ID-Dokumentmodell von Dokument Intelligenz
Wichtig
- Public Preview-Releases von Dokument Intelligenz bieten frühzeitigen Zugriff auf Features, die sich in der aktiven Entwicklung befinden.
- Features, Ansätze und Prozesse können sich aufgrund von Benutzerfeedback vor der allgemeinen Verfügbarkeit (General Availability, GA) ändern.
- Die öffentliche Vorschauversion der Clientbibliotheken für Dokument-Intelligence ist standardmäßig die REST-API-Version 2024-02-29-preview.
- Öffentliche Vorschauversion 2024-02-29-preview ist derzeit nur in den folgenden Azure-Regionen verfügbar:
- USA, Osten
- USA, Westen 2
- Europa, Westen
Dieser Inhalt gilt für:![]() v4.0 (Vorschau) | Vorherige Versionen:
v4.0 (Vorschau) | Vorherige Versionen:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Dieser Inhalt gilt für:![]() v3.1 (GA) | Aktuelle Version:
v3.1 (GA) | Aktuelle Version:![]() v4.0 (Vorschau) | Vorherige Versionen:
v4.0 (Vorschau) | Vorherige Versionen:![]() v3.0
v3.0![]() v2.1
v2.1
Dieser Inhalt gilt für:![]() v3.0 (GA) | Aktuelle Versionen:
v3.0 (GA) | Aktuelle Versionen:![]() v4.0 (Vorschau)
v4.0 (Vorschau)![]() v3.1 | Vorherige Version:
v3.1 | Vorherige Version:![]() v2.1
v2.1
Dieser Inhalt gilt für:![]() v2.1 | Neueste Version:
v2.1 | Neueste Version:![]() v4.0 (Vorschau)
v4.0 (Vorschau)
Das Ausweisdokumentmodell von Dokument Intelligenz kombiniert optische Zeichenerkennung (Optical Character Recognition, OCR) mit Deep Learning-Modellen, um wichtige Informationen aus Ausweisdokumenten zu analysieren und zu extrahieren. Die API analysiert Ausweisdokumente (einschließlich folgende) und gibt eine strukturierte JSON-Datendarstellung zurück:
- Passbuch, Reisepass im Kartenformat (weltweit)
- Führerschein aus den USA, Europa, Indien, Kanada und Australien
- Ausweisdokumente der USA, Aufenthaltserlaubnis (Greencard), Sozialversicherungskarte, Militärausweis
- Europäische Personalausweise, Aufenthaltserlaubnisse
- Indische PAN-Karte, Aadhaar-Karte
- Kanadische Ausweisdokumente, Aufenthaltserlaubnis (Maple Card)
- Australische Fotokarte, Keypass-Ausweis (einschließlich digitaler Version)
Mit Dokument Intelligenz können Informationen aus amtlichen Ausweisen unter Verwendung des vordefinierten ID-Modells analysiert und extrahiert werden. Dabei werden unsere leistungsstarken Funktionen zur optischen Zeichenerkennung (Optical Character Recognition, OCR) mit ID-Erkennungsfunktionen kombiniert, um wesentliche Informationen aus internationalen Reisepässen und US-amerikanischen Führerscheinen (alle 50 Bundesstaaten). Mit der ID-API werden wesentliche Informationen aus diesen Ausweisdokumenten extrahiert, z. B. Vorname, Nachname, Geburtsdatum und Dokumentnummer. Diese API ist in Dokument Intelligenz 2.1 als Clouddienst verfügbar.
Verarbeitung von Ausweisdokumenten
Bei der Verarbeitung von Ausweisdokumenten werden die Daten aus Ausweisdokumenten entweder manuell oder mit OCR-basierten Technologien extrahiert. Die Verarbeitung von Ausweisdokumenten ist ein wichtiger Schritt in jedem Geschäftsvorgang, der einen Identitätsnachweis erfordert. Beispiele sind die Kundenüberprüfung in Banken und anderen Finanzinstituten, bei Hypothekenanträgen, Arztbesuchen, zur Verarbeitung von Anträgen, im Gastgewerbe usw. Einzelpersonen weisen ihre Identität mit ihrem Führerschein, Reisepass und ähnlichen Dokumenten nach, damit das Unternehmen sie effizient überprüfen kann, bevor es Dienstleistungen und Leistungen bereitstellt.
US-Beispielfahrerlaubnis, die mit Dokument Intelligenz Studio verarbeitet wurde:
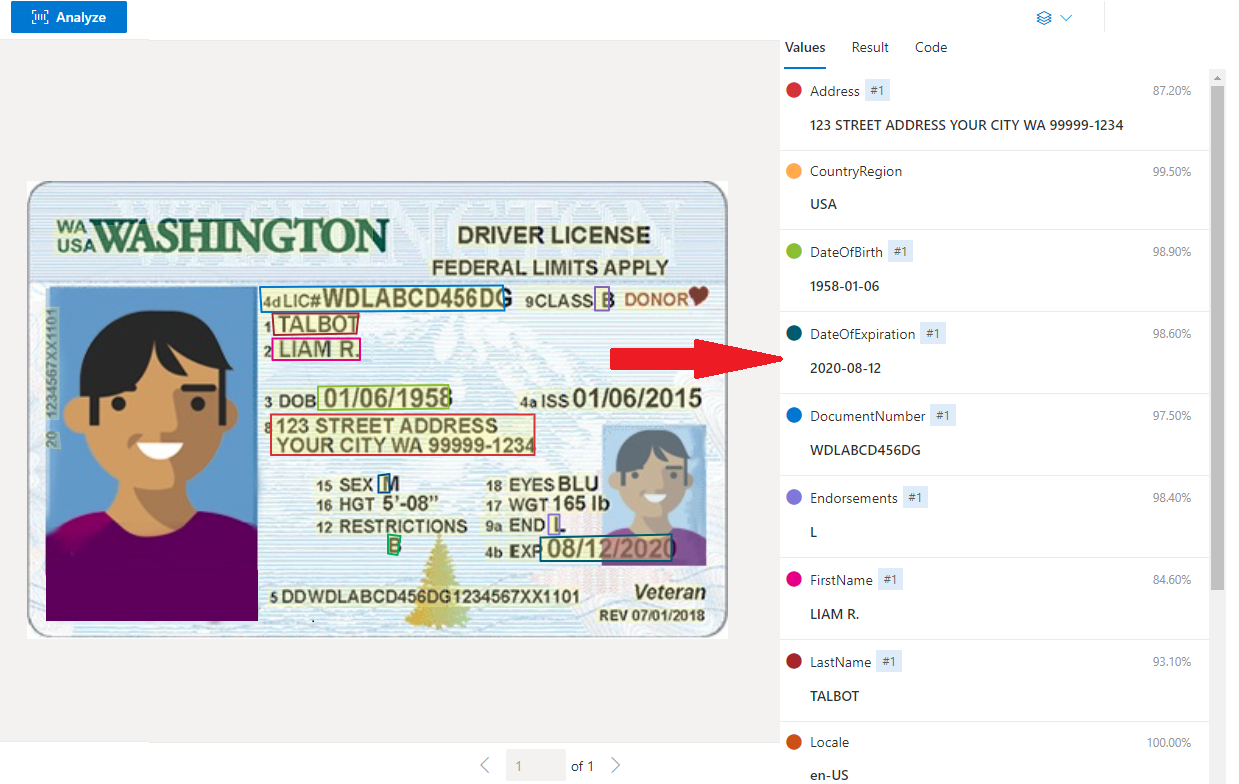
Extrahieren von Daten
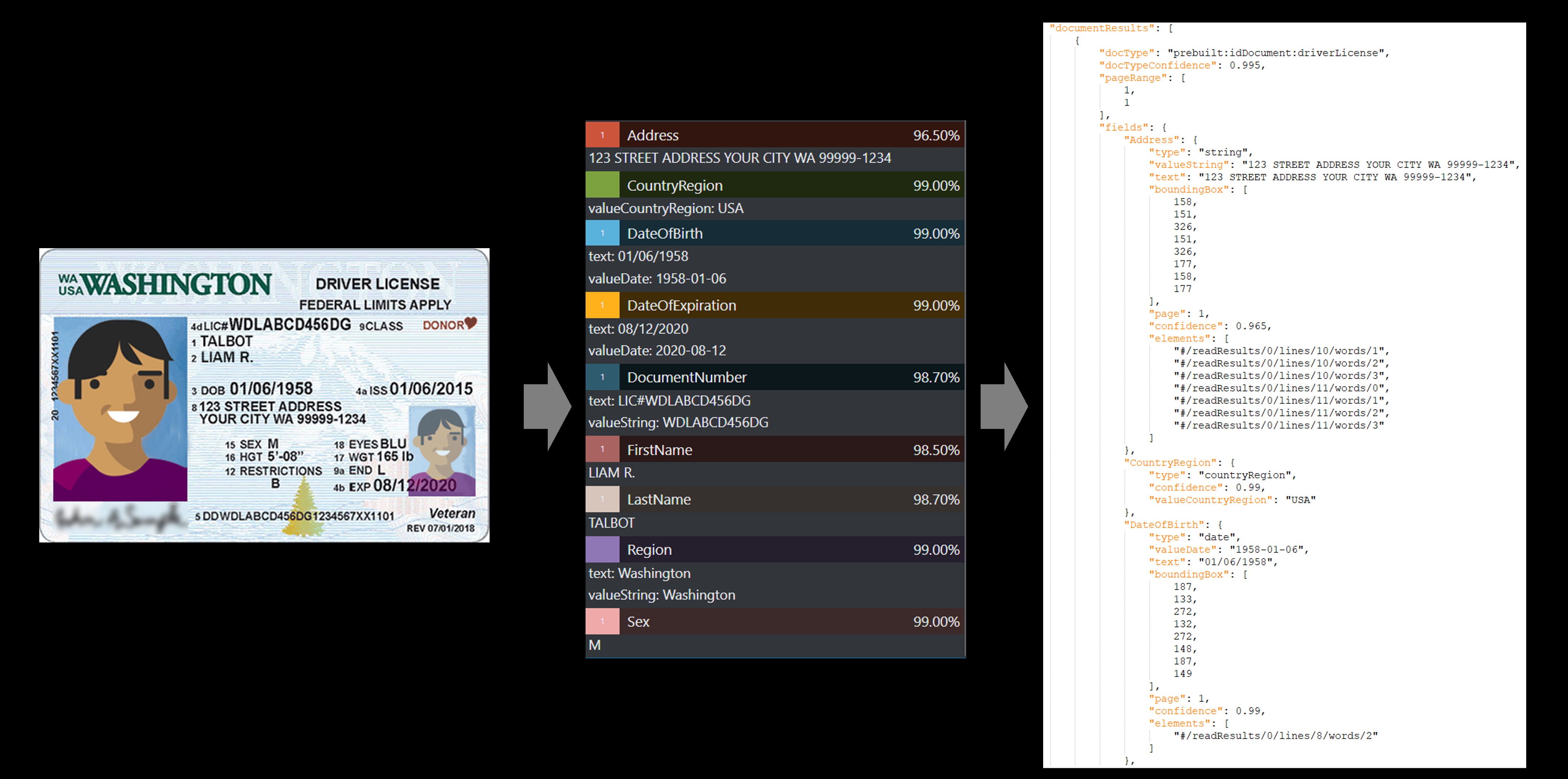
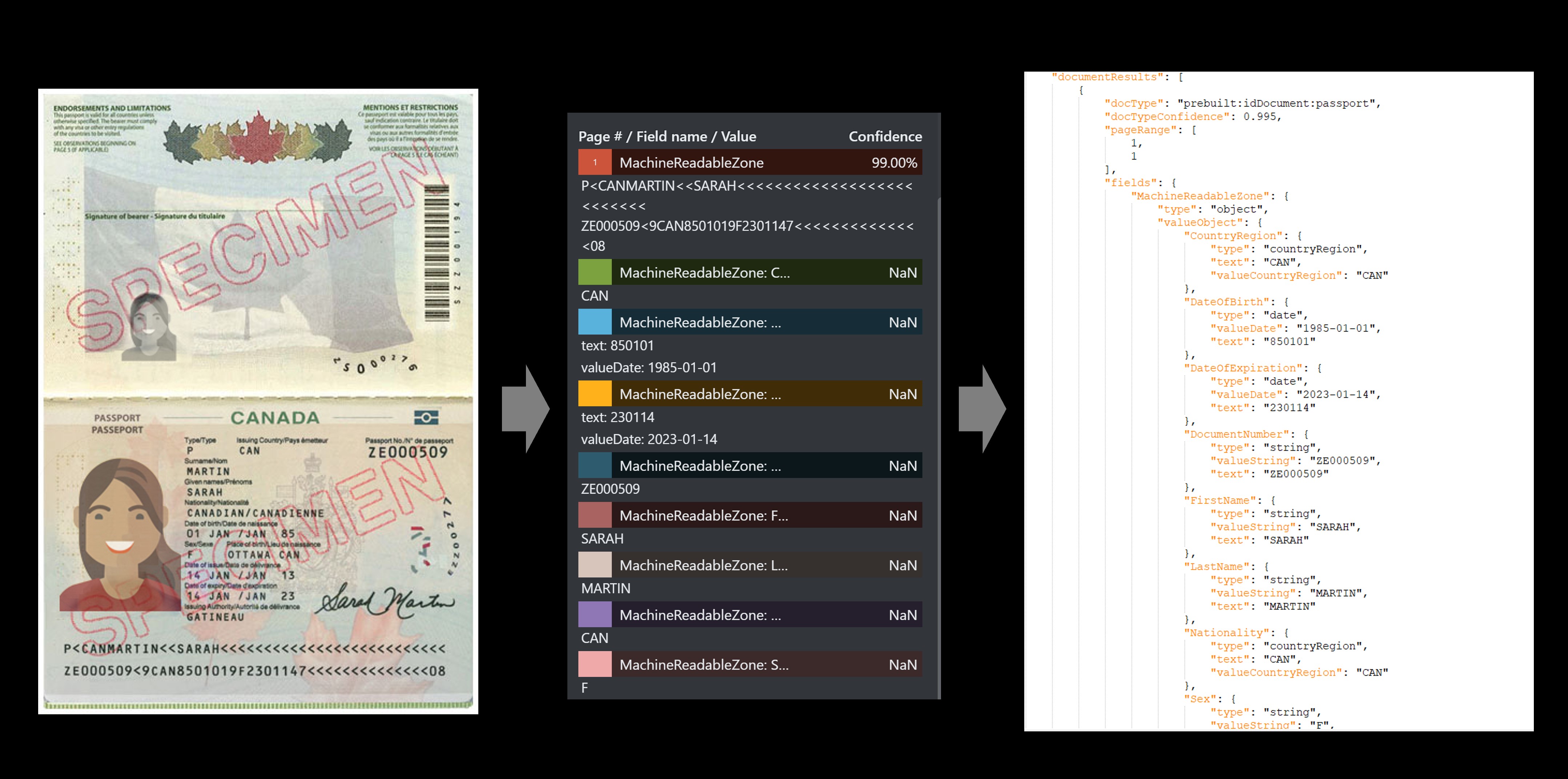
Der vorgefertigte ID-Dienst extrahiert die Schlüsselwerte aus den internationalen Reisepässen und den US-Führerscheinen und gibt Sie in einer organisierten strukturierten JSON-Antwort zurück.
Führerschein als Beispiel
Reisepass als Beispiel
Entwicklungsoptionen
Document Intelligence v4.0 (2024-02-29-preview, 2023-10-31-preview) unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Funktion | Ressourcen | Modell-ID |
|---|---|---|
| Ausweisdokumentmodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v3.1 unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen | Modell-ID |
|---|---|---|
| Ausweisdokumentmodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v3.0 unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen | Modell-ID |
|---|---|---|
| Ausweisdokumentmodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Dokument Intelligenz v2.1 unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen |
|---|---|
| Ausweisdokumentmodell | • Dokument Intelligenz-Bezeichnungstool • REST-API • Clientbibliothek SDK • Dokument Intelligenz-Docker-Container |
Eingabeanforderungen
Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
Unterstützte Dateiformate:
Modell PDF Bild:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) und HTMLLesen ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Allgemeines Dokument ✔ ✔ Vordefiniert ✔ ✔ Benutzerdefinierte Extraktion ✔ ✔ Benutzerdefinierte Klassifizierung ✔ ✔ ✔ (2024-02-29-preview) In den Formaten PDF und TIFF können bis zu 2.000 Seiten verarbeitet werden (bei einem kostenlosen Abonnement werden nur die ersten beiden Seiten verarbeitet).
Die Dateigröße für die Analyse von Dokumenten beträgt 500 MB für die kostenpflichtige (S0) und 4 MB für die kostenlose (F0) Stufe.
Die Bildgrößen müssen im Bereich zwischen 50 × 50 Pixel und 10.000 × 10.000 Pixel liegen.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Die Mindesthöhe des zu extrahierenden Texts beträgt 12 Pixel für ein Bild von 1024 × 768 Pixel. Diese Abmessung entspricht etwa einem
8-Punkt-Text bei 150 Punkten pro Zoll (Dots per Inch, DPI).Die maximale Anzahl Seiten für Trainingsdaten beträgt beim benutzerdefinierten Modelltraining 500 für das benutzerdefinierte Vorlagenmodell und 50.000 für das benutzerdefinierte neuronale Modell.
Für das Training des benutzerdefinierten Extraktionsmodells beträgt die Gesamtgröße der Trainingsdaten 50 MB für das Vorlagenmodell und 1G-MB für das neuronale Modell.
Für das Training des benutzerdefinierten Klassifizierungsmodells beträgt die Gesamtgröße der Trainingsdaten
1GBmit einem Maximum von 10 000 Seiten.
Unterstützte Dateiformate: JPEG, PNG, PDF und TIFF.
Unterstützte Seitenanzahl für PDF- und TIFF-Dateien: bis zu 2.000 Seiten oder nur die ersten beiden Seiten für Abonnenten der kostenlosen Version.
Unterstützte Dateigröße: weniger als 50 MB GESAMT; Mindestpixel: 50 x 50 px; Maximale Pixel 10.000 x 10.000 px.
Datenextraktion für das Ausweisdokumentmodell
Extrahieren Sie Daten aus Ausweisdokumenten, darunter den Namen, das Geburtsdatum und das Ablaufdatum. Sie benötigen die folgenden Ressourcen:
Ein Azure-Abonnement (Sie können ein kostenloses Abonnement erstellen).
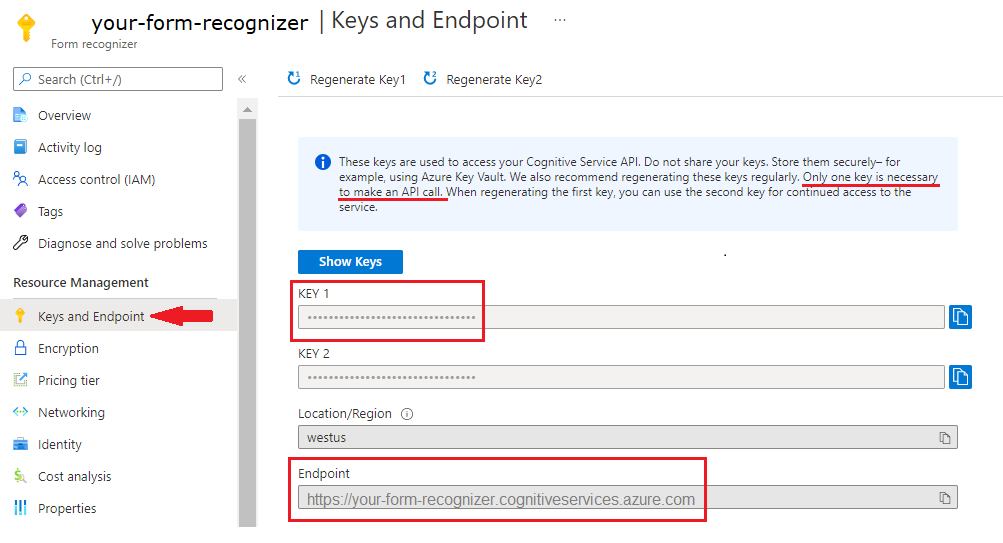
Eine Dokument Intelligenz-Instanz im Azure-Portal. Sie können den kostenlosen Tarif (
F0) verwenden, um den Dienst auszuprobieren. Wählen Sie nach der Bereitstellung Ihrer Ressource Zu Ressource wechseln aus, um Ihren Schlüssel und Endpunkt abzurufen.
Hinweis
Dokument Intelligenz Studio ist mit den APIs der Versionen 3.1 und 3.0 und höheren Versionen verfügbar.
Wählen Sie auf der Startseite von Dokument Intelligenz Studio die Option Ausweisdokumente aus.
Sie können die Musterrechnung analysieren oder Ihre eigenen Dateien hochladen.
Wählen Sie die Schaltfläche Analyse ausführen aus, und konfigurieren Sie bei Bedarf die Analyseoptionen:

Beispielbeschriftungstool von Dokument Intelligenz
Navigieren Sie zum Dokument Intelligenz-Beispieltool.
Wählen Sie auf der Startseite des Beispieltools die Kachel Use prebuilt model to get data (Vordefiniertes Modell zum Abrufen von Daten verwenden) aus.
Wählen Sie im Dropdownfenster den zu analysierenden Formulartyp aus.
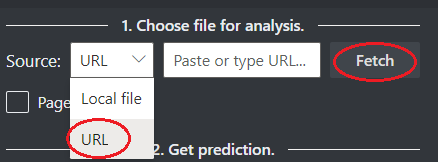
Wählen Sie aus den folgenden Optionen eine URL zu der Datei aus, die Sie analysieren möchten:
Wählen Sie im Feld Quelle die URL aus dem Dropdownmenü aus, fügen Sie die ausgewählte URL ein, und wählen Sie die Schaltfläche Abrufen aus.
Fügen Sie im Feld Dokument Intelligenz-Dienstendpunkt den Endpunkt ein, den Sie mit Ihrem Dokument Intelligenz-Abonnement erhalten haben.
Fügen Sie im Feld Schlüssel den Schlüssel ein, den Sie von Ihrer Dokument Intelligenz-Ressource erhalten haben.
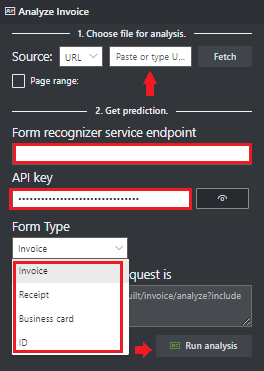
Wählen Sie Run Analysis (Analyse ausführen) aus. Das Dokument Intelligenz-Tool für die Beschriftung von Beispielen ruft die „Analyze Prebuilt“-API auf und analysiert das Dokument.
Zeigen Sie die Ergebnisse an. Sehen Sie sich die extrahierten Schlüssel-Wert-Paare, die Positionen, den extrahierten markierten Text und die erkannten Tabellen an.
Laden Sie die JSON-Ausgabedatei herunter, um die ausführlichen Ergebnisse anzuzeigen.
- Der Knoten „readResults“ enthält jede Textzeile mit der Platzierung des zugehörigen Begrenzungsrahmens auf der Seite.
- Der Knoten „selectionMarks“ zeigt jede Auswahlmarkierung (Kontrollkästchen, Optionsfeld) und ihren Status (ausgewählt oder nicht ausgewählt).
- Der Abschnitt „pageResults“ enthält die extrahierten Tabellen. Für jede Tabelle extrahiert Dokument Intelligenz den Text-, Zeilen- und Spaltenindex, die Zeilen- und Spaltenaufteilung, den Begrenzungsrahmen und Ähnliches.
- Das Feld „documentResults“ enthält Informationen zu Schlüssel-Wert-Paaren und Positionen für die relevantesten Teile des Dokuments.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hinweis
Das Tool für die Beschriftung von Beispielen unterstützt nicht das BMP-Dateiformat. Dies ist eine Einschränkung des Tools, nicht des Dokument Intelligenz-Diensts.
Unterstützte Dokumenttypen
| Region | Dokumenttypen |
|---|---|
| Weltweit | Passbuch, Reisepass im Kartenformat |
| USA | Führerschein, Personalausweis, Aufenthaltserlaubnis (Greencard), Sozialversicherungskarte, Wehrpass |
| Europa | Führerschein, Personalausweis, Aufenthaltserlaubnis |
| Indien | Führerschein, PAN Card, Aadhaar Card |
| Kanada | Führerschein, Personalausweis, Aufenthaltserlaubnis (Maple Card) |
| Australien | Führerschein, Fotokarte, Keypass-Ausweis (einschließlich digitaler Version) |
Feldextraktionen
Im Anschluss finden Sie die extrahierten Felder pro Dokumenttyp. Das Ausweismodell von Dokument Intelligenz (prebuilt-idDocument) extrahiert die folgenden Felder in documents.*.fields. Die JSON-Ausgabe enthält den gesamten extrahierten Text in den Dokumenten, Wörtern, Zeilen und Stilen.
idDocument.driverLicense
| Feld | Typ | Beschreibung des Dataflows | Beispiel |
|---|---|---|---|
CountryRegion |
countryRegion |
Code des Lands oder der Region | USA |
Region |
string |
Bundesland oder Kanton | Washington |
DocumentNumber |
string |
Führerscheinnummer | WDLABCD456DG |
DocumentDiscriminator |
string |
Diskriminator des Führerscheindokuments | 12645646464554646456464544 |
FirstName |
string |
Vorname und ggf. Anfangsbuchstabe des zweiten Vornamen | LIAM R. |
LastName |
string |
Surname | TALBOT |
Address |
address |
Adresse | 123 STREET ADDRESS YOUR CITY WA 99999-1234 |
DateOfBirth |
date |
Geburtsdatum | 01/06/1958 |
DateOfExpiration |
date |
Ablaufdatum | 08/12/2020 |
DateOfIssue |
date |
Ausstellungsdatum | 08/12/2012 |
EyeColor |
string |
Augenfarbe | Blau |
HairColor |
string |
Haarfarbe | Braun |
Height |
string |
Höhe | 5'11" |
Weight |
string |
Weight | 185LB |
Sex |
string |
Geschlecht | M |
Endorsements |
string |
Empfehlungen | L |
Restrictions |
string |
Beschränkungen | B |
VehicleClassifications |
string |
Fahrzeugklassifizierung | D |
idDocument.passport
| Feld | Typ | Beschreibung des Dataflows | Beispiel |
|---|---|---|---|
DocumentNumber |
string |
Passport number | 340020013 |
FirstName |
string |
Vorname und ggf. Anfangsbuchstabe des zweiten Vornamen | JENNIFER |
MiddleName |
string |
Name zwischen Vorname und Nachname | REYES |
LastName |
string |
Surname | BROOKS |
Aliases |
array |
||
Aliases.* |
string |
Andere Bezeichnung | MAT LIN |
DateOfBirth |
date |
Geburtsdatum | 1980-01-01 |
DateOfExpiration |
date |
Ablaufdatum | 2019-05-05 |
DateOfIssue |
date |
Ausstellungsdatum | 2014-05-06 |
Sex |
string |
Geschlecht | F |
CountryRegion |
countryRegion |
Ausstellende(s) Land oder Organisation | USA |
DocumentType |
string |
Dokumenttyp | P |
Nationality |
countryRegion |
Nationality | USA |
PlaceOfBirth |
string |
Geburtsort | MASSACHUSETTS, U.S.A. |
PlaceOfIssue |
string |
Ausstellungsort | LISSABON |
IssuingAuthority |
string |
Ausstellende Behörde | US-Außenministerium |
PersonalNumber |
string |
Persönliche ID. Nein. | A234567893 |
MachineReadableZone |
object |
Maschinenlesbarer Bereich | P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F1905054710000307<715816 |
MachineReadableZone.FirstName |
string |
Vorname und ggf. Anfangsbuchstabe des zweiten Vornamen | JENNIFER |
MachineReadableZone.LastName |
string |
Surname | BROOKS |
MachineReadableZone.DocumentNumber |
string |
Passport number | 340020013 |
MachineReadableZone.CountryRegion |
countryRegion |
Ausstellende(s) Land oder Organisation | USA |
MachineReadableZone.Nationality |
countryRegion |
Nationality | USA |
MachineReadableZone.DateOfBirth |
date |
Geburtsdatum | 1980-01-01 |
MachineReadableZone.DateOfExpiration |
date |
Ablaufdatum | 2019-05-05 |
MachineReadableZone.Sex |
string |
Geschlecht | F |
idDocument.nationalIdentityCard
| Feld | Typ | Beschreibung des Dataflows | Beispiel |
|---|---|---|---|
CountryRegion |
countryRegion |
Code des Lands oder der Region | USA |
Region |
string |
Bundesland oder Kanton | Washington |
DocumentNumber |
string |
Nationale Ausweisnummer | WDLABCD456DG |
DocumentDiscriminator |
string |
Diskriminator des nationalen Ausweisdokuments | 12645646464554646456464544 |
FirstName |
string |
Vorname und ggf. Anfangsbuchstabe des zweiten Vornamen | LIAM R. |
LastName |
string |
Surname | TALBOT |
Address |
address |
Adresse | 123 STREET ADDRESS YOUR CITY WA 99999-1234 |
DateOfBirth |
date |
Geburtsdatum | 01/06/1958 |
DateOfExpiration |
date |
Ablaufdatum | 08/12/2020 |
DateOfIssue |
date |
Ausstellungsdatum | 08/12/2012 |
EyeColor |
string |
Augenfarbe | BLAU |
HairColor |
string |
Haarfarbe | BRAUN |
Height |
string |
Höhe | 5'11" |
Weight |
string |
Weight | 185LB |
Sex |
string |
Geschlecht | M |
idDocument.residencePermit
| Feld | Typ | Beschreibung des Dataflows | Beispiel |
|---|---|---|---|
CountryRegion |
countryRegion |
Code des Lands oder der Region | USA |
DocumentNumber |
string |
Nummer der Aufenthaltsgenehmigung | WDLABCD456DG |
FirstName |
string |
Vorname und ggf. Anfangsbuchstabe des zweiten Vornamen | LIAM R. |
LastName |
string |
Surname | TALBOT |
DateOfBirth |
date |
Geburtsdatum | 01/06/1958 |
DateOfExpiration |
date |
Ablaufdatum | 08/12/2020 |
DateOfIssue |
date |
Ausstellungsdatum | 08/12/2012 |
Sex |
string |
Geschlecht | M |
PlaceOfBirth |
string |
Geburtsort | Deutschland |
Category |
string |
Genehmigungskategorie | DV2 |
Address |
string |
Anschrift | 123 STREET ADDRESS YOUR CITY WA 99999-1234 |
idDocument.usSocialSecurityCard
| Feld | Typ | Beschreibung des Dataflows | Beispiel |
|---|---|---|---|
DocumentNumber |
string |
Nummer der Sozialversicherungskarte | WDLABCD456DG |
FirstName |
string |
Vorname und ggf. Anfangsbuchstabe des zweiten Vornamen | LIAM R. |
LastName |
string |
Surname | TALBOT |
DateOfIssue |
date |
Ausstellungsdatum | 08/12/2012 |
idDocument
| Feld | Typ | Beschreibung des Dataflows | Beispiel |
|---|---|---|---|
Address |
address |
Adresse | 123 STREET ADDRESS YOUR CITY WA 99999-1234 |
DocumentNumber |
string |
Führerscheinnummer | WDLABCD456DG |
FirstName |
string |
Vorname und ggf. Anfangsbuchstabe des zweiten Vornamen | LIAM R. |
LastName |
string |
Surname | TALBOT |
DateOfBirth |
date |
Geburtsdatum | 01/06/1958 |
DateOfExpiration |
date |
Ablaufdatum | 08/12/2020 |
Unterstützte Dokumenttypen
Dieses Ausweismodell ist derzeit für US-Führerscheine und die biografische Seite internationaler Reisepässe (ausgenommen Visa und andere Reisedokumente) verfügbar.
Extrahierte Felder
| Name | Typ | BESCHREIBUNG | Wert |
|---|---|---|---|
| Land | country | Ländercode, konform zu ISO 3166-Standard | „USA“ |
| DateOfBirth | date | Geburtsdatum im Format JJJJ-MM-TT | „1980-01-01“ |
| DateOfExpiration | date | Ablaufdatum im Format JJJJ-MM-TT | „2019-05-05“ |
| DocumentNumber | Zeichenfolge | Relevante Passnummer, Führerscheinnummer usw. | „340020013“ |
| FirstName | Zeichenfolge | Extrahierter Vorname und ggf. Mittelinitial | „JENNIFER“ |
| LastName | Zeichenfolge | Extrahierter Nachname | „BROOKS“ |
| Nationality | country | Ländercode, konform zu ISO 3166-Standard | „USA“ |
| Geschlecht | gender | Mögliche extrahierte Werte: „M“, „F“, „X“ | "F" |
| MachineReadableZone | Objekt | Maschinenlesbarer zweizeiliger Bereich (Machine Readable Zone, MRZ) mit jeweils 44 Zeichen | "P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F1905054710000307<715816" |
| DocumentType | Zeichenfolge | Dokumenttyp, z. B. Pass oder Führerschein | „passport“ |
| Adresse | Zeichenfolge | Extrahierte Adresse (nur beim Führerschein) | „123 STREET ADDRESS YOUR CITY WA 99999-1234“ |
| Region | Zeichenfolge | Extrahierte Region, Bundesstaat, Provinz usw. (nur Führerschein) | „Washington“ |
Migrationsleitfaden
- Folgen Sie unserem Migrationsleitfaden für Document Intelligence 3.1, um zu erfahren, wie Sie die Version 3.0 in Ihren Anwendungen und Workflows verwenden können.
Nächste Schritte
Versuchen Sie, Ihre eigenen Formulare und Dokumente mithilfe von Dokument Intelligenz Studio zu verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.
Versuchen Sie, Ihre eigenen Formulare und Dokumente mithilfe des Dokument Intelligenz-Stichproben-Bezeichnungstools zu verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.