Dokument Intelligenz-Layoutmodell
Wichtig
- Public Preview-Releases von Dokument Intelligenz bieten frühzeitigen Zugriff auf Features, die sich in der aktiven Entwicklung befinden.
- Features, Ansätze und Prozesse können sich aufgrund von Benutzerfeedback vor der allgemeinen Verfügbarkeit (General Availability, GA) ändern.
- Die öffentliche Vorschauversion der Clientbibliotheken für Dokument-Intelligence ist standardmäßig die REST-API-Version 2024-02-29-preview.
- Öffentliche Vorschauversion 2024-02-29-preview ist derzeit nur in den folgenden Azure-Regionen verfügbar:
- USA, Osten
- USA, Westen 2
- Europa, Westen
Dieser Inhalt gilt für:![]() v4.0 (Vorschau) | Vorherige Versionen:
v4.0 (Vorschau) | Vorherige Versionen:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Dieser Inhalt gilt für:![]() v3.1 (GA) | Aktuelle Version:
v3.1 (GA) | Aktuelle Version:![]() v4.0 (Vorschau) | Vorherige Versionen:
v4.0 (Vorschau) | Vorherige Versionen:![]() v3.0
v3.0![]() v2.1
v2.1
Dieser Inhalt gilt für:![]() v3.0 (GA) | Aktuelle Versionen:
v3.0 (GA) | Aktuelle Versionen:![]() v4.0 (Vorschau)
v4.0 (Vorschau)![]() v3.1 | Vorherige Version:
v3.1 | Vorherige Version:![]() v2.1
v2.1
Dieser Inhalt gilt für:![]() v2.1 | Neueste Version:
v2.1 | Neueste Version:![]() v4.0 (Vorschau)
v4.0 (Vorschau)
Das Layoutmodell von Dokument Intelligenz ist eine auf erweitertem maschinellem Lernen basierende Dokumentlayoutanalyse-API, die in der Dokument Intelligenz-Cloud verfügbar ist. Sie ermöglicht Ihnen, Dokumente in verschiedenen Formaten zu nehmen und strukturierte Datendarstellungen der Dokumente zurückzugeben. Die API kombiniert eine verbesserte Version der leistungsstarken Funktionen zur optischen Zeichenerkennung (Optical Character Recognition, OCR) mit Deep Learning-Modellen zum Extrahieren von Text, Tabellen, Auswahlmarkierungen und der Dokumentstruktur.
Dokumentlayoutanalyse
Bei der Dokumentstruktur-Layoutanalyse handelt es sich um den Vorgang der Analyse eines Dokuments zu dem Zweck, relevante Bereiche und ihre Beziehungen untereinander zu extrahieren. Ziel ist es, Text- und Strukturelemente aus der Seite zu extrahieren, um Modelle mit besserem Semantikverständnis zu erstellen. Es gibt zwei Arten von Rollen in einem Dokumentlayout:
- Geometrische Rollen: Text, Tabellen, Abbildungen und Auswahlmarkierungen sind Beispiele für geometrische Rollen.
- Logische Rollen: Titel, Kopfzeilen und Fußzeilen sind Beispiele für logische Rollen von Texten.
Die folgende Abbildung zeigt die typischen Komponenten eines Bildes auf einer Beispielseite.

Entwicklungsoptionen
Document Intelligence v4.0 (2024-02-29-preview, 2023-10-31-preview) unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Funktion | Ressourcen | Modell-ID |
|---|---|---|
| Layoutmodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-layout |
Document Intelligence v3.1 unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen | Modell-ID |
|---|---|---|
| Layoutmodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-layout |
Document Intelligence v3.0 unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen | Modell-ID |
|---|---|---|
| Layoutmodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-layout |
Dokument Intelligenz v2.1 unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen |
|---|---|
| Layoutmodell | • Dokument Intelligenz-Bezeichnungstool • REST-API • Clientbibliothek SDK • Dokument Intelligenz-Docker-Container |
Eingabeanforderungen
Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
Unterstützte Dateiformate:
Modell PDF Bild:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) und HTMLLesen ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Allgemeines Dokument ✔ ✔ Vordefiniert ✔ ✔ Benutzerdefinierte Extraktion ✔ ✔ Benutzerdefinierte Klassifizierung ✔ ✔ ✔ (2024-02-29-preview) In den Formaten PDF und TIFF können bis zu 2.000 Seiten verarbeitet werden (bei einem kostenlosen Abonnement werden nur die ersten beiden Seiten verarbeitet).
Die Dateigröße für die Analyse von Dokumenten beträgt 500 MB für die kostenpflichtige (S0) und 4 MB für die kostenlose (F0) Stufe.
Die Bildgrößen müssen im Bereich zwischen 50 × 50 Pixel und 10.000 × 10.000 Pixel liegen.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Die Mindesthöhe des zu extrahierenden Texts beträgt 12 Pixel für ein Bild von 1024 × 768 Pixel. Diese Abmessung entspricht etwa einem
8-Punkt-Text bei 150 Punkten pro Zoll (Dots per Inch, DPI).Die maximale Anzahl Seiten für Trainingsdaten beträgt beim benutzerdefinierten Modelltraining 500 für das benutzerdefinierte Vorlagenmodell und 50.000 für das benutzerdefinierte neuronale Modell.
Für das Training des benutzerdefinierten Extraktionsmodells beträgt die Gesamtgröße der Trainingsdaten 50 MB für das Vorlagenmodell und 1G-MB für das neuronale Modell.
Für das Training des benutzerdefinierten Klassifizierungsmodells beträgt die Gesamtgröße der Trainingsdaten
1GBmit einem Maximum von 10 000 Seiten.
- Unterstützte Dateiformate: JPEG, PNG, PDF und TIFF.
- Unterstützte Seitenanzahl: Für die Formate PDF und TIFF werden bis zu 2.000 Seiten verarbeitet. Bei Abonnements im Free-Tarif werden nur die ersten beiden Seiten verarbeitet.
- Unterstützte Dateigröße: Die Datei muss kleiner als 50 MB sein und eine Größe von mindestens 50 × 50 Pixel und höchstens 10.000 × 10.000 Pixel aufweisen.
Erste Schritte mit dem Layoutmodell
Erfahren Sie, wie Daten, einschließlich Text, Tabellen, Tabellenkopfzeilen, Auswahlmarkierungen und Strukturinformationen, mithilfe von Dokument Intelligenz aus Dokumenten extrahiert werden. Sie benötigen die folgenden Ressourcen:
Ein Azure-Abonnement (Sie können ein kostenloses Abonnement erstellen).
Eine Dokument Intelligenz-Instanz im Azure-Portal. Sie können den kostenlosen Tarif (
F0) verwenden, um den Dienst auszuprobieren. Wählen Sie nach der Bereitstellung Ihrer Ressource Zu Ressource wechseln aus, um Ihren Schlüssel und Endpunkt abzurufen.
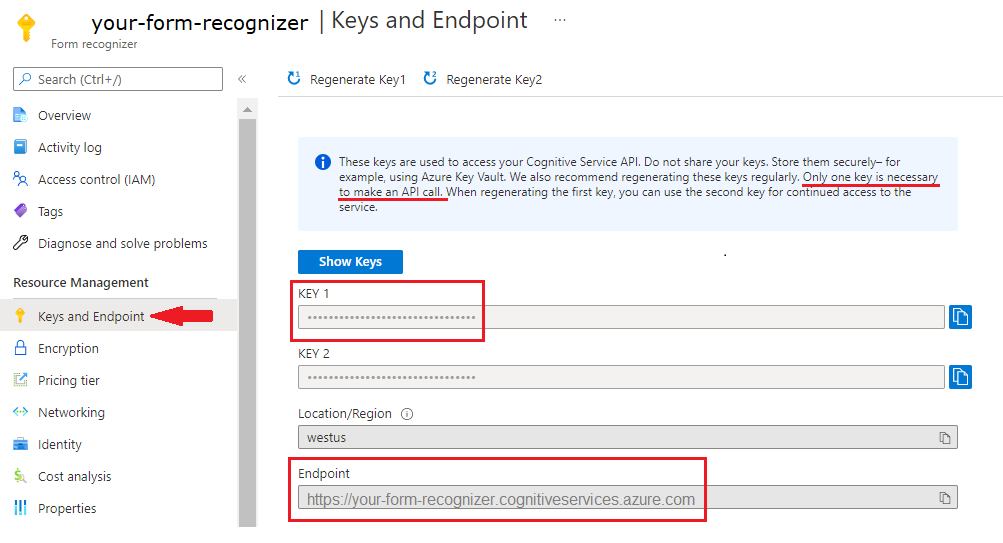
Hinweis
Dokument Intelligenz Studio ist mit den APIs der Version 3.0 und höheren Versionen verfügbar.
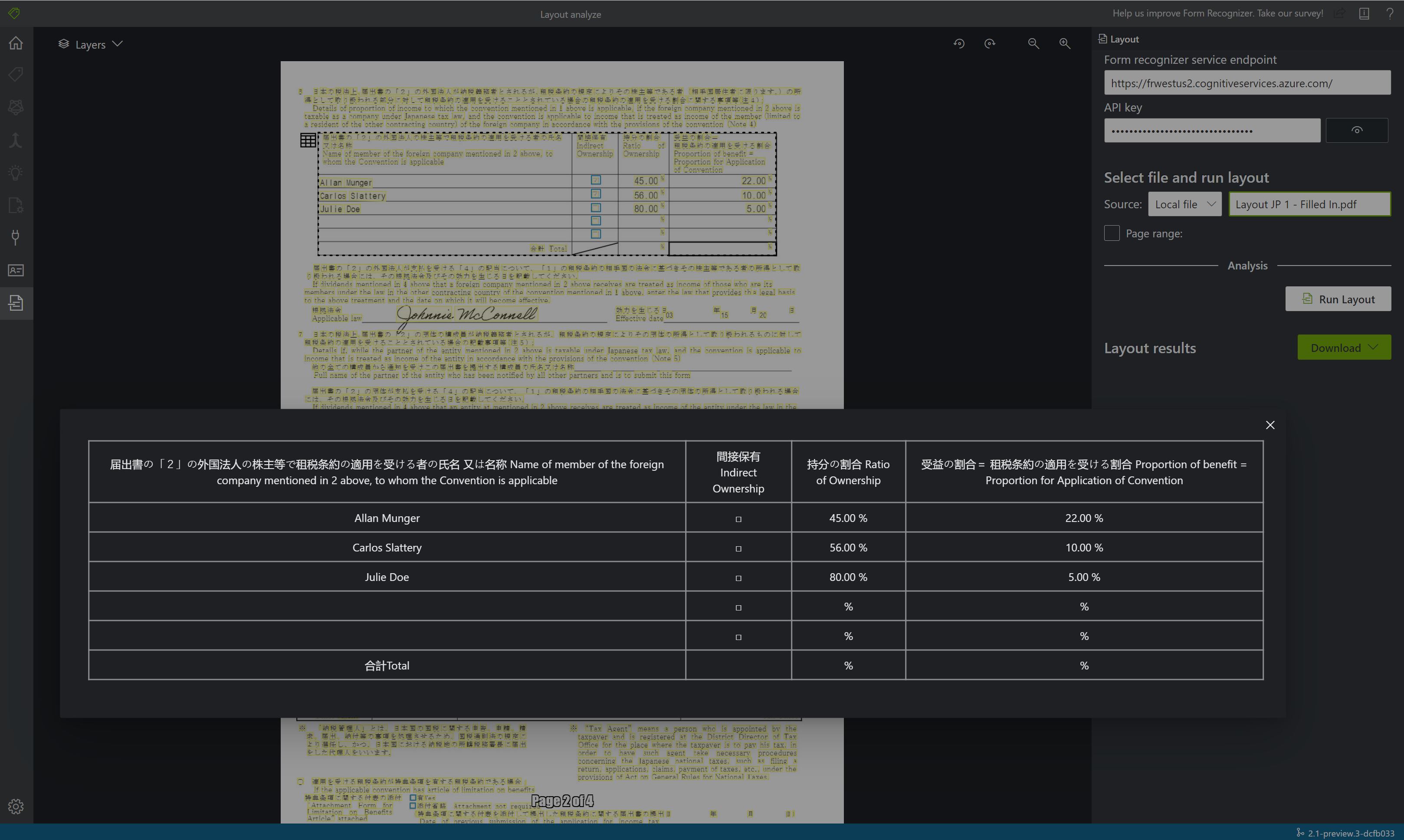
Beispieldokument, das mit Dokument Intelligenz Studio verarbeitet wurde
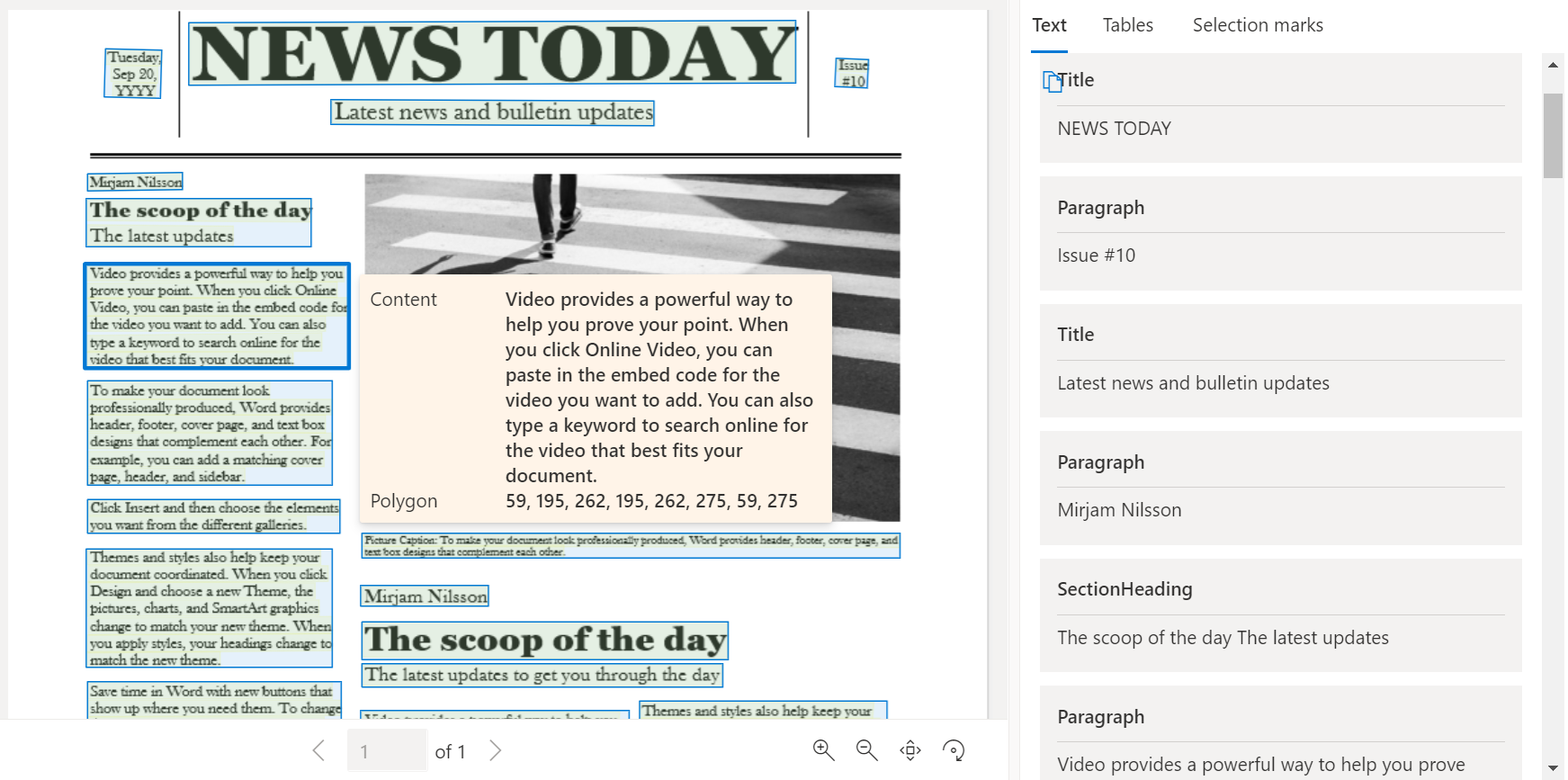
Wählen Sie auf der Startseite von Document Intelligence Studio die Option Layout aus.
Sie können das Musterdokument analysieren oder Ihre eigenen Dateien hochladen.
Wählen Sie die Schaltfläche Analyse ausführen aus, und konfigurieren Sie bei Bedarf die Analyseoptionen:

Beispielbeschriftungstool von Dokument Intelligenz
Navigieren Sie zum Dokument Intelligenz-Beispieltool.
Wählen Sie auf der Startseite des Beispieltools die Option Use Layout to get text, tables and selection marks (Layout zum Abrufen von Text, Tabellen und Auswahlmarkierungen verwenden) aus.
Fügen Sie im Feld Dokument Intelligenz-Dienstendpunkt den Endpunkt ein, den Sie mit Ihrem Dokument Intelligenz-Abonnement erhalten haben.
Fügen Sie im Feld Schlüssel den Schlüssel ein, den Sie von Ihrer Dokument Intelligenz-Ressource erhalten haben.
Wählen Sie im Feld Quelle die URL aus dem Dropdownmenü aus. Sie können unser Beispieldokument verwenden:
Wählen Sie die Schaltfläche Fetch (Fetchen) aus.
Wählen Sie Run Layout (Layout ausführen) aus. Das Tool für die Beschriftung von Beispielen von Document Intelligence ruft die
Analyze Layout-API auf und analysiert das Dokument.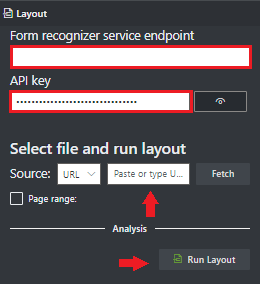
Anzeigen der Ergebnisse: Sehen Sie sich den hervorgehobenen extrahierten Text, die erkannten Auswahlmarkierungen und die erkannten Tabellen an.
{kind=link}
Unterstützte Sprachen und Gebietsschemas
Eine vollständige Liste der unterstützten Sprachen finden Sie unter Sprachunterstützung – Dokumentanalysemodelle.
Dokument Intelligenz v2.1 unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen |
|---|---|
| Layout-API |
Extrahieren von Daten
Das Layoutmodell extrahiert Text, Auswahlmarken, Tabellen, Absätze und Absatztypen (roles) aus Ihren Dokumenten.
Hinweis
Versionen 2024-02-29-preview, 2023-10-31-previewund höher unterstützen Microsoft Office (DOCX, XLSX, PPTX) und HTML-Dateien. Folgende Funktionen werden nicht unterstützt:
- Für die einzelnen Seitenobjekte gibt es keine Angaben für Winkel, Breite/Höhe und Einheit.
- Für die einzelnen erkannten Objekte gibt es weder ein Begrenzungspolygon noch einen Begrenzungsbereich.
- Der Seitenbereich (
pages) wird nicht als Parameter unterstützt. - Es gibt kein
lines-Objekt.
Seiten
Die Seitensammlung ist eine Liste von Seiten innerhalb des Dokuments. Jede Seite wird innerhalb des Dokuments sequenziell dargestellt und enthält den Ausrichtungswinkel, der angibt, ob die Seite gedreht wurde, sowie die Breite und Höhe (Abmessungen in Pixel). Die Seiteneinheiten in der Modellausgabe werden wie gezeigt berechnet:
| Dateiformat | Berechnete Seiteneinheit | Seiten gesamt |
|---|---|---|
| Bilder (JPEG/JPG, PNG, BMP, HEIF) | Jedes Bild = 1 Seiteneinheit | Gesamtzahl der Bilder |
| Jede Seite in der PDF = 1 Seiteneinheit | Gesamtseitenzahl in der PDF | |
| TIFF | Jedes TIFF-Bild = 1 Seiteneinheit | Gesamtanzahl der Bilder im TIFF-Dokument |
| Word (DOCX) | Bis zu 3.000 Zeichen = 1 Seiteneinheit, eingebettete oder verknüpfte Bilder werden nicht unterstützt | Gesamtzahl der Seiten von bis zu 3.000 Zeichen jeweils |
| Excel (XLSX) | Jedes Arbeitsblatt = 1 Seiteneinheit, eingebettete oder verknüpfte Bilder nicht unterstützt | Arbeitsblätter insgesamt |
| PowerPoint (PPTX) | Jede Folie = 1 Seiteneinheit, eingebettete oder verknüpfte Bilder nicht unterstützt | Folien insgesamt |
| HTML | Bis zu 3.000 Zeichen = 1 Seiteneinheit, eingebettete oder verknüpfte Bilder werden nicht unterstützt | Gesamtzahl der Seiten von bis zu 3.000 Zeichen jeweils |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
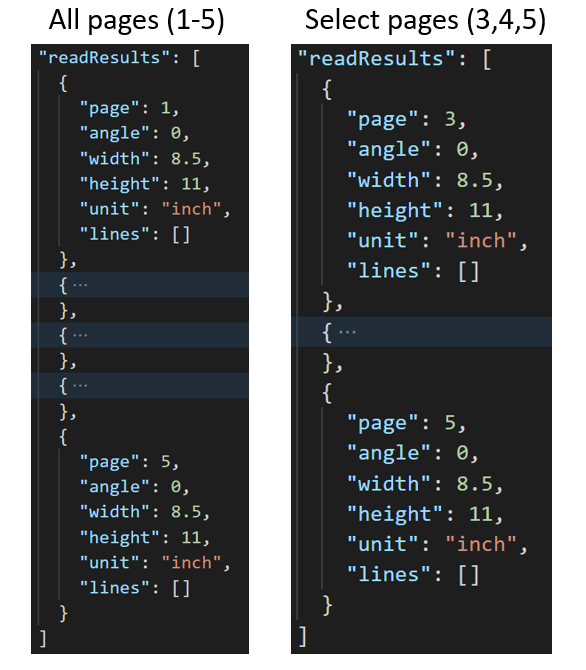
Extrahiert ausgewählte Seiten aus Dokumenten
Verwenden Sie für umfangreiche Dokumente mit mehreren Seiten den Abfrageparameter pages, um bestimmte Seitenzahlen oder Seitenbereiche für die Textextraktion anzugeben.
Absätze
Das Layoutmodell extrahiert alle identifizierten Textblöcke in der paragraphs-Auflistung als Objekt der obersten Ebene unter analyzeResults. Jeder Eintrag in dieser Auflistung stellt einen Textblock dar und enthält den extrahierten Text als content sowie die Koordinaten des Begrenzungs-polygon. Die span-Informationen zeigen auf das Textfragment innerhalb der content-Eigenschaft der obersten Ebene, die den vollständigen Text aus dem Dokument enthält.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Absatzrollen
Die neue auf maschinellem Lernen basierende Seitenobjekterkennung extrahiert logische Rollen wie Titel, Abschnittsüberschriften, Kopfzeilen, Fußzeilen und vieles mehr. Das Layoutmodell von Dokument Intelligenz weist bestimmte Textblöcke in der paragraphs-Sammlung mit ihrer speziellen, vom Modell vorhergesagten Rolle oder ihrem speziellen Typ zu. Sie werden am besten mit unstrukturierten Dokumenten verwendet, um das Layout des extrahierten Inhalts zu verstehen und so eine umfassendere semantische Analyse zu ermöglichen. Die folgenden Absatzrollen werden unterstützt:
| Vorhergesagte Rolle | Beschreibung | Unterstützte Dateitypen |
|---|---|---|
title |
Hauptüberschriften auf der Seite | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
Eine oder mehrere Unterüberschriften auf der Seite | pdf, image, docx, xlsx, html |
footnote |
Text im unteren Bereich der Seite | pdf, image |
pageHeader |
Text am oberen Rand der Seite | pdf, image, docx |
pageFooter |
Text am unteren Rand der Seite | pdf, image, docx, pptx, html |
pageNumber |
Seitenzahl | pdf, image |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Text, Zeilen und Wörter
Das Dokumentlayoutmodell in Dokument Intelligenz extrahiert gedruckten und handschriftlichen Text als lines und words. Die styles-Auflistung enthält alle handschriftlichen Formatvorlagen für Zeilen (sofern erkannt) sowie die Spannen, die auf den zugeordneten Text zeigen. Dieses Feature gilt für unterstützte handschriftliche Sprachen.
Für Microsoft Word, Excel, PowerPoint und HTML extrahieren die Document Intelligence-Versionen 2024-02-29-preview und 2023-10-31-preview Layout-Modell den gesamten eingebetteten Text wie er ist. Texte werden als Wörter und Absätze extrahiert. Eingebettete Bilder werden nicht unterstützt.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
Handschriftlicher Text für Textzeilen
Die Antwort umfasst die Klassifizierung, ob es sich bei den einzelnen Textzeilen um einen handschriftlichen Stil handelt, sowie eine Konfidenzbewertung. Weitere Informationen Weitere Informationen finden Sie im Artikel zur Unterstützung für handschriftlichen Text. Das folgende Beispiel zeigt einen beispielhaften JSON-Ausschnitt.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Wenn Sie die Add-On-Funktion für Schriftart/Schriftschnitt aktivieren, erhalten Sie als Teil des styles-Objekts auch das Ergebnis für die Schriftart und den Schriftschnitt.
Auswahlmarkierungen
Das Layoutmodell extrahiert darüber hinaus Auswahlmarkierungen aus Dokumenten. Extrahierte Auswahlmarken werden in der pages-Auflistung für jede Seite angezeigt. Sie enthalten das Begrenzungs-polygon, confidence und den Auswahl-state (selected/unselected). Die Textdarstellung (d. h. :selected: und :unselected) wird auch als Startindex (offset) und length hinzugefügt, die auf die content-Eigenschaft der obersten Ebene mit dem vollständigen Text des Dokuments verweist.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
Tabellen
Das Extrahieren von Tabellen ist eine wichtige Anforderung für die Verarbeitung von Dokumenten mit großen Datenmengen, die in der Regel als Tabellen formatiert sind. Das Layoutmodell extrahiert Tabellen in den pageResults-Abschnitt der JSON-Ausgabe. Die extrahierten Tabelleninformationen umfassen die Anzahl von Spalten und Zeilen sowie den Zeilen- und Spaltenabstand. Jede Zelle mit ihrem Begrenzungspolygon wird zusammen mit Informationen ausgegeben, unabhängig davon, ob der Bereich als columnHeader erkannt wird oder nicht. Das Modell unterstützt das Extrahieren von Tabellen, die gedreht wurden. Jede Tabellenzelle enthält den Zeilen- und Spaltenindex sowie die Koordinaten des Begrenzungspolygons. Für den Zellentext gibt das Modell die span-Informationen aus, die den Startindex (offset) enthalten. Das Modell gibt auch die length innerhalb des Inhalts der obersten Ebene aus, der den vollständigen Text aus dem Dokument enthält.
Hinweis
Tabellen werden nicht unterstützt, wenn die Eingabedatei eine XLSX-Datei ist.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
Anmerkungen (nur in 2023-02-28-preview API verfügbar.)
Das Layoutmodell extrahiert Anmerkungen in Dokumenten, z. B. Häkchen und Kreuze. Die Antwort enthält die Art der Anmerkung, zusammen mit einer Konfidenzbewertung und einem Begrenzungspolygon.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
Ausgabe im Markdownformat
Die Layout-API kann den extrahierten Text im Markdownformat ausgeben. outputContentFormat=markdown Geben Sie das Ausgabeformat in Markdown an. Der Markdowninhalt wird als Teil des content Abschnitts ausgegeben.
"analyzeResult": {
"apiVersion": "2024-02-29-preview",
"modelId": "prebuilt-layout",
"contentFormat": "markdown",
"content": "# CONTOSO LTD...",
}
Zahlen
Abbildungen (Diagramme, Bilder) in Dokumenten spielen eine entscheidende Rolle bei der Ergänzung und Verbesserung des Textinhalts, wobei visuelle Darstellungen bereitgestellt werden, die das Verständnis komplexer Informationen unterstützen. Das vom Layoutmodell erkannte Abbildungsobjekt weist wichtige Eigenschaften auf boundingRegions (die räumlichen Positionen der Abbildung auf den Dokumentseiten, einschließlich der Seitenzahl und der Polygonkoordinaten, die die Begrenzung der Abbildung umrissen), spans (detailiert den Text, der sich auf die Abbildung bezieht, und gibt ihre Offsets und Längen im Text des Dokuments an. Diese Verbindung hilft beim Zuordnen der Abbildung zu ihrem relevanten Textkontext, elements (den Bezeichnern für Textelemente oder Absätze im Dokument, die sich auf die Abbildung beziehen oder beschreiben) und caption falls vorhanden.
{
"figures": [
{
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
Abschnitte
Die hierarchische Dokumentstrukturanalyse ist entscheidend bei der Organisation, Verständnis und Verarbeitung umfangreicher Dokumente. Dieser Ansatz ist entscheidend für die semantische Segmentierung langer Dokumente, um das Verständnis zu steigern, die Navigation zu erleichtern und den Abruf von Informationen zu verbessern. Die Einführung von Retrieval Augmented Generation (RAG) in dokumentgeneriver KI unterstreicht die Bedeutung der hierarchischen Dokumentstrukturanalyse. Das Layoutmodell unterstützt Abschnitte und Unterabschnitte in der Ausgabe, die die Beziehung von Abschnitten und Objekten innerhalb der einzelnen Abschnitte identifiziert. Die hierarchische Struktur wird in elements den einzelnen Abschnitten beibehalten. Mit der Ausgabe können Sie das Markdownformat verwenden, um die Abschnitte und Unterabschnitte einfach in Markdown abzurufen.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
Ausgabe der natürlichen Leserichtung (nur lateinische Sprachen)
Mit dem Abfrageparameter readingOrder können Sie die Leserichtung angeben, in der die Textzeilen ausgegeben werden. Verwenden Sie natural für eine benutzerfreundlichere Ausgabe der Lesereihenfolge, wie im folgenden Beispiel gezeigt. Dieses Feature wird nur für lateinische Sprachen unterstützt.

Auswählen von Seitenzahlen oder Seitenbereichen für die Textextraktion
Verwenden Sie für umfangreiche Dokumente mit mehreren Seiten den Abfrageparameter pages, um bestimmte Seitenzahlen oder Seitenbereiche für die Textextraktion anzugeben. Das folgende Beispiel zeigt ein Dokument mit 10 Seiten, wobei für beide Fälle – alle Seiten (1-10) und ausgewählte Seiten (3-6) – Text extrahiert wurde.
Der Vorgang „Abrufen des Ergebnisses der Layoutanalyse“
Im zweiten Schritt wird der Vorgang Abrufen des Ergebnisses der Layoutanalyse aufgerufen. Bei diesem Vorgang wird die Ergebnis-ID als Eingabe verwendet, die der Vorgang „Analyze Layout“ erstellt hat. Er gibt eine JSON-Antwort zurück, die ein Status-Feld mit den folgenden möglichen Werten enthält.
| Feld | type | Mögliche Werte |
|---|---|---|
| status | Zeichenfolge | notStarted: Der Analysevorgang wird nicht gestartet.running: Der Analysevorgang ist in Bearbeitung.failed: Der Analysevorgang ist fehlgeschlagen.succeeded: Der Analysevorgang war erfolgreich. |
Rufen Sie diesen Vorgang solange auf, bis der Wert succeeded zurückgegeben wird. Verwenden Sie ein Intervall von drei bis fünf Sekunden, um zu verhindern, dass die Rate der Anforderungen pro Sekunde (Requests Per Second, RPS) überschritten wird.
Wenn das Feld Status den Wert succeeded aufweist, enthält die JSON-Antwort das extrahierte Layout, den extrahierten Text, die extrahierten Tabellen und die Auswahlmarkierungen. Die extrahierten Daten enthalten die extrahierten Textzeilen und Wörter, Begrenzungsrahmen, die handschriftliche Anzeige von Textdarstellung, Tabellen und Auswahlmarkierungen mit der Angabe „ausgewählt“ oder „nicht ausgewählt“.
Handschriftliche Klassifizierung für Textzeilen (nur Lateinisch)
Die Antwort umfasst die Klassifizierung, ob es sich bei den einzelnen Textzeilen um einen handschriftlichen Stil handelt, sowie eine Konfidenzbewertung. Dieses Feature wird nur für lateinische Sprachen unterstützt. Das folgende Beispiel zeigt die handschriftliche Klassifizierung für den Text im Bild.

JSON-Beispielausgabe
Die Antwort auf den Vorgang Get Analyze Layout Result ist eine strukturierte Darstellung des Dokuments mit allen extrahierten Informationen. Hier sehen Sie ein Beispiel für eine Dokumentdatei und deren strukturierte Ausgabe Beispiel für eine Layoutausgabe.
Die JSON-Ausgabe besteht aus zwei Teilen:
- Der Knoten
readResultsenthält den gesamten erkannten Text und alle erkannten Auswahlmarkierungen. Die Hierarchie der Textpräsentation ist eine Seite, dann eine Zeile und dann einzelne Wörter. - Der Knoten
pageResultsenthält die Tabellen und Zellen, die mit ihren Begrenzungsrahmen, Konfidenz (Vertrauen) und einem Verweis auf die Zeilen und Wörter im Feld „readResults“ extrahiert wurden.
Beispielausgabe
Text
Die Layout-API extrahiert Text aus Dokumenten und Bildern mit unterschiedlichen Textneigungen und Farben. Sie unterstützt Fotos von Dokumenten, Faxe, gedruckten und handschriftlichen Text (nur Englisch) und gemischte Modi. Text wird mit Informationen zu Zeilen, Wörtern, Begrenzungsrahmen, Konfidenzbewertungen und Stil (handschriftlich oder anderer) extrahiert. Alle Textinformationen sind im Abschnitt readResults der JSON-Ausgabe enthalten.
Tabellen mit Kopfzeilen
Die Layout-API extrahiert Tabellen in den pageResults Abschnitt der JSON-Ausgabe. Dokumente können gescannt, fotografiert oder digitalisiert sein. Tabellen können komplexe Tabellen mit zusammengeführten Zellen oder Spalten (mit oder ohne Rahmen) und mit ungeraden Winkeln sein. Die extrahierten Tabelleninformationen umfassen die Anzahl von Spalten und Zeilen sowie den Zeilen- und Spaltenabstand. Jede Zelle mit ihrem Begrenzungsrahmen wird zusammen mit Informationen ausgegeben, unabhängig davon, ob der Bereich als Teil einer Kopfzeile erkannt werden oder nicht. Die vom Modell vorhergesagten Kopfzellen können mehrere Zeilen umfassen und müssen nicht zwingend die ersten Zeilen in einer Tabelle sein. Dies funktioniert auch bei gedrehten Tabellen. Jede Tabellenzelle enthält auch den vollständigen Text mit Verweisen auf die einzelnen Wörter im readResults-Abschnitt.
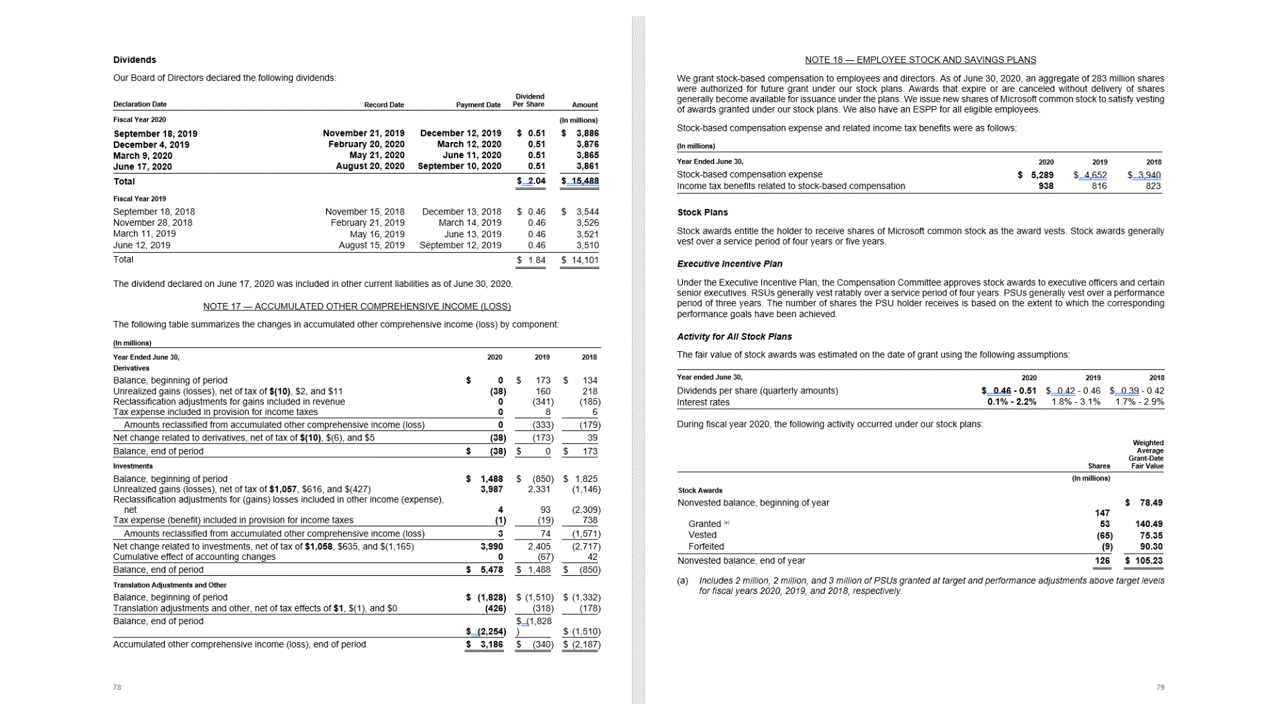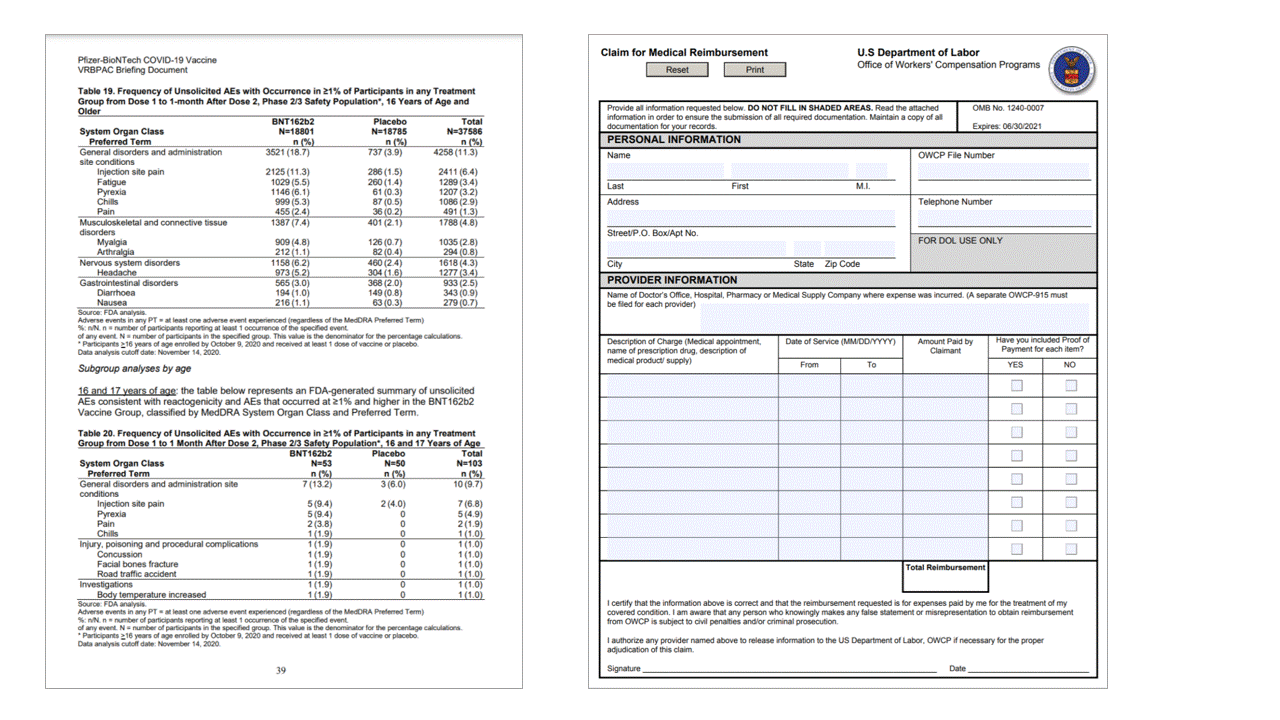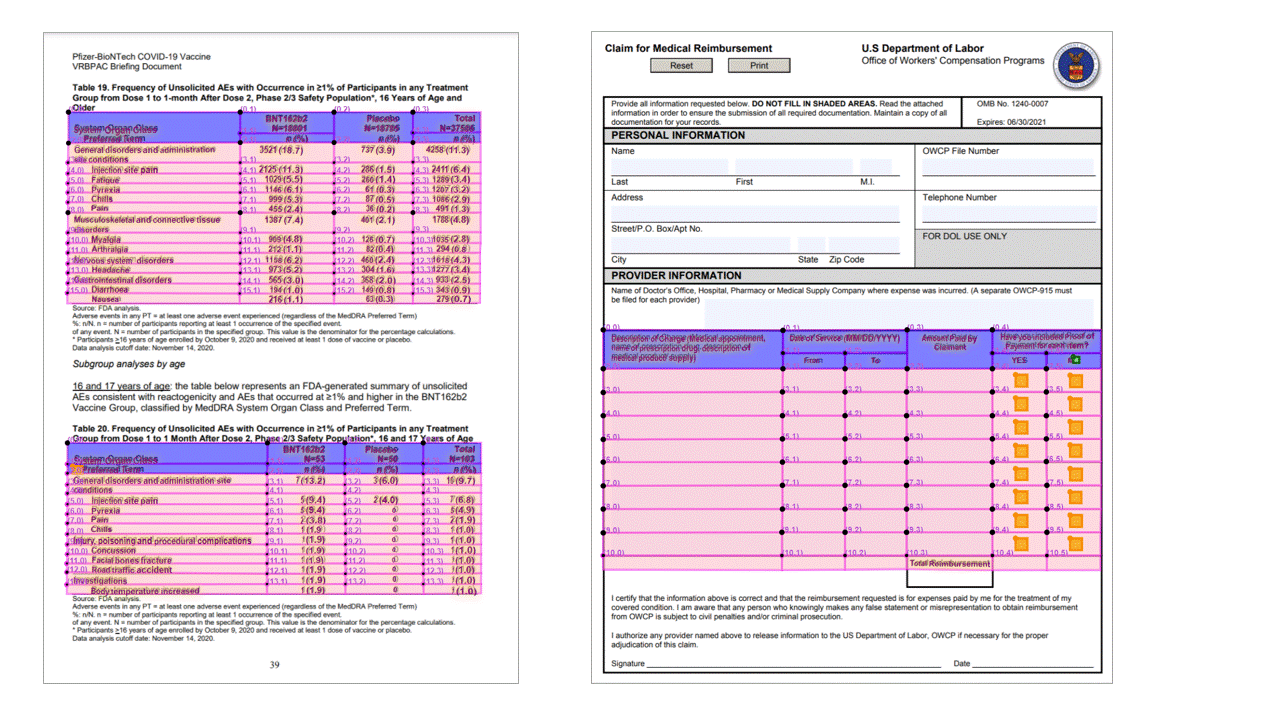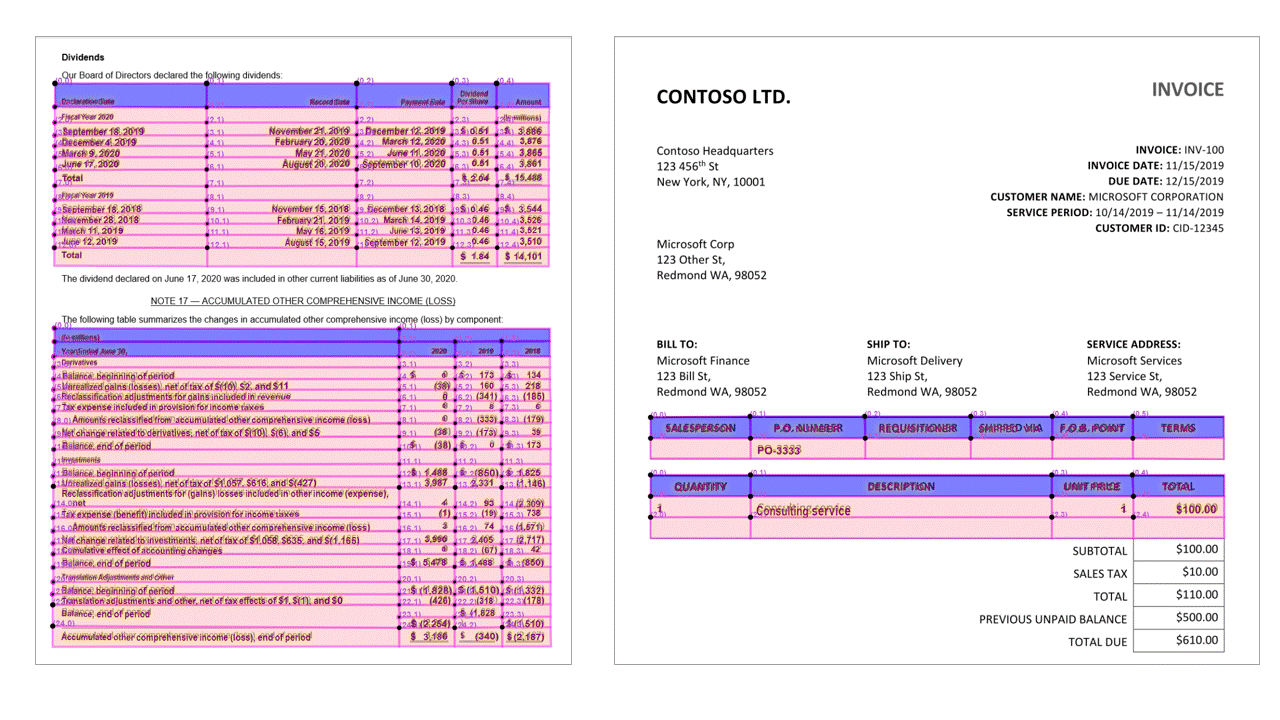
Auswahlmarkierungen
Die Layout-API extrahiert auch Auswahlmarkierungen aus Dokumenten. Extrahierte Auswahlmarkierungen enthalten den Begrenzungsrahmen, die Konfidenz (Zuverlässigkeit) und den Status („ausgewählt“ oder „nicht ausgewählt“). Informationen zur Auswahlmarkierung werden im Abschnitt readResults der JSON-Ausgabe extrahiert.
Migrationsleitfaden
- Folgen Sie dem Migrationsleitfaden für Dokument Intelligenz 3.1, um zu erfahren, wie Sie die Version 3.1 in Ihren Anwendungen und Workflows verwenden können.
Nächste Schritte
Hier erfahren Sie, wie Sie Ihre eigenen Formulare und Dokumente mithilfe von Dokument Intelligenz Studio verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.
Erfahren Sie mehr über das Verarbeiten Ihrer eigenen Formulare und Dokumente mit dem Tool für die Beschriftung von Beispielen von Document Intelligence.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.