Einen Datenspeicher in einen Satz horizontaler Partitionen oder Shards unterteilen Dies kann die Skalierbarkeit bei der Speicherung großer Datenmengen sowie beim Zugriff auf diese Daten verbessern.
Kontext und Problem
Ein Datenspeicher, der von einem einzelnen Server gehostet wird, unterliegt möglicherweise den folgenden Einschränkungen:
Speicherplatz: Es wird erwartet, dass ein Datenspeicher für eine umfangreiche Cloudanwendung eine riesige Datenmenge enthält, die mit der Zeit deutlich zunehmen könnte. Ein Server bietet normalerweise nur eine begrenzte Menge an Datenspeicher, aber Sie können vorhandene Datenträger durch größere ersetzen oder weitere Datenträger zu einem Computer hinzufügen, wenn die Datenmenge zunimmt. Allerdings wird das System irgendwann eine Kapazitätsgrenze erreichen, ab der es nicht mehr möglich ist, die Speicherkapazität auf einem bestimmten Server einfach zu erhöhen.
Computingressourcen: Eine Cloudanwendung ist erforderlich, um eine große Anzahl gleichzeitiger Benutzer zu unterstützen, von denen jeder eine Abfrage ausführt, die Informationen aus dem Datenspeicher abruft. Ein einzelner Server, der den Datenspeicher hostet, ist möglicherweise nicht in der Lage, die erforderliche Computeleistung zur Verfügung zu stellen, um diese Auslastung zu unterstützen. Dies führt zu verlängerten Antwortzeiten für Benutzer und häufigen Ausfällen bei Anwendungen, die versuchen, Daten zu speichern und abzurufen. Möglicherweise können Sie Arbeitsspeicher hinzufügen oder Prozessoren aufrüsten, aber das System wird eine Grenze erreichen, ab der es nicht mehr möglich ist, die Computeressourcen weiter zu erhöhen.
Netzwerkbandbreite: Letztendlich wird die Leistung eines Datenspeichers, der auf einem einzelnen Server ausgeführt wird, durch die Geschwindigkeit bestimmt, mit der der Server Anforderungen empfangen und Antworten senden kann. Es ist möglich, dass die Menge des Netzwerkdatenverkehrs die Kapazität des Netzwerks übersteigt, das für die Verbindung mit dem Server verwendet wird, was zu Anforderungsfehlern führt.
Geografie: Es kann erforderlich sein, von bestimmten Benutzern generierte Daten, die sich in derselben Region wie diese Benutzer befinden, aus rechtlichen, Konformitäts- oder Leistungsgründen zu speichern oder die Wartezeit des Datenzugriffs zu reduzieren. Wenn die Benutzer über verschiedene Länder oder Regionen verteilt sind, ist es unter Umständen nicht möglich, die gesamten Daten für die Anwendung in einem einzelnen Datenspeicher zu speichern.
Eine vertikale Skalierung durch Hinzufügen von mehr Datenträgerkapazität, Rechenleistung, Arbeitsspeicher und Netzwerkverbindungen kann die Auswirkungen einiger dieser Einschränkungen hinauszögern, aber es handelt sich wahrscheinlich nur um eine vorübergehende Lösung. Eine kommerzielle Cloudanwendung, die eine große Anzahl von Benutzern und große Datenmengen unterstützen kann, muss nahezu unbegrenzt skalierbar sein, sodass eine vertikale Skalierung nicht unbedingt die beste Lösung darstellt.
Lösung
Den Datenspeicher in horizontale Partitionen oder Shards unterteilen Jeder Shard weist das gleiche Schema auf, besitzt aber eine eigene, eindeutige Untermenge der Daten. Ein Shard ist ein eigenständiger Datenspeicher (er kann die Daten für viele Entitäten verschiedener Typen enthalten), der auf einem Server ausgeführt wird, der als Speicherknoten fungiert.
Dieses Muster hat folgende Vorteile:
Sie können das System horizontal hochskalieren, indem Sie weitere Shards hinzufügen, die auf zusätzlichen Speicherknoten ausgeführt werden.
Ein System kann anstelle spezieller und teurer Computer für jeden Speicherknoten Standardhardware verwenden.
Sie können Konflikte reduzieren und die Leistung verbessern, indem Sie die Workload auf mehrere Shards verteilen.
In der Cloud können Shards physisch in der Nähe der Benutzer angeordnet werden, die auf die Daten zugreifen.
Entscheiden Sie bei der Aufteilung eines Datenspeichers in Shards, welche Daten in jedem Shard abgelegt werden sollen. Ein Shard enthält typischerweise Elemente, die in einen bestimmten Bereich fallen, der durch mindestens ein Attribut der Daten bestimmt wird. Diese Attribute bilden den Shard-Schlüssel (auch als Partitionsschlüssel bezeichnet). Der Shard-Schlüssel sollte statisch sein. Er sollte nicht auf Daten basieren, die sich möglicherweise ändern.
Durch das Sharding werden die Daten physisch angeordnet. Wenn eine Anwendung Daten speichert und abruft, leitet die Sharding-Logik die Anwendung an den entsprechenden Shard weiter. Diese Sharding-Logik kann als Teil des Datenzugriffscodes in der Anwendung implementiert werden, oder sie kann vom Datenspeichersystem implementiert werden, wenn es das Sharding offensichtlich unterstützt.
Die Abstraktion der physischen Speicherorte der Daten in der Sharding-Logik bietet ein hohes Maß an Kontrolle darüber, welche Shards welche Daten enthalten. Sie ermöglicht auch die Migration von Daten zwischen Shards, ohne die Geschäftslogik einer Anwendung überarbeiten zu müssen, wenn die Daten in den Shards später neu verteilt werden müssen (wenn die Shards z. B. unausgeglichen sind). Der Nachteil hierbei ist der zusätzliche Aufwand für den Datenzugriff, der erforderlich ist, um den Speicherort der einzelnen Datenelemente beim Abruf zu bestimmen.
Um eine optimale Leistung und Skalierbarkeit sicherzustellen, ist es wichtig, die Daten so aufzuteilen, dass sie für die von der Anwendung ausgeführten Abfragen geeignet sind. In vielen Fällen ist es unwahrscheinlich, dass das Sharding-Schema genau den Anforderungen jeder Abfrage entspricht. In einem mandantenfähigen System kann eine Anwendung beispielsweise Mandantendaten anhand der Mandanten-ID abrufen, aber auch anhand eines anderen Attributs wie dem Namen oder dem Standort des Mandanten nachschlagen. Implementieren Sie zur Bewältigung dieser Situationen eine Sharding-Strategie mit einem Shard-Schlüssel, der die gängigsten Abfragen unterstützt.
Wenn Abfragen regelmäßig Daten über eine Kombination von Attributwerten abrufen, können Sie wahrscheinlich einen zusammengesetzten Shard-Schlüssel definieren, indem Sie Attribute miteinander verknüpfen. Alternativ können Sie auch ein Muster wie Indextabelle verwenden, um eine schnelle Suche nach Daten zu ermöglichen, die auf Attributen basieren, die nicht durch den Shard-Schlüssel abgedeckt sind.
Sharding-Strategien
Bei der Auswahl des Shard-Schlüssels und der Entscheidung, wie die Daten auf die Shards verteilt werden sollen, werden im Allgemeinen drei Strategien verwendet. Beachten Sie, dass es keine eineindeutige Übereinstimmung zwischen den Shards und den Servern, die sie hosten, geben muss. Ein einzelner Server kann mehrere Shards hosten. Verfügbare Strategien
Suchstrategie: Bei dieser Strategie implementiert die Sharding-Logik eine Zuordnung, die eine Datenanforderung mithilfe des Shard-Schlüssels an den Shard weiterleitet, der diese Daten enthält. In einer mandantenfähigen Anwendung können alle Daten eines Mandanten zusammen in einem Shard gespeichert werden, wobei die Mandanten-ID als Shard-Schlüssel verwendet wird. Mehrere Mandanten können denselben Shard gemeinsam nutzen, aber die Daten für einen einzelnen Mandanten werden nicht über mehrere Shards verteilt. Die Abbildung veranschaulicht das Sharding für Mandantendaten auf Grundlage der Mandanten-IDs.
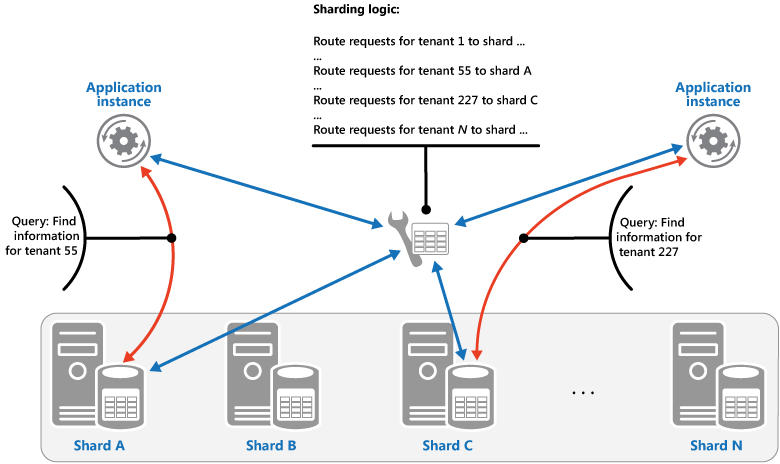
Die Zuordnung zwischen Shard-Schlüssel und physischem Speicher kann auf physischen Shards basieren, wobei jeder Shard-Schlüssel einer physischen Partition zugeordnet wird. Alternativ dazu ist die virtuelle Partitionierung ein flexibleres Verfahren zum Neuverteilen von Shards, wobei die Shard-Schlüssel derselben Anzahl virtueller Shards zugeordnet wird, die wiederum auf weniger physische Partitionen abgebildet werden. Bei diesem Ansatz sucht eine Anwendung die Daten mit Hilfe eines Shard-Schlüssels, der auf einen virtuellen Shard verweist, und das System ordnet virtuelle Shards transparent physischen Partitionen zu. Die Zuordnung zwischen einem virtuellen Shard und einer physischen Partition kann sich ändern, ohne dass der Anwendungscode geändert werden muss, um einen anderen Satz von Shard-Schlüsseln zu verwenden.
Bereichsstrategie: Bei dieser Strategie werden zusammengehörige Elemente im selben Shard gruppiert und nach Shard-Schlüssel angeordnet. Die Shard-Schlüssel sind aufeinander folgend. Sie eignet sich für Anwendungen, die häufig Sätze von Datenelementen mithilfe von Bereichsabfragen (Abfragen, die einen Satz von Datenelementen für einen Shard-Schlüssel zurückgeben, der in einen bestimmten Bereich liegt) abrufen müssen. Wenn eine Anwendung z. B. regelmäßig alle in einem bestimmten Monat aufgegebenen Bestellungen finden muss, können diese Daten schneller abgerufen werden, wenn alle Bestellungen eines Monats im selben Shard nach Datum und Zeit gespeichert werden. Wenn jede Bestellung in einem anderen Shard gespeichert wurde, müssten sie einzeln über eine große Anzahl von Punktabfragen (Abfragen, die ein einzelnes Datenelement zurückgeben) abgeholt werden. Die folgende Abbildung veranschaulicht das Speichern von sequentiellen Datensätzen (Bereiche) in Shards.
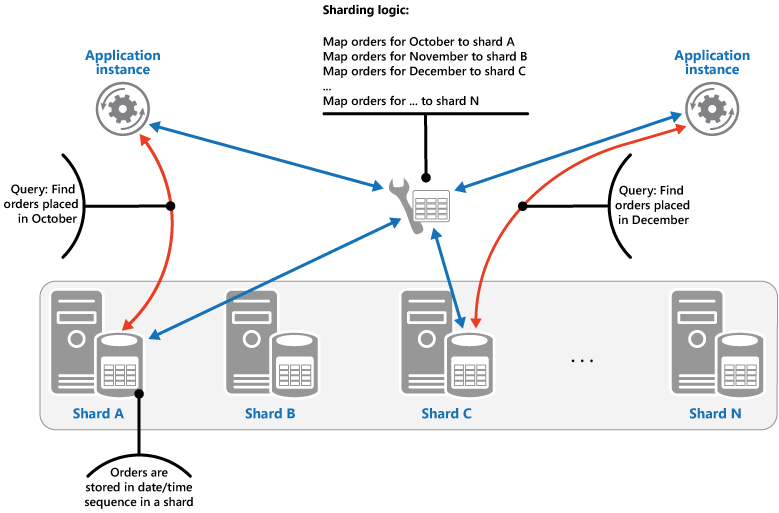
In diesem Beispiel ist der Shard-Schlüssel ein zusammengesetzter Schlüssel, der den Bestellmonat als wichtigstes Element enthält, gefolgt vom Bestelltag und der Uhrzeit. Die Daten für Bestellungen werden natürlich sortiert, wenn neue Bestellungen erstellt und einem Shard hinzugefügt werden. Einige Datenspeicher unterstützen zweiteilige Shard-Schlüssel, die ein Partitionsschlüsselelement enthalten, das den Shard kennzeichnet, und einen Zeilenschlüssel, der ein Element im Shard eindeutig kennzeichnet. Daten werden im Shard normalerweise nach Zeilenschlüssel gespeichert. Elemente, die Bereichsabfragen unterliegen und gruppiert werden müssen, können einen Shard-Schlüssel verwenden, der denselben Wert für den Partitionsschlüssel, aber einen eindeutigen Wert für den Zeilenschlüssel hat.
Hashstrategie: Ziel dieser Strategie ist es, die Wahrscheinlichkeit von sogenannten Hotspots (Shards, die überproportional belastet werden) zu reduzieren. Verteilt die Daten in einer Weise auf die Shards, die ein Gleichgewicht zwischen der Größe der einzelnen Shards und der durchschnittlichen Workload erreicht, die für die einzelnen Shards auftritt. Die Sharding-Logik berechnet den Shard für die Speicherung eines Elements auf Grundlage eines Hashs von mindestens einem Attribut der Daten. Die gewählte Hashfunktion sollte die Daten gleichmäßig über die Shards verteilen, möglicherweise durch die Einführung eines zufälligen Elements in die Berechnung. Die nächste Abbildung veranschaulicht das Sharding für Mandantendaten auf Grundlage des Hashs der Mandanten-IDs.
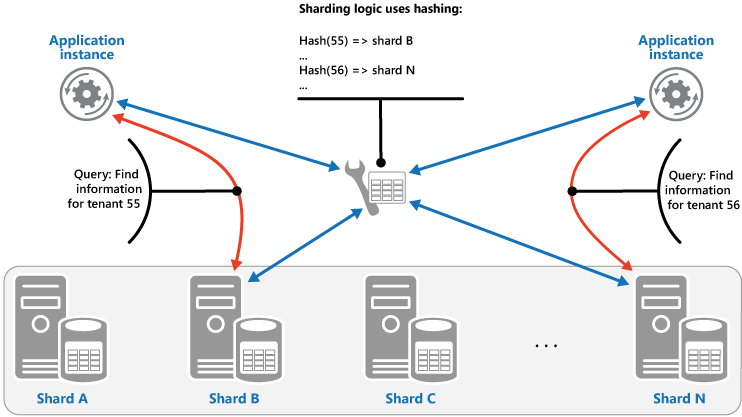
Um den Vorteil der Hash-Strategie gegenüber anderen Sharding-Strategien zu verstehen, betrachten Sie, wie eine mandantenfähige Anwendung, die neue Mandanten nacheinander anmeldet, die Mandanten den Shards im Datenspeicher zuweisen könnte. Bei Verwendung der Bereichsstrategie werden die Daten für die Mandanten 1 bis n alle in Shard A gespeichert, während die Daten für die Mandanten n+1 bis m alle in Shard B gespeichert werden usw. Wenn die zuletzt registrierten Mandanten auch die aktivsten sind, wird die meiste Datenaktivität in einer kleinen Anzahl von Shards erfolgen, was zu überproportional belasteten Shards führen kann. Im Gegensatz dazu ordnet die Hashstrategie Mandanten auf Basis eines Hashs ihrer Mandanten-ID zu Shards zu. Das bedeutet, dass sequentielle Mandanten höchstwahrscheinlich verschiedenen Shards zugeordnet werden, die die Workload auf sie verteilen. Die vorherige Abbildung zeigt dies für die Mandanten 55 und 56.
Die drei Sharding-Strategien weisen die folgenden Vorteile und Aspekte auf:
Suche: Bietet eine umfassendere Kontrolle über die Konfiguration und Verwendung der Shards. Die Verwendung virtueller Shards reduziert die Auswirkungen beim Neuverteilen von Daten, da neue physische Partitionen hinzugefügt werden können, um die Workloads auszugleichen. Die Zuordnung zwischen einem virtuellen Shard und den physischen Partitionen, die den Shard implementieren, kann geändert werden, ohne den Anwendungscode zu beeinflussen, der einen Shard-Schlüssel zum Speichern und Abrufen von Daten verwendet. Die Suche nach Shard-Speicherorten kann einen zusätzlichen Aufwand verursachen.
Bereich: Diese Strategie ist einfach zu implementieren und eignet sich gut für Bereichsabfragen, da sie oft mehrere Datenelemente von einem einzelnen Shard in einem einzigen Vorgang abrufen können. Diese Strategie bietet eine einfachere Datenverwaltung. Wenn sich Benutzer z. B. in der gleichen Region im selben Shard befinden, können Updates in den jeweiligen Zeitzonen basierend auf dem lokalen Workload- und Bedarfsmuster geplant werden. Diese Strategie bietet jedoch keinen optimalen Ausgleich zwischen den Shards. Die Neuverteilung für Shards ist schwierig und behebt möglicherweise nicht das Problem ungleichmäßiger Workloads, wenn der Großteil der Aktivität für angrenzende Shard-Schlüssel anfällt.
Hash: Diese Strategie bietet eine höhere Wahrscheinlichkeit, dass Daten und Workloads gleichmäßiger verteilt werden. Das Routing von Anforderungen kann direkt über die Hashfunktion durchgeführt werden. Die Verwaltung einer Zuordnung ist nicht erforderlich. Beachten Sie, dass die Hashberechnung möglicherweise einen zusätzlichen Aufwand darstellt. Die Neuverteilung auf die Shards ist zudem schwierig.
Die geläufigsten Sharding-Systeme implementieren einen der oben beschriebenen Ansätze, aber Sie sollten auch die Geschäftsanforderungen Ihrer Anwendungen und deren Datennutzungsmuster berücksichtigen. Zum Beispiel in einer mandantenfähigen Anwendung:
Sie können Daten auf Basis der Workload auf Shards verteilen. Sie könnten die Daten für sehr unbeständige Mandanten in separaten Shards isolieren. Die Geschwindigkeit des Datenzugriffs könnte dadurch für andere Mandanten verbessert werden.
Sie können die Daten auf Basis des Standorts der Mandanten auf Shards verteilen. Sie können die Daten von Mandanten in einer bestimmten geografischen Region zur Sicherung und Wartung während der Nebenzeiten in dieser Region offline nehmen, während die Daten von Mandanten in anderen Regionen während ihrer Geschäftszeiten online und zugänglich bleiben.
Hochwertige Mandanten könnten ihre eigenen privaten, leistungsstarken und wenig belasteten Shards zugewiesen bekommen, während Mandanten mit geringerem Wert sich dicht gepackte, stark ausgelastete Shards teilen müssten.
Die Daten für Mandanten, die ein hohes Maß an Datenisolation und Datenschutz benötigen, können auf einem vollständig separaten Server gespeichert werden.
Skalierungs- und Datenverschiebungsvorgänge
Jede der Sharding-Strategien umfasst unterschiedliche Funktionen und Komplexitätsstufen für das Ab- und Aufskalieren, für die Datenverschiebung und die Aufrechterhaltung des Zustands.
Die Suchstrategie ermöglicht Skalierungs- und Datenverschiebungsvorgänge auf Benutzerebene, die entweder online oder offline ausgeführt werden. Die Methode besteht darin, einige oder alle Benutzeraktivitäten zu unterbrechen (z. B. während der Nebenzeiten), die Daten auf die neue virtuelle Partition oder den physischen Shard zu verschieben, die Zuordnungen zu ändern, alle Caches, die diese Daten enthalten, außer Kraft zu setzen oder zu aktualisieren und dann die Benutzeraktivität wieder aufzunehmen. Dieser Typ von Vorgang kann oftmals zentral verwaltet werden. Die Suchstrategie setzt voraus, dass der Zustand in hohem Maße zwischenspeicherbar und replizierbar ist.
Die Bereichsstrategie bedeutet einige Einschränkungen für Skalierungs- und Datenverschiebungsvorgänge, die typischerweise ausgeführt werden müssen, wenn ein Teil oder der gesamte Datenspeicher offline ist, da die Daten über die Shards hinweg verteilt und zusammengeführt werden müssen. Das Verschieben der Daten zur Neuverteilung von Shards kann das Problem der ungleichmäßigen Workload nicht lösen, wenn der Großteil der Aktivität auf benachbarte Shard-Schlüssel oder Datenbezeichner entfällt, die sich im gleichen Bereich befinden. Die Bereichsstrategie könnte auch erfordern, dass ein gewisser Zustand beibehalten wird, um Bereiche den physischen Partitionen zuzuordnen.
Die Hashstrategie gestaltet Skalierungs- und Datenverschiebungsvorgänge komplizierter, da die Partitionsschlüssel Hashes der Shard-Schlüssel oder Datenbezeichner sind. Der neue Speicherort der einzelnen Shards muss über die Hashfunktion ermittelt oder die Funktion so geändert werden, dass die ordnungsgemäßen Zuordnungen vorgenommen werden. Die Hashstrategie erfordert jedoch keine Aufrechterhaltung des Zustands.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
Das Sharding ergänzt andere Formen der Partitionierung, z. B. die vertikale und die funktionale Partitionierung. Ein einzelner Shard kann z. B. vertikal partitionierte Elemente enthalten und eine funktionale Partition kann als mehrere Shards implementiert werden. Weitere Informationen zur Partitionierung finden Sie im Leitfaden zur Datenpartitionierung.
Sorgen Sie für ausgeglichene Shards, die alle ein ähnliches E/A-Aufkommen bewältigen müssen. Wenn Daten eingefügt und gelöscht werden, ist es erforderlich, die Shards regelmäßig neu auszugleichen, um eine gleichmäßige Verteilung zu gewährleisten und die Wahrscheinlichkeit von überproportional belasteten Shards zu verringern. Die Neuverteilung kann sich als kostenintensiver Vorgang erweisen. Um die Notwendigkeit der Neuverteilung zu reduzieren, planen Sie das Wachstum ein, indem Sie sicherstellen, dass jeder Shard genügend freien Speicherplatz bietet, um das erwartete Ausmaß an Änderungen zu bewerkstelligen. Sie sollten auch Strategien und Skripts entwickeln, mit denen Sie Shards bei Bedarf schnell ausgleichen können.
Verwenden Sie für den Shard-Schlüssel entsprechend beständige Daten. Wenn sich der Shard-Schlüssel ändert, muss das entsprechende Datenelement möglicherweise zwischen den Shards hin- und herbewegt werden, was den Aufwand für Aktualisierungsvorgänge erhöht. Vermeiden Sie es daher, den Shard-Schlüssel auf potenziell unbeständige Informationen zu stützen. Suchen Sie stattdessen nach Attributen, die unveränderlich sind oder auf natürliche Weise einen Schlüssel bilden.
Stellen Sie sicher, dass Shard-Schlüssel eindeutig sind. Vermeiden Sie z. B. die Verwendung von Feldern mit automatischer Inkrementierung als Shard-Schlüssel. Bei manchen Systemen können automatisch inkrementierte Felder nicht über Shards hinweg koordiniert werden, was dazu führen kann, dass Elemente in verschiedenen Shards den gleichen Shard-Schlüssel aufweisen.
Automatisch inkrementierte Werte in anderen Feldern, die keine Shard-Schlüssel sind, können ebenfalls Probleme verursachen. Wenn Sie z. B. automatisch inkrementierte Felder verwenden, um eindeutige IDs zu generieren, können zwei verschiedene Elemente, die sich in verschiedenen Shards befinden, dieselbe ID erhalten.
Unter Umständen ist es nicht möglich, einen Shard-Schlüssel zu entwerfen, der den Anforderungen jeder möglichen Abfrage in Bezug auf die Daten entspricht. Verteilen Sie die Daten auf Shards, um die am häufigsten ausgeführten Abfragen zu unterstützen, und erstellen Sie bei Bedarf sekundäre Indextabellen, um Abfragen zu unterstützen, die Daten mithilfe von Kriterien abrufen, die auf Attributen basieren, die nicht Teil des Shard-Schlüssels sind. Weitere Informationen finden Sie unter Index Table Pattern (Indextabellenmuster).
Abfragen, die nur auf einen einzelnen Shard zugreifen, sind effizienter als Abfragen, die Daten von mehreren Shards abrufen. Vermeiden Sie es daher, ein Sharding-System zu implementieren, das dazu führt, dass Anwendungen eine große Anzahl von Abfragen ausführen, die Daten aus verschiedenen Shards zusammenführen. Denken Sie daran, dass ein einzelner Shard die Daten für mehrere Typen von Entitäten enthalten kann. Ziehen Sie in Betracht, Ihre Daten zu denormalisieren, um verwandte Entitäten, die häufig gemeinsam abgefragt werden (z. B. die Details von Kunden und Bestellungen, die sie aufgegeben haben), im selben Shard zu speichern, um die Anzahl der separaten Lesezugriffe zu reduzieren, die eine Anwendung ausführt.
Wenn eine Entität in einem Shard auf eine Entität verweist, die in einem anderen Shard gespeichert ist, fügen Sie den Shard-Schlüssel für die zweite Entität als Teil des Schemas für die erste Entität hinzu. Dies kann dazu beitragen, die Leistung von Abfragen zu verbessern, die über Shards hinweg auf verwandte Daten verweisen.
Wenn eine Anwendung Abfragen durchführen muss, die Daten von mehreren Shards abrufen, können diese Daten möglicherweise über parallele Aufgaben abgerufen werden. Beispiele hierfür sind Auffächerungsabfragen, bei denen Daten aus mehreren Shards parallel abgerufen und dann in ein einzelnes Ergebnis aggregiert werden. Dieser Ansatz erhöht jedoch zwangsläufig die Komplexität der Datenzugriffslogik einer Lösung.
Für viele Anwendungen kann es effizienter sein, eine größere Anzahl von kleinen Shards zu erzeugen als eine kleine Anzahl von großen Shards, da sie bessere Möglichkeiten für den Lastausgleich bieten. Dies kann auch hilfreich sein, wenn Sie erwarten, dass Shards von einem physischen Speicherort zu einem anderen migriert werden müssen. Kleine Shards können schneller als große Shards verschoben werden.
Stellen Sie sicher, dass die für jeden Shard-Speicherknoten verfügbaren Ressourcen ausreichen, um den Anforderungen an die Skalierbarkeit im Hinblick auf die Größe der Daten und den Durchsatz zu entsprechen. Weitere Informationen finden Sie im Abschnitt „Entwerfen von Partitionen für Skalierbarkeit“ im Leitfaden zur Datenpartitionierung.
Ziehen Sie in Betracht, entsprechende Referenzdaten auf alle Shards zu replizieren. Wenn ein Vorgang, der Daten von einem Shard abruft, auch auf statische oder langsam zu verschiebende Daten als Teil derselben Abfrage verweist, fügen Sie diese Daten dem Shard hinzu. Die Anwendung kann dann auf einfache Weise alle Daten für die Abfrage holen, ohne einen zusätzlichen Roundtrip zu einem separaten Datenspeicher durchführen zu müssen.
Wenn in mehreren Shards gespeicherte Referenzdaten geändert werden, muss das System diese Änderungen über alle Shards hinweg synchronisieren. Während dieser Synchronisation kann es zu Inkonsistenzen im System kommen. In diesem Fall sollten Sie Ihre Anwendungen so gestalten, dass sie damit entsprechend umgehen können.
Es kann schwierig sein, die referentielle Integrität und Konsistenz zwischen den Shards aufrechtzuerhalten, daher sollten Sie Vorgänge, die Daten in mehreren Shards betreffen, minimieren. Wenn eine Anwendung Daten über mehrere Shards hinweg ändern muss, prüfen Sie, ob eine umfassende Datenkonsistenz tatsächlich erforderlich ist. Stattdessen ist eine gängige Vorgehensweise in der Cloud, letztendliche Konsistenz zu implementieren. Die Daten in den einzelnen Partitionen werden separat aktualisiert, und die Anwendungslogik muss die Verantwortung dafür übernehmen, dass die Aktualisierungen erfolgreich abgeschlossen werden. Zudem ist sie dafür zuständig, die Inkonsistenzen zu behandeln, die durch die Abfrage von Daten während eines letztendlich konsistenten Vorgangs entstehen können. Weitere Informationen zum Implementieren von letztlicher Konsistenz finden Sie unter Data Consistency Primer (Grundlagen der Datenkonsistenz).
Die Konfiguration und Verwaltung einer großen Anzahl von Shards kann eine Herausforderung darstellen. Aufgaben wie Überwachung, Sicherung, Konsistenzprüfung, Protokollierung oder Überprüfung müssen auf mehreren Shards und Servern durchgeführt werden, die sich möglicherweise an mehreren Standorten befinden. Diese Aufgaben werden wahrscheinlich mithilfe von Skripts oder anderen Automatisierungslösungen realisiert, aber das kann die zusätzlichen Verwaltungsanforderungen nicht vollständig ausschließen.
Shards können so positioniert werden, dass die darin befindlichen Daten in der Nähe der Instanzen einer Anwendung liegen, die diese verwenden. Dieser Ansatz kann die Leistung erheblich verbessern, erfordert jedoch zusätzliche Überlegungen für Aufgaben, die auf mehrere Shards an verschiedenen Standorten zugreifen müssen.
Verwendung dieses Musters
Verwenden Sie dieses Muster, wenn ein Datenspeicher voraussichtlich über die Ressourcen hinaus skaliert werden muss, die für einen einzelnen Speicherknoten zur Verfügung stehen, oder um die Leistung zu verbessern, indem Sie mögliche Konflikte in einem Datenspeicher verringern.
Hinweis
Der primäre Fokus des Shardings liegt auf der Verbesserung von Leistung und Skalierbarkeit eines Systems, aber als Nebeneffekt kann es auch die Verfügbarkeit verbessern, da die Daten auf separate Partitionen aufgeteilt werden. Ein Ausfall einer Partition hindert eine Anwendung nicht unbedingt daran, auf Daten in anderen Partitionen zuzugreifen. Zudem kann ein Bediener die Wartung oder Wiederherstellung einer oder mehrerer Partitionen durchführen, ohne die gesamten Daten für eine Anwendung unzugänglich zu machen. Weitere Informationen finden Sie im Leitfaden zur Datenpartitionierung.
Workloadentwurf
Ein Architekt sollte evaluieren, wie das Sharding-Muster im Design seiner Workloads verwendet werden kann, um die Ziele und Prinzipien zu erreichen, die in den Säulen des Azure Well-Architected Framework behandelt werden. Zum Beispiel:
| Säule | So unterstützt dieses Muster die Säulenziele |
|---|---|
| Zuverlässigkeitsdesignentscheidungen tragen dazu bei, dass Ihre Workload ausfallsicher wird und dass sie nach einem Ausfall wieder in einen voll funktionsfähigen Zustand zurückkehrt. | Da die Daten oder die Verarbeitung auf dem Shard isoliert sind, bleibt eine Störung in einem Shard auf diesen Shard beschränkt. - RE:06 Datenpartitionierung - RE:07 Selbsterhaltung |
| Die Kostenoptimierung konzentriert sich auf Erhaltung und Verbesserung der Rendite Ihrer Workload. | Ein System, das Shards implementiert, profitiert oft von der Verwendung mehrerer Instanzen von weniger teuren Rechen- oder Speicherressourcen anstelle einer einzigen teureren Ressource. In vielen Fällen können Sie mit dieser Konfiguration Geld sparen. - CO:07 Komponentenkosten |
| Die Leistungseffizienz hilft Ihrer Workload, Anforderungen effizient durch Optimierungen in Skalierung, Daten und Code zu erfüllen. | Wenn Sie Sharding in Ihrer Skalierungsstrategie verwenden, werden die Daten oder die Verarbeitung auf einem Shard isoliert, so dass sie nur mit anderen Anfragen, die an diesen Shard gerichtet sind, um Ressourcen konkurrieren. Sie können auch Sharding verwenden, um die Daten nach geografischen Gesichtspunkten zu optimieren. - PE:05 Skalierung und Partitionierung - PE:08 Datenleistung |
Berücksichtigen Sie wie bei jeder Designentscheidung alle Kompromisse im Hinblick auf die Ziele der anderen Säulen, die mit diesem Muster eingeführt werden könnten.
Beispiel
Das folgende Beispiel in C# verwendet eine Reihe von SQL Server-Datenbanken, die als Shards fungieren. Jede Datenbank enthält eine Teilmenge der Daten, die von einer Anwendung verwendet werden. Die Anwendung ruft über Shards verteilte Daten mithilfe einer eigenen Sharding-Logik (dies ist ein Beispiel für eine Auffächerungsabfrage) ab. Die Details der Daten, die sich in jedem Shard befinden, werden von einer Methode namens GetShards zurückgegeben. Diese Methode gibt eine aufzählbare Liste von ShardInformation-Objekten zurück, wobei der Typ ShardInformation einen Bezeichner für jeden Shard und die SQL Server-Verbindungszeichenfolge enthält, die eine Anwendung verwenden sollte, um sich mit dem Shard zu verbinden (die Verbindungszeichenfolgen werden im Codebeispiel nicht angezeigt).
private IEnumerable<ShardInformation> GetShards()
{
// This retrieves the connection information from a shard store
// (commonly a root database).
return new[]
{
new ShardInformation
{
Id = 1,
ConnectionString = ...
},
new ShardInformation
{
Id = 2,
ConnectionString = ...
}
};
}
Der folgende Code zeigt, wie die Anwendung die Liste der ShardInformation-Objekte verwendet, um eine Abfrage auszuführen, die Daten von den einzelnen Shards gleichzeitig abruft. Die Details der Abfrage werden nicht angezeigt, aber in diesem Beispiel enthalten die abgerufenen Daten eine Zeichenfolge, die Informationen wie den Namen eines Kunden enthalten könnte, wenn die Shards die Details von Kunden enthalten. Die Ergebnisse werden in eine ConcurrentBag-Sammlung aggregiert und von der Anwendung verarbeitet.
// Retrieve the shards as a ShardInformation[] instance.
var shards = GetShards();
var results = new ConcurrentBag<string>();
// Execute the query against each shard in the shard list.
// This list would typically be retrieved from configuration
// or from a root/primary shard store.
Parallel.ForEach(shards, shard =>
{
// NOTE: Transient fault handling isn't included,
// but should be incorporated when used in a real world application.
using (var con = new SqlConnection(shard.ConnectionString))
{
con.Open();
var cmd = new SqlCommand("SELECT ... FROM ...", con);
Trace.TraceInformation("Executing command against shard: {0}", shard.Id);
var reader = cmd.ExecuteReader();
// Read the results in to a thread-safe data structure.
while (reader.Read())
{
results.Add(reader.GetString(0));
}
}
});
Trace.TraceInformation("Fanout query complete - Record Count: {0}",
results.Count);
Nächste Schritte
Die folgenden Richtlinien sind unter Umständen beim Implementieren dieses Musters ebenfalls relevant:
- Data Consistency Primer (Grundlagen der Datenkonsistenz). Es ist möglicherweise erforderlich, die Konsistenz der Daten, die über verschiedene Shards verteilt sind, zu erhalten. Fasst die Probleme bei der Aufrechterhaltung von Konsistenz in verteilten Daten zusammen und beschreibt die Vor- und Nachteile der verschiedenen Konsistenzmodelle.
- Data Partitioning Guidance (Leitfaden zur Datenpartitionierung). Das Sharding eines Datenspeichers kann eine Reihe von zusätzlichen Problemen mit sich bringen. Beschreibt diese Probleme in Bezug auf die Partitionierung von Datenspeichern in der Cloud, um die Skalierbarkeit zu verbessern, Konflikte zu verringern und die Leistung zu optimieren.
Zugehörige Ressourcen
Die folgenden Muster sind unter Umständen bei der Implementierung dieses Musters ebenfalls relevant:
- Index Table Pattern (Indextabellenmuster): Mitunter ist es nicht möglich, Abfragen allein durch die Gestaltung des Shard-Schlüssels vollständig zu unterstützen. Ermöglicht einer Anwendung das schnelle Abrufen von Daten aus einem großen Datenspeicher durch die Angabe eines anderen Schlüssels als des Shard-Schlüssels.
- Muster „Materialisierte Sichten“: Um die Leistung einiger Abfragevorgänge aufrechtzuerhalten, ist es sinnvoll, materialisierte Ansichten zu erstellen, die Daten aggregieren und zusammenfassen. Dies ist insbesondere hilfreich, wenn diese zusammenfassenden Daten auf Informationen basieren, die über Shards verteilt sind. Beschreibt das Erstellen und Füllen dieser Ansichten.