Ereignisanalyse und -visualisierung mit Azure Monitor-Protokollen
Azure Monitor-Protokolle sammeln und analysieren Telemetriedaten von Anwendungen und Diensten, die in der Cloud gehostet werden. Darüber hinaus sind Analysetools verfügbar, um die Verfügbarkeit und Leistung dieser Anwendungen und Dienste maximieren zu können. In diesem Artikel wird beschrieben, wie Sie Abfragen in Azure Monitor-Protokolle ausführen, um einen Einblick in den Cluster zu erhalten und Probleme zu beheben. Folgende allgemeine Fragen werden berücksichtigt:
- Wie behebe ich Probleme bei Integritätsereignissen?
- Wie weiß ich, dass ein Knoten ausfällt?
- Wie finde ich heraus, ob die Dienste der Anwendung gestartet oder beendet wurden?
Hinweis
Dieser Artikel wurde kürzlich aktualisiert, um den Begriff Azure Monitor-Protokolle anstelle von Log Analytics aufzunehmen. Protokolldaten werden immer noch in einem Log Analytics-Arbeitsbereich gespeichert und weiterhin mit dem gleichen Log Analytics-Dienst erfasst und analysiert. Die Terminologie hat sich geändert, um der Rolle von Protokollen in Azure Monitor besser Rechnung zu tragen. Weitere Informationen finden Sie unter Terminologieänderungen bei Azure Monitor.
Übersicht über den Log Analytics-Arbeitsbereich
Hinweis
Obwohl der Diagnosespeicher bei der Clustererstellung standardmäßig aktiviert wird, müssen Sie den Log Analytics-Arbeitsbereich dennoch so einrichten, dass er aus dem Diagnosespeicher gelesen wird.
Azure Monitor-Protokolle sammeln Daten von verwalteten Ressourcen, z.B. von einer Azure Storage-Tabelle oder einem Agent, und verwalten sie in einem zentralen Repository. Die Daten können dann für Analyse, Warnungen und Visualisierung oder für den weiteren Export verwendet werden. Azure Monitor-Protokolle unterstützen Ereignisse, Leistungsdaten oder jegliche anderen benutzerdefinierten Daten. Überprüfen Sie die Schritte zum Konfigurieren der Diagnoseerweiterung zum Aggregieren von Ereignissen und die Schritte zum Erstellen eines Log Analytics-Arbeitsbereichs zum Lesen der Ereignisse im Speicher, um sicherzustellen, dass Daten in Azure Monitor-Protokolle geschrieben werden.
Nachdem Daten von Azure Monitor-Protokollen empfangen wurden, verfügt Azure über mehrere Überwachungslösungen. Dabei handelt es sich um vorkonfigurierte Lösungen oder operative Dashboards zum Überwachen eingehender Daten, die an verschiedene Szenarien angepasst sind. Dazu gehören eine Service Fabric-Analyselösung und eine Containerlösung. Dies sind die beiden wichtigsten Lösungen für die Diagnose und Überwachung bei Verwendung von Service Fabric-Clustern. In diesem Artikel wird die Verwendung der Service Fabric-Analyse-Lösung beschrieben, die im Arbeitsbereich erstellt wird.
Zugriff auf die Service Fabric-Analyse-Lösung
Navigieren Sie im Azure-Portal zu der Ressourcengruppe, in der Sie die Service Fabric-Analyse-Lösung erstellt haben.
Wählen Sie die Ressource ServiceFabric<OMS-Arbeitsbereichsname> aus.
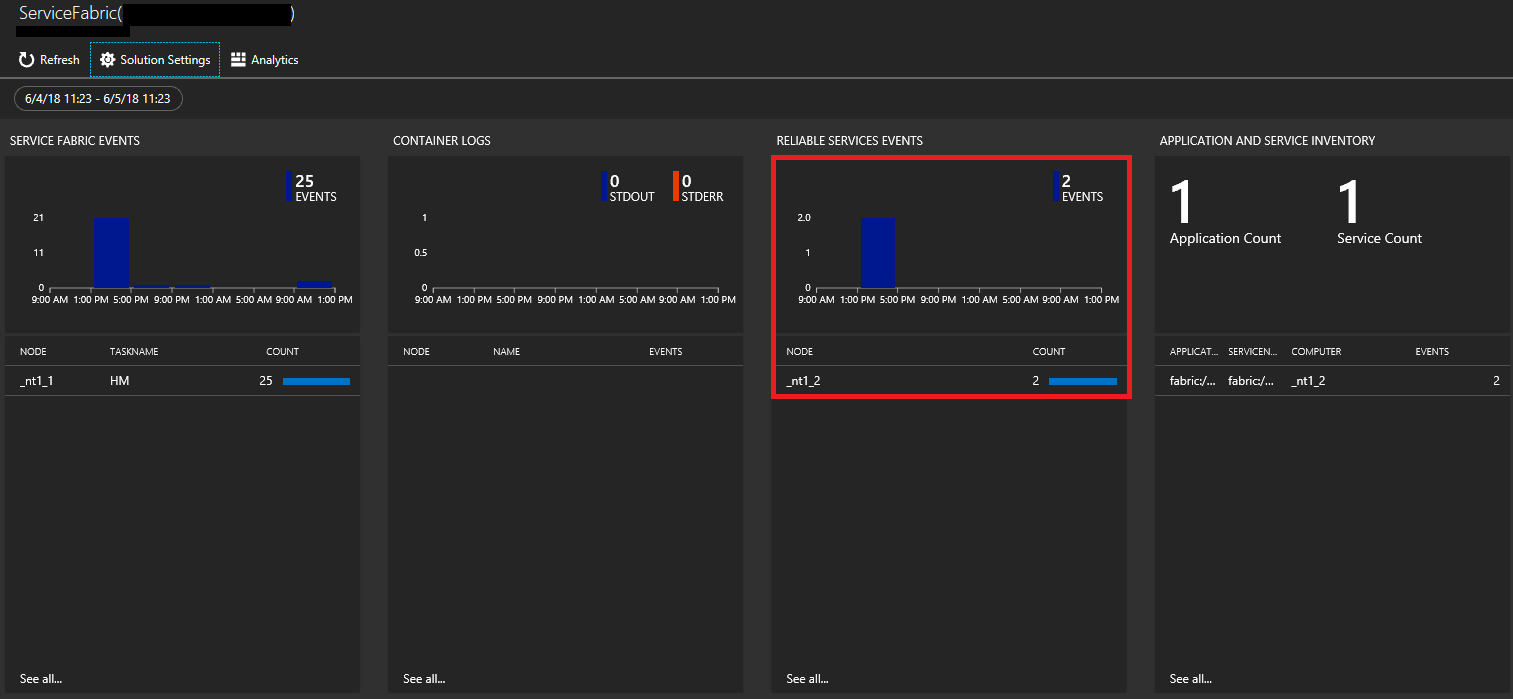
In Summary werden Kacheln in Form eines Graphs für jede der aktivierten Lösungen angezeigt, dies schließt Service Fabric ein. Klicken Sie auf den Graph Service Fabric, um mit der Service Fabric-Analyse-Lösung fortzufahren.
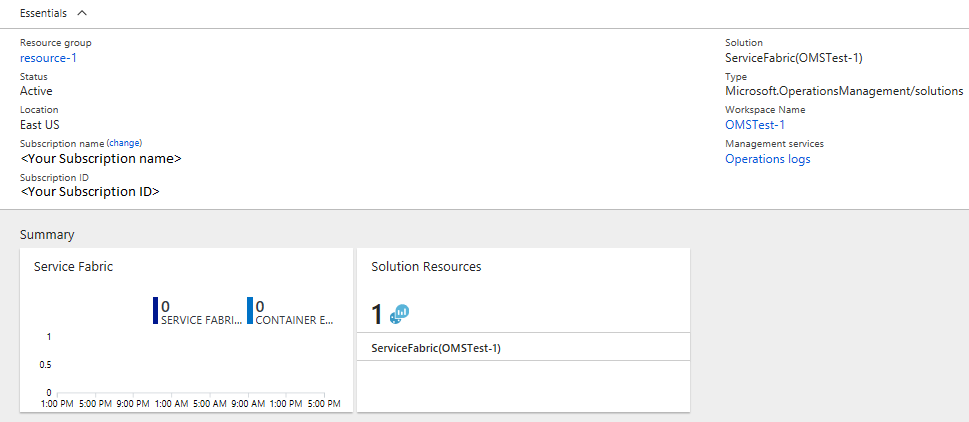
In der folgenden Abbildung ist die Startseite der Service Fabric-Analyse-Lösung dargestellt. Diese Startseite bietet eine Momentaufnahmeansicht der Vorgänge im Cluster.
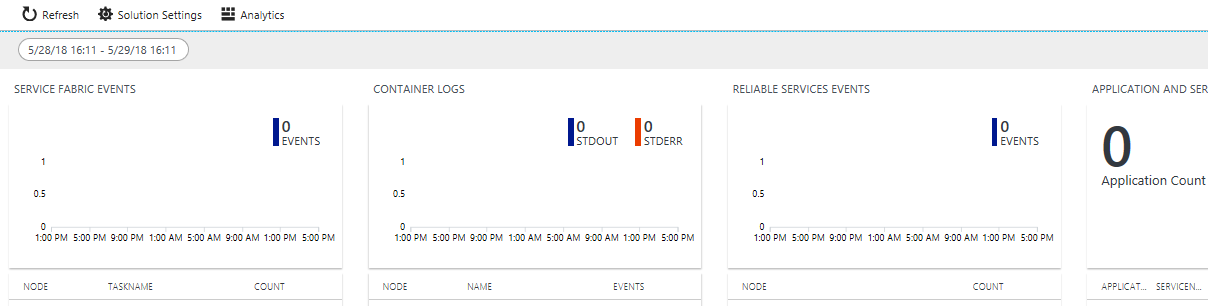
Wenn Sie die Diagnose bei der Clustererstellung aktiviert haben, werden folgende Ereignisse angezeigt:
- Service Fabric-Clusterereignisse
- Ereignisse des Reliable Actors-Programmiermodells
- Ereignisse des Reliable Services-Programmiermodells
Hinweis
Zusätzlich zu den Service Fabric-Ereignissen können durch das Aktualisieren der Konfiguration der Diagnoseerweiterung detailliertere Systemereignisse erfasst werden.
Anzeigen von Service Fabric-Ereignissen einschließlich Aktionen auf Knoten
Klicken Sie auf der Seite „Service Fabric-Analyse“ auf den Graphen für Service Fabric-Ereignisse.
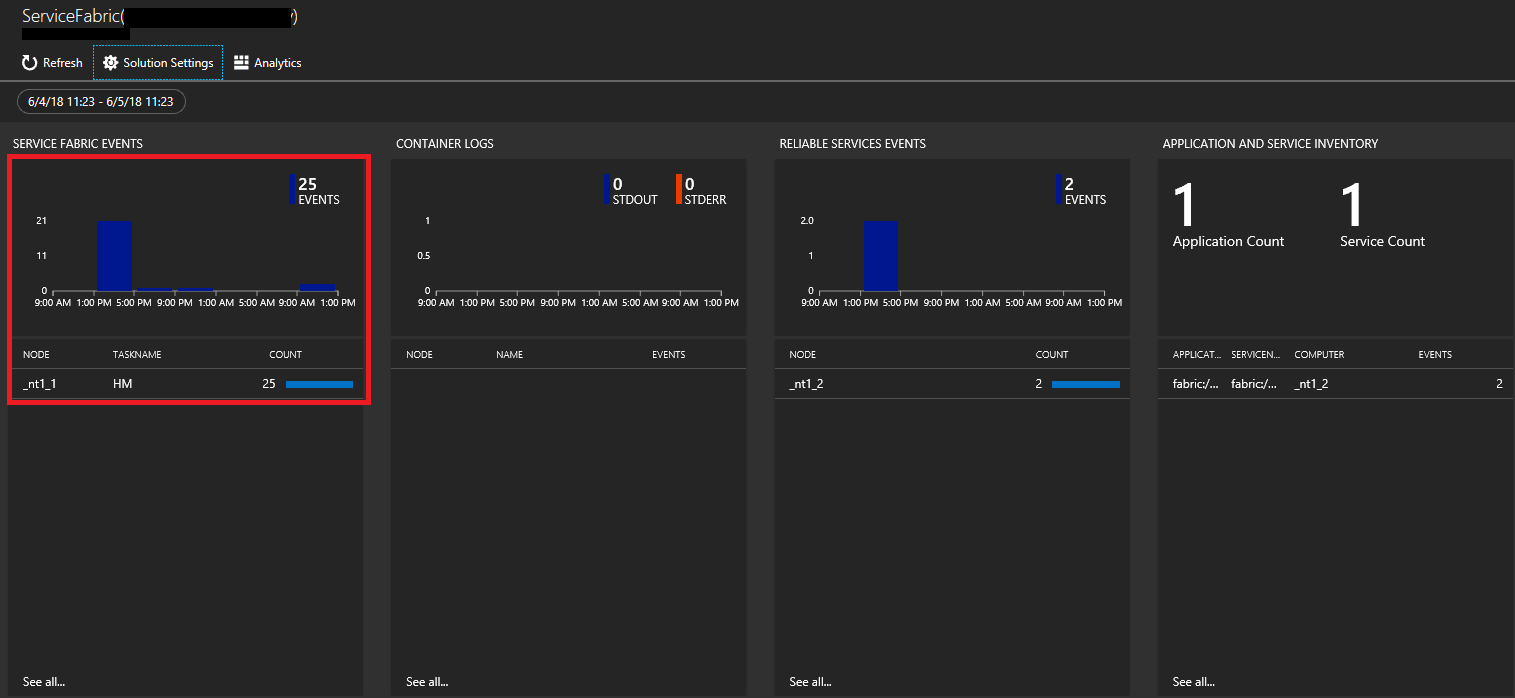
Klicken Sie auf Liste, um die Ereignisse in einer Liste anzuzeigen. In der Liste werden alle gesammelten Systemereignisse angezeigt. Zur Referenz: Diese stammen aus WADServiceFabricSystemEventsTable im Azure Storage-Konto. Auch die Reliable Services- und Reliable Actors-Ereignisse, die als Nächstes angezeigt werden, stammen aus diesen entsprechenden Tabellen.
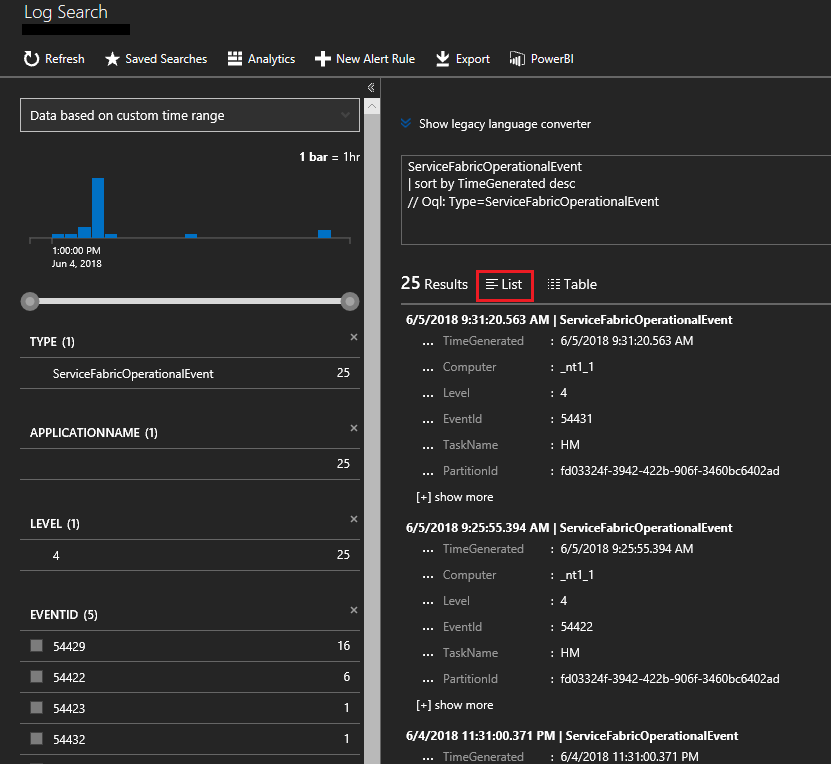
Alternativ können Sie auf die Lupe links klicken und mit der Abfragesprache Kusto die gewünschten Ereignisse suchen. Um beispielsweise alle Aktionen zu suchen, die im Cluster für Knoten durchgeführt wurden, können Sie die folgende Abfrage verwenden. Die unten verwendeten Ereignis-IDs finden Sie in der Referenz der Betriebskanalprotokolle.
ServiceFabricOperationalEvent
| where EventId < 25627 and EventId > 25619
Sie können Abfragen für viele weitere Felder durchführen, z. B. für bestimmte Knoten (Computer), den Systemdienst (TaskName) usw.
Anzeigen von Service Fabric Reliable Service- und Reliable Actor-Ereignissen
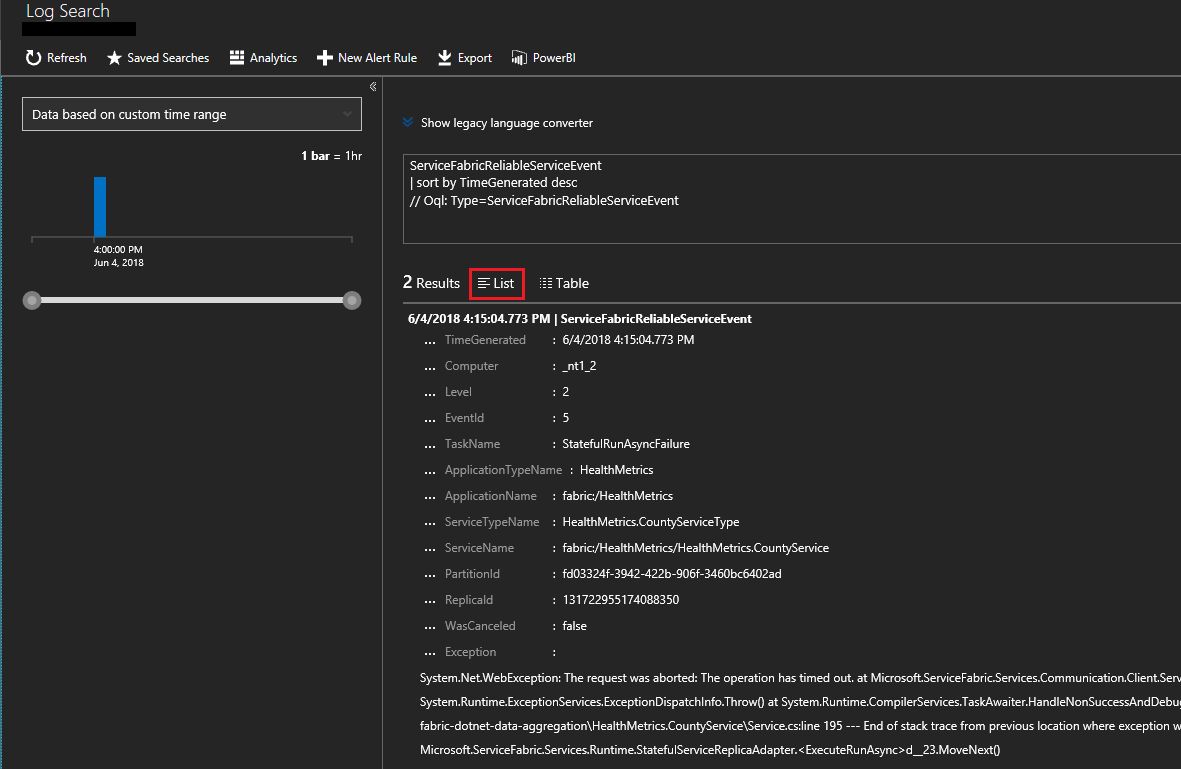
Klicken Sie auf der Seite „Service Fabric-Analyse“ auf den Graphen für Reliable Services.
Klicken Sie auf Liste, um die Ereignisse in einer Liste anzuzeigen. Hier werden Ereignisse aus den zuverlässigen Diensten angezeigt. Es werden unterschiedliche Ereignisse für den Start und das Ende des runasync-Diensts angezeigt. Dies erfolgt normalerweise bei Bereitstellungen und Upgrades.
Reliable Actor-Ereignisse können auf ähnliche Weise angezeigt werden. Um ausführlichere Ereignisse für Reliable Actors zu konfigurieren, müssen Sie scheduledTransferKeywordFilter in der Konfiguration für die Diagnoseerweiterung ändern (siehe unten). Details zu den entsprechenden Werten finden Sie in der Referenz der Reliable Actors-Ereignisse.
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
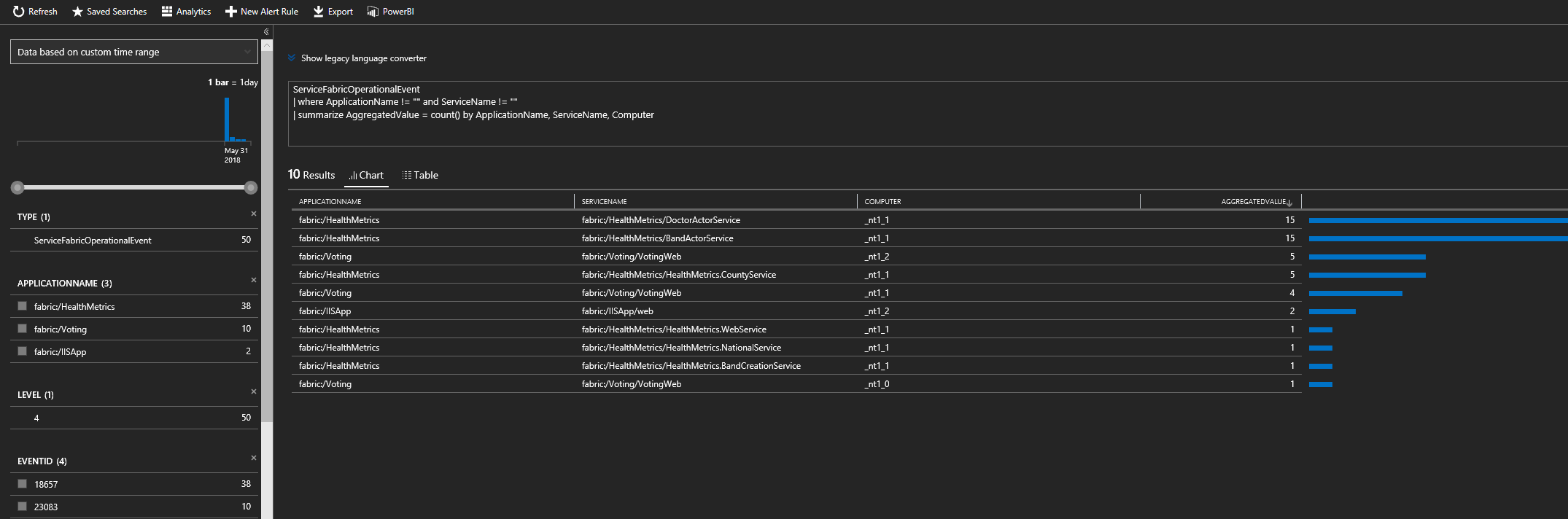
Die Abfragesprache Kusto ist leistungsstark. Eine weitere nützliche Abfrage ist die Suche der Knoten, die die meisten Ereignisse generieren. In der Abfrage im folgenden Screenshot sind mit anhand des spezifischen Diensts und Knotens aggregierte Reliable Services-Ereignisse zu sehen.
Nächste Schritte
- Um die Infrastrukturüberwachung, d.h. Leistungsindikatoren, zu aktivieren, wechseln Sie zu Hinzufügen des Log Analytics-Agents. Der Agent sammelt Leistungsindikatoren und fügt sie dem vorhandenen Arbeitsbereich zu.
- Für lokale Cluster bieten Azure Monitor-Protokolle ein Gateway (HTTP-Weiterleitungsproxy), über das Daten an Azure Monitor-Protokolle gesendet werden können. Weitere Informationen dazu finden Sie unter Verbinden von Computern ohne Internetzugriff über das Log Analytics-Gateway.
- Konfigurieren Sie automatisierte Warnungen für die Erkennung und Diagnose.
- Machen Sie sich mit den Features zur Protokollsuche und -abfrage in Azure Monitor-Protokollen vertraut.
- Eine ausführlichere Übersicht über Azure Monitor-Protokolle und die zugehörigen Optionen finden Sie unter Was ist Azure Monitor-Protokolle?.