Dokument Intelligenz-Visitenkartenmodell
Wichtig
Ab Dokument Intelligenz v4.0 (Vorschau) und zukünftig ist das Modell für Visitenkarten (prebuilt-businessCard) veraltet. Um Daten aus Visitenkartenformaten zu extrahieren, verwenden Sie Folgendes:
| Feature | version | Modell-ID |
|---|---|---|
| Modell für Visitenkarten | • v3.1:2023-07-31 (allgemein verfügbar) • v3.0:2022-08-31 (allgemein verfügbar) • v2.1 (allgemein verfügbar) |
prebuilt-businessCard |
Dieser Inhalt gilt für:![]() v3.0 (GA) | Aktuelle Versionen:
v3.0 (GA) | Aktuelle Versionen:![]() v4.0 (Vorschau)
v4.0 (Vorschau)![]() v3.1 | Vorherige Version:
v3.1 | Vorherige Version:![]() v2.1
v2.1
Dieser Inhalt gilt für:![]() v2.1 | Neueste Version:
v2.1 | Neueste Version:![]() v4.0 (Vorschau)
v4.0 (Vorschau)
Das Visitenkartenmodell von Dokument Intelligenz kombiniert leistungsstarke OCR (Optical Character Recognition)-Funktionen mit Deep Learning-Modellen, um Daten aus Visitenkartenbildern zu analysieren und zu extrahieren. Die API analysiert gedruckte Visitenkarten, extrahiert Schlüsselinformationen wie Vorname, Nachname, Firmenname, E-Mail-Adresse und Telefonnummer und gibt eine strukturierte JSON-Datendarstellung zurück.
Datenextraktion aus Visitenkarten
Visitenkarten stellen sowohl für ein Unternehmen als auch für seine Mitarbeiter eine hervorragende Präsentationsmöglichkeit dar. Das Firmenlogo, die Schriftarten und die Hintergrundbilder auf den Visitenkarten stärken das Branding des Unternehmens und heben es von anderen ab. Die Anwendung von OCR und auf maschinellem Lernen basierenden Techniken zur Automatisierung des Scannens von Visitenkarten ist ein gängiges Bildverarbeitungsszenario. Unternehmenssysteme, die von Vertriebs- und Marketingteams genutzt werden, verfügen in der Regel über eine integrierte Funktion zur Extraktion von Visitenkartendaten, die den Benutzern zugute kommt.
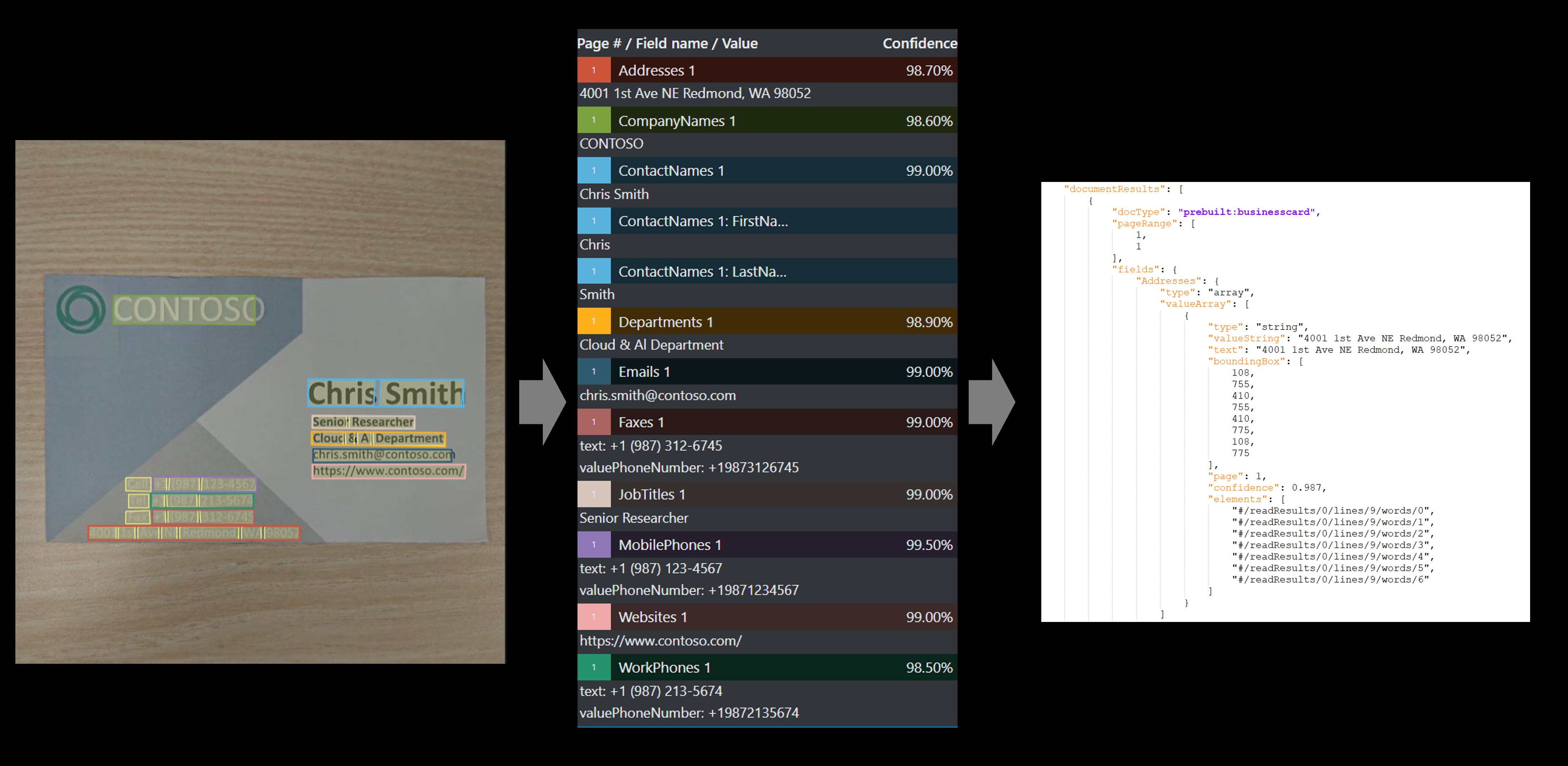
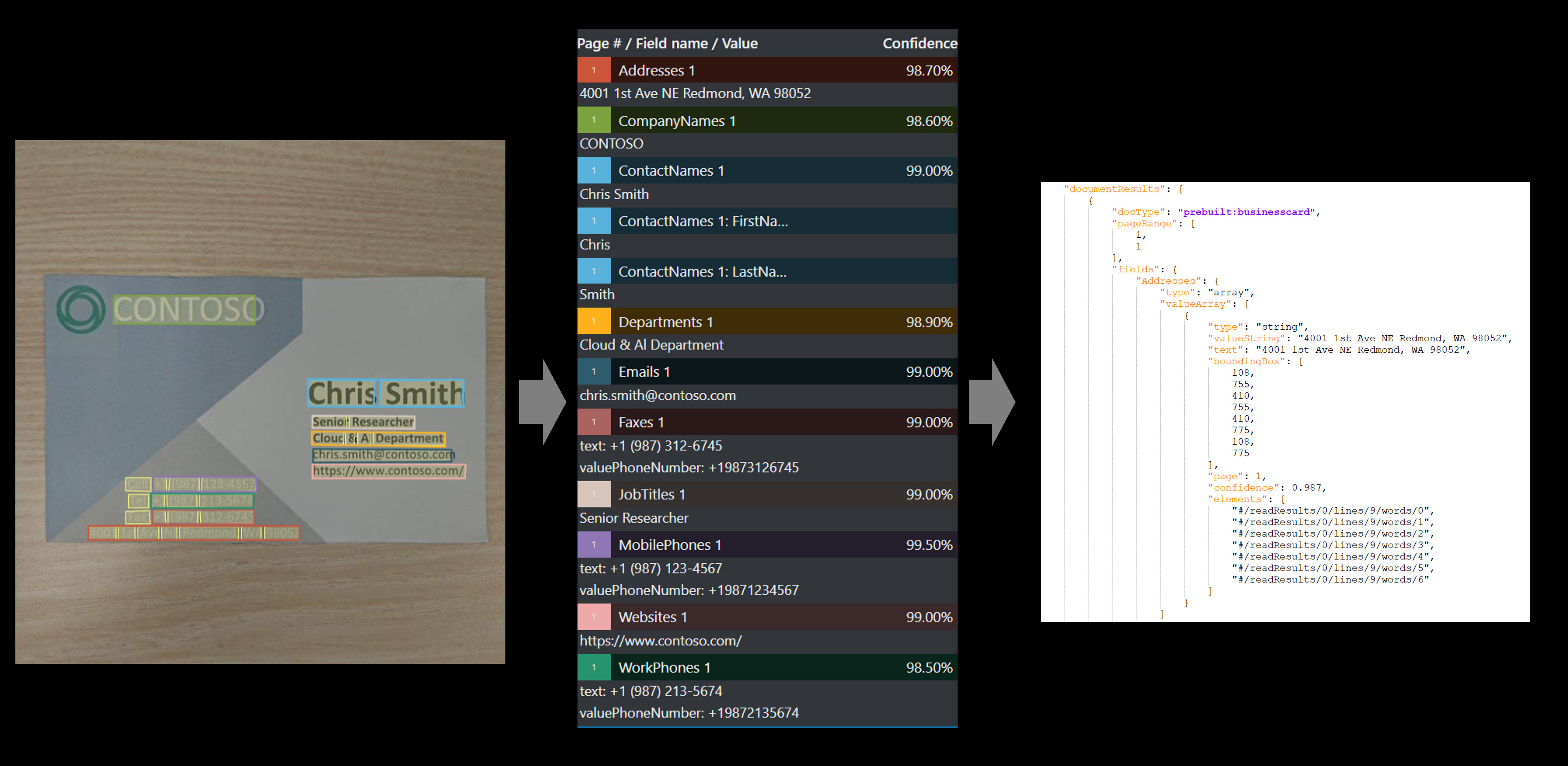
Beispielvisitenkarte verarbeitet mit Dokument Intelligenz Studio

Beispielvisitenkarte, die mit dem Tool zur Beschriftung von Beispielen in Dokument Intelligenz verarbeitet wurde
Entwicklungsoptionen
Dokument Intelligenz v3.1:2023-07-31 (allgemein verfügbar) unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen | Modell-ID |
|---|---|---|
| Modell für Visitenkarten | • Dokument Intelligenz Studio • REST-API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-businessCard |
Dokument Intelligenz v3.0:2022-08-31 (allgemein verfügbar) unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen | Modell-ID |
|---|---|---|
| Modell für Visitenkarten | • Dokument Intelligenz Studio • REST-API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-businessCard |
Dokument Intelligenz v2.1 (allgemein verfügbar) unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen |
|---|---|
| Modell für Visitenkarten | • Beschriftungstool von Dokument Intelligenz • REST-API • Clientbibliothek/SDK • Docker-Container für Dokument Intelligenz |
Testen der Datenextraktion aus Visitenkarten
Erfahren Sie, wie Daten, einschließlich Name, Position, Adresse, E-Mail und Firmenname, aus Visitenkarten extrahiert werden. Sie benötigen die folgenden Ressourcen:
Azure-Abonnement – Sie können ein kostenloses Abonnement erstellen
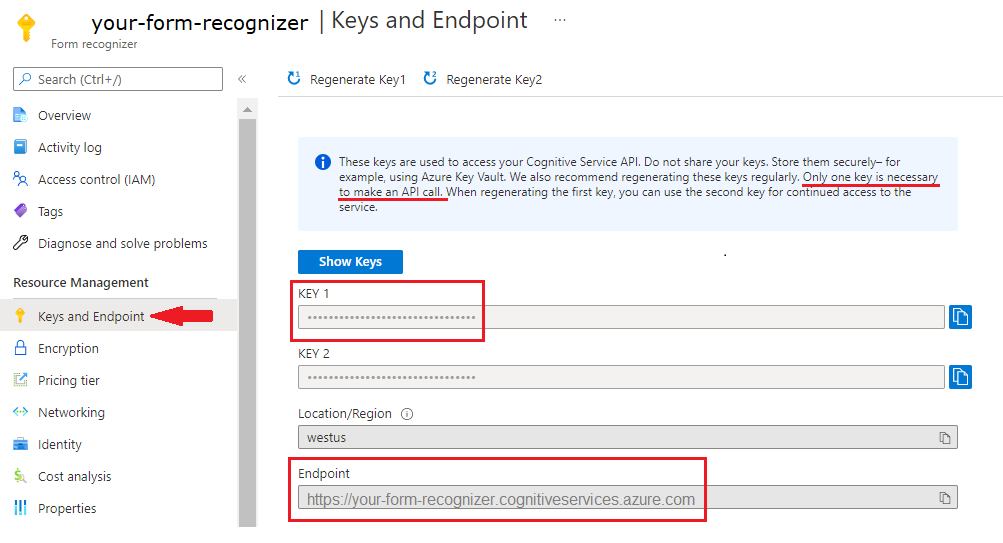
Eine Dokument Intelligenz-Instanz im Azure-Portal. Sie können den kostenlosen Tarif (
F0) verwenden, um den Dienst auszuprobieren. Wählen Sie nach der Bereitstellung Ihrer Ressource Zu Ressource wechseln aus, um Ihren Schlüssel und Endpunkt abzurufen.
Dokument Intelligenz Studio
Hinweis
Dokument Intelligenz Studio ist mit den APIs der Version 3.1 und 3.0 verfügbar.
Wählen Sie auf der Startseite von Dokument Intelligenz Studio die Option Visitenkarten aus.
Sie können die Mustervisitenkarte analysieren oder Ihre eigenen Dateien hochladen.
Wählen Sie die Schaltfläche Analyse ausführen aus, und konfigurieren Sie bei Bedarf die Analyseoptionen:

Beispielbeschriftungstool von Dokument Intelligenz
Navigieren Sie zum Dokument Intelligenz-Beispieltool.
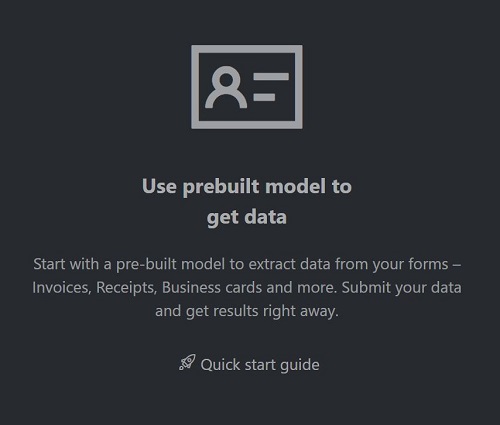
Wählen Sie auf der Startseite des Beispieltools die Kachel Use prebuilt model to get data (Vordefiniertes Modell zum Abrufen von Daten verwenden) aus.
Wählen Sie im Dropdownfenster den zu analysierenden Formulartyp aus.
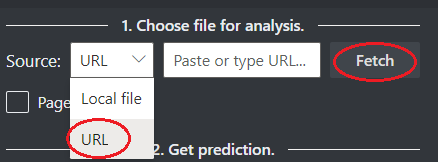
Wählen Sie aus den folgenden Optionen eine URL zu der Datei aus, die Sie analysieren möchten:
Wählen Sie im Feld Quelle die URL aus dem Dropdownmenü aus, fügen Sie die ausgewählte URL ein, und wählen Sie die Schaltfläche Abrufen aus.
Fügen Sie im Feld Dokument Intelligenz-Dienstendpunkt den Endpunkt ein, den Sie mit Ihrem Dokument Intelligenz-Abonnement erhalten haben.
Fügen Sie im Feld Schlüssel den Schlüssel ein, den Sie von Ihrer Dokument Intelligenz-Ressource erhalten haben.
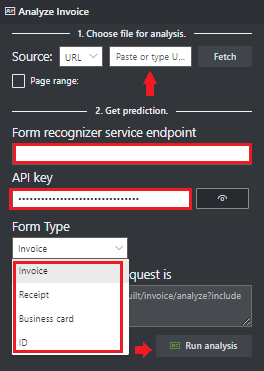
Wählen Sie Run Analysis (Analyse ausführen) aus. Das Dokument Intelligenz-Tool für die Beschriftung von Beispielen ruft die „Analyze Prebuilt“-API auf und analysiert das Dokument.
Zeigen Sie die Ergebnisse an. Sehen Sie sich die extrahierten Schlüssel-Wert-Paare, die Positionen, den extrahierten markierten Text und die erkannten Tabellen an.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hinweis
Das Tool für die Beschriftung von Beispielen unterstützt nicht das BMP-Dateiformat. Dies ist eine Einschränkung des Tools, nicht des Dokument Intelligenz-Diensts.
Eingabeanforderungen
Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
Unterstützte Dateiformate:
Modell PDF Bild:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) und HTMLLesen ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Allgemeines Dokument ✔ ✔ Vordefiniert ✔ ✔ Benutzerdefinierte Extraktion ✔ ✔ Benutzerdefinierte Klassifizierung ✔ ✔ ✔ (2024-02-29-preview) In den Formaten PDF und TIFF können bis zu 2.000 Seiten verarbeitet werden (bei einem kostenlosen Abonnement werden nur die ersten beiden Seiten verarbeitet).
Die Dateigröße für die Analyse von Dokumenten beträgt 500 MB für die kostenpflichtige (S0) und 4 MB für die kostenlose (F0) Stufe.
Die Bildgrößen müssen im Bereich zwischen 50 × 50 Pixel und 10.000 × 10.000 Pixel liegen.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Die Mindesthöhe des zu extrahierenden Texts beträgt 12 Pixel für ein Bild von 1024 × 768 Pixel. Diese Abmessung entspricht etwa einem
8-Punkt-Text bei 150 Punkten pro Zoll (Dots per Inch, DPI).Die maximale Anzahl Seiten für Trainingsdaten beträgt beim benutzerdefinierten Modelltraining 500 für das benutzerdefinierte Vorlagenmodell und 50.000 für das benutzerdefinierte neuronale Modell.
Für das Training des benutzerdefinierten Extraktionsmodells beträgt die Gesamtgröße der Trainingsdaten 50 MB für das Vorlagenmodell und 1G-MB für das neuronale Modell.
Für das Training des benutzerdefinierten Klassifizierungsmodells beträgt die Gesamtgröße der Trainingsdaten
1GBmit einem Maximum von 10 000 Seiten.
- Unterstützte Dateiformate: JPEG, PNG, PDF und TIFF
- In den Formaten PDF und TIFF werden bis zu 2.000 Seiten verarbeitet. Bei Abonnements im Free-Tarif werden nur die ersten beiden Seiten verarbeitet.
- Die Dateigröße muss weniger als 50 MB betragen, und die Abmessungen müssen mindestens 50 × 50 Pixel und höchstens 10.000 × 10.000 Pixel betragen.
Unterstützte Sprachen und Regionen
Eine vollständige Liste der unterstützten Sprachen finden Sie unter Sprachunterstützung – Benutzerdefinierte Modelle.
Feldextraktionen
| Name | Typ | BESCHREIBUNG | Standardisierte Ausgabe |
|---|---|---|---|
| ContactNames | Array von Objekten | Kontaktname | |
| FirstName | String | Vorname des Kontakts | |
| LastName | String | Nachname des Kontakts | |
| CompanyNames | Array von Zeichenfolgen | Name(n) des Unternehmens | |
| Departments | Array von Zeichenfolgen | Abteilung(en) oder Kontaktorganisation(en) | |
| JobTitles | Array von Zeichenfolgen | Aufgeführte Position(en) des Kontakts | |
| E-Mails | Array von Zeichenfolgen | E-Mail-Adresse(n) des Kontakts | |
| Websites | Array von Zeichenfolgen | Website(s) des Unternehmens | |
| Adressen | Array von Zeichenfolgen | Aus der Visitenkarte extrahierte Adresse(n) | |
| MobilePhones | Array aus Telefonnummern | Mobiltelefonnummer(n) von der Visitenkarte | +1 xxx xxx xxxx |
| Faxnummern | Array aus Telefonnummern | Faxnummer(n) von der Visitenkarte | +1 xxx xxx xxxx |
| WorkPhones | Array aus Telefonnummern | Telefonnummer(n) (geschäftlich) von der Visitenkarte | +1 xxx xxx xxxx |
| OtherPhones | Array aus Telefonnummern | Andere Telefonnummer(n) von der Visitenkarte | +1 xxx xxx xxxx |
Extrahierte Felder
| Name | Typ | BESCHREIBUNG | Text |
|---|---|---|---|
| ContactNames | Array von Objekten | Aus der Visitenkarte extrahierter Name des Kontakts | [{ "FirstName": "John", "LastName": "Doe" }] |
| FirstName | Zeichenfolge | Vorname des Kontakts | „John“ |
| LastName | Zeichenfolge | Nachname des Kontakts | „Doe“ |
| CompanyNames | array of strings | Aus der Visitenkarte extrahierter Unternehmensname | ["Contoso"] |
| Departments | array of strings | Abteilung oder Organisation des Kontakts | ["R&D"] |
| JobTitles | array of strings | Aufgeführte Position des Kontakts | ["Software Engineer"] |
| E-Mails | array of strings | Aus der Visitenkarte extrahierte E-Mail-Adresse des Kontakts | ["johndoe@contoso.com"] |
| Websites | array of strings | Aus der Visitenkarte extrahierte Website | ["https://www.contoso.com"] |
| Adressen | array of strings | Aus der Visitenkarte extrahierte Adresse | ["123 Main Street, Redmond, WA 98052"] |
| MobilePhones | Array aus Telefonnummern | Aus der Visitenkarte extrahierte Mobiltelefonnummer | ["+19876543210"] |
| Faxnummern | Array aus Telefonnummern | Aus der Visitenkarte extrahierte Faxnummer | ["+19876543211"] |
| WorkPhones | Array aus Telefonnummern | Aus der Visitenkarte extrahierte geschäftliche Telefonnummer | ["+19876543231"] |
| OtherPhones | Array aus Telefonnummern | Aus der Visitenkarte extrahierte weitere Telefonnummern | ["+19876543233"] |
Unterstützte Gebietsschemas
Vordefinierte Visitenkarten v2.1 unterstützt die folgenden Gebietsschemas:
- de-de
- en-au
- en-ca
- en-gb
- .en-in
Migrationsleitfaden und REST-API v3.1
- Folgen Sie unserem Migrationsleitfaden für Document Intelligence 3.1, um zu erfahren, wie Sie die Version 3.0 in Ihren Anwendungen und Workflows verwenden können.
Nächste Schritte
Versuchen Sie, Ihre eigenen Formulare und Dokumente mithilfe von Dokument Intelligenz Studio zu verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.
Versuchen Sie, Ihre eigenen Formulare und Dokumente mithilfe von Dokument Intelligenz-Beispielbezeichnungstool zu verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.