Architekturprinzipien
Tipp
Diese Inhalte sind ein Auszug aus dem E-Book „Architect Modern Web Applications with ASP.NET Core and Azure“, das unter .NET Docs oder als kostenlos herunterladbare PDF-Datei verfügbar ist, die offline gelesen werden kann.

„Wenn Architekten Gebäude so bauen würden, wie Programmierer Programme erstellen, würde der erste Specht, der auftauchen würde, die Zivilisation zerstören.“
– Gerald Weinberg
Sie sollten Softwarelösungen mit der Verwaltbarkeit im Hinterkopf entwickeln und entwerfen. Die Prinzipien, die in diesem Artikel erläutert werden, können Ihnen bei Entscheidungen bezüglich der Architektur helfen, wodurch Sie ordentliche und verwaltbare Anwendungen erstellen können. Im Allgemeinen begleiten Sie diese Prinzipien in Richtung der Erstellung von Anwendungen aus einzelnen Komponenten, die nicht eng an andere Teile Ihrer Anwendung gebunden sind, sondern die eher über explizite Schnittstellen oder Nachrichtensysteme kommunizieren.
Allgemeine Entwurfsprinzipien
Separation of Concerns
Ein Leitprinzip beim Entwickeln ist das Separation of Concerns. Dieses Prinzip macht geltend, dass Software basierend auf der Arbeit, die von dieser ausgeführt wird, getrennt werden soll. Ein Beispiel hierfür ist eine Anwendung, die Logik zur Identifizierung von wichtigen Elementen enthält, die dem Benutzer angezeigt werden sollen, und die diese Elemente in einer Art und Weise formatiert, sodass diese auffälliger werden. Das Verhalten, das dafür verantwortlich ist, welche Elemente formatiert werden, sollte von dem Verhalten getrennt werden, das für das Formatieren der Elemente verantwortlich ist, da diese Verhaltensweisen separate Aspekte sind, die nur zufällig miteinander in Verbindung stehen.
Anwendungen können – architektonisch gesehen – logisch erstellt werden, um diesen Prinzipien zu folgen, indem das grundlegende Geschäftsverhalten von der Infrastruktur und der Logik der Benutzeroberfläche getrennt wird. Im Idealfall sollten sich Geschäftsregeln und Logik in einem separaten Projekt befinden, das nicht von anderen Projekten in der Anwendung abhängig sein darf. Diese Trennung trägt dazu bei, dass das Geschäftsmodell leicht zu testen ist und sich weiterentwickeln kann, ohne dass es eng an die Details der Implementierung auf niedriger Ebene gekoppelt ist (sie ist auch dann hilfreich, wenn Infrastrukturbelange von Abstraktionen abhängen, die in der Geschäftsschicht definiert sind). Die Separation of Concerns spielt im Hinblick auf die Verwendung von Schichten in Anwendungsarchitekturen eine wichtige Rolle.
Kapselung
Unterschiedliche Teile einer Anwendung müssen die Kapselung verwenden, um sie von anderen Teile der Anwendung zu isolieren. Anwendungskomponenten und -schichten sollten ihre interne Implementierung anpassen können, ohne dass Fehler bei ihren Komponenten verursacht werden, solange nicht gegen externe Verträge verstoßen wird. Durch die ordnungsgemäße Verwendung der Kapselung kann die lose Kopplung und Modularität in Anwendungsdesigns erreicht werden, da Objekte und Pakete durch alternative Implementierung ersetzt werden können, solange dieselbe Schnittstelle beibehalten wird.
In Klassen erfolgt die Kapselung durch Verringern des Zugriffs auf den internen Zustand der Klasse von außerhalb. Wenn ein Akteur von außerhalb den Zustand des Objekts manipulieren will, sollte dies durch eine klar definierte Funktion (oder einen Eigenschaftensetter) erfolgen und nicht über den Direktzugriff auf den privaten Zustand des Objekts. Anwendungskomponenten und Anwendungen selbst müssen ebenso klar definierte Schnittstellen für die Verwendung durch ihre Komponenten vorweisen und nicht zulassen, dass ihr Zustand direkt geändert werden kann. Durch diesen Ansatz kann das interne Design der Anwendung über einen Zeitraum weiterentwickelt werden, ohne dass die Sorge besteht, dass durch diese Aktion Komponentenfehler auftreten, solange die öffentlichen Verträge bestehen.
Ein veränderlicher globaler Zustand steht im Gegensatz zur Kapselung. Ein Wert, der aus einem veränderlichen globalen Zustand in einer Funktion abgerufen wird, kann in einer anderen Funktion (oder sogar in derselben Funktion) nicht zuverlässig denselben Wert aufweisen. Das Verständnis von Problemen mit veränderlichen globalen Zuständen ist einer der Gründe, warum Programmiersprachen wie C# verschiedene Regeln zur Bereichsdefinition unterstützen, die überall – von Anweisungen über Methoden bis hin zu Klassen – eingesetzt werden. Es ist erwähnenswert, dass datengesteuerte Architekturen, die sich für die Integration innerhalb und zwischen Anwendungen auf eine zentrale Datenbank stützen, selbst von dem durch die Datenbank dargestellten veränderlichen globalen Zustand abhängig sind. Eine wichtige Überlegung beim domänenorientierten Design und einer sauberen Architektur ist die Frage, wie der Zugriff auf Daten gekapselt und wie sichergestellt werden kann, dass der Anwendungszustand nicht durch direkten Zugriff auf das Persistenzformat ungültig wird.
Abhängigkeitsumkehr
Die Abhängigkeitsrichtung innerhalb der Anwendung sollte sich in Richtung der Abstraktion bewegen, nicht in Richtung Implementierungsdetails. Die meisten Anwendungen werden so geschrieben, dass die Kompilierzeitabhängigkeit in Richtung der Runtimeausführung geht und ein Diagramm der direkten Abhängigkeit produziert. Das heißt, wenn Klasse A eine Methode von Klasse B und Klasse B eine Methode von Klasse C aufruft, dann hängt zur Kompilierzeit Klasse A von Klasse B und Klasse B von Klasse C ab, wie in Abbildung 4-1 dargestellt.
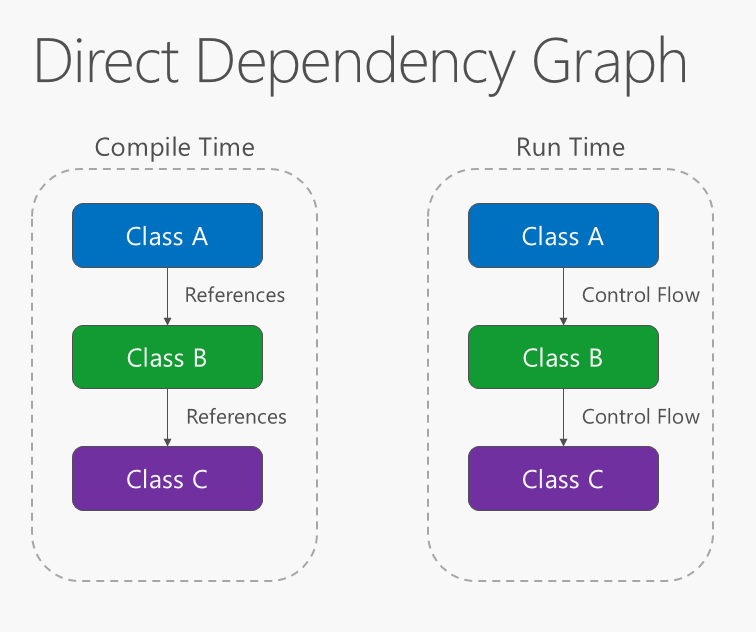
Abbildung 4-1. Diagramm der direkten Abhängigkeit
Durch die Anwendung des Prinzips der Abhängigkeitsumkehr kann A Methoden für eine Abstraktion abrufen, die von B implementiert wird. So kann B von A zur Laufzeit aufgerufen werden, jedoch kann B von einer Schnittstelle abhängig sein, die von A zur Kompilierzeit gesteuert wird (das bedeutet, dass die typische Kompilierzeitabhängigkeit umgekehrt wird). Der Ablauf der Programmausführung bleibt zur Laufzeit unverändert, jedoch bedeutet die Einführung von Schnittstellen, dass unterschiedliche Implementierungen dieser Schnittstellen einfach mit eingeschlossen werden können.
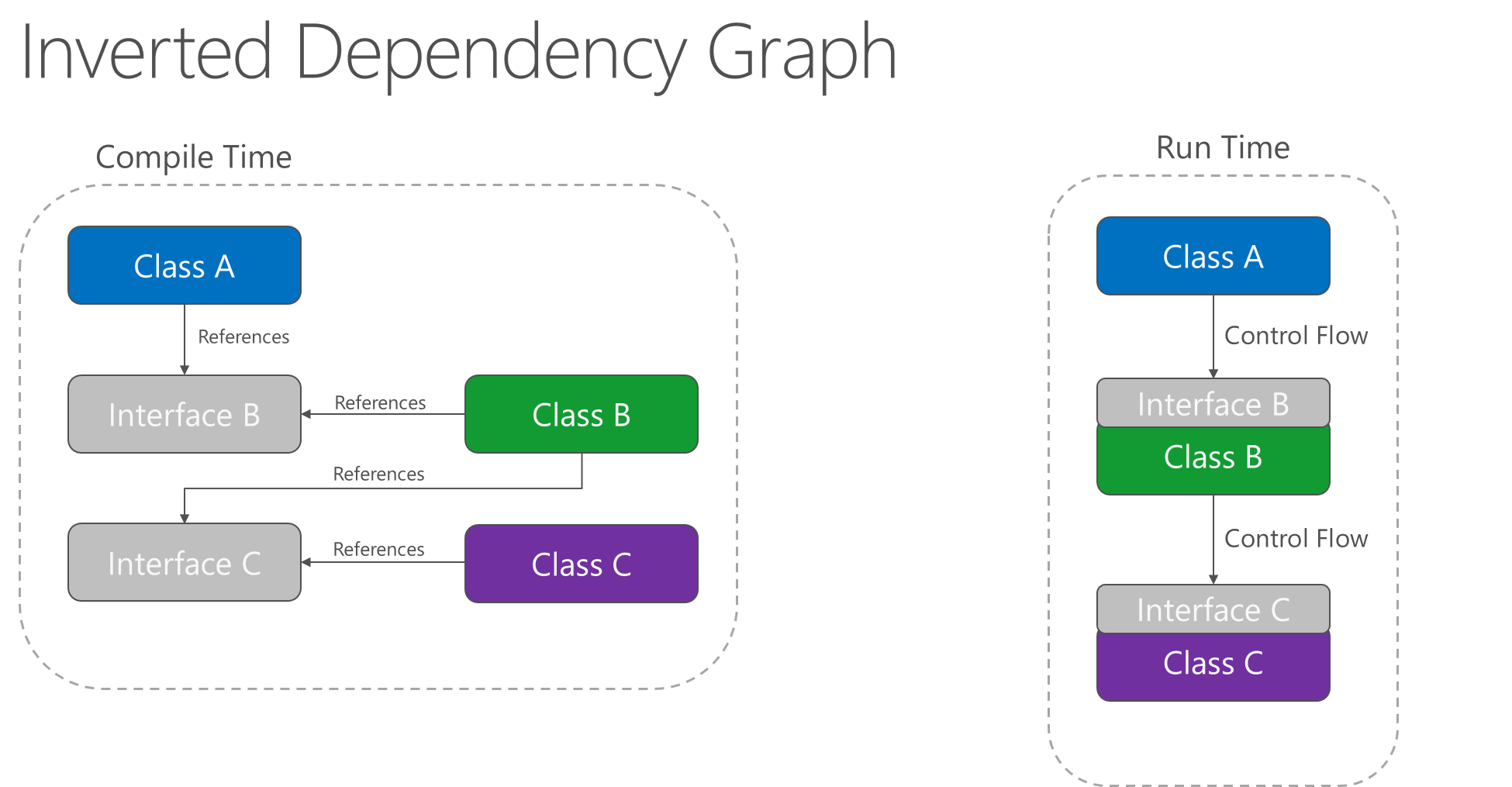
Abbildung 4-2. Diagramm der umgekehrten Abhängigkeit
Die Abhängigkeitsumkehrung ist ein wichtiger Bestandteil beim Erstellen von lose gekoppelten Anwendungen, da die Implementierungsdetails so geschrieben werden können, dass sie von übergeordneten Abstraktionen abhängig sind und diese implementieren, anstatt andersherum. Die sich daraus ergebenden Anwendungen können besser getestet werden, sind modular und deshalb auch besser verwaltbar. Die Methode der Abhängigkeitsinjektion wird durch das nachfolgende Prinzip der Abhängigkeitsumkehrung ermöglicht.
Explizite Abhängigkeiten
Methoden und Klassen sollten explizit alle benötigten zusammenarbeitenden Objekte erfordern, um ordnungsgemäß zu funktionieren. Es wird als Prinzip der expliziten Abhängigkeiten bezeichnet. Damit Klassen sich in einem gültigen Zustand befinden bzw. ordnungsgemäß funktionieren können, bieten Klassenkonstruktoren die Möglichkeit, dass Klassen die dafür benötigen Elemente identifizieren können. Wenn Sie Klassen identifizieren, die konstruiert und aufgerufen werden können, die jedoch nur ordnungsgemäß funktionieren, wenn bestimmte globale Komponenten bzw. Komponenten der Infrastruktur vorhanden sind, sind diese Klassen Ihren Kunden gegenüber unehrlich. Der Konstruktorvertrag sagt aus, dass der Kunde nur die angegebenen Elemente benötigt (wenn möglich auch nichts, wenn die Klasse nur einen parameterlosen Konstruktor verwendet), aber zur Laufzeit wird angegeben, dass das Objekt etwas anderes benötigt.
Durch Befolgen des expliziten Abhängigkeitsprinzips sind Ihre Klassen und Methoden gegenüber den Kunden ehrlich, wenn es um die Elemente geht, die sie benötigen, um ordnungsgemäß zu arbeiten. Bei Befolgen dieses Prinzips wird Ihr Code selbstdokumentierender und Ihr Codierungsvertrag benutzerfreundlicher, da Benutzer darauf vertrauen werden, dass die Objekte, mit denen sie arbeiten, sich zur Runtime ordnungsgemäß verhalten, solange sie die erforderlichen Methoden oder Konstruktorparameter bereitstellen.
Prinzip der einzigen Verantwortung (Single Responsibility)
Das Prinzip der einzigen Verantwortung gilt für ein objektorientiertes Design, kann aber auch als Architekturprinzip ähnlich der Separation of Concerns angesehen werden. Es besagt, dass Objekte nur eine Verantwortung haben dürfen und dass sie nur einen Grund für eine Änderung haben dürfen. Dies bedeutet, dass das Objekt nur dann geändert werden muss, wenn die Art und Weise, wie es seine einzige Aufgabe durchführt, aktualisiert werden muss. Wenn Sie dieses Prinzip befolgen, können Sie mehr lose gekoppelte und modulare Systeme erstellen, da viele Teile des neuen Verhalten als neue Klassen implementiert werden können, und so wird vorhandenen Klassen keine zusätzliche Verantwortung hinzugefügt. Das Hinzufügen neuer Klassen ist immer sicherer als das Ändern vorhandener Klassen, da noch kein Code von den neuen Klassen abhängig ist.
In einer monolithischen Anwendung können wir das Prinzip der einzigen Verantwortung allgemein auf die Schichten in der Anwendung anwenden. Die Präsentationsverantwortung muss im Benutzeroberflächenprojekt verbleiben, während die Datenzugriffsverantwortung innerhalb eine Infrastrukturprojekts beibehalten werden sollte. Geschäftslogik sollte im Anwendungskernprojekt verbleiben, wo sie einfach getestet werden kann und sich unabhängig von anderen Verantwortungen entwickeln kann.
Wenn dieses Prinzip auf die Anwendungsarchitektur angewendet wird und bis zu ihrem logischen Endpunkt reicht, erhalten Sie Microservices. Ein bestimmter Microservice muss über eine einzige Verantwortung verfügen. Wenn Sie das Verhalten eines Systems erweitern müssen, ist es in der Regel am besten, dies durch Hinzufügen von zusätzlichen Microservices zu tun, anstatt Verantwortung zu einem vorhandenen Verhalten hinzuzufügen.
Weitere Informationen zur Microservicearchitektur
Don't Repeat Yourself (DRY)
Die Anwendung sollte kein Verhalten angeben, das mit einem bestimmten Konzept in mehreren Bereichen im Zusammenhang steht, da diese Methode eine bekannte Fehlerquelle ist. Zu einem späteren Zeitpunkt können geänderte Anforderungen dazu führen, dass dieses Verhalten geändert werden muss. Es ist wahrscheinlich, dass mindestens eine Instanz des Verhaltens nicht aktualisiert werden kann, und das System wird sich inkonsistent verhalten.
Kapseln Sie die Logik in einem Programmierungskonstrukt anstatt sie zu duplizieren. Machen Sie dieses Konstrukt zur einzelnen Autorität über dieses Verhalten. Ein anderer Teil der Anwendung, die dieses Verhalten erfordert, verwendet dann dieses neue Konstrukt.
Hinweis
Verknüpfen Sie keine Verhaltensmuster, die sich nur durch Zufall wiederholen. Auch wenn zwei unterschiedliche Konstanten über den gleichen Wert verfügen, bedeutet das nicht, dass Sie nur eine Konstante besitzen dürfen, wenn diese sich konzeptuell gesehen auf unterschiedliche Dinge beziehen. Duplizierung ist immer einer Kopplung an die falsche Abstraktion vorzuziehen.
Ignorieren der Persistenz
Das Ignorieren der Persistenz (Persistence Ignorance, PI) bezieht sich auf Typen, die beibehalten werden müssen, deren Code jedoch von der Wahl der Persistenztechnologie nicht beeinflusst wird. Solche Typen werden in .NET häufig als „Plain Old CLR Objects“ (POCOs) bezeichnet, da sie nicht von einer bestimmten Basisklasse erben oder eine bestimmte Schnittstelle implementieren müssen. Das Ignorieren der Persistenz ist wertvoll, weil das Geschäftsmodell so auf unterschiedliche Weise beibehalten werden kann, wodurch zusätzliche Flexibilität für die Anwendung garantiert werden kann. Die Wahl der Persistenz kann sich mit der Zeit von einer Datenbanktechnologie zur anderen ändern, oder es sind möglicherweise zusätzliche Persistenzformen entsprechend der Komponente erforderlich, mit der die Anwendung gestartet wurde (z. B. mithilfe eines Redis-Caches oder mit Azure Cosmos DB zusätzlich zu einer relationalen Datenbank).
Einige Beispiele für Verstöße gegen dieses Prinzip:
Eine erforderliche Basisklasse
Eine erforderliche Schnittstellenimplementierung
Klassen, die für die Speicherung von sich selbst verantwortlich sind (z. B. das Muster „Aktiver Datensatz“)
Erforderlicher parameterloser Konstruktor
Eigenschaften, die ein virtuelles Schlüsselwort erfordern
Eigens für die Persistenz erforderliche Attribute
Die Anforderung, dass Klassen über eines der oben genannten Features oder Verhalten verfügen müssen hat zur Folge, dass die Kopplung zwischen Typen beibehalten werden muss, sowie die Wahl der Persistenztechnologie. So wird es schwieriger, zukünftig neue Strategien für den Datenzugriff zu realisieren.
Kontextgrenzen
Kontextgrenzen stellen ein zentrales Muster im domänengesteuerten Design dar. Sie bieten die Möglichkeit, mit der Komplexität in großen Anwendungen und Organisation umzugehen, indem eine Aufteilung in einzelne konzeptuelle Module erfolgt. Jedes konzeptuelle Modul stellt einen Kontext dar, der von anderen Kontexten getrennt (also gebunden) ist und sich unabhängig entwickeln kann. Jede Kontextgrenze sollte idealerweise ihre eigenen Namen für interne Konzepte auswählen und über exklusiven Zugriff auf den eigenen persistenten Speicher verfügen können.
Anstatt eine Datenbank mit anderen Anwendungen zu teilen, sollten einzelne Webanwendungen darin bestrebt sein, mindestens die eigene Kontextgrenze darzustellen, mit eigenem persistenten Speicher für ihr Geschäftsmodell. Die Kommunikation zwischen Kontextgrenzen erfolgt über Programmschnittstellen und nicht über eine freigegebene Datenbank. So können Geschäftslogik und Ereignisse als Reaktion auf auftretende Änderungen erfolgen. Kontextgrenzen sind Microservices eng zugeordnet. Diese sind ebenso ideal als ihre eigenen individuellen Kontextgrenzen implementiert.
Zusätzliche Ressourcen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für