenratenkonflikt zu behandeln und Ihre Erfassungsanforderungen einfach zu puffern, bis der gedrosselte Dienst den Rückstand aufholen kann. Sollte Ihre Anwendung in diesem Szenario abstürzen, besteht die Gefahr, dass die gepufferten Daten verloren gehen.
Zur Vermeidung dieses Risikos empfiehlt es sich gegebenenfalls, die Datensätze an ein langlebiges Messagingsystem zu senden, das in der Lage ist, Ihre Erfassungsrate vollständig auszunutzen. (Dienste wie Azure Event Hubs können Millionen von Vorgängen pro Sekunde bewältigen.) Anschließend können Sie einzelne oder mehrere Auftragsprozessoren verwenden, um die Datensätze mit einer kontrollierten Rate, die innerhalb der Grenzwerte des gedrosselten Diensts liegt, aus dem Messagingsystem zu lesen. Die Übermittlung von Datensätzen an das Messagingsystem trägt zur Entlastung des internen Arbeitsspeichers bei, da Sie so die Möglichkeit haben, nur Datensätze aus der Warteschlange zu entnehmen, die während eines bestimmten Zeitintervalls verarbeitet werden können.
Azure bietet mehrere langlebige Messagingdienste, die mit diesem Muster verwendet werden können. Hierzu zählen beispielsweise:
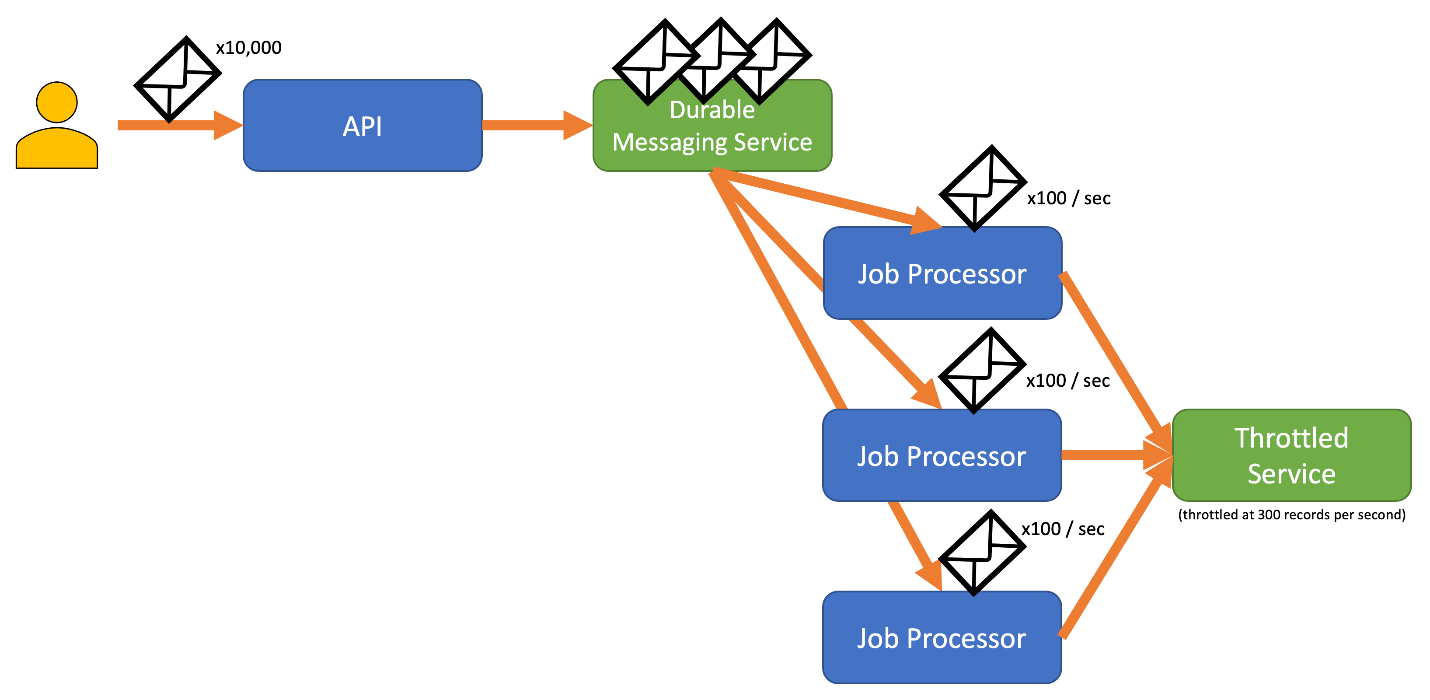
Wenn Sie Datensätze senden, kann der für die Freigabe von Datensätzen verwendete Zeitraum präziser sein als der Zeitraum, auf dem die Drosselung des Diensts basiert. Drosselungen werden von Systemen häufig auf der Grundlage leicht nachvollzieh- und verwendbarer Zeiträume festgelegt. Für den Computer, auf dem ein Dienst ausgeführt wird, können diese Zeiträume jedoch im Vergleich zur erreichbaren Verarbeitungsgeschwindigkeit sehr lang sein. So kann es beispielsweise sein, dass die Drosselung eines Systems auf Sekunden oder Minuten basiert, während der Code in der Regel im Nano- oder Millisekundenbereich verarbeitet wird.
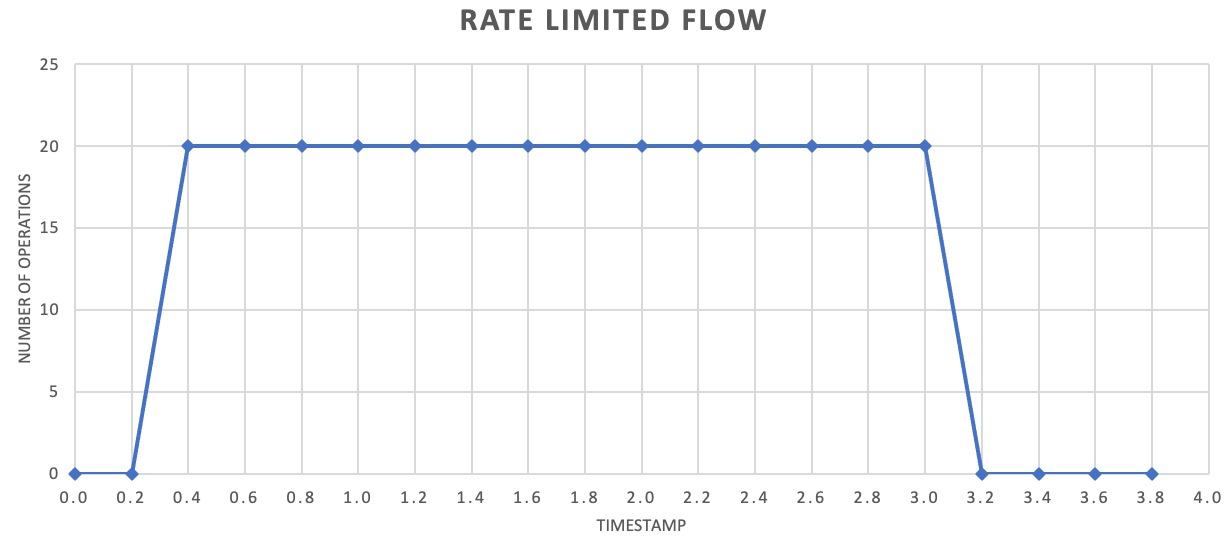
Daher wird oftmals empfohlen, häufiger kleinere Datensatzmengen zu senden, um den Durchsatz zu verbessern. Dies ist jedoch nicht zwingend erforderlich. Anstatt also für eine Freigabe alles im Sekunden- oder Minutentakt zu einem Batch zusammenzufassen, können Sie differenzierter vorgehen, um einen gleichmäßigeren Ressourcenverbrauch (Arbeitsspeicher, CPU, Netzwerk usw.) zu erzielen und potenzielle Engpässe durch plötzlich auftretende Anforderungsspitzen zu vermeiden. Wenn ein Dienst beispielsweise 100 Vorgänge pro Sekunde zulässt, lassen sich die Anforderungen durch die Implementierung einer Ratenbegrenzung gleichmäßig verteilen, indem alle 200 Millisekunden 20 Vorgänge freigegeben werden, wie im folgenden Diagramm dargestellt:
Darüber hinaus ist es manchmal erforderlich, dass sich mehrere nicht koordinierte Prozesse einen gedrosselten Dienst teilen. In diesem Szenario können Sie zur Implementierung der Ratenbegrenzung die Kapazität des Diensts logisch partitionieren und dann ein verteiltes Mutex-System verwenden, um exklusive Sperren für diese Partitionen zu verwalten. Die nicht koordinierten Prozesse können dann um Sperren für diese Partitionen konkurrieren, wenn sie Kapazität benötigen. Für jede Partition, für die ein Prozess über eine Sperre verfügt, wird ihm eine bestimmte Kapazität erteilt.
Wenn das gedrosselte System beispielsweise 500 Anforderungen pro Sekunde bewältigen kann, können Sie 20 Partitionen mit jeweils 25 Anforderungen pro Sekunde erstellen. Sind für einen Prozess 100 Anforderungen erforderlich, können beim verteilten Mutex-System vier Partitionen angefordert werden. Vom System werden ggf. zwei Partitionen für zehn Sekunden gewährt. Der Prozess begrenzt daraufhin die Rate auf 50 Anforderungen pro Sekunde, schließt die Aufgabe in zwei Sekunden ab und gibt anschließend die Sperre frei.
Eine Implementierungsmöglichkeit für dieses Muster wäre beispielsweise die Verwendung von Azure Storage. In diesem Szenario wird pro logischer Partition in einem Container ein einzelnes 0-Byte-Blob erstellt. Ihre Anwendungen können dann für einen kurzen Zeitraum (beispielsweise 15 Sekunden) direkt exklusive Leases für diese Blobs beziehen. Für jede Lease, die einer Anwendung gewährt wird, kann die Kapazität dieser Partition genutzt werden. Die Anwendung muss dann die Leasezeit nachverfolgen, damit die gewährte Kapazität nach Ablauf der Leasezeit nicht weiter beansprucht wird. Bei der Implementierung dieses Musters soll häufig von jedem Prozess versucht werden, im Falle von Kapazitätsbedarf eine Partition nach dem Zufallsprinzip zu leasen.
Zur weiteren Verkürzung der Wartezeit kann für jeden Prozess eine kleine exklusive Kapazitätsmenge zugeordnet werden. Dadurch wird erreicht, dass sich ein Prozess nur dann um eine Lease für gemeinsam genutzte Kapazität bemüht, wenn die reservierte Kapazität überschritten werden musste.
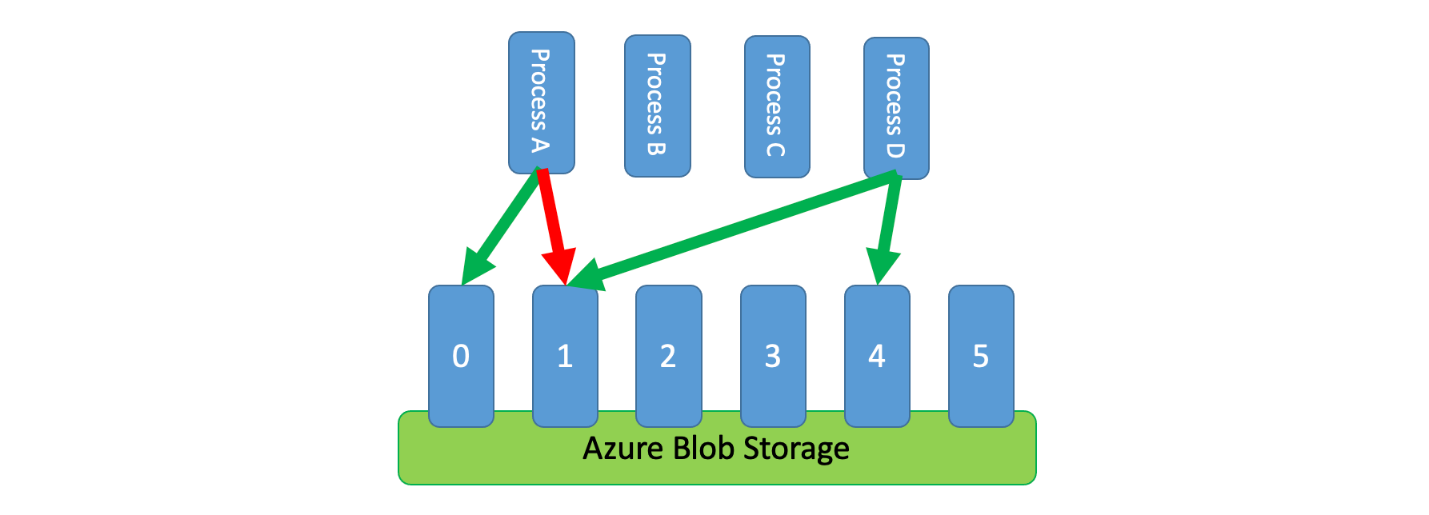
Als Alternative zu Azure Storage lässt sich diese Art von Leaseverwaltungssystem unter anderem auch mithilfe von Technologien wie Zookeeper, Consul, etcd und Redis/Redsync implementieren.
Probleme und Überlegungen
Beachten Sie bei der Entscheidung, wie dieses Muster implementiert werden soll, Folgendes:
- Das Ratenbegrenzungsmuster kann zwar die Anzahl von Drosselungsfehlern verringern, aufgetretene Drosselungsfehler müssen von Ihrer Anwendung allerdings trotzdem ordnungsgemäß behandelt werden.
- Wenn Ihre Anwendung über mehrere Arbeitsstreams verfügt, die auf den gleichen gedrosselten Dienst zugreifen, müssen alle in Ihre Ratenbegrenzungsstrategie einbezogen werden. Vielleicht unterstützen Sie beispielsweise das Massenladen von Datensätzen in eine Datenbank sowie das Abfragen von Datensätzen in der gleichen Datenbank. Sie können die Kapazität verwalten, indem Sie sicherstellen, dass alle Arbeitsstreams durch den gleichen Ratenbegrenzungsmechanismus begrenzt werden. Alternativ können Sie separate Kapazitätspools für jeden Arbeitsstream reservieren.
- Der gedrosselte Dienst kann in mehreren Anwendungen verwendet werden. Diese Verwendung kann in manchen Fällen koordiniert werden (wie oben gezeigt). Wenn unerwartet viele Drosselungsfehler auftreten, kann dies auf einen Konflikt zwischen Anwendungen hindeuten, die auf einen Dienst zugreifen. In diesem Fall empfiehlt es sich unter Umständen, den durch Ihren Ratenbegrenzungsmechanismus erzwungenen Durchsatz vorübergehend zu verringern, bis die Nutzung durch andere Anwendungen zurückgeht.
Verwendung dieses Musters
Verwendung Sie dieses Muster für folgende Zwecke:
- Verringern von Drosselungsfehlern, die durch einen gedrosselten Dienst verursacht werden
- Verringern des Datenverkehrs (verglichen mit einem naiven Ansatz vom Typ „Wiederholung bei Fehler“)
- Verringern der Arbeitsspeichernutzung, indem Datensätze nur dann aus der Warteschlange entnommen werden, wenn Kapazität für deren Verarbeitung zur Verfügung steht
Workloadentwurf
Ein Architekt sollte evaluieren, wie das Rate Limiting-Pattern im Design seiner Workloads verwendet werden kann, um die Ziele und Prinzipien zu erreichen, die in den Azure Well-Architected Framework-Säulen behandelt werden. Zum Beispiel:
| Säule | So unterstützt dieses Muster die Säulenziele |
|---|---|
| Zuverlässigkeitsdesignentscheidungen tragen dazu bei, dass Ihre Workload ausfallsicher wird und dass sie nach einem Ausfall wieder in einen voll funktionsfähigen Zustand zurückkehrt. | Diese Taktik schützt den Kunden, indem sie die Einschränkungen und Kosten der Kommunikation mit einem Dienst anerkennt und berücksichtigt, wenn der Dienst eine übermäßige Nutzung vermeiden möchte. - RE:07 Selbsterhaltung |
Berücksichtigen Sie wie bei jeder Designentscheidung alle Kompromisse im Hinblick auf die Ziele der anderen Säulen, die mit diesem Muster eingeführt werden könnten.
Beispiel
Mit der folgenden Beispielanwendung können Benutzer verschiedenartige Datensätze an eine API übermitteln. Für die einzelnen Datensatztypen steht jeweils ein individueller Auftragsprozessor zur Verfügung, der folgende Schritte ausführt:
- Überprüfen
- Anreicherung
- Hinzufügung des Datensatzes zur Datenbank
Bei allen Komponenten der Anwendung (API, Auftragsprozessor A und Auftragsprozessor B) handelt es sich um separate Prozesse, die jeweils unabhängig voneinander skaliert werden können. Die Prozesse kommunizieren nicht direkt miteinander.
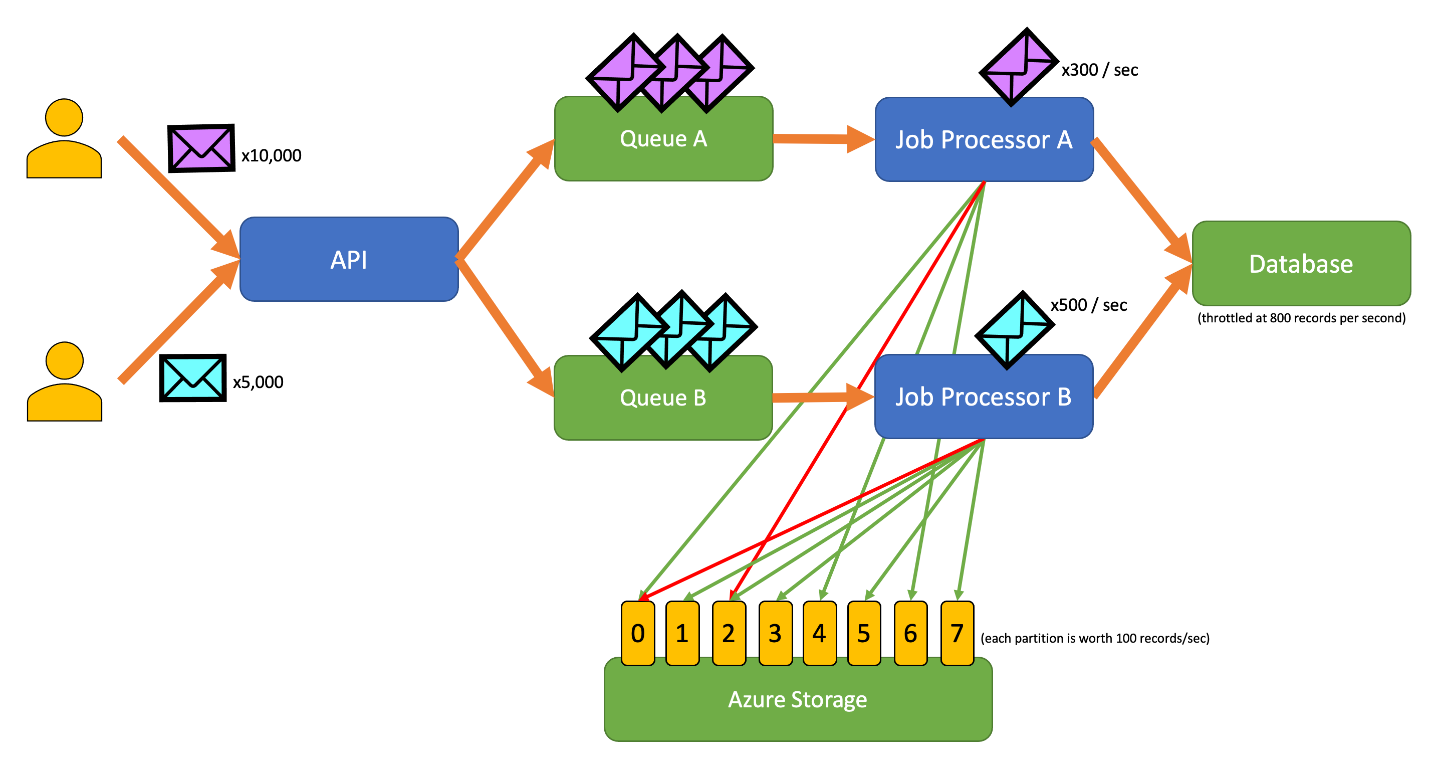
Dieses Diagramm zeigt den folgenden Workflow:
- Ein Benutzer übermittelt 10.000 Datensätze vom Typ A an die API.
- Die API reiht diese 10.000 Datensätze in die Warteschlange A ein.
- Ein Benutzer übermittelt 5.000 Datensätze vom Typ B an die API.
- Die API reiht diese 5.000 Datensätze in die Warteschlange B ein.
- Der Auftragsprozessor A stellt fest, dass die Warteschlange A Datensätze enthält, und versucht, eine exklusive Lease für das Blob 2 zu erhalten.
- Der Auftragsprozessor B stellt fest, dass die Warteschlange B Datensätze enthält, und versucht, eine exklusive Lease für das Blob 2 zu erhalten.
- Die Leaseanforderung des Auftragsprozessors A ist nicht erfolgreich.
- Der Auftragsprozessor B erhält die Lease für das Blob 2 für 15 Sekunden. Die an die Datenbank gerichteten Anforderungen können nun auf eine Rate von 100 Anforderungen pro Sekunde begrenzt werden.
- Der Auftragsprozessor B entnimmt 100 Datensätze aus der Warteschlange B und schreibt sie.
- Eine Sekunde vergeht.
- Der Auftragsprozessor A stellt fest, dass die Warteschlange A weitere Datensätze enthält, und versucht, eine exklusive Lease für das Blob 6 zu erhalten.
- Der Auftragsprozessor B stellt fest, dass die Warteschlange B weitere Datensätze enthält, und versucht, eine exklusive Lease für das Blob 3 zu erhalten.
- Der Auftragsprozessor A erhält die Lease für das Blob 6 für 15 Sekunden. Die an die Datenbank gerichteten Anforderungen können nun auf eine Rate von 100 Anforderungen pro Sekunde begrenzt werden.
- Der Auftragsprozessor B erhält die Lease für das Blob 3 für 15 Sekunden. Die an die Datenbank gerichteten Anforderungen können nun auf eine Rate von 200 Anforderungen pro Sekunde begrenzt werden. (Der Prozessor verfügt auch noch über die Lease für das Blob 2.)
- Der Auftragsprozessor A entnimmt 100 Datensätze aus der Warteschlange A und schreibt sie.
- Der Auftragsprozessor B entnimmt 200 Datensätze aus der Warteschlange B und schreibt sie.
- Eine Sekunde vergeht.
- Der Auftragsprozessor A stellt fest, dass die Warteschlange A weitere Datensätze enthält, und versucht, eine exklusive Lease für das Blob 0 zu erhalten.
- Der Auftragsprozessor B stellt fest, dass die Warteschlange B weitere Datensätze enthält, und versucht, eine exklusive Lease für das Blob 1 zu erhalten.
- Der Auftragsprozessor A erhält die Lease für das Blob 0 für 15 Sekunden. Die an die Datenbank gerichteten Anforderungen können nun auf eine Rate von 200 Anforderungen pro Sekunde begrenzt werden. (Der Prozessor verfügt auch noch über die Lease für das Blob 6.)
- Der Auftragsprozessor B erhält die Lease für das Blob 1 für 15 Sekunden. Die an die Datenbank gerichteten Anforderungen können nun auf eine Rate von 300 Anforderungen pro Sekunde begrenzt werden. (Der Prozessor verfügt auch noch über die Lease für die Blobs 2 und 3.)
- Der Auftragsprozessor A entnimmt 200 Datensätze aus der Warteschlange A und schreibt sie.
- Der Auftragsprozessor B entnimmt 300 Datensätze aus der Warteschlange B und schreibt sie.
- Und so weiter.
Nach 15 Sekunden ist mindestens einer der beiden Aufträge immer noch nicht abgeschlossen. Wenn die Leases ablaufen, muss ein Prozessor auch die Anzahl von Anforderungen verringern, die er aus der Warteschlange entnimmt und schreibt.
 Implementierungen dieses Musters sind in verschiedenen Programmiersprachen verfügbar:
Implementierungen dieses Musters sind in verschiedenen Programmiersprachen verfügbar:
Zugehörige Ressourcen
Die folgenden Muster und Anweisungen können für die Implementierung dieses Musters ebenfalls relevant sein:
- Einschränkung. Das hier erläuterte Ratenbegrenzungsmuster wird in der Regel implementiert, um auf einen gedrosselten Dienst zu reagieren.
- Wiederholen. Wenn an einen gedrosselten Dienst gerichtete Anforderungen zu Drosselungsfehlern führen, können diese im Allgemeinen nach einem geeigneten Intervall wiederholt werden.
Der warteschlangenbasierte Lastenausgleich ist zwar ähnlich, weist jedoch einige entscheidende Unterschiede zum Ratenbegrenzungsmuster auf:
- Bei der Ratenbegrenzung muss die Lastverwaltung nicht unbedingt über Warteschlangen erfolgen, es muss aber ein langlebiger Messagingdienst verwendet werden. Für ein Ratenbegrenzungsmuster können beispielsweise Dienste wie Apache Kafka und Azure Event Hubs genutzt werden.
- Das Ratenbegrenzungsmuster führt das Konzept eines verteilten Mutex-Systems für Partitionen ein, mit dem Sie die Kapazität für mehrere nicht koordinierte Prozesse verwalten können, die mit dem gleichen gedrosselten Dienst kommunizieren.
- Ein warteschlangenbasiertes Lastenausgleichsmuster kann immer dann verwendet werden, wenn ein Leistungskonflikt zwischen Diensten besteht oder die Resilienz verbessert werden soll. Dies macht es zu einem universelleren Muster als die Ratenbegrenzung, bei der es mehr um den effizienten Zugriff auf einen gedrosselten Dienst geht.